TextClusterLab: An Integrated Framework for Reliable Text Clustering Studies
Pith reviewed 2026-06-30 19:02 UTC · model grok-4.3
The pith
TextClusterLab uses an LLM to generate synthetic text datasets with adjustable clustering attributes and includes a benchmark to assess their suitability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TextClusterLab offers a Large Language Model (LLM)-driven text clustering dataset generator to produce synthetic text datasets for evaluating clustering algorithms. This generator supports setting various clustering attributes, such as class imbalance, intra-cluster compactness, and inter-cluster diversity. These generated datasets can serve as practical benchmarks for testing the robustness and versatility of text clustering algorithms in diverse scenarios. Moreover, the paper introduces a benchmark to verify whether a text dataset is suitable for clustering evaluation.
What carries the argument
The LLM-driven dataset generator that produces text data with specified clustering attributes, supported by a suitability verification benchmark.
If this is right
- Clustering algorithms can be tested for robustness under controlled class imbalance conditions.
- Performance can be evaluated at different levels of intra-cluster compactness and inter-cluster diversity.
- Synthetic datasets provide a way to create reproducible benchmarks without depending on real-world data limitations.
- The suitability benchmark helps filter out unsuitable datasets for more reliable evaluations.
Where Pith is reading between the lines
- If successful, this could standardize how text clustering methods are compared across studies.
- Researchers might use the generator to create datasets for related tasks like topic modeling or intent detection.
- Comparing algorithm performance on these synthetic sets versus real data could reveal strengths and weaknesses in current methods.
Load-bearing premise
That datasets generated by LLMs can faithfully capture the ambiguous semantic boundaries and inconsistent structures of actual text data, and that the benchmark accurately identifies suitable ones.
What would settle it
Demonstrating that text clustering algorithms yield significantly different results or rankings on the generated datasets compared to real-world text datasets with matched attributes.
Figures

