Gatekeepers and Hallucinations: A Layered Evaluation Framework for LLM-Driven Quantum Circuit Generation
Pith reviewed 2026-06-27 00:12 UTC · model grok-4.3
The pith
LLM outputs for quantum circuits in materials simulations require gatekeeper validation to catch inherent failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
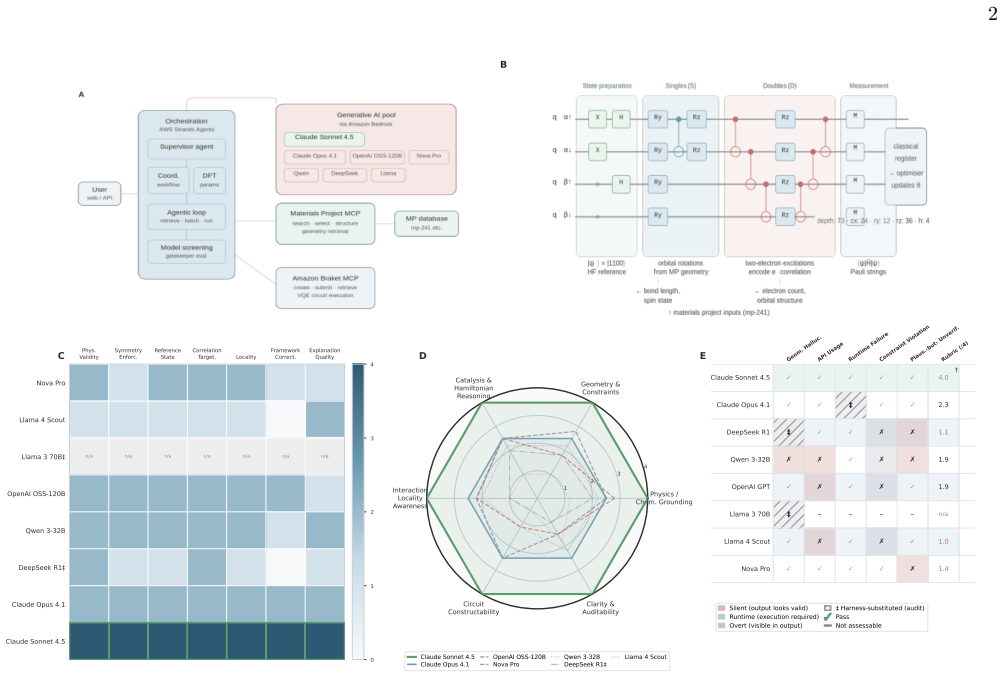
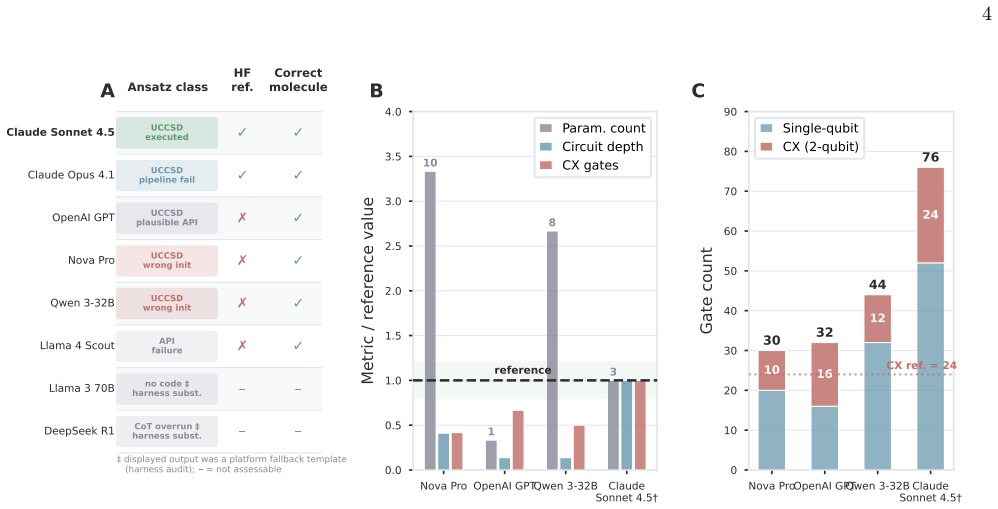
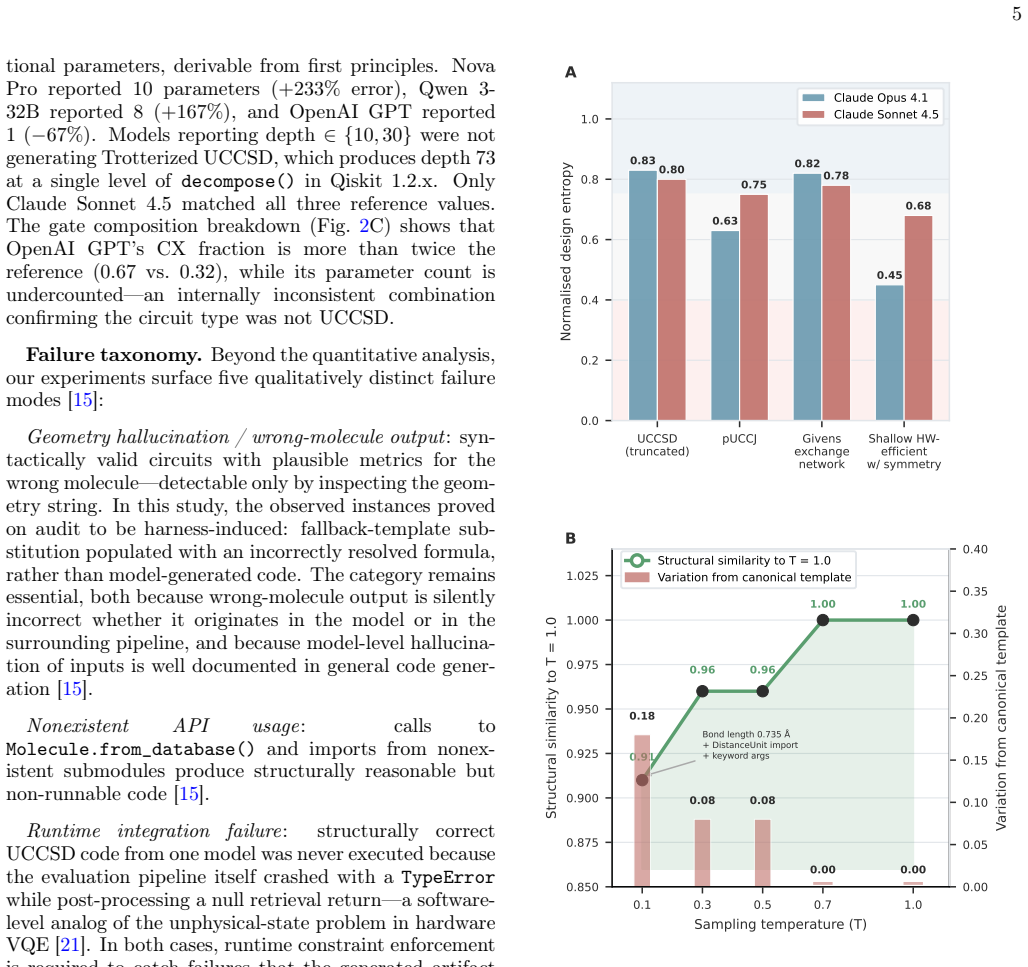
The central claim is that a multi-layered evaluation framework, including gatekeeper screening, circuit fidelity analysis, and design entropy, reveals five structural failure modes in LLM-driven quantum circuit generation for VQE on materials like H2, making gatekeeper-style validation necessary rather than optional for reliable deployment across multiple foundation models. A forensic audit of the evaluation platform further shows that some failures originate in the harness infrastructure, placing it within the same trust boundary.
