PorTEXTO: A European Portuguese Benchmark for Visual Text Extraction
Pith reviewed 2026-06-26 21:26 UTC · model grok-4.3
The pith
PorTEXTO benchmark finds specialized multilingual data drives better pt-PT OCR performance than model size or resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
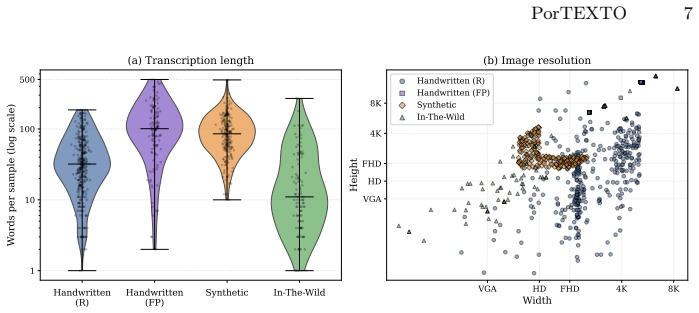
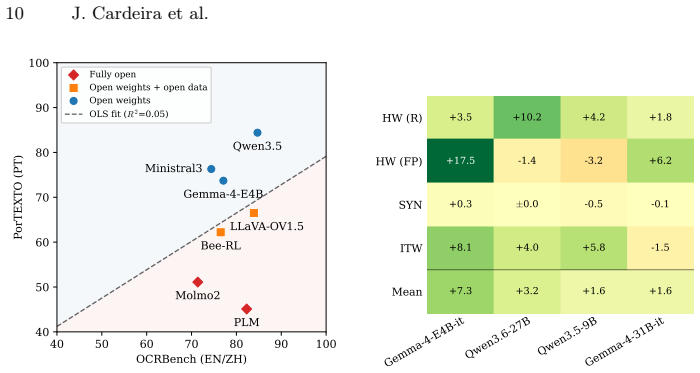
PorTEXTO provides the first benchmark dataset for contemporary and culturally relevant European Portuguese visual text extraction. An annotation pipeline that starts with transcriptions from a frontier large vision-language model and applies exhaustive native-speaker review ensures label quality. Evaluation across models shows a pronounced performance decline on real-world images versus synthetic ones. The central result is that specialized multilingual data currently improves pt-PT performance more than additional model parameters or higher resolution budgets.
What carries the argument
The PorTEXTO benchmark dataset together with its LVLM-plus-native-speaker annotation pipeline, used to compare model performance under varying data specialization, size, and resolution conditions.
If this is right
- Specialized multilingual datasets will yield higher real-world pt-PT extraction accuracy than equivalent gains in model size.
- Synthetic-only training will continue to overestimate performance on authentic pt-PT images.
- Open release of pt-PT OCR resources will enable further targeted improvements beyond current scaling approaches.
- Evaluation protocols for low-resource languages should prioritize real-world samples over synthetic ones.
Where Pith is reading between the lines
- The same data-specialization priority could be tested on other low-resource European languages to check whether the pattern generalizes.
- Future model development for multilingual OCR may shift resources from parameter scaling toward curated language-specific corpora.
- Benchmarks that separate synthetic and real-world splits could become standard for measuring true deployment readiness.
Load-bearing premise
The annotation pipeline that combines frontier LVLM transcriptions with exhaustive native-speaker review produces high-quality, reliable ground truth labels for the benchmark.
What would settle it
A larger model or higher-resolution model trained only on general multilingual data achieving higher accuracy on PorTEXTO real-world samples than models using specialized pt-PT data would falsify the central claim.
Figures




read the original abstract
European Portuguese (pt-PT) is largely absent from OCR benchmarks, which skew toward high-resource languages. The few benchmarks that cover pt-PT focus on historical artifacts and literature. This work addresses modern OCR applications, introducing PorTEXTO, the first benchmark for contemporary and culturally relevant pt-PT visual text extraction. To ascertain quality, we employ an annotation pipeline combining transcriptions from a frontier LVLM with exhaustive review by native speakers. We observe a sharp performance drop from synthetic to real world samples in most models, and find that, currently, specialized multilingual data is a better driver for pt-PT performance than model size or resolution budget, motivating the release of open pt-PT OCR resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PorTEXTO, the first benchmark for contemporary European Portuguese (pt-PT) visual text extraction, filling a gap left by OCR benchmarks that skew toward high-resource languages or historical pt-PT content. It describes an annotation pipeline that generates initial transcriptions via a frontier LVLM followed by exhaustive native-speaker review, reports a sharp performance drop on real-world versus synthetic samples across models, and concludes that specialized multilingual training data currently drives better pt-PT performance than increases in model size or input resolution.
