When LLMs Stop Following Steps: A Diagnostic Study of Procedural Execution in Language Models
Pith reviewed 2026-05-22 10:00 UTC · model grok-4.3
The pith
Large language models lose accuracy on long step-by-step procedures, dropping from 61 percent to 20 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
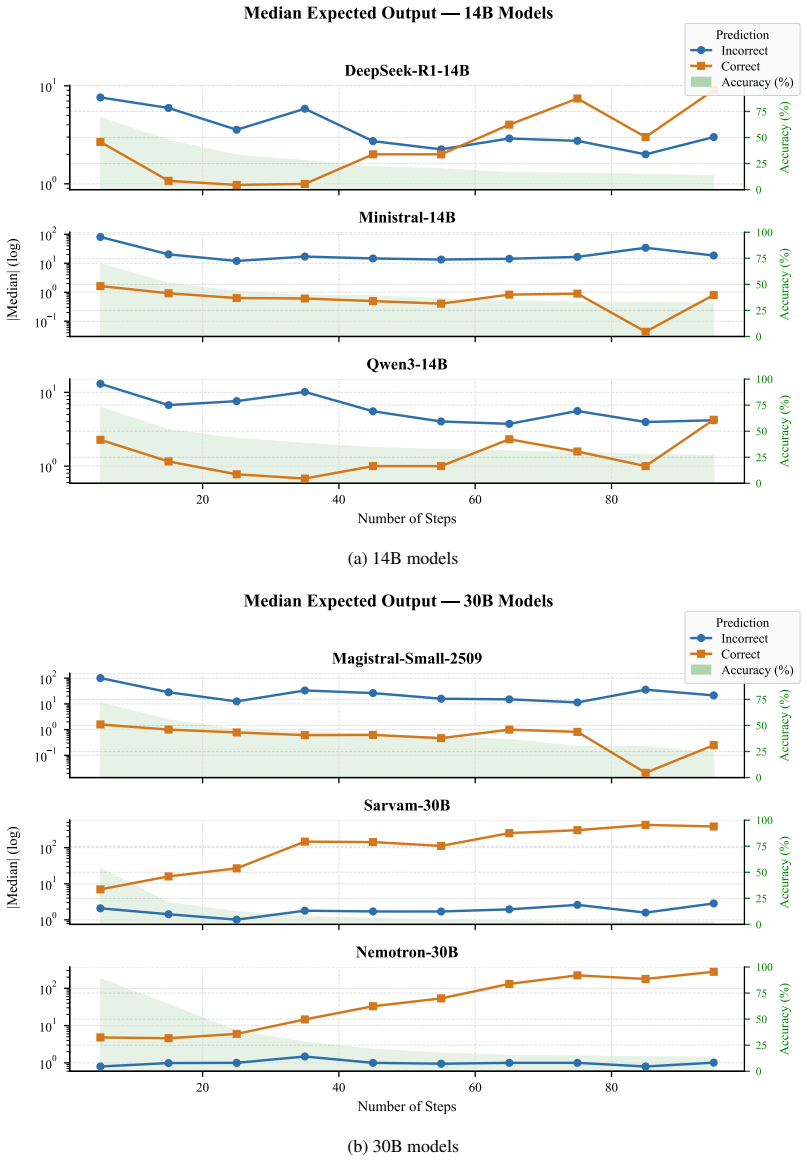
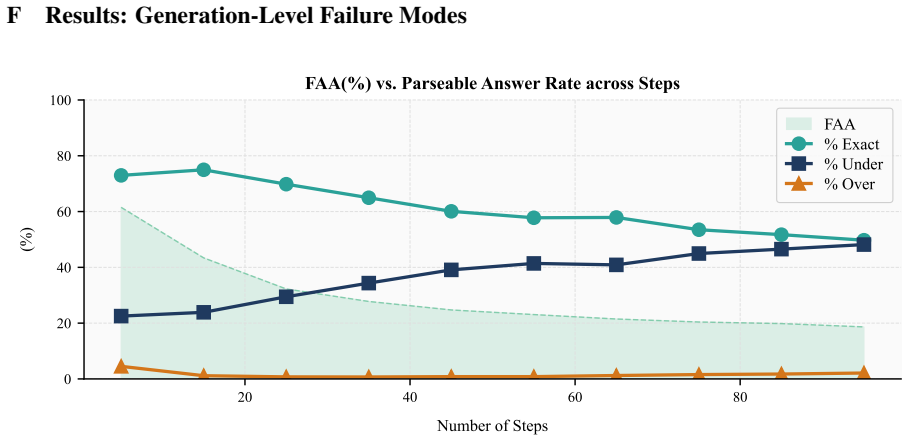
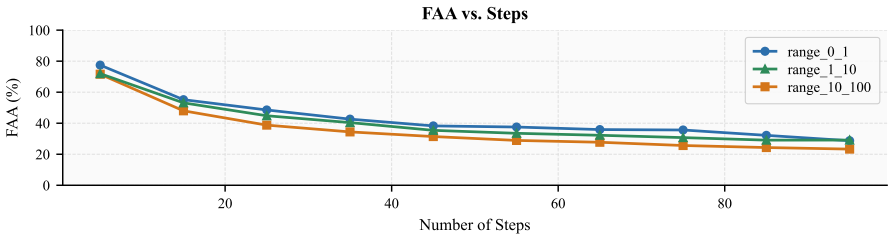
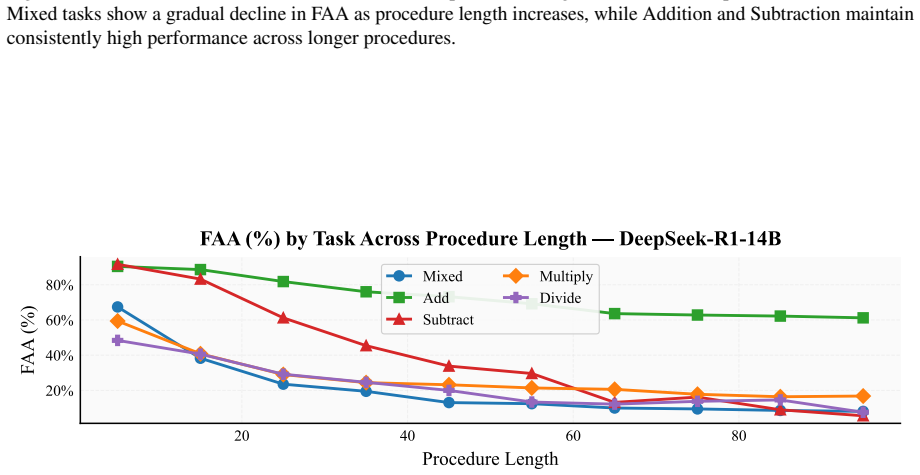