What carries the argument
The layered evaluation framework consisting of a gatekeeper screening rubric across seven physical and framework criteria, circuit fidelity analysis against reference implementations, and design entropy as a run-to-run consistency metric.
If this is right
- Gatekeeper validation must be integrated into LLM-driven quantum workflows to prevent propagation of errors through simulation pipelines.
- Evaluation infrastructure requires its own forensic auditing because silent substitutions can mimic model failures.
- The five failure modes each carry distinct detectability profiles that call for targeted checks rather than single-point verification.
- Design entropy serves as a practical metric for quantifying behavioral consistency in repeated circuit generation runs.
- The framework applies directly to Materials Project integrated pipelines for ansatze such as UCCSD on small molecules like H2.
Where Pith is reading between the lines
- The taxonomy of failure modes could guide creation of targeted fine-tuning datasets for quantum code generation tasks.
- Similar layered screening might transfer to LLM-assisted code generation in other domains where verification carries high computational cost.
- Direct embedding of gatekeeper logic into agentic pipelines could enable iterative self-correction during circuit synthesis.
- Testing the framework on larger molecules would show whether failure rates scale with system size or remain task-inherent.
Load-bearing premise
The five failure modes are structural to the task of LLM-driven quantum circuit generation rather than specific to any one model.
What would settle it
A demonstration that all five failure modes can be eliminated in a production pipeline using a single foundation model without any gatekeeper screening, or conversely, that a model exhibits none of them on repeated trials for the H2 VQE task.
Figures
read the original abstract
As large language models (LLMs) become embedded in quantum simulation workflows (IDE copilots, notebook assistants, agentic pipelines), evaluation must move beyond functional correctness to anticipate and catch structured failures before they propagate through expensive pipelines. We present a layered evaluation framework for materials-informed Variational Quantum Eigensolver (VQE) circuit generation: (i) a gatekeeper screening rubric across seven physical and framework criteria; (ii) a circuit fidelity analysis comparing model outputs against analytical and reference-implementation values for H2/STO-3G/Jordan-Wigner/UCCSD, with ansatz classification and gate-composition breakdown; and (iii) design entropy, a run-to-run behavioral consistency metric. We surface a taxonomy of five distinct LLM failure modes (geometry hallucination, nonexistent API usage, runtime integration failures, constraint violations, and plausible-but-unverifiable output), each with distinct detectability profiles and structural to the task rather than to any one model. A forensic audit of the evaluation platform's own source code further establishes that two apparent model failures originated in the harness through silent fallback-template substitution, demonstrating that evaluation infrastructure belongs inside the same trust boundary as the models it tests. Applied across multiple foundation models on a Materials Project integrated pipeline, the framework shows that gatekeeper-style validation is necessary, not optional, for reliable deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a layered evaluation framework for LLM-generated quantum circuits in materials-informed VQE workflows. It defines a seven-criteria gatekeeper rubric, a circuit fidelity analysis against reference H2/STO-3G/UCCSD implementations, and a 'design entropy' consistency metric. The work reports a taxonomy of five failure modes (geometry hallucination, nonexistent API usage, runtime integration failures, constraint violations, plausible-but-unverifiable output) claimed to be structural to the task, presents a forensic audit revealing two harness-induced failures, and concludes that gatekeeper-style validation is necessary rather than optional when the framework is applied across multiple foundation models on a Materials Project pipeline.
Significance. If the observed failure modes prove structural and the gatekeeper rubric demonstrably catches outputs that would pass functional-correctness checks, the framework could improve reliability of LLM-assisted quantum simulation pipelines. The self-audit of the evaluation harness itself is a methodological strength that places infrastructure inside the trust boundary. However, the absence of quantitative results, error bars, cross-model tabulations, or explicit counts of gatekeeper-rejected outputs limits the ability to assess whether the necessity claim holds beyond high-level description.
major comments (2)
- [Abstract] Abstract (final paragraph): the claim that the five failure modes are 'structural to the task rather than to any one model' is not supported by any tabulated cross-model breakdown, controls for prompt or harness variation, or explicit count of outputs that would have passed a standard functional-correctness check but failed the seven-criteria gatekeeper rubric; without these data the necessity conclusion rests on descriptive assertion alone.
