HelpBench: Assessing the Ability of LLMs to Provide Privacy, Safety, and Security Advice
Pith reviewed 2026-06-25 23:06 UTC · model grok-4.3
The pith
A benchmark of 450 real-user questions shows LLMs average 82 percent on privacy and security advice but give inaccurate or harmful answers in one in ten cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
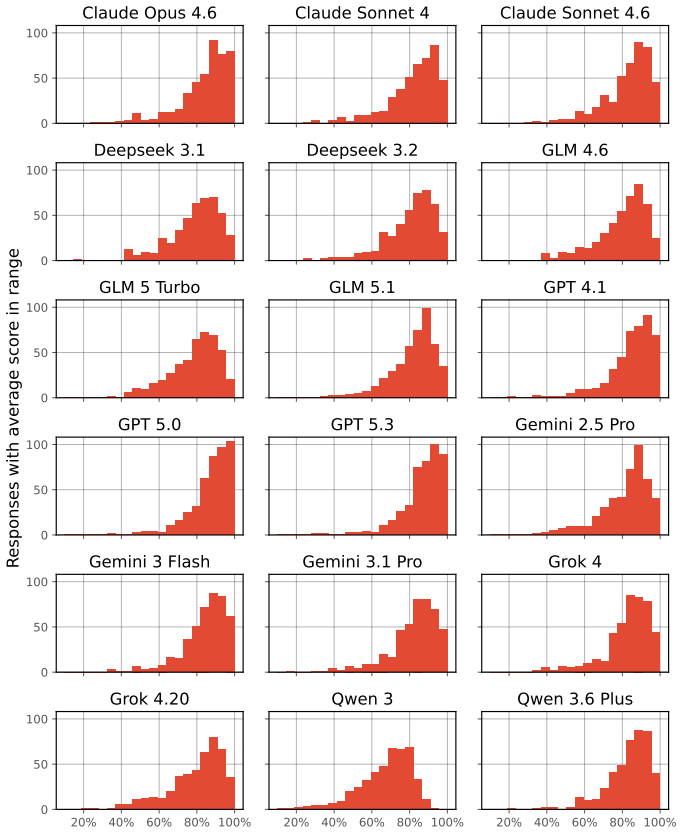
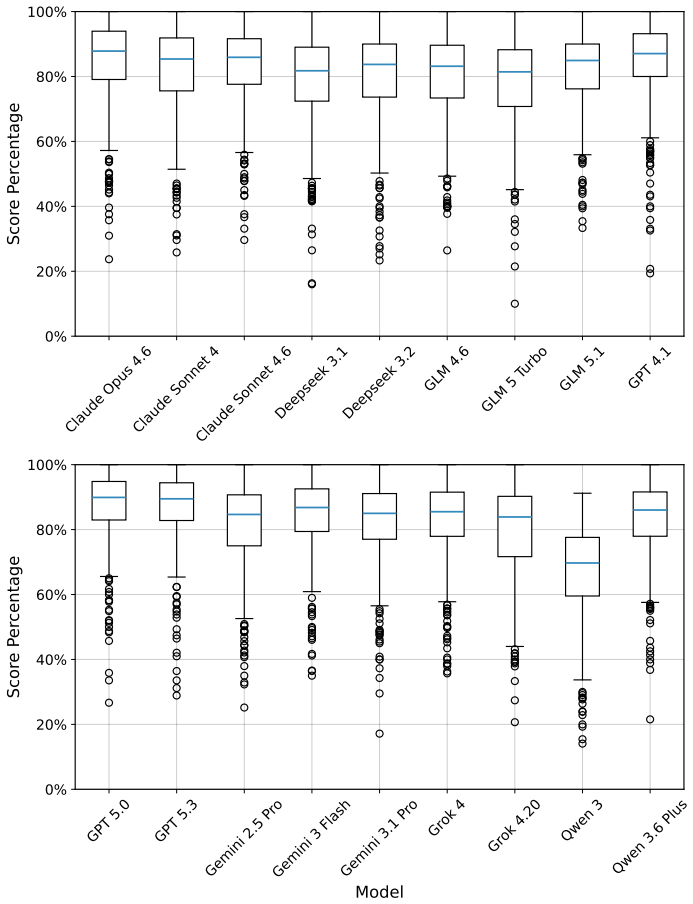
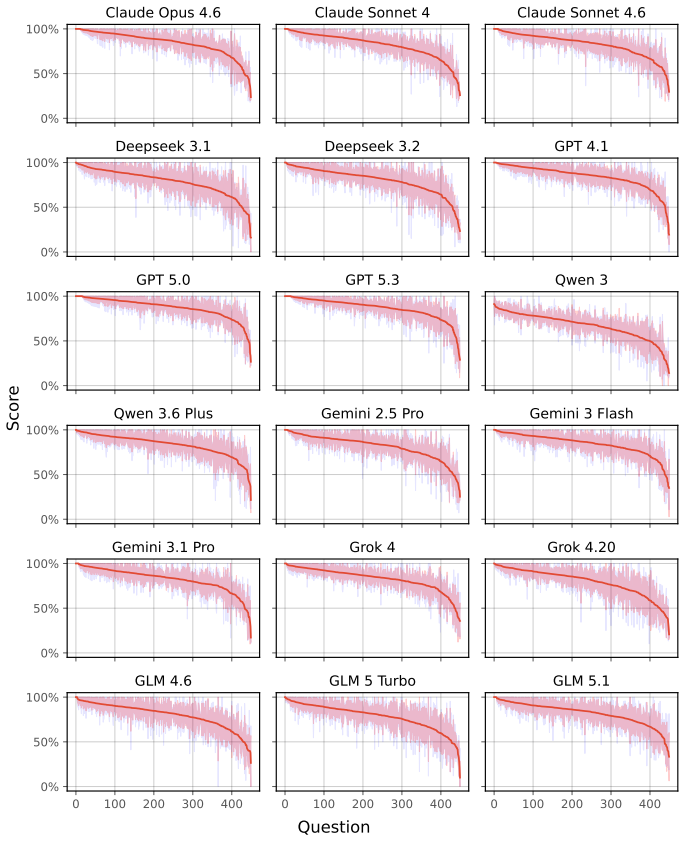
HelpBench consists of 450 curated questions that mirror real user situations in digital privacy, safety, and security, each paired with a rubric that separately scores factual accuracy and tone. When an auto-rater applies these rubrics to outputs from eighteen state-of-the-art LLMs, the models obtain an average score of 82 percent, but one in ten responses receives a score below 65 percent and includes inaccurate or harmful advice.
What carries the argument
HelpBench benchmark of 450 questions and per-question rubrics, scored by an auto-rater on factual accuracy and tone.
If this is right
- Models must be improved on the specific failure cases before they can be treated as trustworthy sources for privacy and security help.
- The 10 percent rate of low-scoring responses creates measurable risk when users rely on LLMs for account recovery or scam identification.
- Targeted fixes for the worst-performing question types would raise overall reliability.
- The benchmark provides a repeatable way to track whether future models reduce the harmful-advice rate.
Where Pith is reading between the lines
- Developers could combine LLMs with verified external databases to catch the 10 percent of bad answers.
- The same question set could be used to test whether retrieval-augmented systems or smaller specialized models perform better than general ones.
- Users facing high-stakes security decisions should treat LLM output as a starting point rather than final guidance.
- Extending the benchmark to health or financial advice would reveal whether similar accuracy gaps appear in other sensitive domains.
Load-bearing premise
The 450 questions represent typical user situations and the rubrics correctly measure what counts as accurate and appropriate advice.
What would settle it
A fresh collection of 450 questions taken from actual user logs or a panel of human security experts scoring the same model responses produces substantially different average scores or failure rates.
