REVIEW 2 major objections 2 minor 24 references
Pairwise preference rewards and group diversity signals enable superior alignment and variety in open-ended generation without scalar rewards.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 10:11 UTC pith:YWK22GQI
load-bearing objection PPR-GDE bundles pairwise preferences with group diversity into one RL objective for open-ended generation, but the experimental claims rest on thin reported support. the 2 major comments →
Pairwise Preference Reward and Group-Based Diversity Enhancement for Superior Open-Ended Generation
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PPR-GDE integrates a pairwise preference reward, derived from repeated comparisons with swapped response order to mitigate position bias, together with a group-based diversity reward that explicitly encourages semantic dispersion within each response group, into a unified group-relative policy optimization objective. This structure avoids training separate scalar reward models and counters the diversity collapse typical of RLVR in open domains. When applied to role-playing, the method produces responses with measurably higher alignment quality and expressive diversity than strong RL baselines, with ablation confirming that pairwise signals matter most for subjective alignment and the group-m
What carries the argument
PPR-GDE, which combines pairwise preference rewards from order-swapped comparisons with a group-based diversity reward inside a group-relative policy optimization objective.
Load-bearing premise
The pairwise preference signal obtained from repeated comparisons with swapped order accurately reflects subjective human preferences without introducing new systematic biases.
What would settle it
A blind human evaluation in which PPR-GDE responses are not preferred over strong RL baselines in pairwise judgments for both alignment quality and expressive diversity on held-out role-playing prompts would falsify the performance claim.
If this is right
- Better alignment quality than strong RL baselines on subjective tasks such as role-playing.
- Higher expressive diversity and broader semantic coverage than standard RL methods.
- Pairwise preference is critical for achieving preference alignment from a subjective perspective.
- The group diversity metric is essential for superior expressive diversity without stereotypical outputs.
Where Pith is reading between the lines
- The method could reduce the annotation and compute costs of building reward models for open-ended domains.
- Similar comparative-plus-group structures might help other creative generation settings where repetition is a known failure mode.
- Treating human judgments as comparative rather than absolute may prove more robust for training in highly subjective tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pairwise Preference Reward and Group-based Diversity Enhancement (PPR-GDE), an RL method for open-ended generation that replaces scalar rewards with pairwise preference signals obtained via repeated comparisons with swapped response order, adds a group-based diversity term to encourage semantic dispersion within response groups, and combines both into a unified group-relative policy optimization objective. The method is instantiated on a role-playing task, where the abstract claims it yields better alignment quality and expressive diversity than strong RL baselines, with further analysis attributing alignment gains to the pairwise component and diversity gains to the group metric.
Significance. If the empirical results can be substantiated with quantitative metrics, ablations, and controls for judge biases, the work could provide a useful alternative to standard RLVR approaches in subjective open-ended domains by reducing reward-model costs and mitigating diversity collapse. The group-level diversity mechanism is a potentially interesting technical choice, but its impact remains unverified in the current presentation.
major comments (2)
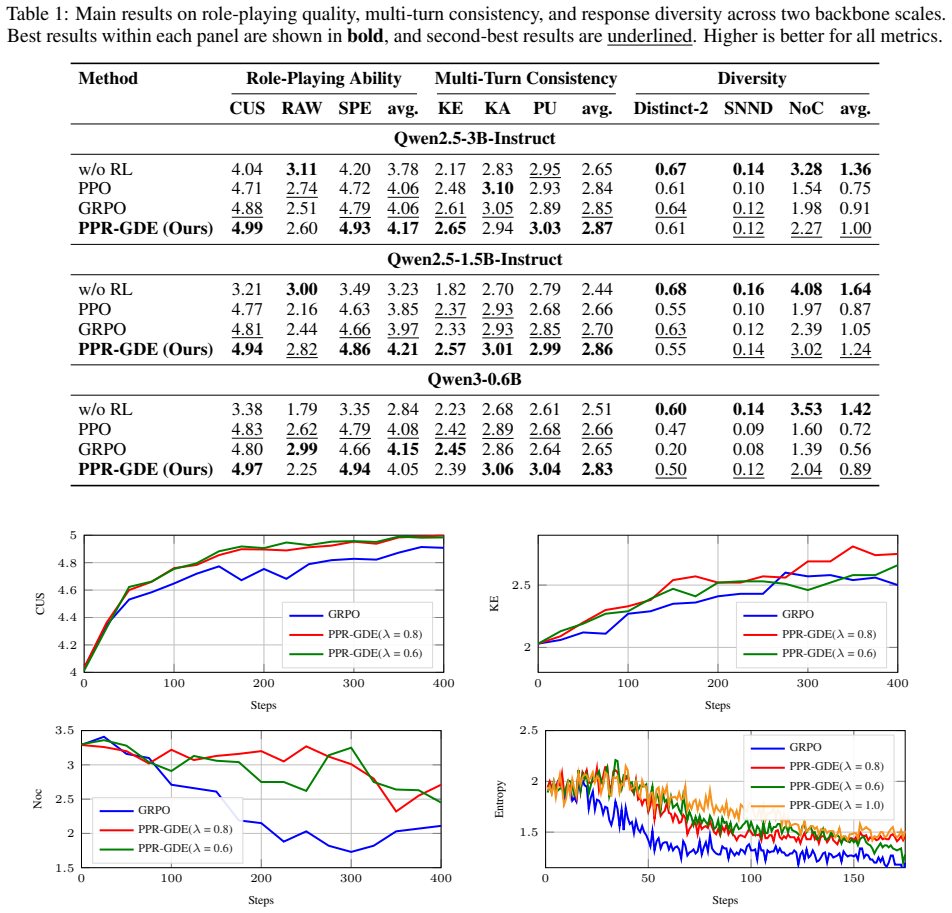
- [Abstract] Abstract: the central claim that 'experiments show that PPR-GDE achieves a better alignment quality as well as expressive diversity than strong RL baselines' is unsupported by any quantitative metrics, tables, statistical tests, dataset descriptions, or ablation results, which is load-bearing for the paper's contribution.
