Frequency-Scale Saliency for Spectral Descriptor Analysis in 3D Shape Retrieval
Pith reviewed 2026-06-27 19:53 UTC · model grok-4.3
The pith
Ablating scale intervals in spectral descriptors shows short scales drive 3D shape retrieval while long scales harm it, enabling a weighting method that raises mAP by 0.156 on hard categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
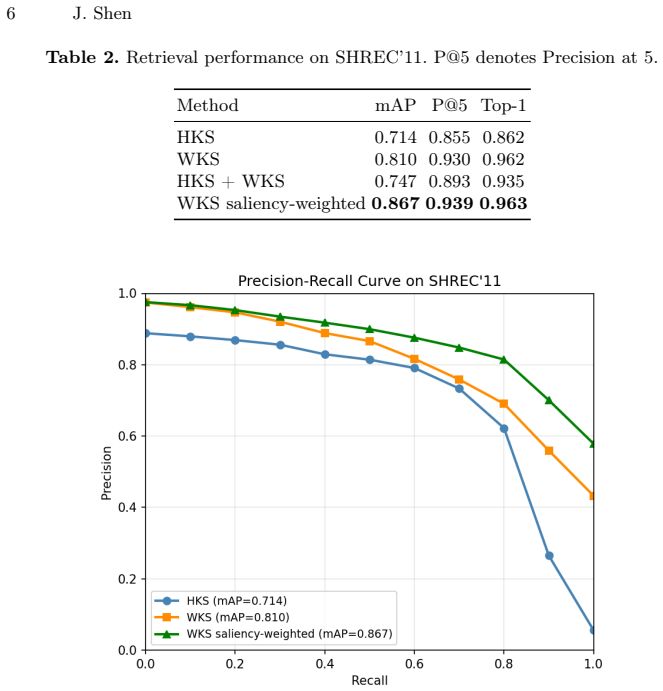
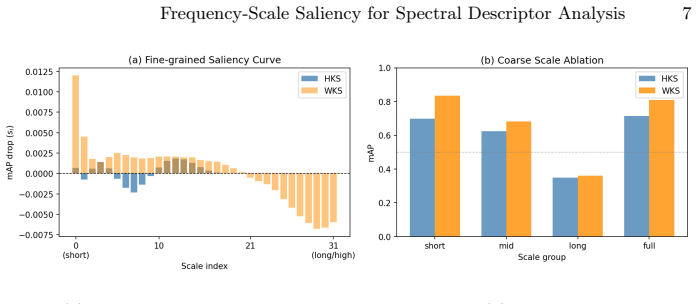
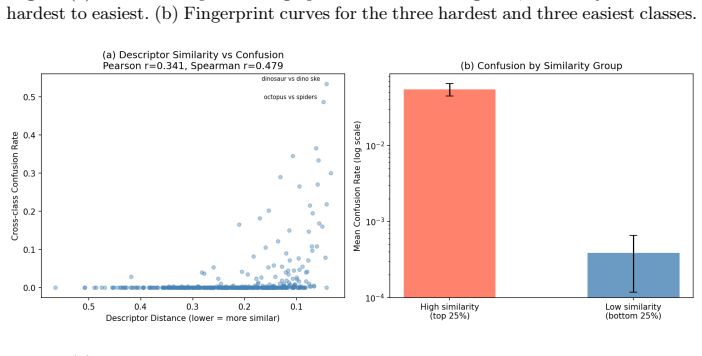
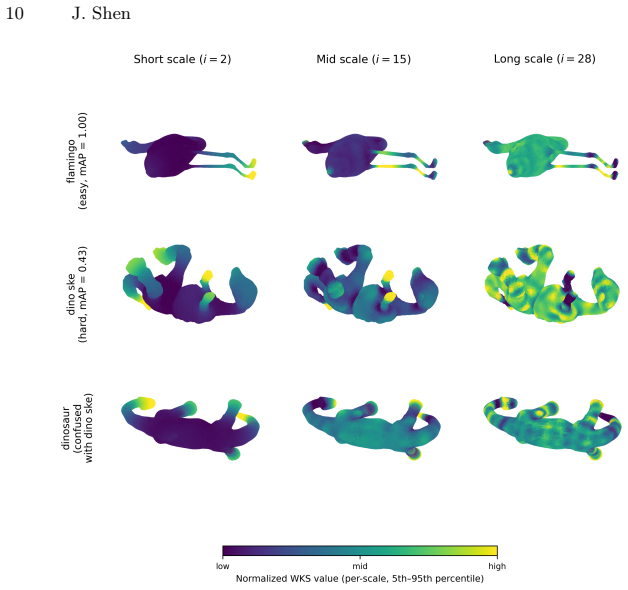
The frequency-scale saliency framework quantifies the retrieval-level contribution of each descriptor scale interval through ablation on descriptors like HKS and WKS. It shows that short scales dominate performance while long scales are harmful, that HKS and WKS have distinct scale dependence, and that class descriptor similarity correlates with retrieval failure (Spearman 0.479). Saliency-weighted retrieval improves mAP on hard categories by 0.156, with cross-fold and random-weight controls verifying the improvement is not arbitrary.
