Invoice Haystack: Benchmarking Document Retrieval and Visual Question Answering Under Strong Visual Homogeneity
Pith reviewed 2026-06-29 05:05 UTC · model grok-4.3
The pith
A hybrid text-visual retrieval method reaches 60 percent recall on collections of visually identical invoices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VL-RAG jointly uses text and visual embeddings to retrieve documents from visually homogeneous collections, then applies a VLM-based verification filter; this yields 60.0 percent Recall@1 on Invoice Haystack-500 and improves results on DocHaystack-1000 and InfoHaystack-1000, establishing dual-stream fusion as a consistently superior strategy.
What carries the argument
VL-RAG, the hybrid retrieval-augmented generation framework that fuses text and visual embeddings followed by a VLM verification filter.
If this is right
- Dual-stream fusion raises Recall@1 by up to 13.5 absolute points on the new homogeneous benchmark.
- The same fusion also improves retrieval on the heterogeneous DocHaystack-1000 and InfoHaystack-1000 sets.
- A verification filter after embedding retrieval is required for precise identification when visual templates overlap.
- Future retrieval systems for templated documents should combine modalities instead of using a single embedding stream.
Where Pith is reading between the lines
- Benchmarks that deliberately increase visual homogeneity may become the standard test for enterprise document systems.
- The approach could extend to other high-volume templated domains such as medical forms or financial statements.
- Scaling the verification filter to collections larger than 500 documents would test whether the reported gains persist.
Load-bearing premise
The mean pairwise cosine similarity of 0.73 in the benchmark accurately reflects the retrieval difficulty found in real enterprise repositories that contain thousands of records sharing identical visual templates.
What would settle it
Measure Recall@1 when the same method is run on an enterprise invoice archive of several thousand records that share one visual template; if performance falls below 50 percent the central performance claim would be falsified.
Figures

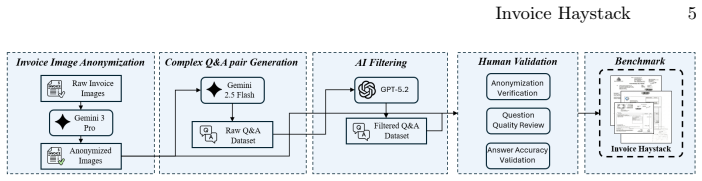
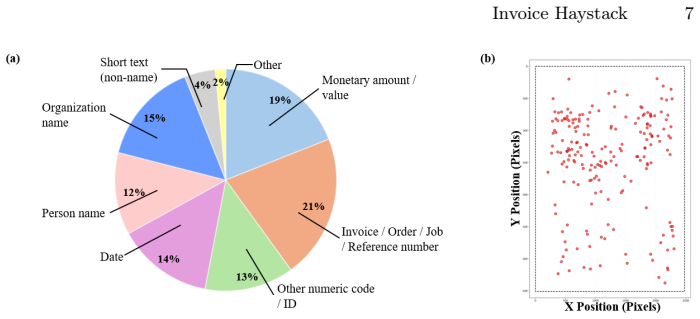
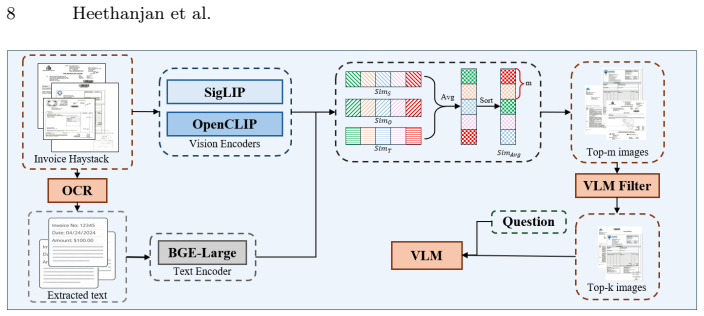
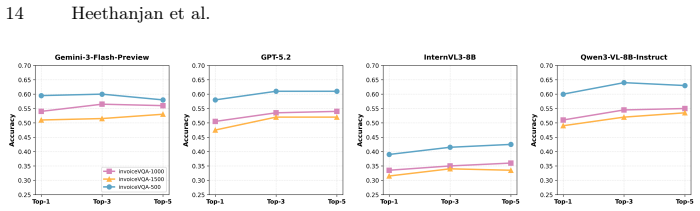
read the original abstract
Vision Language Models have achieved near-human performance on single-document Visual Question Answering, yet their effectiveness degrades significantly when retrieving information from large collections of visually homogeneous documents. Existing multi-document benchmarks aggregate diverse document types, creating artificial separation in embedding space that does not reflect enterprise document repositories where thousands of records share identical visual templates. We identify this as embedding collapse and introduce Invoice Haystack, a benchmark with 1,500 anonymized invoice images paired with 200 discriminative question-answer pairs, specifically designed to stress-test retrieval under strong visual homogeneity. Invoice