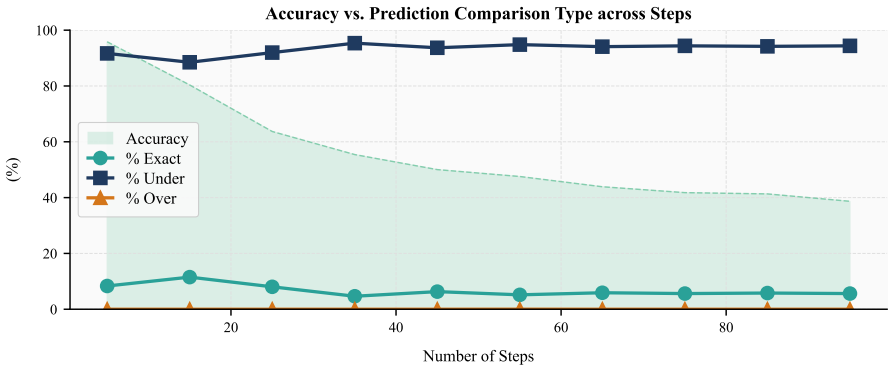
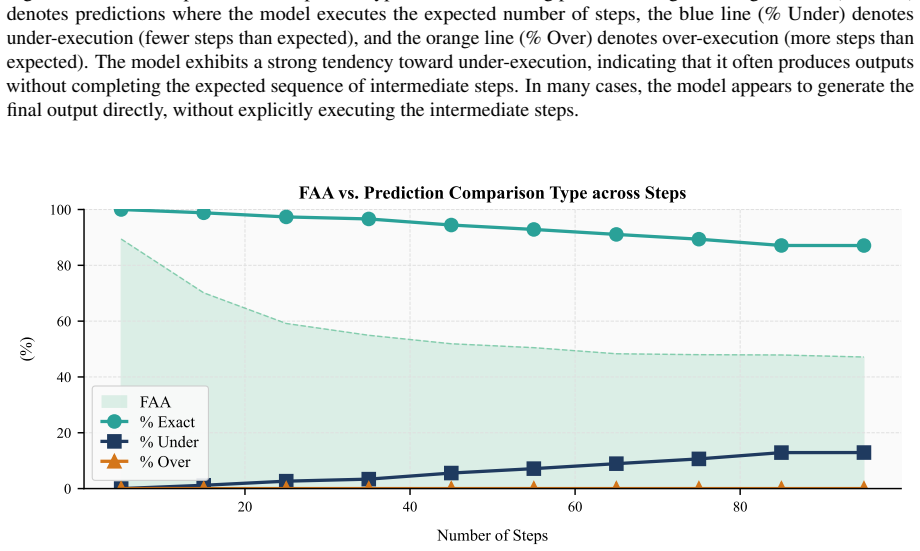
When models receive a step-wise arithmetic algorithm and two numeric inputs, they must return the final value, yet first-answer accuracy declines from 61 percent on five-step procedures to 20 percent on ninety-five-step procedures, and generation analysis reveals frequent missing answers, premature answers, self-corrections after errors, under-executed traces, and hallucinated extra steps.