What carries the argument
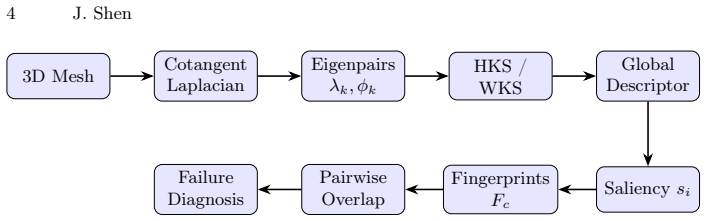
The frequency-scale saliency framework, which audits descriptors by ablating scale intervals to measure their individual contributions to retrieval accuracy.
If this is right
- Short scales dominate retrieval performance while long scales are harmful.
- HKS and WKS exhibit distinct scale dependence patterns.
- Descriptor similarity between class pairs is correlated with retrieval failure at Spearman 0.479.
- Saliency-weighted retrieval improves mAP on hard categories by 0.156 with stable gains under controls.
Where Pith is reading between the lines
- The saliency framework might apply to analyzing other non-spectral descriptors in shape matching tasks.
- Class fingerprints could help predict which shape categories will be difficult to distinguish before retrieval runs.
- Future descriptor design could prioritize or exclude scales based on these contribution patterns.
Load-bearing premise
That removing one scale interval at a time isolates its contribution without interactions between remaining scales affecting the results substantially.
What would settle it
If applying the saliency-derived weights to descriptors on a different 3D retrieval dataset fails to improve mAP on hard categories compared to the original descriptors, that would indicate the improvement is not general.
Figures
read the original abstract
Classical spectral descriptors such as the Heat Kernel Signature and Wave Kernel Signature are widely used for non-rigid 3D shape retrieval, yet their failure modes remain poorly understood. We present a frequency-scale saliency framework that audits these descriptors by quantifying the retrieval-level contribution of each descriptor scale interval through ablation. We introduce class spectral fingerprints to characterize category-level scale dependence, and show that descriptor similarity between class pairs is substantially correlated with retrieval failure, with a Spearman correlation of 0.479. Experiments on SHREC'11 demonstrate that short scales dominate retrieval performance while long scales are harmful, that HKS and WKS exhibit distinct scale dependence patterns, and that saliency-weighted retrieval improves mAP on hard categories by 0.156, with cross-fold and random-weight controls confirming that the gain is stable and not due to arbitrary reweighting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a frequency-scale saliency framework that uses ablation of scale intervals in spectral descriptors (HKS, WKS) to quantify their retrieval-level contributions on SHREC'11. It defines class spectral fingerprints, reports a Spearman correlation of 0.479 between inter-class descriptor similarity and retrieval failure, finds that short scales dominate while long scales harm performance, and shows that saliency-weighted descriptors improve mAP by 0.156 on hard categories, with cross-fold and random-weight controls.
Significance. If the ablation isolates independent scale contributions, the framework offers a practical audit tool for spectral descriptors and a concrete way to boost retrieval on difficult categories. The quantitative mAP gain, the correlation result, and the use of controls are clear strengths that would make the work useful to the 3D retrieval community.
major comments (2)
- [§3, §4.2] §3 (Frequency-Scale Saliency Framework) and §4.2 (Ablation Procedure): the derivation of saliency weights assumes that removing one scale interval leaves the remaining descriptor components unchanged in their effective scale and normalization statistics. No experiment tests whether global normalization or basis projection across the full spectrum creates interactions; if present, the reported 0.156 mAP gain and the 0.479 correlation would be confounded rather than causal.