Haystack exhibits a mean pairwise cosine similarity of 0.73, compared to 0.38 (DocHaystack) and 0.31 (InfoHaystack) in existing benchmarks, posing a fundamentally more challenging retrieval problem. Addressing the identified challenge, we propose VL-RAG, a hybrid retrieval-augmented generation framework that jointly leverages text and visual embeddings to harness the complementary strengths of both modalities, followed by a VLM-based verification filter for precise document identification. VL-RAG achieves 60.0\% Recall@1 on Invoice Haystack-500, outperforming existing state-of-the-art method by up to an absolute 13.5 percentage points. It further improves retrieval considerably on DocHaystack-1000 (77.1\% vs.\ 75.2\%) and InfoHaystack-1000 (84.5\% vs.\ 80.0\%), establishing the proposed dual-stream fusion as a consistently superior retrieval strategy across both homogeneous and heterogeneous document collections.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Invoice Haystack, a benchmark of 1,500 anonymized invoice images paired with 200 QA pairs exhibiting high visual homogeneity (mean pairwise cosine similarity 0.73, vs. 0.38/0.31 in prior benchmarks), to address embedding collapse in enterprise multi-document VQA. It proposes VL-RAG, a hybrid RAG framework combining text and visual embeddings with VLM-based verification, reporting 60.0% Recall@1 on Invoice Haystack-500 (outperforming SOTA by up to 13.5pp) and gains on DocHaystack-1000 and InfoHaystack-1000.
Significance. If the empirical results hold under rigorous validation, the benchmark offers a targeted stress test for visually homogeneous documents that better reflects enterprise conditions than existing heterogeneous collections, while the dual-stream fusion in VL-RAG demonstrates a practical way to mitigate embedding collapse; the work would strengthen evaluation practices and retrieval strategies for template-heavy document corpora.
major comments (2)
- [Abstract] Abstract: the central claim that Invoice Haystack constitutes a 'fundamentally more challenging retrieval problem' rests on the mean pairwise cosine similarity of 0.73, yet no evidence is supplied that this value, the similarity distribution, or query-document alignment matches the scale, template repetition across years, or scan-quality variation of actual enterprise repositories containing thousands of records.
- [Abstract] Abstract: the headline performance numbers (60.0% Recall@1, +13.5pp) are presented without accompanying details on dataset splits, error bars, ablation studies, statistical significance tests, or the precise construction of the Invoice Haystack-500 subset, preventing verification of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Invoice Haystack constitutes a 'fundamentally more challenging retrieval problem' rests on the mean pairwise cosine similarity of 0.73, yet no evidence is supplied that this value, the similarity distribution, or query-document alignment matches the scale, template repetition across years, or scan-quality variation of actual enterprise repositories containing thousands of records.
