Parameter Golf: What Really Works?
Pith reviewed 2026-07-03 20:47 UTC · model grok-4.3
The pith
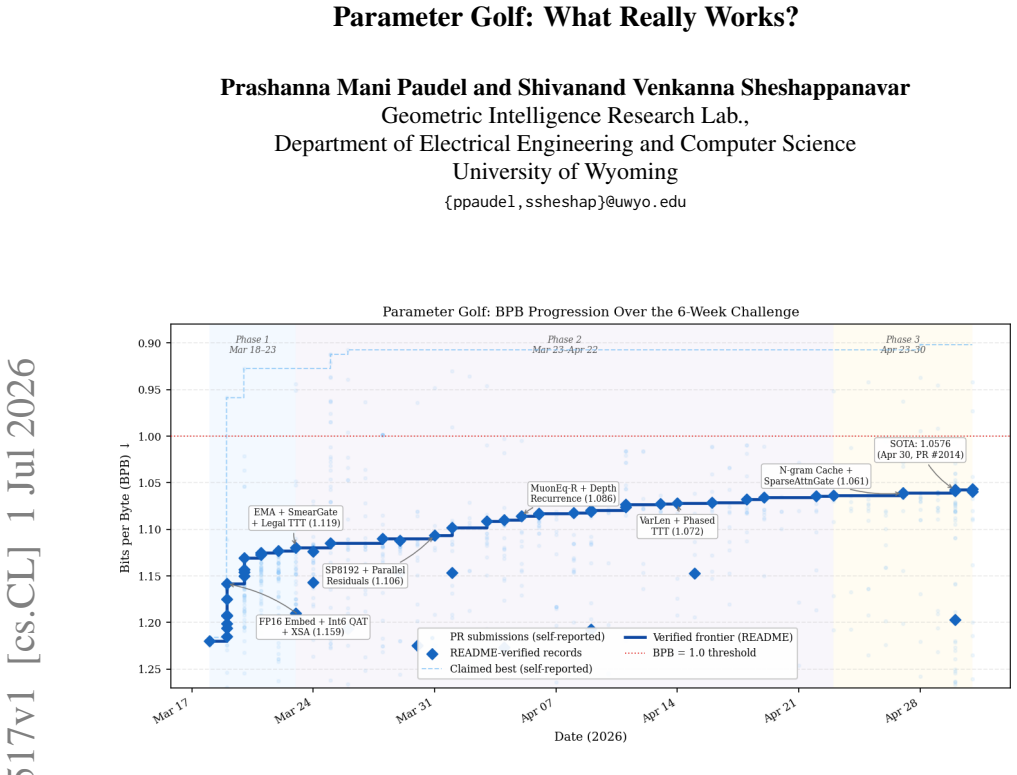
Community contest submissions cut language model BPB from 1.2244 to 1.058 despite most single techniques adding under 1%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
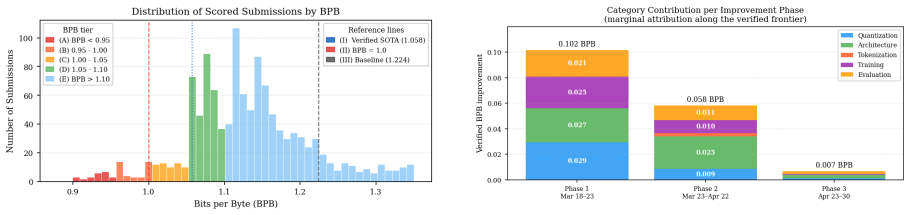
The verified leaderboard score dropped from 1.2244 to 1.058 BPB across three phases -- a 13.6% reduction, despite individual techniques rarely improving BPB by more than 1%. We show that most gains in techniques shrink across competitive submissions, isolating the few methods that improve performance across stacks.