What carries the argument
A diagnostic benchmark of controlled arithmetic procedures whose length and look-back dependencies over intermediate variables are varied while keeping the underlying operations simple.
If this is right
- Final-answer correctness on reasoning benchmarks does not confirm that models have executed the specified procedure.
- Common errors include missing the answer, answering before all steps finish, correcting an earlier mistake, stopping early, or adding steps absent from the prompt.
- Weaknesses in procedural execution appear even when the arithmetic itself remains elementary.
- Increasing both the number of steps and the number of required look-backs makes execution failures easier to observe.
Where Pith is reading between the lines
- Prompting or training methods that reward only the final answer may leave step-by-step fidelity untouched.
- Tasks that demand strict adherence to a protocol, such as following a scientific protocol or generating code from a detailed spec, may be more fragile than benchmark scores suggest.
- Evaluations that score intermediate traces separately from the end result could expose reliability limits that final-answer metrics miss.
Load-bearing premise
The arithmetic procedures are built so that any performance drop must come from failing to follow the steps rather than from limits in arithmetic skill or prompt understanding.
What would settle it
Finding a model that sustains above 50 percent accuracy on the longest procedures while producing complete and correct traces of every intermediate variable would contradict the reported decline.
Figures









































































































































































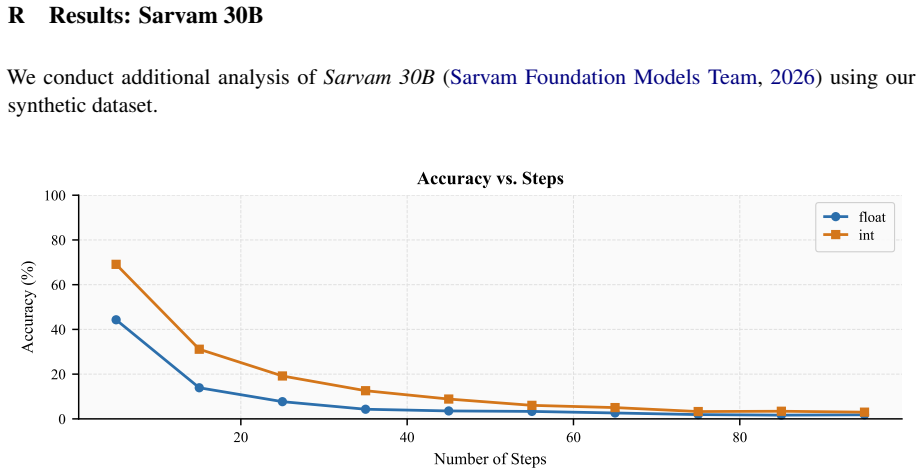














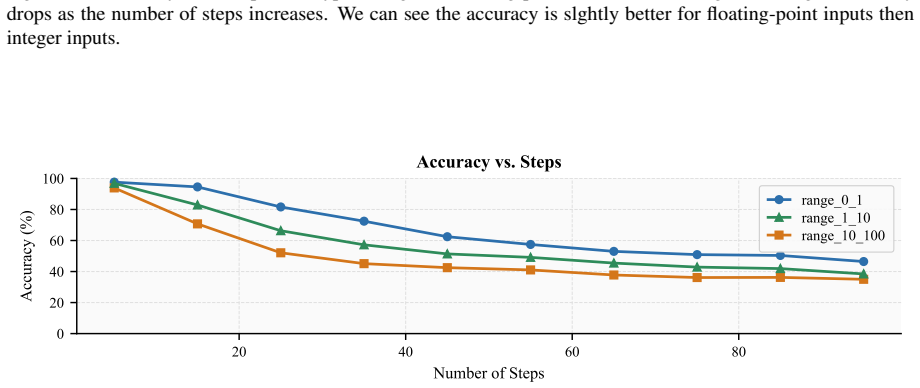






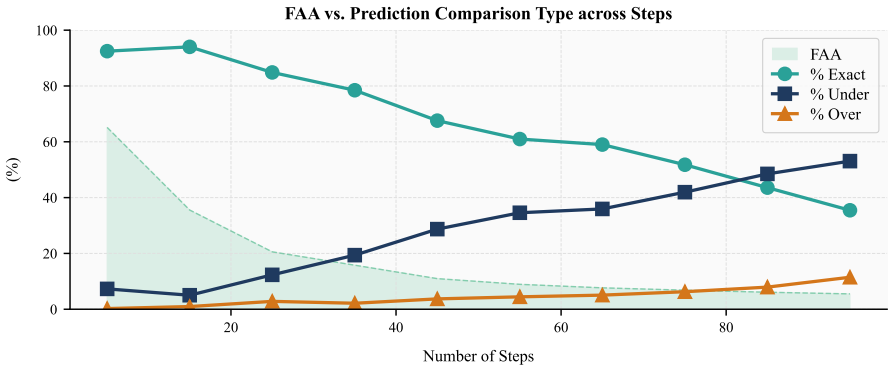

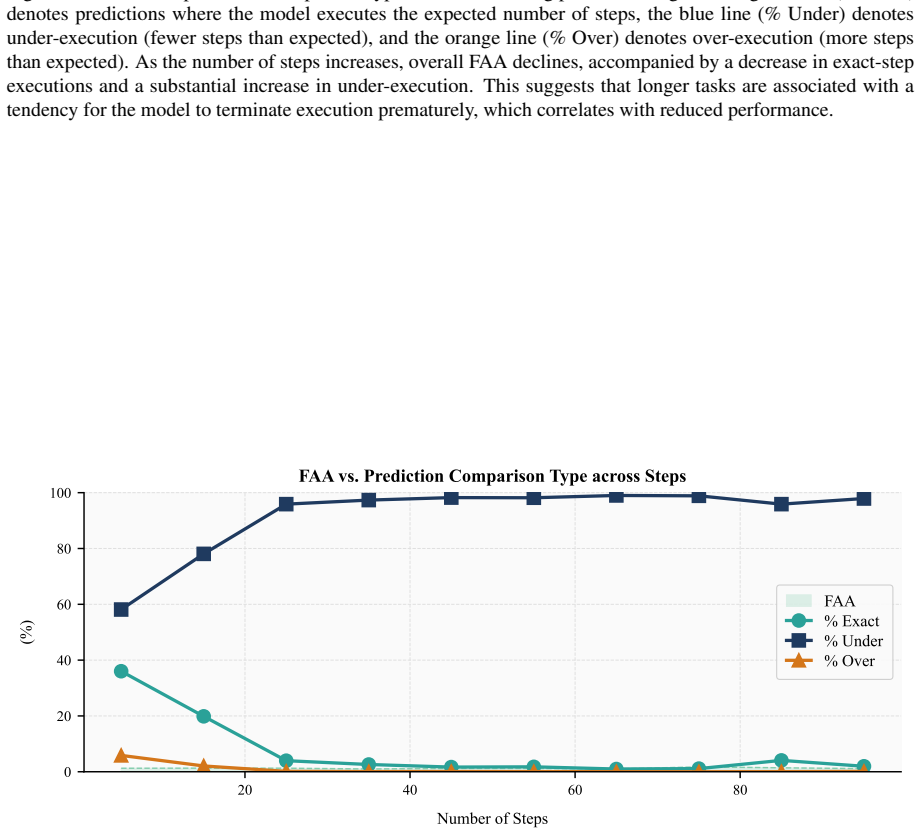















read the original abstract