- [Abstract] Abstract: the forensic audit finding that two failures originated in the harness is presented without accompanying totals (e.g., total model outputs examined, fraction attributable to harness vs. model), making it impossible to evaluate the relative contribution of infrastructure errors to the reported failure taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that the abstract claims would benefit from additional quantitative support.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that the five failure modes are 'structural to the task rather than to any one model' is not supported by any tabulated cross-model breakdown, controls for prompt or harness variation, or explicit count of outputs that would have passed a standard functional-correctness check but failed the seven-criteria gatekeeper rubric; without these data the necessity conclusion rests on descriptive assertion alone.
Authors: The manuscript applies the framework to multiple foundation models within the Materials Project pipeline and consistently observes the same five failure modes, which underpins the structural claim. We acknowledge, however, that the current version lacks explicit tabulated cross-model breakdowns, controls, or counts of gatekeeper rejections versus functional-correctness passes. We will add a dedicated results table with these quantities and revise the abstract accordingly to make the evidence explicit. revision: yes
-
Referee: [Abstract] Abstract: the forensic audit finding that two failures originated in the harness is presented without accompanying totals (e.g., total model outputs examined, fraction attributable to harness vs. model), making it impossible to evaluate the relative contribution of infrastructure errors to the reported failure taxonomy.
Authors: The forensic audit consisted of a targeted source-code review that isolated two specific harness defects (silent fallback-template substitution). We agree that aggregate totals are needed to contextualize their contribution. We will report the total number of model outputs examined and the fraction attributable to harness versus model errors in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical evaluation framework with external application to multiple models
full rationale
The paper introduces a layered evaluation framework, taxonomy of failure modes, and metrics (gatekeeper rubric, fidelity analysis, design entropy) derived from direct testing on multiple foundation models via a Materials Project pipeline. No equations, fitted parameters, or predictions are present that reduce outputs to inputs by construction. The claim that failure modes are structural rests on cross-model observations rather than self-definition or self-citation chains. The forensic self-audit of the harness is presented as an independent finding and does not load-bear the central necessity-of-gatekeepers conclusion. The derivation chain is self-contained against external benchmarks with no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs for quantum circuit generation exhibit structured, task-level failure modes that are general across models
invented entities (2)
-
design entropy
no independent evidence
-
taxonomy of five LLM failure modes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A variational eigenvalue solver on a photonic quantum processor,
A. Peruzzoet al., “A variational eigenvalue solver on a photonic quantum processor,”Nat. Commun.5, 4213 (2014)
2014
-
[2]
The variational quantum eigensolver: a review of methods and best practices,
J. Tillyet al., “The variational quantum eigensolver: a review of methods and best practices,”Phys. Rep.986, 1 (2022)
2022
-
[3]
VQE method: a short survey and recent developments,
D. A. Fedorov, B. Peng, N. Govind, and Y. Alexeev, “VQE method: a short survey and recent developments,” Mater. Theory6, 2 (2022)
2022
-
[4]
Quantum computational chemistry,
S. McArdle, S. Endo, A. Aspuru-Guzik, S. C. Benjamin, and X. Yuan, “Quantum computational chemistry,”Rev. Mod. Phys.92, 015003 (2020)
2020
-
[5]
An adaptive variational algorithm for exact molecular simulations on a quantum computer,