- [§4.3] §4.3 (Retrieval Experiments): the cross-fold and random-weight controls address arbitrary reweighting but do not address scale-interaction effects. An additional control that renormalizes the descriptor after each ablation (or recomputes the basis) is needed to confirm that the saliency weights reflect genuine per-scale importance.
minor comments (2)
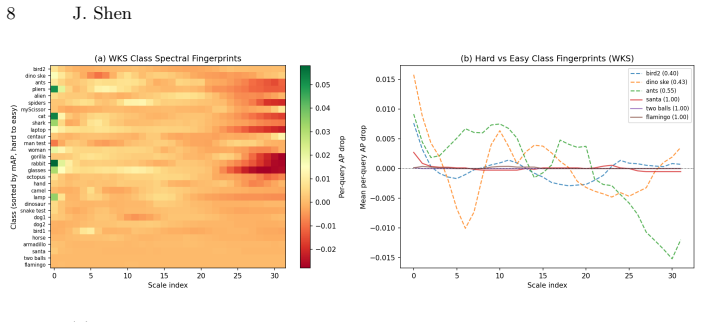
- [Figure 4] Figure 4 (class spectral fingerprints): the color scale and axis labels make it difficult to compare HKS vs. WKS patterns across categories; adding a shared reference bar would improve readability.
- [§2] Notation: the definition of 'scale interval' is introduced in §2 but used with different granularity in the ablation tables; a single explicit definition with example boundaries would eliminate ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validating the independence of scale contributions in our ablation framework. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3, §4.2] §3 (Frequency-Scale Saliency Framework) and §4.2 (Ablation Procedure): the derivation of saliency weights assumes that removing one scale interval leaves the remaining descriptor components unchanged in their effective scale and normalization statistics. No experiment tests whether global normalization or basis projection across the full spectrum creates interactions; if present, the reported 0.156 mAP gain and the 0.479 correlation would be confounded rather than causal.
Authors: The saliency weights are computed to reflect the net marginal contribution of each scale interval to retrieval performance when the standard HKS/WKS descriptor is used as-is. This includes any interactions with global normalization or basis projection, which is the relevant quantity for auditing how these descriptors actually behave. The 0.479 Spearman correlation between class descriptor similarity and retrieval failure provides independent evidence that the identified scale patterns are tied to real failure modes rather than ablation artifacts. We will revise §4.2 to explicitly state this interpretation of the ablation and discuss the assumption. revision: partial
-
Referee: [§4.3] §4.3 (Retrieval Experiments): the cross-fold and random-weight controls address arbitrary reweighting but do not address scale-interaction effects. An additional control that renormalizes the descriptor after each ablation (or recomputes the basis) is needed to confirm that the saliency weights reflect genuine per-scale importance.
Authors: Renormalizing or recomputing the basis after ablation would evaluate a different descriptor construction than the standard HKS/WKS that the community uses. Our existing controls already demonstrate that gains are not from arbitrary reweighting, and the distinct scale-dependence patterns observed for HKS versus WKS, together with the mAP lift on hard categories, support that the weights capture genuine importance. We will add a brief acknowledgment of this scope limitation in the revised §4.3. revision: partial
Circularity Check
Saliency weights fitted via ablation on retrieval data then applied to same data for claimed mAP gain
specific steps
-
fitted input called prediction
[Abstract]
"We present a frequency-scale saliency framework that audits these descriptors by quantifying the retrieval-level contribution of each descriptor scale interval through ablation. [...] saliency-weighted retrieval improves mAP on hard categories by 0.156, with cross-fold and random-weight controls confirming that the gain is stable and not due to arbitrary reweighting."
Saliency weights are obtained by measuring ablation-induced changes in retrieval mAP on the evaluation dataset; re-applying those same weights to the identical retrieval task produces the reported gain by construction. The controls test only against random reweighting, not against the fact that the weights were selected to maximize the very metric being improved.