What carries the argument
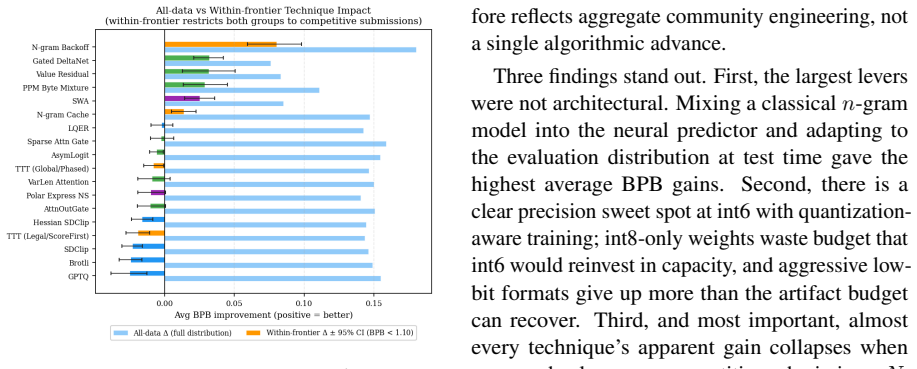
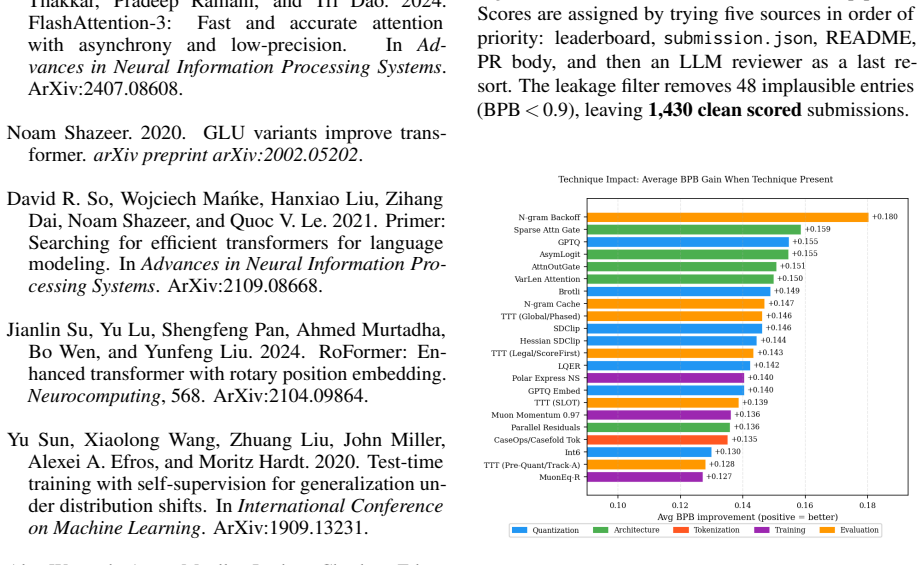
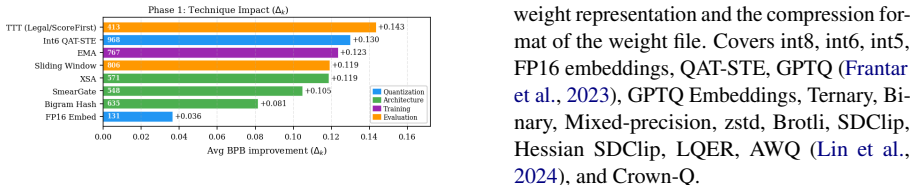
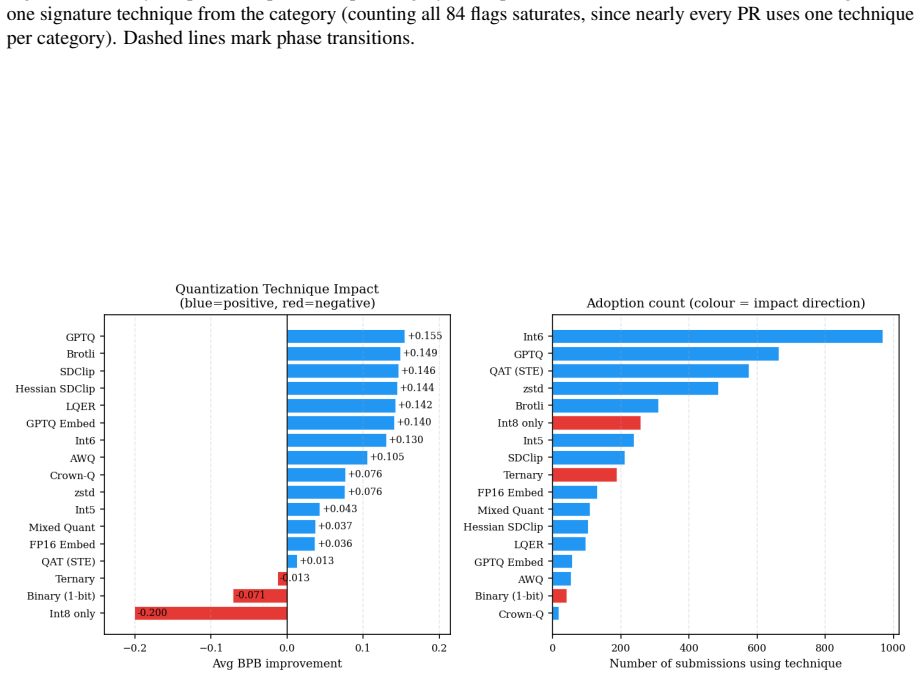
The taxonomy of 84 optimization techniques extracted from the 1,430 submissions, together with per-technique contribution measurements to BPB.