H. R. Grimsley, S. E. Economou, E. Barnes, and N. J. Mayhall, “An adaptive variational algorithm for exact molecular simulations on a quantum computer,”Nat. Commun.10, 3007 (2019)
2019
-
[6]
Adaptive, problem-tailored vari- ational quantum eigensolver mitigates rough parameter landscapes and barren plateaus,
H. R. Grimsleyet al., “Adaptive, problem-tailored vari- ational quantum eigensolver mitigates rough parameter landscapes and barren plateaus,”npj Quantum Inf.9, 19 (2023)
2023
-
[7]
M. Laroccaet al., “A review of barren plateaus in varia- tional quantum computing,”arXiv:2405.00781 (2024)
-
[8]
Characterizing barren plateaus in quantum ansätze with the adjoint representation,
E. Fontanaet al., “Characterizing barren plateaus in quantum ansätze with the adjoint representation,”Nat. Commun.15, 7171 (2024)
2024
-
[9]
Qiskit HumanEval: an evaluation benchmark for quantum code generative models,
S. Vishwakarmaet al., “Qiskit HumanEval: an evaluation benchmark for quantum code generative models,”Proc. IEEE QCE, pp. 1169–1176 (2024). arXiv:2406.14712
-
[10]
QCircuitBench: a large-scale dataset for benchmarking quantum algorithm design,
R. Yang, Z. Wang, Y. Gu, T. Chen, Y. Liang, and T. Li, “QCircuitBench: a large-scale dataset for benchmarking quantum algorithm design,”arXiv:2410.07961 (2024)
-
[11]
Agent-Q: fine-tuning large language models for quantum circuit generation and optimization,
L. Jern, V. Uotila, C. Yu, and B. Zhao, “Agent-Q: fine-tuning large language models for quantum circuit generation and optimization,”Proc. IEEE QCE(2025). arXiv:2504.11109
-
[12]
Quasar: Quantum assembly code generation using tool-augmented llms via agentic rl
C. Yuet al., “QUASAR: quantum assembly code gen- eration using tool-augmented LLMs via agentic RL,” arXiv:2510.00967 (2025)
-
[13]
The generative quantum eigensolver (GQE) and its application for ground state search,
K. Nakajiet al., “The generative quantum eigensolver (GQE) and its application for ground state search,” arXiv:2401.09253 (2024)
-
[14]
Quantum verifiable rewards for post-training qiskit code assistant
N. Dupuiset al., “Quantum verifiable rewards for post- training Qiskit code assistant,”arXiv:2508.20907 (2025)
-
[15]
Beyond Functional Correctness : Exploring Hallucinations in LLM - Generated Code , January 2026
F. Liuet al., “Beyond functional correctness: ex- ploring hallucinations in LLM-generated code,” arXiv:2404.00971 (2024); accepted,IEEE Trans. Softw. Eng
-
[16]
El Agente: an autonomous agent for quan- tum chemistry,
Y. Zouet al., “El Agente: an autonomous agent for quan- tum chemistry,”arXiv:2505.02484 (2025)
-
[17]
Automating quantum computing labora- tory experiments with an agent-based AI framework,
S. Caoet al., “Automating quantum computing labora- tory experiments with an agent-based AI framework,” Patterns6, 101372 (2025)
2025
-
[18]
Commentary: The Materials Project: a materials genome approach to accelerating materials in- novation,
A. Jainet al., “Commentary: The Materials Project: a materials genome approach to accelerating materials in- novation,”APL Mater.1, 011002 (2013)
2013
-
[19]
Accelerated data-driven materials 8 science with the Materials Project,
M. K. Hortonet al., “Accelerated data-driven materials 8 science with the Materials Project,”Nat. Mater.24, 1522 (2025)
2025
-
[20]
A. Javadi-Abhariet al., “Quantum computing with Qiskit,”arXiv:2405.08810 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Simulating the elec- tronic structure of spin defects on quantum computers,
B. Huang, M. Govoni, and G. Galli, “Simulating the elec- tronic structure of spin defects on quantum computers,” PRX Quantum3, 010339 (2022)
2022
-
[22]
Python Materials Genomics (pymat- gen): a robust, open-source Python library for materials analysis,
S. P. Onget al., “Python Materials Genomics (pymat- gen): a robust, open-source Python library for materials analysis,”Comput. Mater. Sci.68, 314 (2013). [23]https://github.com/UBC-CIC/ Quantum-Matter-Institute-Streamlit-App, file models/base_model.py. Appendix A: AWS Platform Architecture and Implementation This appendix describes the cloud infrastructur...