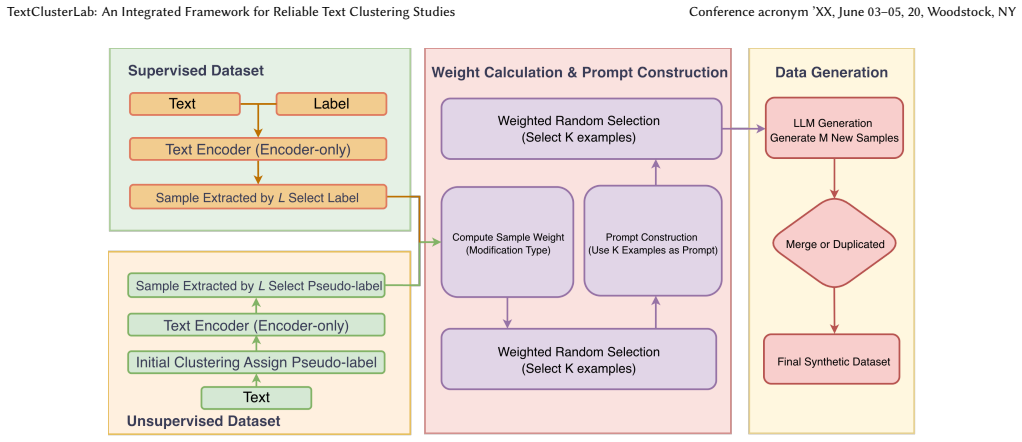
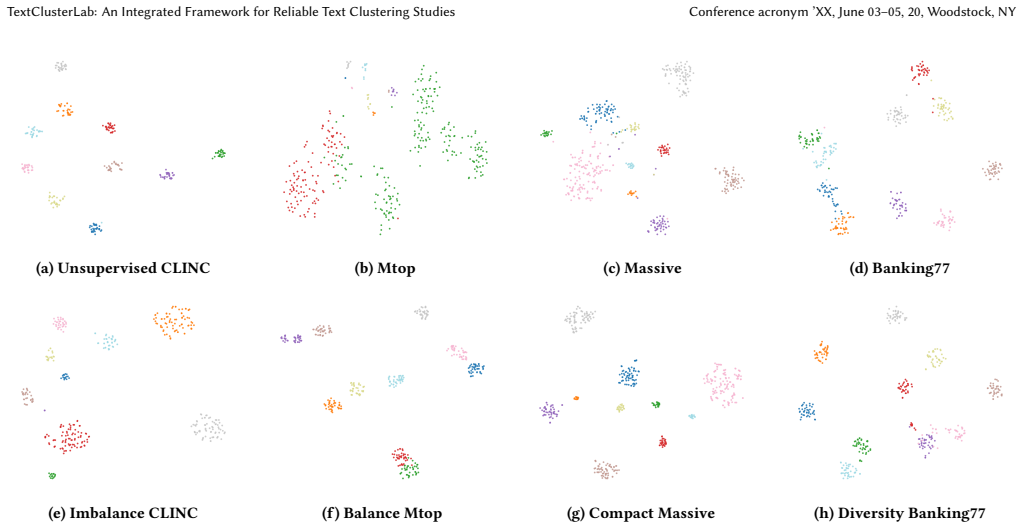
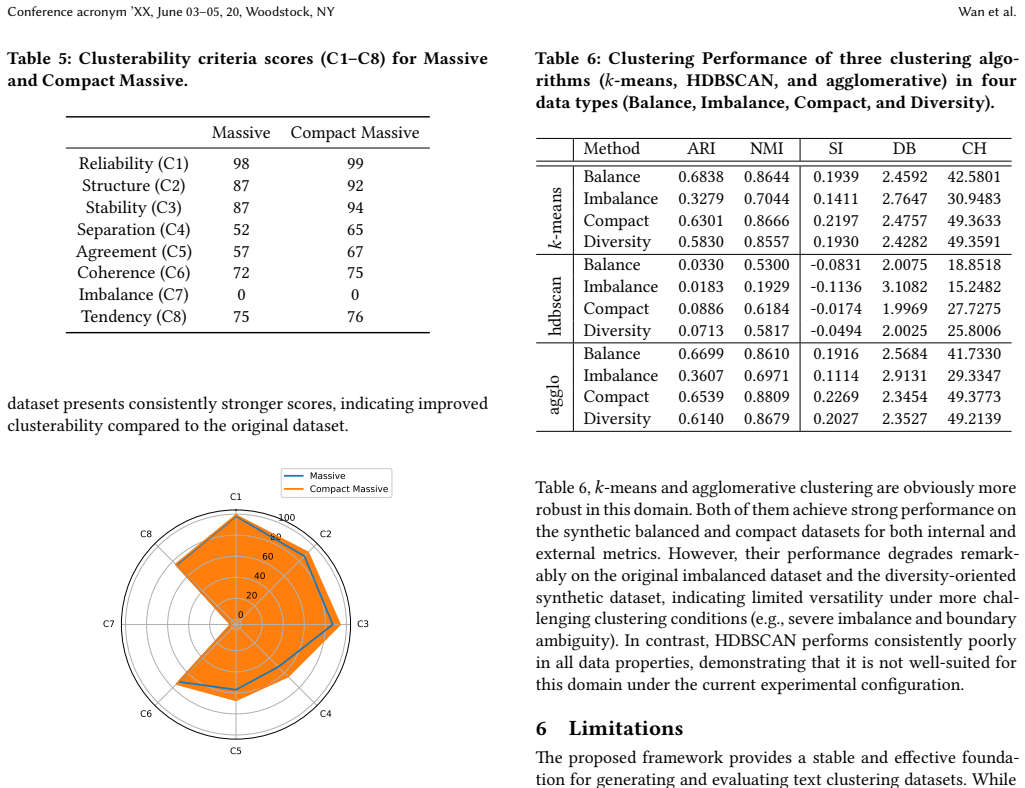
read the original abstract
In recent years, text clustering has become a critical technique for applications including intent discovery, topic mining, and recommendation systems. However, evaluating text clustering algorithms remains challenging since many real-world textual datasets are not suitable for clustering assessment due to ambiguous semantic boundaries, the high dimensionality of embeddings, and inconsistent cluster structure. Current clustering dataset generators are designed for numerical data, providing limited support for text-specific benchmarking. This paper introduces TextClusterLab, a comprehensive framework for text clustering research. TextClusterLab offers a Large Language Model (LLM)-driven text clustering dataset generator to produce synthetic text datasets for evaluating clustering algorithms. This generator supports setting various clustering attributes, such as class imbalance, intra-cluster compactness, and inter-cluster diversity. These generated datasets can serve as practical benchmarks for testing the robustness and versatility of text clustering algorithms in diverse scenarios. Moreover, we introduce a benchmark to verify whether a text dataset is suitable for clustering evaluation. Therefore, TextClusterLab provides an integrated framework for reproducible and comprehensive text-specific clustering research. Our TextClusterLab is publicly available at https://github.com/research-paper-code/TextClusterLab, and some synthetic example datasets with various attributes are publicly available at https://huggingface.co/datasets/DW-irlab/TextClusterLab.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TextClusterLab, an integrated framework for text clustering research consisting of an LLM-driven generator for synthetic text datasets that supports controllable attributes including class imbalance, intra-cluster compactness, and inter-cluster diversity, plus a benchmark to assess whether a given text dataset is suitable for clustering evaluation. The framework is positioned as addressing the limitations of real-world text data (ambiguous boundaries, high dimensionality, inconsistent structure) and the lack of text-specific generators, with code and example datasets released publicly.