Large language models (LLMs) often achieve strong performance on reasoning benchmarks, but final-answer accuracy alone does not show whether they faithfully execute the procedure specified in a prompt. We introduce a controlled diagnostic benchmark for procedural execution, where models are given a step-wise arithmetic procedure and two numeric inputs, and must return the final computed value. Complexity is varied through procedure length and look-back dependencies over intermediate variables. Average first-answer accuracy drops from 63% on 5-step procedures to 20% on 95-step procedures. Generation-level analysis shows that failures often involve missing answers, premature answers, self-correction after an initial error and under-executed traces. These findings suggest that apparent reasoning ability can mask substantial weaknesses in faithful long-horizon procedural execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a controlled diagnostic benchmark to assess whether large language models faithfully execute step-by-step arithmetic procedures given in prompts, beyond merely producing correct final answers. The benchmark varies procedure length (5 to 95 steps) and look-back dependencies on intermediate variables while using simple arithmetic. Experiments across 14 models and 55 datasets show first-answer accuracy declining from 61% to 20%, with failure modes including missing or premature answers, self-corrections, under-executed traces, and hallucinated steps. The authors conclude that strong performance on reasoning tasks may conceal deficiencies in procedural instruction following.
Significance. If the results are robust, this study provides valuable evidence that current LLMs struggle with faithful execution of long procedures, which has implications for applications requiring reliable multi-step reasoning and instruction adherence. The broad evaluation across many models and datasets lends credibility to the observed trends and could guide future work on improving procedural fidelity in language models. The scale of the empirical evaluation is a clear strength.
major comments (1)
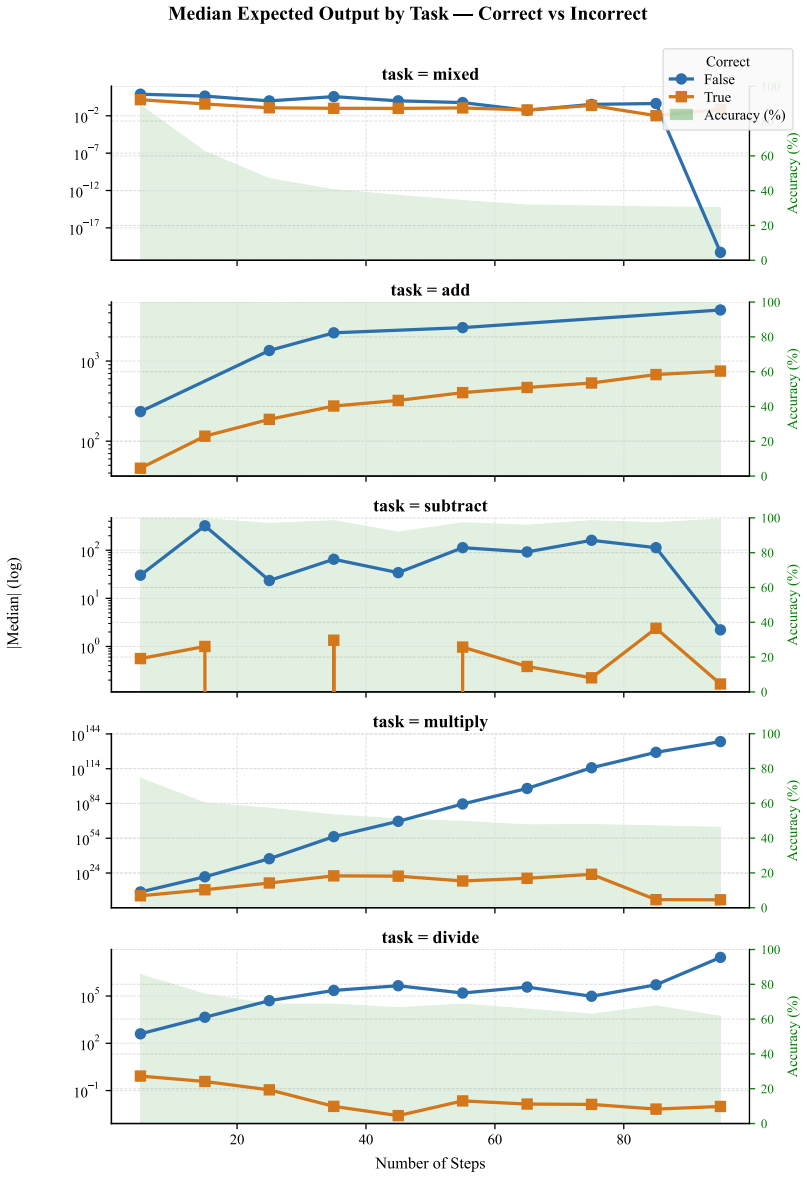
- [Benchmark construction] Benchmark construction (as described in the abstract): The central assumption that varying algorithm length and look-back dependencies over intermediate variables sufficiently isolates procedural execution failures from context tracking, attention dilution, or variable reference resolution is not fully supported by the design. Longer