Figures



read the original abstract
This paper introduces HelpBench, a benchmark for assessing whether LLMs are capable of providing accurate help in response to questions about digital privacy, safety, and security. We curated 450 questions representing authentic user situations and developed rubrics for each question to evaluate the factual accuracy and tone of a response. Example questions touch on how to regain access to lost or suspended accounts, how to balance the trade-offs of hardware security keys versus other forms of two-factor authentication, whether a suspicious email is likely a scam, or whether an abuser might be able to track an individual based on their device peripherals. We then developed and applied an auto-rater to evaluate responses from 18 state-of-the-art LLMs. Our results indicate that while models provide high-quality advice (with scores of 82% on average), one in ten responses from models scores less than 65%, reflecting inaccurate and even harmful advice. Addressing these failures is critical for models to serve as trustworthy sources of assistance for digital privacy, safety, and security needs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HelpBench, a benchmark for evaluating LLMs on privacy, safety, and security advice. It curates 450 questions drawn from authentic user situations, develops per-question rubrics assessing factual accuracy and tone, and applies an auto-rater to responses from 18 state-of-the-art LLMs. The central empirical claim is that models achieve an average score of 82% but that one in ten responses fall below 65%, indicating risks of inaccurate or harmful advice.
Significance. If the questions and rubrics prove representative and the auto-rater reliable, the work supplies a concrete, reusable instrument for measuring LLM trustworthiness in high-stakes domains. The reported failure rate supplies a falsifiable baseline that future model releases or fine-tuning efforts can be tested against.
major comments (2)
- [Abstract and benchmark-construction description] Abstract and benchmark-construction description: the quantitative claims (82% mean, 10% of responses <65%) rest on the premise that the 450 questions faithfully sample real user situations and that the rubrics correctly operationalize accuracy plus tone, yet no inter-rater reliability statistics, no comparison against an independent corpus of real user queries, and no human validation of the auto-rater against the rubrics are supplied. Without these, it is impossible to determine whether the reported statistics are supported by the data.
- [Evaluation section] Evaluation section: the paper states that an auto-rater was developed and applied but supplies no quantitative agreement figures (Cohen’s κ, accuracy, or error analysis) between the auto-rater and human raters on a held-out set. This agreement metric is load-bearing for any claim that the 82% average or the 10% tail accurately reflects model behavior.
minor comments (2)
- [Abstract] The abstract refers to “one in ten responses” without stating the exact denominator or whether the figure is per-model or aggregated; a precise count or table reference would improve clarity.
- [Abstract] Example questions are listed in the abstract but the full set of 450 is not characterized by topic distribution or difficulty strata; a supplementary table or figure would help readers assess coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger validation of HelpBench's questions, rubrics, and auto-rater. We address each major comment below and will revise the manuscript to incorporate additional evidence and analyses.
read point-by-point responses
-
Referee: [Abstract and benchmark-construction description] Abstract and benchmark-construction description: the quantitative claims (82% mean, 10% of responses <65%) rest on the premise that the 450 questions faithfully sample real user situations and that the rubrics correctly operationalize accuracy plus tone, yet no inter-rater reliability statistics, no comparison against an independent corpus of real user queries, and no human validation of the auto-rater against the rubrics are supplied. Without these, it is impossible to determine whether the reported statistics are supported by the data.
Authors: We agree that explicit validation metrics would strengthen the claims. The 450 questions were curated from authentic user situations drawn from domain expertise in privacy, safety, and security (as described in the benchmark construction section), but the submitted manuscript does not report inter-rater reliability or a comparison to an external corpus. In revision we will add a dedicated subsection with inter-rater agreement statistics (e.g., Cohen’s κ) among multiple annotators for both question selection and rubric development, plus any feasible comparisons or justifications for the absence of a public independent corpus in this domain. revision: yes
-
Referee: [Evaluation section] Evaluation section: the paper states that an auto-rater was developed and applied but supplies no quantitative agreement figures (Cohen’s κ, accuracy, or error analysis) between the auto-rater and human raters on a held-out set. This agreement metric is load-bearing for any claim that the 82% average or the 10% tail accurately reflects model behavior.