If this is right
- Only a minority of techniques retain their BPB gains once many submissions compete.
- Overall score improvement can still reach double digits even when every single technique stays below 1 percent.
- Techniques must be evaluated for cross-stack robustness rather than isolated peak effect.
- Diminishing returns appear for the majority of common optimizations under tight artifact budgets.
Where Pith is reading between the lines
- Re-running the contest with the same techniques but new participants would test whether the observed shrinkage is due to selection or to genuine interactions.
- The same measurement approach could be applied to other constrained training settings such as mobile or edge models.
- Future work could measure pairwise interactions among the few persistent techniques to explain why they combine better than the rest.
Load-bearing premise
The 1,430 clean scored submissions and the derived taxonomy of 84 techniques provide an unbiased and complete basis for attributing BPB improvements to specific optimizations rather than to unmeasured interactions or selection effects in the contest data.
What would settle it
A controlled replication that applies the isolated top techniques to fresh model stacks outside the original contest and checks whether the full 13.6 percent BPB reduction is recovered.
Figures




read the original abstract
How far can a language model improve under a strict artifact budget? Parameter Golf posed this question as an open community challenge in which participants trained the best language model, with the complete artifact (training code + compressed weights) required to fit within 16 MB and be trained in under ten minutes on 8xH100 SXM GPUs. Quality was measured in bits-per-byte (BPB), the average number of bits required to encode each byte of unseen text. We analyze 2,037 pull requests and 1,430 clean scored submissions from the contest, build a taxonomy of 84 optimization techniques, and measure each technique's contribution to BPB. The verified leaderboard score dropped from 1.2244 to 1.058 BPB across three phases -- a 13.6% reduction, despite individual techniques rarely improving BPB by more than 1%. We show that most gains in techniques shrink across competitive submissions, isolating the few methods that improve performance across stacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 2,037 pull requests and 1,430 scored submissions from the Parameter Golf contest, in which participants optimized language models to fit within a 16 MB artifact budget and train in under 10 minutes on 8xH100 GPUs. It constructs a taxonomy of 84 optimization techniques, attributes BPB improvements to them, and reports that the verified leaderboard score fell from 1.2244 to 1.058 BPB (13.6% reduction) across phases, with most individual techniques contributing <1% and gains shrinking over time, while isolating a small set of methods that improve performance across stacks.
Significance. If the per-technique attributions prove robust, the work supplies a large-scale empirical map of what optimizations matter under tight compute and size constraints, highlighting diminishing returns and cross-stack generalizers. The scale of the contest data and the explicit taxonomy constitute a reproducible resource for the community.
major comments (3)
- [Abstract / §4] Abstract and §4 (results): The central claim that the 13.6% BPB reduction can be decomposed into contributions from the 84-technique taxonomy rests on observational contest submissions without reported statistical methods, confidence intervals, or controls for co-occurrence and sequential dependence. Later high-scoring entries are conditioned on earlier ones, so observed deltas cannot be cleanly attributed to individual techniques rather than interactions, survivor bias, or search effort.
- [§3] §3 (taxonomy construction): The assignment of the 84 techniques to the 1,430 submissions is described as post-hoc labeling; without pre-specified criteria, inter-annotator reliability metrics, or sensitivity checks to alternative taxonomies, the isolation of 'few methods that improve performance across stacks' risks circularity with the leaderboard ordering itself.
- [§4.2] §4.2 (per-technique measurement): No matched-pair ablations, randomized controls, or regression models with interaction terms are mentioned to separate main effects from confounders; the reported shrinkage of gains across phases therefore cannot be distinguished from selection effects in the competitive data.
minor comments (2)
- [Abstract] Abstract: 'verified leaderboard score' is used without a definition of the verification procedure or exclusion criteria for the 1,430 clean submissions.