Authors: The 0.73 mean pairwise cosine similarity is offered as a quantitative indicator of greater visual homogeneity relative to DocHaystack (0.38) and InfoHaystack (0.31). Invoice Haystack is constructed from real anonymized invoices to reproduce the template repetition typical of enterprise settings. Direct matching to proprietary enterprise corpora at full scale is not feasible due to confidentiality. We will revise the abstract to replace 'fundamentally more challenging' with 'presents a more challenging retrieval problem under high visual homogeneity' and add an explicit limitations paragraph on the use of this proxy. revision: partial
-
Referee: [Abstract] Abstract: the headline performance numbers (60.0% Recall@1, +13.5pp) are presented without accompanying details on dataset splits, error bars, ablation studies, statistical significance tests, or the precise construction of the Invoice Haystack-500 subset, preventing verification of the reported gains.
Authors: The abstract is kept concise by design, but the full manuscript details benchmark construction and the Invoice Haystack-500 subset (a 500-document sample from the 1,500-image collection) in Section 3, experimental splits and protocol in Section 4, and ablations plus full results in Section 5. We will update the abstract to reference these sections and ensure error bars and significance tests appear in the results tables in the revision. revision: yes
- Direct empirical evidence that the similarity distribution, query-document alignment, scale, multi-year template repetition, and scan-quality variation exactly match those of real enterprise repositories containing thousands of records cannot be supplied due to data-access and privacy constraints.
Circularity Check
No circularity; benchmark and method are independently constructed and evaluated
full rationale
The paper introduces Invoice Haystack as a new benchmark whose mean pairwise cosine similarity (0.73) is directly computed on the constructed 1,500-image collection and compared to prior benchmarks; VL-RAG is described as a hybrid of existing text and visual embeddings plus a VLM filter, with Recall@1 reported as an empirical evaluation on this benchmark and on DocHaystack/InfoHaystack. No equations, fitted parameters, self-citations, or ansatzes are present that would reduce the reported gains to a quantity defined by the authors' own prior choices or by construction. The derivation chain consists of standard retrieval evaluation and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text and visual embeddings provide complementary information for document retrieval under visual homogeneity.
Reference graph
Works this paper leans on
-
[1]
ACM Computing Surveys54(6), 1–35 (2021)
van der Aalst, J., Weske, M., Grünbauer, D.: Workflow patterns in invoice process- ing automation. ACM Computing Surveys54(6), 1–35 (2021)
2021
- [2]
-
[3]
com/ocr-sdk/(2024), accessed: 2024-02-23
ABBYY: ABBYY FineReader Engine: Advanced OCR SDK.https://www.abbyy. com/ocr-sdk/(2024), accessed: 2024-02-23
2024
-
[4]
In: NeurIPS (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: A visual language model for few-shot learning. In: NeurIPS (2022)
2022
-
[5]
Information Management Journal47(3), 28–41 (2023)
Anderson, M., Davis, P., Wilson, K.: Survey of enterprise document management practices. Information Management Journal47(3), 28–41 (2023)
2023
-
[6]
Anthropic: The claude 3 model family: Opus, sonnet, haiku. Tech. rep., Anthropic (2024)
2024
-
[7]
Anthropic: Claude 3.7 sonnet model card. Tech. rep., Anthropic (2025),https: //www.anthropic.com/news/claude-3-7-sonnet
2025
-
[8]
In: The Twelfth International Con- ference on Learning Representations (2023)
Asai, A., Wu, Z., Wang, Y., Sil, A., Hajishirzi, H.: Self-rag: Learning to retrieve, generate, and critique through self-reflection. In: The Twelfth International Con- ference on Learning Representations (2023)
2023
-
[9]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Nougat: Neural Optical Understanding for Academic Documents
Blecher, L., Cucurull, G., Scialom, T., Stojnic, R.: Nougat: Neural optical under- standing for academic documents. arXiv preprint arXiv:2308.13418 (2023) 16 Heethanjan et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chang, Y., Narang, M., Suzuki, H., Cao, G., Gao, J., Bisk, Y.: Webqa: Multihop and multimodal qa. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16495–16504 (2022)
2022
-
[12]
Chen, J., Xu, D., Fei, J., Feng, C.M., Elhoseiny, M.: Document haystacks: Vision- languagereasoningoverpilesof1000+documents.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 24817–24826 (2025)
2025
-
[13]
In: Pro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing
Chen, W., Hu, H., Chen, X., Verga, P., Cohen, W.: Murag: Multimodal retrieval- augmented generator for open question answering over images and text. In: Pro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 5558–5570 (2022)
2022
-
[14]
Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., Jitsev, J.: Reproducible scaling laws for contrastive language-image learning. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). p. 2818–2829. IEEE (Jun 2023).https://doi. org/10.1109/cvpr52729.2023.00276,http://dx.doi.o...