Significance. If the generator produces datasets whose properties match real text clustering challenges and the suitability benchmark is shown to predict algorithm performance, the framework could enable more reproducible and controlled benchmarking in text clustering, a gap not filled by numerical dataset generators. The explicit public release of code at the cited GitHub repository and datasets on Hugging Face is a clear strength supporting reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that the LLM-driven generator 'can serve as practical benchmarks for testing the robustness and versatility of text clustering algorithms' and that the suitability benchmark verifies appropriateness rests on no reported validation results, error analysis, or comparisons to real corpora (e.g., no embedding statistics, human judgments of boundary ambiguity, or downstream NMI/ARI agreement with established datasets such as 20 Newsgroups).
- [Abstract (generator description)] The manuscript supplies no quantitative checks that the controllable attributes (class imbalance, intra-cluster compactness, inter-cluster diversity) produce datasets whose semantic ambiguity and cluster inconsistency match real-world text data, which is load-bearing for the motivation and usefulness claim.
minor comments (2)
- [Framework description] The description of the LLM prompting strategy and exact attribute control mechanisms is not detailed enough to allow reproduction from the text alone.
- [Introduction] No references are provided to prior text-specific clustering benchmarks or synthetic data generators in IR/NLP literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly note the absence of empirical validation in the current manuscript. We address each point below and will revise accordingly to include quantitative checks and comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the LLM-driven generator 'can serve as practical benchmarks for testing the robustness and versatility of text clustering algorithms' and that the suitability benchmark verifies appropriateness rests on no reported validation results, error analysis, or comparisons to real corpora (e.g., no embedding statistics, human judgments of boundary ambiguity, or downstream NMI/ARI agreement with established datasets such as 20 Newsgroups).
Authors: We agree that the abstract claims would be more robust with supporting validation. The manuscript currently focuses on describing the framework, generator controls, and suitability benchmark without systematic empirical comparisons. In revision we will add an evaluation section reporting embedding statistics, NMI/ARI agreement between generated and real datasets (including 20 Newsgroups), and limited human judgments of boundary ambiguity where feasible. revision: yes
-
Referee: [Abstract (generator description)] The manuscript supplies no quantitative checks that the controllable attributes (class imbalance, intra-cluster compactness, inter-cluster diversity) produce datasets whose semantic ambiguity and cluster inconsistency match real-world text data, which is load-bearing for the motivation and usefulness claim.
Authors: The referee correctly identifies that no quantitative verification is provided showing how the tunable attributes replicate real-world semantic properties. The generator relies on LLM prompting to enforce the attributes, but the manuscript does not measure resulting ambiguity or inconsistency against real corpora. The revised version will include experiments that vary these parameters and report clustering metrics plus direct comparisons to real text datasets to substantiate the motivation. revision: yes
Circularity Check
No circularity: framework contribution with no derivations or fitted predictions
full rationale
The paper introduces a software framework (TextClusterLab) consisting of an LLM-driven dataset generator and a suitability benchmark. No mathematical derivations, equations, fitted parameters, or predictions are described that could reduce to inputs by construction. The central claims concern the existence and utility of the tool itself rather than any result derived from prior outputs or self-referential definitions. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. This is a standard non-circular engineering/software contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andreas Adolfsson, Margareta Ackerman, and Naomi C Brownstein. 2019. To cluster, or not to cluster: An analysis of clusterability methods. Pattern Recogni- tion 88 (2019), 13–26
2019
-
[2]
Charu C Aggarwal and ChengXiang Zhai. 2012. A survey of text clustering algorithms. In Mining text data. Springer, 77–128
2012
-
[3]
Majid Hameed Ahmed, Sabrina Tiun, Nazlia Omar, and Nor Samsiah Sani. 2022. Short text clustering algorithms, application and challenges: A survey. Applied Sciences 13, 1 (2022), 342
2022
-
[4]
AH Aziira, NA Setiawan, and I Soesanti. 2020. Generation of synthetic continu- ous numerical data using generative adversarial networks. In Journal of Physics: Conference Series, Vol. 1577. IOP Publishing, 012027
2020
-
[5]
Shai Ben-David, Ulrike Von Luxburg, and Dávid Pál. 2006. A sober look at clustering stability. In International conference on computational learning theory . Springer, 5–19
2006
-
[6]
Iñigo Casanueva, Tadas Temčinas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. 2020. Efficient Intent Detection with Dual Sentence Encoders. In Proceed- ings of the 2nd Workshop on Natural Language Processing for Conversational AI . Association for Computational Linguistics, Online, 38–45. doi:10.18653/v1/2020 .nlp4convai-1.5
-
[7]
Inigo Casanueva, Ivan Vulić, Georgios Spithourakis, and Paweł Budzianowski
-
[8]
In Findings of the Association for Com- putational Linguistics: NAACL 2022
NLU++: A multi-label, slot-rich, generalisable dataset for natural language understanding in task-oriented dialogue. In Findings of the Association for Com- putational Linguistics: NAACL 2022 . 1998–2013
2022
-
[9]
Zhiyuan Chen and Bing Liu. 2014. Mining topics in documents: standing on the shoulders of big data. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining . 1116–1125
2014
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Under- standing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) . Association for Com...