- [§2] The manuscript would benefit from an explicit statement of how BPB is computed on the held-out text and whether the same evaluation set was used across all phases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating revisions where we agree changes are warranted while defending the observational nature of the study.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (results): The central claim that the 13.6% BPB reduction can be decomposed into contributions from the 84-technique taxonomy rests on observational contest submissions without reported statistical methods, confidence intervals, or controls for co-occurrence and sequential dependence. Later high-scoring entries are conditioned on earlier ones, so observed deltas cannot be cleanly attributed to individual techniques rather than interactions, survivor bias, or search effort.
Authors: We agree the analysis is observational and lacks formal statistical controls such as regression models, confidence intervals, or explicit handling of sequential dependence. Attributions derive from associating technique introductions with score deltas across submissions. We will revise the abstract and §4 to qualify claims as observational, add a limitations paragraph on confounders including survivor bias and co-occurrence, and report technique co-occurrence frequencies among top entries. New controlled experiments are not feasible on historical data. revision: partial
-
Referee: [§3] §3 (taxonomy construction): The assignment of the 84 techniques to the 1,430 submissions is described as post-hoc labeling; without pre-specified criteria, inter-annotator reliability metrics, or sensitivity checks to alternative taxonomies, the isolation of 'few methods that improve performance across stacks' risks circularity with the leaderboard ordering itself.
Authors: The taxonomy was built by iterative review of PR descriptions and code diffs, with categories defined independently before scoring associations. No formal inter-annotator metrics were computed. We will add explicit discussion of the post-hoc process and a sensitivity analysis re-grouping a sample of techniques to test robustness of the cross-stack results. Circularity is mitigated because taxonomy labels precede score-based filtering and are applied uniformly across all submissions. revision: partial
-
Referee: [§4.2] §4.2 (per-technique measurement): No matched-pair ablations, randomized controls, or regression models with interaction terms are mentioned to separate main effects from confounders; the reported shrinkage of gains across phases therefore cannot be distinguished from selection effects in the competitive data.
Authors: We concur that no ablations or randomized controls exist, as the work analyzes existing contest data rather than new experiments. The phase-wise shrinkage is reported descriptively. We will revise §4.2 to state explicitly that selection effects cannot be ruled out and to frame the shrinkage finding as correlational. Core per-technique measurements remain unchanged without new data. revision: yes
Circularity Check
No circularity: analysis rests on external contest data without self-referential reductions
full rationale
The paper reports an observational analysis of 2,037 pull requests and 1,430 external contest submissions, constructing a taxonomy of 84 techniques and measuring their BPB contributions from public leaderboard scores. No equations, definitions, or self-citations are presented that reduce the reported 13.6% BPB drop or per-technique attributions to fitted inputs, self-definitions, or prior author work by construction. The derivation chain is self-contained against the external contest data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bits-per-byte on unseen text is an appropriate scalar measure of language-model quality under the contest constraints.