-
[15]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
2023
-
[16]
arXiv preprint arXiv:2203.06482 (2022)
Davis, L., Chen, S., Soricut, V., Bansal, M.: Visually-rich document understanding: Challenges and opportunities. arXiv preprint arXiv:2203.06482 (2022)
-
[17]
DeepMind, G.: Gemini 2.5 flash technical report. Tech. rep., Google DeepMind (2025),https://deepmind.google/models/gemini/flash
2025
-
[18]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[19]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [20]
-
[21]
Du, Y., Tian, M., Ronanki, S., Rongali, S., Bodapati, S., Galstyan, A., Wells, A., Schwartz, R., Huerta, E.A., Peng, H.: Context length alone hurts llm performance despite perfect retrieval. arXiv preprint arXiv:2510.05381 (2025)
-
[22]
ColPali: Efficient Document Retrieval with Vision Language Models
Faysse, M., Sibille, H., Wu, T., Omrani, B., Viaud, G., Hudelot, C., Colombo, P.: Colpali: Efficient document retrieval with vision language models. arXiv preprint arXiv:2407.01449 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Google DeepMind: Gemini (2026),https://deepmind.google/models/gemini/, accessed: 2026-03-04
2026
-
[24]
Google DeepMind: Gemini 3.1 pro model card (February 2026),https : / / deepmind.google/models/model-cards/gemini-3-1-pro/, accessed: 2026-03-04
2026
-
[25]
Advances in Neural Information Processing Systems34, 39–50 (2021)
Gu, J., Kuen, J., Morariu, V.I., Zhao, H., Jain, R., Barmpalios, N., Nenkova, A., Sun, T.: Unidoc: Unified pretraining framework for document understanding. Advances in Neural Information Processing Systems34, 39–50 (2021)
2021
-
[26]
In: International conference on machine learning
Guu, K., Lee, K., Tung, Z., Pasupat, P., Chang, M.: Retrieval augmented language model pre-training. In: International conference on machine learning. pp. 3929–
-
[27]
PMLR (2020) Invoice Haystack 17
2020
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Z., Iscen, A., Sun, C., Wang, Z., Chang, K.W., Sun, Y., Schmid, C., Ross, D.A., Fathi, A.: Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23369–23379 (2023)
2023
-
[29]
In: Proceedings of ACM Multimedia (2022)
Huang, Y., Lv, T., Cui, L., Lu, Y., Wei, F.: Layoutlmv3: Pre-training for document ai with unified text and image masking. In: Proceedings of ACM Multimedia (2022)
2022
-
[30]
In: Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume
Izacard, G., Grave, E.: Leveraging passage retrieval with generative models for open domain question answering. In: Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume. pp. 874–880 (2021)
2021
-
[31]
Journal of Machine Learning Research24(251), 1–43 (2023)
Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi- Yu, J., Joulin, A., Riedel, S., Grave, E.: Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research24(251), 1–43 (2023)
2023
-
[32]
In: EMNLP (2020)
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: EMNLP (2020)
2020
- [33]
-
[34]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Katti, A.R., Reisswig, C., Guder, C., Brarda, S., Bickel, S., Höhne, J., Faddoul, J.B.: Chargrid: Towards understanding 2d documents. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4459–4469 (2018)
2018
- [35]
-
[36]
In: SIGIR (2020)
Khattab, O., Zaharia, M.: Colbert: Efficient and effective passage search via con- textualized late interaction over bert. In: SIGIR (2020)
2020
-
[37]
In: European Conference on Computer Vision
Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., Park, S.: Ocr-free document understanding transformer. In: European Conference on Computer Vision. pp. 498–517. Springer (2022)
2022
-
[38]
arXiv preprint arXiv:2412.08802 (2024)
Koukounas, A., Mastrapas, G., Eslami, S., Wang, B., Akram, M.K., Günther, M., Mohr, I., Sturua, S., Wang, N., Xiao, H.: jina-clip-v2: Multilingual multimodal embeddings for text and images. arXiv preprint arXiv:2412.08802 (2024)