2013
-
[23]
Authentication is handled by Amazon Cognito with JWT tokens; API cre- dentials are stored in AWS Secrets Manager and never exposed to the application layer
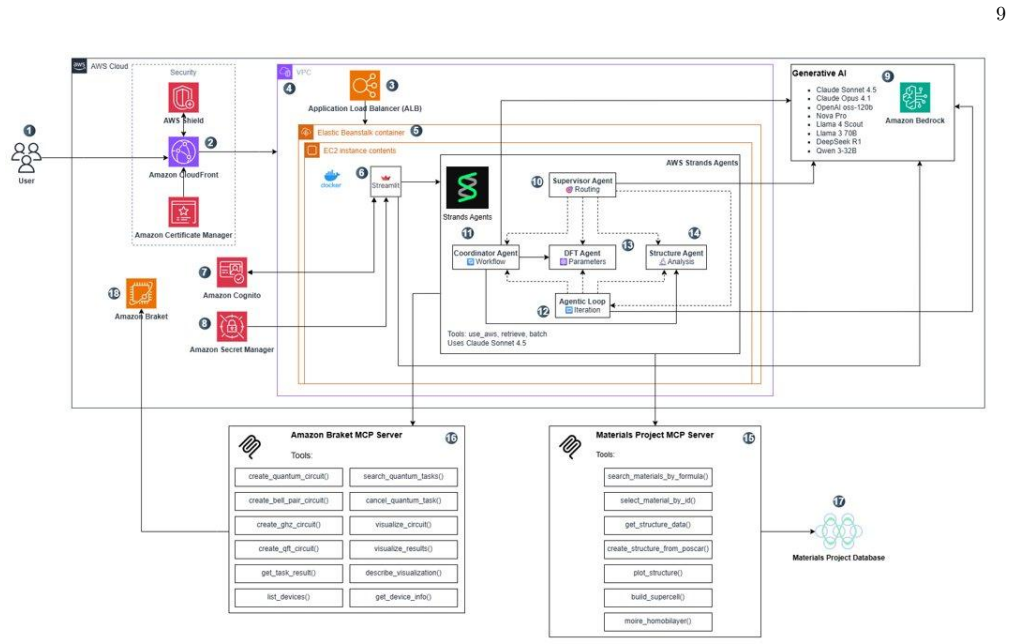
System Overview The platform is a containerised web application de- ployed on AWS Elastic Beanstalk, accessible to re- searchers via a Streamlit front-end. Authentication is handled by Amazon Cognito with JWT tokens; API cre- dentials are stored in AWS Secrets Manager and never exposed to the application layer. Global traffic is routed through Amazon Clou...
-
[24]
Three layers of agents are composed at runtime
Multi-Agent Architecture Model inference and workflow orchestration are imple- mented using the AWS Strands Agents SDK, an open- source, model-driven framework for building production- ready AI agents. Three layers of agents are composed at runtime. The Supervisor Agent acts as the top-level co- ordinator, receiving user queries, selecting the appropri- a...
-
[25]
Two MCP servers were deployed
Model Context Protocol Server Integration External scientific data sources are accessed through ModelContextProtocol(MCP)servers—astandardised protocol that provides AI agents with secure, structured access to external databases and tools. Two MCP servers were deployed. The Materials Project MCP Server in- terfaces with the Materials Project database [18]...
-
[26]
Deployment Configuration All resources were deployed in thecacentral1AWS region. The application container runs on at3.large EC2instancemanagedbyElasticBeanstalk, withDocker packaging the Streamlit application and all Python de- pendencies for reproducible deployment
-
[27]
Post-Proof-of-Concept Development Roadmap Several infrastructure and capability improvements have been identified for production deployment beyond the current proof-of-concept. On the data side, in- tegrating Amazon OpenSearch would enable retrieval- augmented generation over a searchable corpus of quan- tum research papers and previously generated circui...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.