Reference graph
Works this paper leans on
- [1]
-
[2]
2025 , howpublished =
work page 2025
-
[3]
Guilherme Penedo and Hynek Kydl. The. Advances in Neural Information Processing Systems , year =
-
[4]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , howpublished =
work page 2024
-
[5]
International Conference on Learning Representations , year =
Songlin Yang and Jan Kautz and Ali Hatamizadeh , title =. International Conference on Learning Representations , year =
-
[6]
International Conference on Learning Representations , year =
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , title =. International Conference on Learning Representations , year =
-
[7]
Constantinides and Yiren Zhao , title =
Cheng Zhang and Jianyi Cheng and George A. Constantinides and Yiren Zhao , title =. International Conference on Machine Learning , year =
-
[8]
Taku Kudo and John Richardson , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages =. 2018 , note =
work page 2018
-
[9]
Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI) , year =
Pavel Izmailov and Dmitrii Podoprikhin and Timur Garipov and Dmitry Vetrov and Andrew Gordon Wilson , title =. Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI) , year =
-
[10]
Efros and Moritz Hardt , title =
Yu Sun and Xiaolong Wang and Zhuang Liu and John Miller and Alexei A. Efros and Moritz Hardt , title =. International Conference on Machine Learning , year =
-
[11]
Slava M. Katz , title =. IEEE Transactions on Acoustics, Speech, and Signal Processing , volume =
-
[12]
John G. Cleary and Ian H. Witten , title =. IEEE Transactions on Communications , volume =
-
[13]
Yoshua Bengio and Nicholas L. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , journal =
-
[14]
Jianlin Su and Yu Lu and Shengfeng Pan and Ahmed Murtadha and Bo Wen and Yunfeng Liu , title =. Neurocomputing , volume =. 2024 , note =
work page 2024
-
[15]
GLU Variants Improve Transformer
Noam Shazeer , title =. arXiv preprint arXiv:2002.05202 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[16]
ACM Transactions on Information Systems , volume =
Jyrki Alakuijala and Andrea Farruggia and Paolo Ferragina and Eugene Kliuchnikov and Robert Obryk and Zoltan Szabadka and Lode Vandevenne , title =. ACM Transactions on Information Systems , volume =
-
[17]
Alex Warstadt and Aaron Mueller and Leshem Choshen and Ethan Wilcox and Chengxu Zhuang and Juan Ciro and Rafael Mosquera and Bhargavi Paranjabe and Adina Williams and Tal Linzen and Ryan Cotterell , title =. Proceedings of the BabyLM Challenge at the Conference on Computational Natural Language Learning , year =
-
[18]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Ronen Eldan and Yuanzhi Li , title =. arXiv preprint arXiv:2305.07759 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , year =
Sharan Narang and Hyung Won Chung and Yi Tay and William Fedus and Thibault Fevry and Michael Matena and Karishma Malkan and Noah Fiedel and Noam Shazeer and Zhenzhong Lan and Yanqi Zhou and Wei Li and Nan Ding and Jake Marcus and Adam Roberts and Colin Raffel , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing , year =
-
[20]
David R. So and Wojciech Ma. Primer: Searching for Efficient Transformers for Language Modeling , booktitle =. 2021 , note =
work page 2021
-
[21]
Scaling Laws for Neural Language Models
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. arXiv preprint arXiv:2001.08361 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[22]
Rae and Oriol Vinyals and Laurent Sifre , title =
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
-
[23]
International Conference on Learning Representations , year =
Urvashi Khandelwal and Omer Levy and Dan Jurafsky and Luke Zettlemoyer and Mike Lewis , title =. International Conference on Learning Representations , year =
-
[24]
Rae and Erich Elsen and Laurent Sifre , title =
Sebastian Borgeaud and Arthur Mensch and Jordan Hoffmann and Trevor Cai and Eliza Rutherford and Katie Millican and George van den Driessche and Jean-Baptiste Lespiau and Bogdan Damoc and Aidan Clark and Diego de Las Casas and Aurelia Guy and Jacob Menick and Roman Ring and Tom Hennigan and Saffron Huang and Loren Maggiore and Chris Jones and Albin Cassir...
-
[25]
Conference on Language Modeling (COLM) , year =
Jiacheng Liu and Sewon Min and Luke Zettlemoyer and Yejin Choi and Hannaneh Hajishirzi , title =. Conference on Language Modeling (COLM) , year =
-
[26]
Proceedings of Machine Learning and Systems (MLSys) , year =
Ji Lin and Jiaming Tang and Haotian Tang and Shang Yang and Wei-Ming Chen and Wei-Chen Wang and Guangxuan Xiao and Xingyu Dang and Chuang Gan and Song Han , title =. Proceedings of Machine Learning and Systems (MLSys) , year =
-
[27]
Advances in Neural Information Processing Systems , year =
Jay Shah and Ganesh Bikshandi and Ying Zhang and Vijay Thakkar and Pradeep Ramani and Tri Dao , title =. Advances in Neural Information Processing Systems , year =
-
[28]
International Conference on Learning Representations , year =
Bowen Peng and Jeffrey Quesnelle and Honglu Fan and Enrico Shippole , title =. International Conference on Learning Representations , year =
-
[29]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao , title =. arXiv preprint arXiv:2312.00752 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
IEEE Conference on Computer Vision and Pattern Recognition , year =
Benoit Jacob and Skirmantas Kligys and Bo Chen and Menglong Zhu and Matthew Tang and Andrew Howard and Hartwig Adam and Dmitry Kalenichenko , title =. IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[31]
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam Shazeer and Vinodkumar Prabhakaran and Emi...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.