-
[11]
Xin Du and Kumiko Tanaka-Ishii. 2025. Information-Theoretic Generative Clus- tering of Documents. In Proceedings of the AAAI Conference on Artificial Intelli- gence, Vol. 39. 16408–16417
2025
-
[12]
Zijin Feng, Luyang Lin, Lingzhi Wang, Hong Cheng, and Kam-Fai Wong. 2024. LLMEdgeRefine: Enhancing Text Clustering with LLM-Based Boundary Point Refinement. In Proceedings of the 2024 Conference on Empirical Methods in Nat- ural Language Processing . Association for Computational Linguistics, Miami, Florida, USA, 18455–18462. doi:10.18653/v1/2024.emnlp-main.1025
-
[13]
Jack FitzGerald, Christopher Hench, Charith Peris, Scott Mackie, Kay Rottmann, Ana Sanchez, Aaron Nash, Liam Urbach, Vishesh Kakarala, Richa Singh, Swetha Ranganath, Laurie Crist, Misha Britan, Wouter Leeuwis, Gokhan Tur, and Prem Natarajan. 2023. MASSIVE: A 1M-Example Multilingual Natural Language Un- derstanding Dataset with 51 Typologically-Diverse Lan...
-
[14]
Mandeep Goyal and Qusay H Mahmoud. 2024. A systematic review of synthetic data generation techniques using generative AI. Electronics 13, 17 (2024), 3509
2024
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, et al. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv: 2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Mengze Hong, Wailing Ng, Chen Jason Zhang, Yuanfeng Song, and Di Jiang
-
[17]
In Proceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing
Dial-In LLM: Human-Aligned LLM-in-the-loop Intent Clustering for Cus- tomer Service Dialogues. In Proceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing . Association for Computational Linguistics, Suzhou, China, 5885–5900. doi:10.18653/v1/2025.emnlp-main.300
-
[18]
Anil K Jain, M Narasimha Murty, and Patrick J Flynn. 1999. Data clustering: a review. ACM computing surveys (CSUR) 31, 3 (1999), 264–323
1999
-
[19]
Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K
Stefan Larson, Anish Mahendran, Joseph J. Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K. Kummerfeld, Kevin Leach, Michael A. Laurenzano, Lingjia Tang, and Jason Mars. 2019. An Evaluation Dataset for Intent Classifica- tion and Out-of-Scope Prediction. In Proceedings of the 2019 Conference on Empir- ical Methods in Natural Language Process...
-
[20]
Haoran Li, Abhinav Arora, Shuohui Chen, Anchit Gupta, Sonal Gupta, and Yashar Mehdad. 2021. MTOP: A Comprehensive Multilingual Task-Oriented Se- mantic Parsing Benchmark. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume . Associa- tion for Computational Linguistics, Online, 2950–29...