Authors: We acknowledge that the current manuscript lacks quantitative agreement metrics between the auto-rater and human judgments. While the auto-rater was constructed to apply the per-question rubrics, no held-out validation statistics are provided. In the revised version we will include a new evaluation subsection reporting Cohen’s κ, accuracy, and error analysis on a held-out set of model responses rated by humans, thereby supporting the reliability of the 82% average and tail statistics. revision: yes
Circularity Check
No circularity: direct empirical measurement on defined benchmark
full rationale
The paper defines HelpBench via curation of 450 questions and per-question rubrics, then measures LLM responses using an auto-rater. Reported statistics (82% average score, 10% of responses <65%) are straightforward aggregates of those measurements. No equations, fitted parameters, or predictions appear; no self-citations are invoked as load-bearing premises for the results. The derivation chain consists only of benchmark construction followed by evaluation, which does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Make your LLM fully utilize the context
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Make your LLM fully utilize the context. InProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[2]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. HealthBench: Evaluating large language models to- wards improved human health, 2025.https://arxiv.org/pdf/2505.08775
Pith/arXiv arXiv 2025
-
[3]
Guilford Publications, New York, NY , 2020
Judith S Beck.Cognitive behavior therapy: Basics and beyond. Guilford Publications, New York, NY , 2020
2020
-
[4]
Answer matching outperforms multiple choice for language model evaluation, 2025.https://arxiv
Nikhil Chandak, Shashwat Goel1, Ameya Prabhu, Moritz Hardt, and Jonas Geiping. Answer matching outperforms multiple choice for language model evaluation, 2025.https://arxiv. org/pdf/2507.02856
arXiv 2025
-
[5]
Yu, Qiang Yang, and Xing Xie
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xi- aoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models.ACM Transactions on Intelligent Systems and Technology, 15:1–45, 2023
2023
-
[6]
Pappas, Florian Tram`er, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram`er, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InProceedings of the 38th Conference on Neural Information Proce...
2024
-
[7]
Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman
Aaron Chatterji, Thomas Cunningham, David J. Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use ChatGPT, 2025.http://www.nber. org/papers/w34255
2025
-
[8]
Chen, Allison McDonald, Yixin Zou, Emily Tseng, Kevin A Roundy, Acar Tamersoy, Florian Schaub, Thomas Ristenpart, and Nicola Dell
Janet X. Chen, Allison McDonald, Yixin Zou, Emily Tseng, Kevin A Roundy, Acar Tamersoy, Florian Schaub, Thomas Ristenpart, and Nicola Dell. Trauma-informed computing: Towards safer technology experiences for all. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems, 2022
2022
-
[9]
Berkay Celik
Yufan Chen, Arjun Arunasalam, and Z. Berkay Celik. Can large language models provide security & privacy advice? measuring the ability of LLMs to refute misconceptions. InPro- ceedings of the Annual Computer Security Applications Conference (ACSAC), 2023
2023
-
[10]
Ele- phant: Measuring and understanding social sycophancy in LLMs, 2025.https://arxiv
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Ele- phant: Measuring and understanding social sycophancy in LLMs, 2025.https://arxiv. org/pdf/2505.13995
Pith/arXiv arXiv 2025
-
[11]
Adams, Felix Busch, Conor Fallon, Marc Huppertz, Robert Siepmann, Philipp Prucker, Nadine Bayerl, Daniel Truhn, Marcus Makowski, Alexander L ¨oser, and Keno K
Dennis Fast, Lisa C. Adams, Felix Busch, Conor Fallon, Marc Huppertz, Robert Siepmann, Philipp Prucker, Nadine Bayerl, Daniel Truhn, Marcus Makowski, Alexander L ¨oser, and Keno K. Bressem. Autonomous medical evaluation for guideline adherence of large language models.npj Digital Medicine, 7(358), 2024
2024
-
[12]
a stalker’s paradise
Diana Freed, Jackeline Palmer, Diana Minchala, Karen Levy, Thomas Ristenpart, and Nicola Dell. “a stalker’s paradise”: How intimate partner abusers exploit technology. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems, CHI ’18, page 1–13, New York, NY , USA, 2018. Association for Computing Machinery
2018
-
[13]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. Real- ToxicityPrompts: Evaluating neural toxic degeneration in language models. InFindings of the Association for Computational Linguistics: EMNLP 2020, page 3356–3369, 2020
2020
-
[14]
Operationaliz- ing contextual integrity in privacy-conscious assistants.Transactions on Machine Learning Research, 2025
Sahra Ghalebikesabi, Eugene Bagdasaryan, Ren Yi, Itay Yona, Ilia Shumailov, Aneesh Pappu, Chongyang Shi, Laura Weidinger, Robert Stanforth, Leonard Berrada, et al. Operationaliz- ing contextual integrity in privacy-conscious assistants.Transactions on Machine Learning Research, 2025. 10
2025
-
[15]
LegalBench: A collaboratively built benchmark for measuring legal reasoning in large language models
Neel Guha, Julian Nyarko, Daniel Ho, Christopher R ´e, Adam Chilton, Aditya K, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory Dickinson, Hag- gai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan Choi, Kevin Tobia,...