full rationale
The frequency-scale saliency is explicitly constructed by ablating scale intervals and measuring their effect on retrieval performance on the SHREC'11 dataset. These data-derived weights are then used to reweight descriptors and report a 0.156 mAP improvement on hard categories, with only random-weight and cross-fold controls (which do not address the fitting itself). This matches the fitted_input_called_prediction pattern: the 'prediction' of improved retrieval is a direct re-application of parameters optimized on the target metric. No self-citation chains or self-definitional equations appear in the provided text. The controls provide partial independence, keeping the score moderate rather than high.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SHREC'11 is an appropriate benchmark for evaluating 3D shape retrieval methods
invented entities (2)
-
frequency-scale saliency framework
no independent evidence
-
class spectral fingerprints
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the ICCV Workshops
Aubry, M., Schlickewei, U., Cremers, D.: The wave kernel signature: A quantum mechanical approach to shape analysis. In: Proceedings of the ICCV Workshops. pp. 1626–1633 (2011)
2011
-
[2]
Computer Graphics Forum 35(6), 87–119 (2015)
Biasotti, S., Cerri, A., Bronstein, A., Bronstein, M.: Recent trends, applications, and perspectives in 3D shape similarity assessment. Computer Graphics Forum 35(6), 87–119 (2015)
2015
-
[3]
ACM Transactions on Graphics30(1), 1 (2011)
Bronstein, A.M., Bronstein, M.M., Guibas, L.J., Ovsjanikov, M.: Shape Google: Geometric words and expressions for invariant shape retrieval. ACM Transactions on Graphics30(1), 1 (2011)
2011
-
[4]
Springer, New York (2009)
Bronstein, A.M., Bronstein, M.M., Kimmel, R.: Numerical Geometry of Non-Rigid Shapes. Springer, New York (2009)
2009
-
[5]
In: Proceedings of CVPR
Bronstein, M.M., Kokkinos, I.: Scale-invariant heat kernel signatures for non-rigid shape recognition. In: Proceedings of CVPR. pp. 1704–1711 (2010)
2010
-
[6]
In: Proceedings of CVPR
Kokkinos,I.,Bronstein,M.M.,Litman,R.,Bronstein,A.M.:Intrinsicshapecontext descriptors for deformable shapes. In: Proceedings of CVPR. pp. 159–166 (2012)
2012
-
[7]
Lévy, B.: Laplace-Beltrami eigenfunctions towards an algorithm that understands geometry.In:ProceedingsoftheIEEEInternationalConferenceonShapeModeling and Applications. p. 13 (2006)
2006
-
[8]
In: Pro- ceedings of the Eurographics Workshop on 3D Object Retrieval
Lian, Z., Godil, A., Bustos, B., Daoudi, M., Hermans, J., Kawamura, S., Kurita, Y.: SHREC’11 track: Shape retrieval on non-rigid 3D watertight meshes. In: Pro- ceedings of the Eurographics Workshop on 3D Object Retrieval. pp. 79–88 (2011)
2011
-
[9]
IEEE Transactions on Pattern Analysis and Machine Intelligence 36(1), 171–180 (2013)
Litman, R., Bronstein, A.M.: Learning spectral descriptors for deformable shape correspondence. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(1), 171–180 (2013)
2013
-
[10]
ACM Transactions on Graphics31(4), 30 (2012)
Ovsjanikov, M., Ben-Chen, M., Solomon, J., Butscher, A., Guibas, L.: Functional maps: A flexible representation of maps between shapes. ACM Transactions on Graphics31(4), 30 (2012)
2012
-
[11]
Graphical Models97, 17–29 (2018)
Pickup, D., Liu, J., Sun, X., Rosin, P.L., Martin, R.R., Cheng, Z., Lian, Z., Nie, S., Jin, L., Shamai, G., Sahillioğlu, Y., Kavan, L.: An evaluation of canonical forms for non-rigid 3D shape retrieval. Graphical Models97, 17–29 (2018)
2018
-
[12]
Computers and Graphics 33(3), 381–390 (2009)
Reuter, M., Biasotti, S., Giorgi, D., Patanè, G., Spagnuolo, M.: Discrete Laplace- Beltrami operators for shape analysis and segmentation. Computers and Graphics 33(3), 381–390 (2009)
2009
-
[13]
Computer-Aided Design38(4), 342–366 (2006)
Reuter, M., Wolter, F.E., Peinecke, N.: Laplace-Beltrami spectra as shape DNA of surfaces and solids. Computer-Aided Design38(4), 342–366 (2006)
2006
-
[14]
Computer Graphics Forum36(1), 222–236 (2017)
Rodolà, E., Cosmo, L., Bronstein, M.M., Torsello, A., Cremers, D.: Partial func- tional correspondence. Computer Graphics Forum36(1), 222–236 (2017)
2017
-
[15]
In: Proceedings of the Symposium on Geometry Processing
Rustamov, R.M.: Laplace-Beltrami eigenfunctions for deformation invariant shape representation. In: Proceedings of the Symposium on Geometry Processing. pp. 225–233 (2007)
2007
-
[16]
In: Proceedings of the Symposium on Geometry Processing
Sun, J., Ovsjanikov, M., Guibas, L.: A concise and provably informative multi-scale signature based on heat diffusion. In: Proceedings of the Symposium on Geometry Processing. pp. 1383–1392 (2009)
2009
-
[17]
In: Proceedings of ECCV
Tombari, F., Salti, S., Di Stefano, L.: Unique signatures of histograms for local surface description. In: Proceedings of ECCV. pp. 356–369 (2010)
2010
-
[18]
The Visual Computer33, 1497–1509 (2017)
Wan, L., Zou, C., Zhang, H.: Full and partial shape similarity through sparse descriptor reconstruction. The Visual Computer33, 1497–1509 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.