- [21]
-
[22]
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. 2024. On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, Bangkok, Thailand, 11065– 11082. doi:10.18653/v1/2024.findings-acl.658
-
[23]
Volodymyr Melnykov, Wei-Chen Chen, and Ranjan Maitra. 2012. MixSim: An R package for simulating data to study performance of clustering algorithms. Journal of Statistical Software 51 (2012), 1–25
2012
- [24]
-
[25]
Guillermo Ortiz-Jimenez, Mark Collier, Anant Nawalgaria, Alexander Nicholas D’Amour, Jesse Berent, Rodolphe Jenatton, and Efi Kokiopoulou. 2023. When does privileged information explain away label noise?. In International Confer- ence on Machine Learning . PMLR, 26646–26669
2023
-
[26]
Gyutae Park, Ingeol Baek, ByeongJeong Kim, Joongbo Shin, and Hwanhee Lee
-
[27]
In Proceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 2: Short Papers)
Dynamic Label Name Refinement for Few-Shot Dialogue Intent Classifi- cation. In Proceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 2: Short Papers) . 41–52
-
[28]
June Young Park, Evan Mistur, Donghwan Kim, Yunjeong Mo, and Richard Hoe- fer. 2022. Toward human-centric urban infrastructure: Text mining for social media data to identify the public perception of COVID-19 policy in transporta- tion hubs. Sustainable Cities and Society 76 (2022), 103524
2022
-
[29]
Alina Petukhova, Joao P Matos-Carvalho, and Nuno Fachada. 2025. Text cluster- ing with large language model embeddings. International Journal of Cognitive Computing in Engineering 6 (2025), 100–108
2025
-
[30]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Conference on Empirical Methods in Natural Lan- guage Processing (2019). doi:10.18653/v1/D19-1410
-
[31]
Yazhou Ren, Jingyu Pu, Zhimeng Yang, Jie Xu, Guofeng Li, Xiaorong Pu, Philip S Yu, and Lifang He. 2024. Deep clustering: A comprehensive survey. IEEE trans- actions on neural networks and learning systems 36, 4 (2024), 5858–5878
2024
-
[32]
Cameron Shand, Richard Allmendinger, Julia Handl, Andrew Webb, and John Keane. 2021. HA WKS: Evolving challenging benchmark sets for cluster analysis. IEEE Transactions on Evolutionary Computation 26, 6 (2021), 1206–1220
2021
-
[33]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2023. One Em- bedder, Any Task: Instruction-Finetuned Text Embeddings. In Findings of the Association for Computational Linguistics: ACL 2023 , Anna Rogers, Jordan Boyd- Graber, and Naoaki Okazaki (Eds.). Association for C...
-
[34]
Henrique Schechter Vera, Sahil Dua, et al. 2025. EmbeddingGemma: Powerful and Lightweight Text Representations. arXiv preprint arXiv: 2509.20354 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual E5 Text Embeddings: A Technical Report. arXiv preprint arXiv: 2402.05672 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Di Wu, Ruiyu Fang, Liting Jiang, Shuangyong Song, Xiaomeng Huang, Shiquan Wang, Zhongqiu Li, Lingling Shi, Mengjiao Bao, Yongxiang Li, et al. 2025. Multi- intent spoken language understanding: a survey of methods, trends, and chal- lenges. Vicinagearth 2, 1 (2025), 20
2025
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, et al. 2025. Qwen3 Technical Report. arXiv preprint arXiv: 2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Zhao Yang, René Algesheimer, and Claudio J Tessone. 2016. A comparative anal- ysis of community detection algorithms on artificial networks. Scientific reports 6, 1 (2016), 30750
2016
-
[39]
Jianhua Yin and Jianyong Wang. 2014. A dirichlet multinomial mixture model- based approach for short text clustering. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining . 233–242
2014
-
[40]
Michael J Zellinger and Peter Bühlmann. 2025. Natural Language-Based Syn- thetic Data Generation for Cluster Analysis. Journal of Classification (2025), 1– 27
2025
-
[41]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jin- gren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Rerank- ing Through Foundation Models. arXiv preprint arXiv:2506.05176 (2025). Conference acronym ’XX, June 03–05, 20, Woodstock, NY Wan et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yuwei Zhang, Zihan Wang, and Jingbo Shang. 2023. ClusterLLM: Large Lan- guage Models as a Guide for Text Clustering. In Proceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing . Association for Com- putational Linguistics, Singapore, 13903–13920. doi:10.18653/v1/2023.emnlp- main.858
-
[43]
Sheng Zhou, Hongjia Xu, Zhuonan Zheng, Jiawei Chen, Zhao Li, Jiajun Bu, Jia Wu, Xin Wang, Wenwu Zhu, and Martin Ester. 2024. A Comprehensive Sur- vey on Deep Clustering: Taxonomy, Challenges, and Future Directions. ACM Comput. Surv. 57, 3, Article 69 (Nov. 2024), 38 pages. doi:10.1145/3689036 TextClusterLab: An Integrated Framework for Reliable Text Clust...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.