Significance. If the benchmark labels prove reliable, the work supplies a needed evaluation resource for a mid-resource language and supplies empirical motivation for prioritizing language-specific multilingual data over scale in OCR development, which could guide resource allocation for other under-served languages.
major comments (1)
- [Annotation pipeline] Annotation pipeline description: the central performance comparisons and the claim that specialized multilingual data outperforms model size or resolution rest entirely on PorTEXTO labels, yet the manuscript supplies no inter-annotator agreement statistics, no measured error rate on a held-out real-world subset, and no comparison against an independent gold-standard set. Systematic omissions (pt-PT diacritics, reading-order errors induced by layout, or domain abbreviations) would directly bias the reported deltas.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction would benefit from explicit dataset statistics (number of images, text instances, domain breakdown) to allow readers to assess coverage before the methods section.
- [Results] Table or figure captions for model comparisons should state the exact evaluation metric (e.g., CER, WER) and whether synthetic versus real splits are reported separately.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We respond point-by-point to the major comment below.
read point-by-point responses
-
Referee: [Annotation pipeline] Annotation pipeline description: the central performance comparisons and the claim that specialized multilingual data outperforms model size or resolution rest entirely on PorTEXTO labels, yet the manuscript supplies no inter-annotator agreement statistics, no measured error rate on a held-out real-world subset, and no comparison against an independent gold-standard set. Systematic omissions (pt-PT diacritics, reading-order errors induced by layout, or domain abbreviations) would directly bias the reported deltas.
Authors: The annotation pipeline starts with initial transcriptions from a frontier LVLM, followed by exhaustive review and correction by native pt-PT speakers. This sequential process is intended to produce reliable labels, with the native review explicitly targeting issues such as diacritics, layout-induced reading order, and domain abbreviations. Inter-annotator agreement statistics are not reported because the workflow does not involve parallel independent annotations by multiple annotators; the final labels reflect the outcome of the exhaustive review step. We agree that an error-rate measurement on a held-out real-world subset or comparison to an external gold standard would provide additional reassurance. We will revise the manuscript to expand the description of the review process and include any available quality indicators from the annotation effort. revision: partial
Circularity Check
No circularity: empirical benchmark introduction with direct evaluations
full rationale
The paper introduces PorTEXTO as a new benchmark dataset for pt-PT visual text extraction and reports empirical performance observations across models. No derivations, equations, fitted parameters, predictions, or self-citations are used to support load-bearing claims. The annotation pipeline and performance comparisons are presented as direct measurements rather than reductions to prior inputs or self-referential fits. This is a standard dataset paper with no self-definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An, X., et al.: LLaVA-OneVision-1.5: Fully open framework for democratized mul- timodal training. arXiv:2509.23661 (2025)
Pith/arXiv arXiv 2025
-
[2]
In: ICCV (2019)
Biten, A.F., et al.: Scene text visual question answering. In: ICCV (2019)
2019
-
[3]
Advances in Neural Information Processing Systems (2026)
Cho, J.H., et al.: Perceptionlm: Open-access data and models for detailed visual understanding. Advances in Neural Information Processing Systems (2026)
2026
-
[4]
Clark, C., et al.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv:2601.10611 (2026)
Pith/arXiv arXiv 2026
-
[5]
Deshmukh, A.S., et al.: Nvidia nemotron nano v2 vl. arXiv:2511.03929 (2025)
arXiv 2025
-
[6]
https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (2026)
Google DeepMind: Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (2026)
2026
-
[7]
https://ai.google.dev/gemma/docs/ core/model_card_4 (2026)
Google DeepMind: Gemma 4 model card. https://ai.google.dev/gemma/docs/ core/model_card_4 (2026)
2026
-
[8]
Hong, W., et al.: Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv:2507.01006 (2025)