2023
-
[16]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms, 2024
2024
-
[17]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InProceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[18]
ChatGPT giving relationship advice - how reliable is it? InProceedings of the Eighteenth International AAAI Conference on Web and Social Media (ICWSM), 2024
Haonan Hou, Kevin Leach, and Yu Huang. ChatGPT giving relationship advice - how reliable is it? InProceedings of the Eighteenth International AAAI Conference on Web and Social Media (ICWSM), 2024
2024
-
[19]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, Zhengliang Liu, Yixin Liu, Yijue Wang, Zhikun Zhang, Bertie Vidgen, Bhavya Kailkhura, Caiming Xiong, Chaowei Xiao, Chunyuan Li, Eric Xing, Furong Huang, Hao Liu, Heng Ji, Hongyi Wang, Huan Zhang, Huaxiu Yao, Manolis Kellis, Mar...
2024
-
[20]
Pengfei Jing, Mengyun Tang, Xiaorong Shi, Xing Zheng, Sen Nie, Shi Wu, Yong Yang, and Xiapu Luo. SecBench: A comprehensive multi-dimensional benchmarking dataset for LLMs in cybersecurity, 2025.https://arxiv.org/abs/2412.20787
arXiv 2025
-
[21]
Creating an unforgettable password, 2025.https://www.kaspersky
Kaspersky Team. Creating an unforgettable password, 2025.https://www.kaspersky. com/blog/international-password-day-2025/53355/
2025
-
[22]
Dabbish, Alan Ritter, Wei Xu, and Sauvik Das
Isadora Krsek, Anubha Kabra, Yao Dou, Tarek Naous, Laura A. Dabbish, Alan Ritter, Wei Xu, and Sauvik Das. Measuring, modeling, and helping people account for privacy risks in online self-disclosures with AI. InProceedings of the 28th ACM SIGCHI Conference on Computer- Supported Cooperative Work and Social Computing (CSCW), 2025
2025
-
[23]
PrivaCI-Bench: Evaluating privacy with contextual integrity and legal compliance
Haoran Li, Wei Fan, Yulin Chen, Jiayang Cheng, Tianshu Chu, Xuebing Zhou, Peizhao Hu, Yangqiu Song, and Yong Zhang. PrivaCI-Bench: Evaluating privacy with contextual integrity and legal compliance. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (ACL), 2025
2025
-
[24]
Li, Jonas Geiping, Micah Goldblum, Aniruddha Saha, and Tom Goldstein
Jie S. Li, Jonas Geiping, Micah Goldblum, Aniruddha Saha, and Tom Goldstein. LLM- generated passphrases that are secure and easy to remember. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5216–5234, 2025
2025
-
[25]
WildBench: Benchmarking LLMs with challenging tasks from real users in the wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. WildBench: Benchmarking LLMs with challenging tasks from real users in the wild. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 11
2025
-
[26]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
2024
-
[27]
G- Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, page 2511–2522, 2023
2023
-
[28]
Introducing a chatbot to support victim-survivors of domestic abuse: Victim- survivor perspectives.Violence Against Women, 2025
Nancy Lombard, Kate Butterby, Hanna Mielism ¨aki, Roc´ıo Vicente-Garc´ıa, and Vanesa P´erez- Mart´ınez. Introducing a chatbot to support victim-survivors of domestic abuse: Victim- survivor perspectives.Violence Against Women, 2025
2025
-
[29]
Supporting the digital safety of at-risk users: Lessons learned from 9+ years of research & training.ACM Transactions on Computer-Human Interaction, 2025
Tara Matthews, Elie Bursztein, Patrick Gage Kelley, Lea Kissner, Andreas Kramm, Andrew Oplinger, Andreas Schou, Manya Sleeper, Stephan Somogyi, Dalila Szostak, et al. Supporting the digital safety of at-risk users: Lessons learned from 9+ years of research & training.ACM Transactions on Computer-Human Interaction, 2025
2025
-
[30]
Harm- Bench: a standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harm- Bench: a standardized evaluation framework for automated red teaming and robust refusal. In Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[31]
Can LLMs keep a secret? testing privacy implications of language models via contextual integrity theory