-
[39]
Transactions of the Association for Compu- tational Linguistics7, 453–466 (2019)
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., et al.: Natural questions: a bench- mark for question answering research. Transactions of the Association for Compu- tational Linguistics7, 453–466 (2019)
2019
-
[40]
In: International Conference on Machine Learning
Lee, K., Joshi, M., Turc, I.R., Hu, H., Liu, F., Eisenschlos, J.M., Khandelwal, U., Shaw, P., Chang, M.W., Toutanova, K.: Pix2struct: Screenshot parsing as pretrain- ing for visual language understanding. In: International Conference on Machine Learning. pp. 18893–18912. PMLR (2023)
2023
-
[41]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoy- anov, V., Zettlemoyer, L.: Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 7871– 7880 (2020)
2020
-
[42]
knowledge-intensive nlp tasks
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for 18 Heethanjan et al. knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[43]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[45]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[46]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[47]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[48]
Advances in neural information processing systems32(2019)
Lu,J.,Batra,D.,Parikh,D.,Lee,S.:Vilbert:Pretrainingtask-agnosticvisiolinguis- tic representations for vision-and-language tasks. Advances in neural information processing systems32(2019)
2019
-
[49]
In: Findings of the association for computational linguistics: ACL 2022
Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279 (2022)
2022
-
[50]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Mathew, M., Bagal, V., Tito, R., Karatzas, D., Valveny, E., Jawahar, C.: Info- graphicvqa. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1697–1706 (2022)
2022
-
[51]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Mathew, M., Karatzas, D., Jawahar, C.: Docvqa: A dataset for vqa on document images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209 (2021)
2021
-
[52]
arXiv preprint arXiv:2504.08748 (2025)
Mei, L., Mo, S., Yang, Z., Chen, C.: A survey of multimodal retrieval-augmented generation. arXiv preprint arXiv:2504.08748 (2025)
-
[53]
Nomic Embed: Training a Reproducible Long Context Text Embedder
Nussbaum, Z., Morris, J.X., Duderstadt, B., Mulyar, A.: Nomic embed: Training a reproducible long context text embedder. arXiv preprint arXiv:2402.01613 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
OpenAI: Gpt-4o: Multimodal capabilities with enhanced reasoning. Tech. rep., OpenAI (2024)
2024
-
[55]
OpenAI API Documentation (2026),https://developers
OpenAI: Models. OpenAI API Documentation (2026),https://developers. openai.com/api/docs/guides/latest-model, accessed: 2026-03-04
2026
-
[56]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
arXiv preprint arXiv:2306.16713 (2023)
Penamakuri, A.S., Gupta, M., Gupta, M.D., Mishra, A.: Answer mining from a pool of images: Towards retrieval-based visual question answering. arXiv preprint arXiv:2306.16713 (2023)
-
[58]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[59]
Robertson, S., Zaragoza, H.: The probabilistic relevance framework: BM25 and beyond, vol. 4. Now Publishers Inc (2009) Invoice Haystack 19
2009
-
[60]
In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR)
Schreiber, S., Agne, S., Wolf, I., Dengel, A., Ahmed, S.: Deepdesrt: Deep learning for detection and structure recognition of tables in document images. In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR). vol. 1, pp. 1162–1167. IEEE (2017)
2017
-
[61]
Transactions of the Association for Computational Linguistics10, 376–392 (2022)
