Technical Report of RoboSpatial Challenge at CVPR 2026: Selective Reasoning Activation and Reference-Frame Disambiguation for Embodied Spatial Reasoning
Pith reviewed 2026-07-01 06:08 UTC · model grok-4.3
The pith
RoboSpatialBrain wins the RoboSpatial Challenge at 80.9 percent by activating deliberate reasoning and redirecting reference frames at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
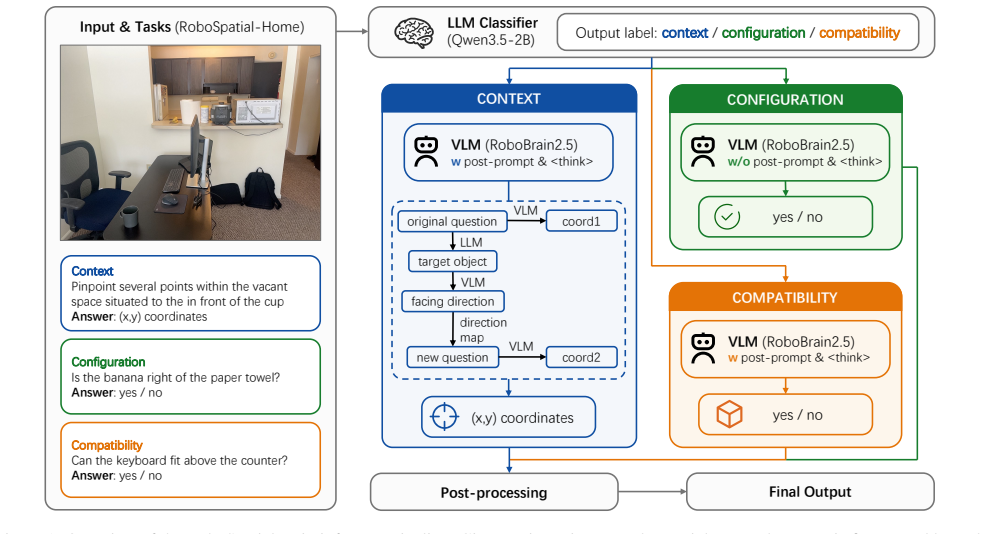
RoboSpatialBrain adds a forced <think> prefix activation strategy with a task-specific post-prompt to produce deliberate reasoning on context and compatibility tasks, together with an explicit reference-frame redirection pipeline that resolves camera-centric and object-centric ambiguity on context tasks; when built on RoboBrain2.5-8B-NV these mechanisms yield first place in the RoboSpatial Challenge with an 80.9 percent overall success rate on RoboSpatial-Home.
What carries the argument
The selective reasoning activation via forced <think> prefix paired with a reference-frame redirection pipeline that switches between camera-centric and object-centric views.
If this is right
- Training-free inference mechanisms can raise success rates on embodied spatial reasoning benchmarks to first-place levels.
- Reference-frame redirection specifically improves performance on context tasks by removing camera versus object ambiguity.
- Fine-tuning on compatibility data can be combined with the prompting strategy and the interaction between them can be measured.
- The overall system reaches 80.9 percent success without additional training for the main mechanisms.
Where Pith is reading between the lines
- The same prefix and redirection steps could be tested on other vision-language tasks that require perspective shifts or multi-step spatial planning.
- Running the method on physical robots would show whether benchmark gains appear in real navigation and manipulation.
- Comparing the approach on models of different sizes would indicate how much the gains depend on the particular base model chosen.
Load-bearing premise
The reported performance gain comes from the selective reasoning activation and reference-frame redirection rather than from the base model, benchmark design, or evaluation protocol.
What would settle it
An ablation that runs the identical base model on the same RoboSpatial-Home test set but removes both the forced <think> prefix with post-prompt and the reference-frame redirection, then checks whether success rate drops substantially below 80.9 percent.
Figures

read the original abstract
Vision-language models achieve strong general perception but often struggle with the spatial reasoning required for embodied tasks. We present RoboSpatialBrain, our submission to the RoboSpatial Challenge at the Embodied Reasoning in Action Workshop, CVPR 2026, built on RoboBrain2.5-8B-NV. RoboSpatialBrain combines two training-free, inference-time mechanisms: a forced <think> prefix activation strategy paired with a task-specific post-prompt that elicits deliberate reasoning on context and compatibility tasks, and an explicit reference-frame redirection pipeline that resolves camera-centric and object-centric ambiguity for context tasks. We additionally explore fine-tuning RoboBrain2.5 on compatibility data and present a detailed analysis of its interaction with prompting. RoboSpatialBrain achieved first place in the RoboSpatial Challenge, with an overall success rate of 80.9\% on RoboSpatial-Home. Code is available at https://github.com/YuxiangXie2003/RoboSpatialBrain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RoboSpatialBrain, a submission to the RoboSpatial Challenge at CVPR 2026 built on RoboBrain2.5-8B-NV. It combines two training-free inference-time mechanisms—a forced <think> prefix paired with a task-specific post-prompt to elicit deliberate reasoning, and an explicit reference-frame redirection pipeline to resolve camera- and object-centric ambiguity—along with optional fine-tuning on compatibility data. The system is reported to have achieved first place with an overall success rate of 80.9% on RoboSpatial-Home; code is released.