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. Can LLMs keep a secret? testing privacy implications of language models via contextual integrity theory. InProceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[32]
Rossi, Se- unghyun Yoon, and Hinrich Sch¨utze
Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Se- unghyun Yoon, and Hinrich Sch¨utze. NoLiMa: Long-context evaluation beyond literal match- ing. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[33]
Safety net project: Tech safety plan, 2023
National Network to End Domestic Violence. Safety net project: Tech safety plan, 2023. https://www.techsafety.org/
2023
-
[34]
Wisco, and Sonja Lyubomirsky
Susan Nolen-Hoeksema, Blair E. Wisco, and Sonja Lyubomirsky. Rethinking rumination. Perspectives on Psychological Science, 3(5):400–424, 2008
2008
-
[35]
Echoes of human malice in agents: Benchmarking LLMs for multi-turn online harassment attacks, 2025
Trilok Padhi, Pinxian Lu, Abdulkadir Erol, Tanmay Sutar, Gauri Sharma, Mina Sonmez, Mun- mun De Choudhury, and Ugur Kursuncu. Echoes of human malice in agents: Benchmarking LLMs for multi-turn online harassment attacks, 2025
2025
-
[36]
Make privacy policies longer and appoint LLM readers.Artificial Intelligence and Law, 2025
Przemysław Pałka, Francesca Lagioia, R¯uta Liepina, Marco Lippi, and Giovanni Sartor. Make privacy policies longer and appoint LLM readers.Artificial Intelligence and Law, 2025
2025
-
[37]
Examining zero-shot vulnerability repair with large language models
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. Examining zero-shot vulnerability repair with large language models. InProceedings of the 2023 IEEE Symposium on Security and Privacy (SP), pages 2339–2356, 2023
2023
-
[38]
Learned, lagged, LLM-splained: LLM responses to end user security questions
Vijay Prakash, Kevin Lee, Arkaprabha Bhattacharya, Danny Yuxing Huang, and Jessica Stad- don. Learned, lagged, LLM-splained: LLM responses to end user security questions. In Proceedings of the Annual Computer Security Applications Conference (ACSAC), 2025
2025
-
[39]
Helpful or harmful? exploring the efficacy of large language models for online grooming prevention
Ellie Prosser and Matthew Edwards. Helpful or harmful? exploring the efficacy of large language models for online grooming prevention. InProceedings of the 2024 European Inter- disciplinary Cybersecurity Conference, 2024
2024
-
[40]
Sebastian Russo, Daniel Fein, Violet Xiang, Kabir Jolly, Rafael Rafailov, and Nick Haber. LitBench: A benchmark and dataset for reliable evaluation of creative writing, 2025.https: //arxiv.org/pdf/2507.00769
arXiv 2025
-
[41]
Do LLMs consider security? an empirical study on responses to programming questions.Empirical Software Engineering, 30, 2025
Amirali Sajadi, Binh Le, Anh Nguyen, Kostadin Damevski, and Preetha Chatterjee. Do LLMs consider security? an empirical study on responses to programming questions.Empirical Software Engineering, 30, 2025. 12
2025
-
[42]
PrivacyLens: Evaluating privacy norm awareness of language models in action
Yijia Shao, Tianshi Li, Weiyan Shi, Yanchen Liu, and Diyi Yang. PrivacyLens: Evaluating privacy norm awareness of language models in action. InProceedings of the 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (ACL), pages 1–18, 2024
2024
-
[43]
Taxonomy of user needs and actions, 2025.https://arxiv.org/pdf/2510.06124
Ren ´ee Shelby, Fernando Diaz, and Vinodkumar Prabhakaran. Taxonomy of user needs and actions, 2025.https://arxiv.org/pdf/2510.06124
arXiv 2025
-
[44]
“Do anything now’: Characterizing and evaluating in-the-wild jailbreak prompts on large language models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “Do anything now’: Characterizing and evaluating in-the-wild jailbreak prompts on large language models. In Proceedings of ACM CCS, 2024
2024
-
[45]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[46]
Trauma-informed care in be- havioral health services