Pith/arXiv arXiv 2025
-
[9]
Huang, A., et al.: Step3-vl-10b technical report. arXiv:2601.09668 (2026)
arXiv 2026
-
[10]
In: ECCV (2022)
Kim, G., et al.: OCR-free document understanding transformer. In: ECCV (2022)
2022
-
[11]
In: MT (2005), https://www.statmt.org/europarl/
Koehn, P.: Europarl: A parallel corpus for statistical machine translation. In: MT (2005), https://www.statmt.org/europarl/
2005
-
[12]
IJCV (2020) 12 J
Kuznetsova, A., et al.: The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. IJCV (2020) 12 J. Cardeira et al
2020
-
[13]
Liu, A.H., et al.: Ministral 3. arXiv:2601.08584 (2026)
Pith/arXiv arXiv 2026
-
[14]
NVIDIA, https://huggingface.co/blog/nvidia/nemotron-ocr-v2 (2026)
Liu, B., et al.: Building a fast multilingual OCR model with synthetic data. NVIDIA, https://huggingface.co/blog/nvidia/nemotron-ocr-v2 (2026)
2026
-
[15]
Science China Information Sciences (2024)
Liu, Y., et al.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences (2024)
2024
-
[16]
In: CVPR (2019)
Marino, K., et al.: OK-VQA: A visual question answering benchmark requiring external knowledge. In: CVPR (2019)
2019
-
[17]
In: WACV (2021)
Mathew, M., et al.: DocVQA: A dataset for VQA on document images. In: WACV (2021)
2021
-
[18]
In: WACV (2022)
Mathew, M., et al.: InfographicVQA. In: WACV (2022)
2022
-
[19]
Journal of Imaging (2025)
Matos, A., et al.: iForal: Automated handwritten text transcription for historical medieval manuscripts. Journal of Imaging (2025)
2025
-
[20]
Hugging Face, https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset (2025)
mazafard: Portuguese OCR dataset. Hugging Face, https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset (2025)
2025
-
[21]
In: ICDAR (2024)
Neto, A.F.S., et al.: BRESSAY: A Brazilian Portuguese dataset for offline hand- written text recognition. In: ICDAR (2024)
2024
-
[22]
In: SIGIR (2021)
de Oliveira, L.L., et al.: REGIS: A test collection for geoscientific documents in Portuguese. In: SIGIR (2021)
2021
-
[23]
In: CIKM (2025)
Osório, T.F., et al.: Portuguese post-OCR resources for text optimisation. In: CIKM (2025)
2025
-
[24]
In: CVPR (2025)
Ouyang, L., et al.: OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations. In: CVPR (2025)
2025
-
[25]
In: ACL (2002)
Papineni, K., et al.: BLEU: a method for automatic evaluation of machine trans- lation. In: ACL (2002)
2002
-
[26]
INESC TEC, https://episa
Project, E.: Typewritten digital representations of Portuguese cultural heritage documents from the 20th century (EPISA dataset). INESC TEC, https://episa. inesctec.pt/outcomes/ (2022)
2022
-
[27]
https://qwen.ai/blog? id=qwen3.5 (2026)
Qwen Team: Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog? id=qwen3.5 (2026)
2026
-
[28]
https: //qwen.ai/blog?id=qwen3.6-27b (2026)
Qwen Team: Qwen3.6-27B: Flagship-level coding in a 27B dense model. https: //qwen.ai/blog?id=qwen3.6-27b (2026)
2026
-
[29]
In: ICDAR (2023)
Santos, M.K., et al.: ESTER-Pt: An evaluation suite for TExt recognition in Por- tuguese. In: ICDAR (2023)
2023
-
[30]
In: CVPR (2019)
Singh, A., et al.: Towards VQA models that can read. In: CVPR (2019)
2019
-
[31]
Smart, D.S., et al.: Encoder vs decoder: Comparative analysis of encoder and decoder language models on multilingual nlu tasks. arXiv:2406.13469 (2024)
arXiv 2024
-
[32]
In: ACL Findings (2025)
Tang, J., et al.: MTVQA: Benchmarking multilingual text-centric visual question answering. In: ACL Findings (2025)
2025
-
[33]
5: Advancing open-source multimodal models in ver- satility, reasoning, and efficiency
Wang, W., et al.: Internvl3. 5: Advancing open-source multimodal models in ver- satility, reasoning, and efficiency. arXiv:2508.18265 (2025)
Pith/arXiv arXiv 2025
-
[34]
Wei, H., et al.: Deepseek-ocr 2: Visual causal flow. arXiv:2601.20552 (2026)
arXiv 2026
-
[35]
HuggingFace Datasets (2023), https://huggingface.co/datasets/wikimedia/wikipedia
Wikimedia Foundation: Wikimedia wikipedia (20231101.pt). HuggingFace Datasets (2023), https://huggingface.co/datasets/wikimedia/wikipedia
2023
-
[36]
In: ICCV (2025)
Yang, Z., et al.: CC-OCR: A comprehensive and challenging OCR benchmark for evaluating large multimodal models in literacy. In: ICCV (2025)
2025
-
[37]
In: NAACL (2025)
Zhang, K., et al.: Lmms-eval: Reality check on the evaluation of large multimodal models. In: NAACL (2025)
2025
-
[38]
Zhang, Y., et al.: Bee: A high-quality corpus and full-stack suite to unlock advanced fully open MLLMs. arXiv:2510.13795 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.