procedures (up to 95 steps) necessarily increase the number of intermediate variables and cumulative reference distances across the context window; models could fail due to these factors even while grasping the high-level steps. This assumption is load-bearing for attributing the accuracy drop (61% at 5 steps to 20% at 95 steps) specifically to weaknesses in faithful instruction execution rather than general context management limitations.
minor comments (2)
- [Abstract] The abstract states that trends are consistent across 14 models and 55 datasets but provides no details on statistical controls, variance, run-to-run variability, or how failure categories were annotated; adding these would improve clarity and verifiability.
- [Methods] Methods details on exact prompt templates, how datasets were generated to control for total context length, and model version specifics are not visible in the provided summary; these would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the work's significance and the breadth of our empirical evaluation across models and datasets. We address the single major comment on benchmark construction below and will incorporate revisions to clarify the design rationale and potential confounds.
read point-by-point responses
-
Referee: Benchmark construction (as described in the abstract): The central assumption that varying algorithm length and look-back dependencies over intermediate variables sufficiently isolates procedural execution failures from context tracking, attention dilution, or variable reference resolution is not fully supported by the design. Longer procedures (up to 95 steps) necessarily increase the number of intermediate variables and cumulative reference distances across the context window; models could fail due to these factors even while grasping the high-level steps. This assumption is load-bearing for attributing the accuracy drop (61% at 5 steps to 20% at 95 steps) specifically to weaknesses in faithful instruction execution rather than general context management limitations.