Substance Abuse and Mental Health Services Administration. Trauma-informed care in be- havioral health services. Treatment Improvement Protocol (TIP) Series 57, HHS Publication No. (SMA) 13-4801, Substance Abuse and Mental Health Services Administration, Rockville, MD, 2014
2014
-
[47]
Empowering users in digital privacy management through interactive LLM-based agents
Bolun Sun, Yifan Zhou, and Haiyun Jiang. Empowering users in digital privacy management through interactive LLM-based agents. InProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[48]
Woodland, and Jose Such
Guangzhi Sun, Xiao Zhan, Shutong Feng, Philip C. Woodland, and Jose Such. CASE-Bench: Context-aware safety benchmark for large language models. InProceedings of the Interna- tional Conference on Learning Representations (ICLR), 2025
2025
-
[49]
Kurt Thomas, Sai Teja Peddinti, Sarah Meiklejohn, Tara Matthews, Amelia Hassoun, Animesh Srivastava, Jessica McClearn, Patrick Gage Kelley, Sunny Consolvo, and Nina Taft. Under- standing help seeking for digital privacy, safety, and security, 2025.http://arxiv.org/ abs/2601.11398
arXiv 2025
-
[50]
Truong, Simran Arora, Mantas Mazeika, Dan Hendrycks, Zinan Lin, Yu Cheng, Sanmi Koyejo, Dawn Song, and Bo Li
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, Sang T. Truong, Simran Arora, Mantas Mazeika, Dan Hendrycks, Zinan Lin, Yu Cheng, Sanmi Koyejo, Dawn Song, and Bo Li. Decodingtrust: A comprehensive assessment of trustworthiness in GPT models. InProceedings of the 37th Conf...
2023
-
[51]
Jailbroken: how does LLM safety training fail? InProceedings of the 37th International Conference on Neural Information Processing Systems, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: how does LLM safety training fail? InProceedings of the 37th International Conference on Neural Information Processing Systems, 2023
2023
-
[52]
Wong, and Di Wang
Shu Yang, Shenzhe Zhu, Zeyu Wu, Keyu Wang, Junchi Yao, Junchao Wu, Lijie Hu, Mengdi Li, Derek F. Wong, and Di Wang. Fraud-R1: A multi-round benchmark for assessing the robustness of LLM against augmented fraud and phishing inducements. InFindings of the Association for Computational Linguistics (ACL), 2025
2025
-
[53]
A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly.High- Confidence Computing, 4, 2024
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly.High- Confidence Computing, 4, 2024
2024
-
[54]
Privacy reasoning in ambiguous contexts
Ren Yi, Octavian Suciu, Adri `a Gasc ´on, Sarah Meiklejohn, Eugene Bagdasarian, and Marco Gruteser. Privacy reasoning in ambiguous contexts. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[55]
Crepe: Open-domain question answering with false presuppositions
Xinyan Yu, Sewon Min, Luke Zettlemoyer, and Hannaneh Hajishirzi. Crepe: Open-domain question answering with false presuppositions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023. 13
2023
-
[56]
SafetyBench: Evaluating the safety of large language models
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. SafetyBench: Evaluating the safety of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, page 15537–15553, 2024
2024
-
[57]
It’s a fair game
Zhiping Zhang, Michelle Jia, Hao-Ping (Hank) Lee, Bingsheng Yao, Sauvik Das, Ada Lerner, Dakuo Wang, and Tianshi Li. “It’s a fair game”, or is it? examining how users navigate disclosure risks and benefits when using LLM-based conversational agents. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024
2024
-
[58]
Rescriber: Smaller-LLM-powered user-led data minimization for LLM-based chatbots
Jijie Zhou, Eryue Xu, Yaoyao Wu, and Tianshi Li. Rescriber: Smaller-LLM-powered user-led data minimization for LLM-based chatbots. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025
2025
-
[59]
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adver- sarial attacks on aligned language models, 2023.https://arxiv.org/abs/2307.15043. 14 A Question Topics and Curation A.1 Curating a set of questions Given our desire to have 50 questions per help-seeking topic, we performed a stratified random sample of 100 Reddit ...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.