- [Method description] The pairwise preference reward construction (repeated comparisons with swapped order): while position bias is addressed, the manuscript provides no evidence or analysis that the resulting signal is free of other systematic biases (length, style, or content preferences) from the underlying judge model; this directly affects the claim that the reward serves as a reliable proxy for subjective human preferences.
minor comments (2)
- [Abstract] The abstract introduces several components (pairwise preference, group diversity, group-relative optimization) without a brief equation or pseudocode sketch, making the high-level description harder to follow on first reading.
- [Experiments] Ensure that all baselines are explicitly named and that the role-playing task dataset and evaluation protocol are described with sufficient detail for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify opportunities to strengthen the presentation of empirical support and to provide explicit validation of the reward signal. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experiments show that PPR-GDE achieves a better alignment quality as well as expressive diversity than strong RL baselines' is unsupported by any quantitative metrics, tables, statistical tests, dataset descriptions, or ablation results, which is load-bearing for the paper's contribution.
Authors: The full manuscript presents quantitative results, including alignment and diversity metrics with baseline comparisons, in Section 4, ablations in Section 5, dataset details in Section 3, and statistical tests where relevant. We agree the abstract would be improved by making this evidence more immediately visible. In the revision we will update the abstract to reference the specific metrics (e.g., preference alignment accuracy and semantic dispersion scores), note the improvements over baselines, and include citations to the relevant tables and sections. revision: yes
-
Referee: [Method description] The pairwise preference reward construction (repeated comparisons with swapped order): while position bias is addressed, the manuscript provides no evidence or analysis that the resulting signal is free of other systematic biases (length, style, or content preferences) from the underlying judge model; this directly affects the claim that the reward serves as a reliable proxy for subjective human preferences.
Authors: We accept that mitigation of position bias alone does not fully establish robustness against other judge-model biases. The revised manuscript will add a dedicated analysis subsection that examines correlations between the derived pairwise signals and response properties such as length, lexical style, and topical content. Any observed systematic biases will be quantified and discussed as limitations, thereby providing clearer justification for treating the signal as a proxy for subjective preferences. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes PPR-GDE as a new RL objective for open-ended tasks that combines a pairwise preference reward (with order-swapping to address position bias) and a group-based diversity reward, all integrated into a group-relative policy optimization framework. Claims rest on experimental comparisons to RL baselines on role-playing, with no presented equations, fitted parameters, or derivations that reduce the reported alignment/diversity gains to quantities obtained by construction from the paper's own inputs or prior self-citations. The formulation is a novel combination of described reward components rather than a renaming or self-referential prediction, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward combination weight
axioms (1)
- domain assumption Pairwise comparisons from judges or models reliably capture subjective preferences for open-ended responses.
read the original abstract
Current reinforcement learning(RL) methods are broadly applicable and powerful in verifiable settings where scalar rewards can be provided. However, in open-ended generation tasks, verifying the correctness of responses remains challenging, and training reward models incurs substantial computational and annotation costs. Moreover, reinforcement learning (RLVR) often leads to diversity collapse and produces stereotypical or rigid outputs, outcomes that are particularly undesirable in open-domain scenarios. We propose Pairwise Preference Reward and Group-based Diversity Enhancement (PPR-GDE), a RL method that is more suitable for open-ended generation. PPR-GDE does not require scalar rewards and incorporates group-level diversity into the reward signal, it preserves the comparative structure of subjective evaluation through a pairwise preference reward, mitigates judge position bias via repeated comparisons with swapped response order, and introduces a group-based diversity reward that explicitly encourages semantic dispersion within a response group, all of these reward signals are integrated into a unified group-relative policy optimization objective. We instantiate PPR-GDE on role-playing task, experiments show that PPR-GDE achieves a better alignment quality as well as expressive diversity than strong RL baselines. Further analysis shows that pairwise preference is critical for preference alignment in subjective perspective, while the diversity metric plays an essential role in achieving superior expressive diversity and broader semantic coverage.