Authors: We appreciate this observation that procedure length inherently correlates with more intermediate variables and longer reference spans, which could interact with general context-management limitations. Our benchmark does attempt to isolate procedural fidelity by fixing the arithmetic operations to simple addition/subtraction while systematically varying both total length and the specific look-back distance to prior variables at each step; this allows us to observe whether models correctly retrieve and apply the referenced value rather than merely losing track of the overall context. The qualitative failure modes we document—such as skipping an explicit step, emitting a premature final answer before completing the trace, or hallucinating an operation not present in the prompt—suggest breakdowns in faithful step execution that go beyond uniform attention dilution. That said, we agree the current presentation does not fully rule out the confound. In the revision we will add a new subsection under Benchmark Design that (a) quantifies the distribution of reference distances across lengths, (b) reports error rates conditioned on reference distance within fixed-length subsets, and (c) discusses the implications for attributing the observed accuracy drop primarily to procedural instruction following. These additions will make the load-bearing assumption more transparent without requiring new experiments. revision: partial
Circularity Check
No circularity: purely empirical benchmark study with no derivations or fitted parameters.
full rationale
This paper constructs controlled benchmark datasets with arithmetic procedures of increasing length and look-back dependencies, then empirically measures LLM accuracy and error patterns across 14 models and 55 datasets. There are no mathematical derivations, parameter fittings, self-citations used as load-bearing premises, or uniqueness theorems invoked. The central claims rest on direct experimental observations of accuracy decline (e.g., 61% to 20%) and qualitative failure modes, which are self-contained against the external benchmark results and do not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The benchmark tasks accurately measure procedural execution fidelity independent of other model capabilities.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Average first-answer accuracy drops from 61% on 5-step procedures to 20% on 95-step procedures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.