Shen, Z., Lo, K., Wang, L.L., Kuehl, B., Weld, D.S., Downey, D.: VILA: Improv- ing structured content extraction from scientific PDFs using visual layout groups. Transactions of the Association for Computational Linguistics10, 376–392 (2022). https://doi.org/10.1162/tacl_a_00466,https://aclanthology.org/2022. tacl-1.22/
-
[62]
In: Document Engineering (2023)
Smith, B., Johnson, R.: Template diversity in enterprise invoice repositories: An empirical study. In: Document Engineering (2023)
2023
-
[63]
In: Ninth international con- ference on document analysis and recognition (ICDAR 2007)
Smith, R.: An overview of the tesseract ocr engine. In: Ninth international con- ference on document analysis and recognition (ICDAR 2007). vol. 2, pp. 629–633. IEEE (2007)
2007
-
[64]
In: ICLR (2021)
Talmor, A., Yoran, O., Catav, A., Lahav, D., Wang, Y., Asai, A., Ilharco, G., Hajishirzi, H., Berant, J.: Multimodalqa: Complex question answering over text, tables and images. In: ICLR (2021)
2021
-
[65]
In: Proceedings of the AAAI Conference on Artificial Intel- ligence
Tanaka, R., Nishida, K., Yoshida, S.: Visualmrc: Machine reading comprehension on document images. In: Proceedings of the AAAI Conference on Artificial Intel- ligence. vol. 35, pp. 13878–13888 (2021)
2021
-
[66]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Tang, Z., Yang, Z., Wang, G., Fang, Y., Liu, Y., Zhu, C., Zeng, M., Zhang, C., Bansal, M.: Unifying vision, text, and layout for universal document processing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 19254–19264 (2023)
2023
-
[67]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[68]
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., Wang, Z., Chen, Z., Zhang, H., Yang, G., Wang, H., Wei, Q., Yin, J., Li, W., Cui, E., Chen, G., Ding, Z., Tian, C., Wu, Z., Xie, J., Li, Z., Yang, B., Duan, Y., Wang, X., Hou, Z., Hao, H., Zhang, T., Li, S., Zhao, X., Duan, H., Deng, N., Fu, B., He, Y., Wang, Y., He,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
In: FinNLP Workshop (2023)
Wang, Z., Huang, M., Xu, Y., Chen, H.: Automated financial document processing: Challenges and opportunities. In: FinNLP Workshop (2023)
2023
- [70]
-
[71]
C-Pack: Packed Resources For General Chinese Embeddings
Xiao, F., Luan, H., Zhao, M., Li, J., Wu, L., Xu, J.: Bge: A family of general text embeddings. arXiv preprint arXiv:2309.07597 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: Layoutlm: Pre-training of text and layout for document image understanding. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 1192–1200 (2020) 20 Heethanjan et al
2020
-
[73]
In: Proceedings of the Annual Meeting of the Asso- ciation for Computational Linguistics (ACL) (2021)
Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., Lu, Y., Florencio, D., Zhang, C., Che, W., Zhang, M., Zhou, L.: Layoutlmv2: Multi-modal pre-training for visually- rich document understanding. In: Proceedings of the Annual Meeting of the Asso- ciation for Computational Linguistics (ACL) (2021)
2021
-
[74]
Yan, S.Q., Gu, J.C., Zhu, Y., Ling, Z.H.: Corrective retrieval augmented generation (2024)
2024
-
[75]
arXiv preprint arXiv:2211.12561 (2022)
Yasunaga, M., Aghajanyan, A., Shi, W., James, R., Leskovec, J., Liang, P., Lewis, M., Zettlemoyer, L., Yih, W.t.: Retrieval-augmented multimodal language model- ing. arXiv preprint arXiv:2211.12561 (2022)
- [76]
-
[77]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
2023
-
[78]
In: 2019 International conference on document analysis and recog- nition (ICDAR)
Zhong, X., Tang, J., Yepes, A.J.: Publaynet: largest dataset ever for document layout analysis. In: 2019 International conference on document analysis and recog- nition (ICDAR). pp. 1015–1022. IEEE (2019)
2019
-
[79]
In: ICML (2024)
Zhou, Y., Wang, X., Kan, M.: Understanding embedding collapse in vision- language models. In: ICML (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.