Figures


Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Wang, Noah and Peng, Z. Y. and Que, Haoran and Liu, Jiaheng and Zhou, Wangchunshu and Wu, Yuhan and Guo, Hongcheng and Gan, Ruitong and Ni, Zehao and Yang, Jian and Zhang, Man and Zhang, Zhaoxiang and Ouyang, Wanli and Xu, Ke and Huang, Wenhao and Fu, Jie and Peng, Junran , title =. Findings of the Association for Computational Linguistics: ACL 2024 , year =
work page 2024
-
[3]
Tu, Quan and Fan, Shilong and Tian, Zihang and Shen, Tianhao and Shang, Shuo and Gao, Xin and Yan, Rui , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[4]
Sakai, Yusuke and Kamigaito, Hidetaka and Watanabe, Taro. m CSQA : Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.844
-
[5]
A Diversity-Promoting Objective Function for Neural Conversation Models
Li, Jiwei and Galley, Michel and Brockett, Chris and Gao, Jianfeng and Dolan, Bill. A Diversity-Promoting Objective Function for Neural Conversation Models. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1014
-
[6]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[7]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
-
[10]
Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for
Wu, Tianhao and Zhu, Banghua and Zhang, Ruoyu and Wen, Zhaojin and Ramchandran, Kannan and Jiao, Jiantao , journal =. Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for
-
[11]
International Conference on Learning Representations , year =
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations , year =
-
[12]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =
-
[13]
International Conference on Machine Learning , pages =
Understanding the Impact of Entropy on Policy Optimization , author =. International Conference on Machine Learning , pages =
-
[14]
arXiv preprint arXiv:2402.06700 , year =
Entropy-Regularized Token-Level Policy Optimization for Language Agent Reinforcement , author =. arXiv preprint arXiv:2402.06700 , year =
-
[15]
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , title =. Advances in Neural Information Processing Systems , year =
-
[16]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Cui, Ganqu and Zhang, Yuchen and Chen, Jiacheng and Yuan, Lifan and Wang, Zhi and Zuo, Yuxin and Li, Haozhan and Fan, Yuchen and Chen, Huayu and Chen, Weize and Liu, Zhiyuan and Peng, Hao and Bai, Lei and Ouyang, Wanli and Cheng, Yu and Zhou, Bowen and Ding, Ning , title =. arXiv preprint arXiv:2505.22617 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Reasoning with Exploration: An Entropy Perspective
Cheng, Daixuan and Huang, Shaohan and Zhu, Xuekai and Dai, Bo and Zhao, Wayne Xin and Zhang, Zhenliang and Wei, Furu , title =. arXiv preprint arXiv:2506.14758 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Judging the judges: A systematic study of position bias in llm-as-a-judge, 2025
Shi, Lin and Ma, Chiyu and Liang, Wenhua and Diao, Xingjian and Ma, Weicheng and Vosoughi, Soroush , title =. arXiv preprint arXiv:2406.07791 , year =
-
[19]
Fine-Tuning Language Models from Human Preferences
Ziegler, Daniel M. and Stiennon, Nisan and Wu, Jeffrey and Brown, Tom B. and Radford, Alec and Amodei, Dario and Christiano, Paul and Irving, Geoffrey , title =. arXiv preprint arXiv:1909.08593 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul F
Stiennon, Nisan and Ouyang, Long and Wu, Jeff and Ziegler, Daniel M. and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul F. , title =. Advances in Neural Information Processing Systems , year =
-
[21]
Shi, Lin and Ma, Chiyu and Liang, Wenhua and Diao, Xingjian and Ma, Weicheng and Vosoughi, Soroush , title =. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , year =
-
[22]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2504.04950 , year =
A unified pairwise framework for rlhf: Bridging generative reward modeling and policy optimization , author=. arXiv preprint arXiv:2504.04950 , year=
-
[24]
Group Sequence Policy Optimization
Zheng, Chujie and Liu, Shixuan and Li, Mingze and Chen, Xiong-Hui and Yu, Bowen and Gao, Chang and Dang, Kai and Liu, Yuqiong and Men, Rui and Yang, An and Zhou, Jingren and Lin, Junyang , title =. arXiv preprint arXiv:2507.18071 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.