Significance. If the performance gain can be attributed to the proposed mechanisms, the work illustrates practical, training-free interventions that improve embodied spatial reasoning in existing vision-language models. The first-place benchmark result supplies a concrete empirical demonstration, and the public code release aids reproducibility.
major comments (3)
- [Abstract] Abstract: the headline claim that the two mechanisms produce the 80.9% first-place score is not supported by any controlled ablation that compares RoboBrain2.5-8B-NV with versus without the forced <think> prefix/post-prompt or the reference-frame redirection pipeline under identical inference settings.
- [Results] Results section: no error bars, multiple random seeds, or statistical tests accompany the 80.9% success rate, so the reliability of the ranking and the magnitude of any improvement cannot be assessed.
- [Methods] Methods and analysis: the reported interaction between fine-tuning and prompting does not include a quantitative isolation of the reference-frame redirection pipeline’s contribution on context tasks versus other prompt variations or base-model behavior.
minor comments (2)
- The exact wording of the forced <think> prefix and task-specific post-prompt templates should be provided verbatim to allow replication.
- A brief description of the RoboSpatial-Home task distribution and evaluation protocol would help readers interpret the 80.9% figure.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. Below we provide point-by-point responses to the major comments, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the two mechanisms produce the 80.9% first-place score is not supported by any controlled ablation that compares RoboBrain2.5-8B-NV with versus without the forced <think> prefix/post-prompt or the reference-frame redirection pipeline under identical inference settings.
Authors: The abstract presents RoboSpatialBrain as the system that combines the two mechanisms with the base model to achieve the reported score. We did not perform controlled ablations isolating each component under identical settings, as the primary goal was to develop a competitive challenge submission. To address the concern, we will revise the abstract to state that the 80.9% score was achieved by the RoboSpatialBrain system incorporating these mechanisms, rather than implying direct causation without supporting experiments. We will also add a brief note on the lack of such ablations. revision: yes
-
Referee: [Results] Results section: no error bars, multiple random seeds, or statistical tests accompany the 80.9% success rate, so the reliability of the ranking and the magnitude of any improvement cannot be assessed.
Authors: The success rate of 80.9% is the official result from the single evaluation run on the RoboSpatial-Home benchmark as per the challenge rules. Challenge submissions are typically not accompanied by statistical analyses like error bars or multiple seeds because the test set is fixed and evaluation is deterministic for the submitted system. We will update the results section to explicitly note this context and clarify that the ranking is based on the official challenge leaderboard. revision: partial
-
Referee: [Methods] Methods and analysis: the reported interaction between fine-tuning and prompting does not include a quantitative isolation of the reference-frame redirection pipeline’s contribution on context tasks versus other prompt variations or base-model behavior.
Authors: Our analysis discusses the combined effects of fine-tuning on compatibility data and the prompting strategies, including the reference-frame redirection. However, we agree that a more isolated quantification of the redirection pipeline's contribution would strengthen the paper. We will revise the methods and analysis sections to include additional experiments or comparisons that isolate the redirection pipeline on context tasks, comparing against base model and other prompt variations where feasible. revision: yes
Circularity Check
No circularity: empirical benchmark result with no derivation chain
full rationale
The paper reports an empirical success rate (80.9% on RoboSpatial-Home) from a challenge submission built on an existing base model plus two described inference-time mechanisms. No equations, fitted parameters, or predictions are presented; the central claim is a measured performance metric rather than a constructed derivation. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way that reduces the result to its inputs by construction. The result is therefore self-contained as an external benchmark outcome.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 14455– 14465, 2024. 1
2024
-
[3]
What’s “up” with vision-language models? investigating their strug- gle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? investigating their strug- gle with spatial reasoning. InEMNLP, 2023. 1
2023
-
[4]
Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models, 2025
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models, 2025. 1
2025
-
[5]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 33:3776–3786, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 33:3776–3786, 2025. 4
2025
-
[6]
RoboSpatial: Teaching spatial understanding to 2D and 3D vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. RoboSpatial: Teaching spatial understanding to 2D and 3D vision-language models for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. Oral Presentation. 1, 4
2025
-
[7]
Robobrain 2.5: Depth in sight, time in mind.arXiv preprint arXiv:2601.14352,
Huajie Tan, Enshen Zhou, Zhiyu Li, Yijie Xu, Yuheng Ji, Xiansheng Chen, Cheng Chi, Pengwei Wang, Huizhu Jia, Yulong Ao, Mingyu Cao, Sixiang Chen, Zhe Li, Mengzhen Liu, Zixiao Wang, Shanyu Rong, Yaoxu Lyu, Zhongxia Zhao, Peterson Co, Yibo Li, Yi Han, Shaoxuan Xie, Guocai Yao, Songjing Wang, Leiduo Zhang, Xi Yang, Yance Jiao, Donghai Shi, Kunchang Xie, Shao...
-
[8]
Qwen3.5: Accelerating productivity with na- tive multimodal agents, 2026
Qwen Team. Qwen3.5: Accelerating productivity with na- tive multimodal agents, 2026. 3
2026
-
[9]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3, 4
2024
-
[10]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023. 4 Technical Report of RoboSpatial Challenge at CVPR 2026: Selective Reasoning Activation and Reference-Frame Disambiguation for Embodied...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.