Imagine to Ensure Safety in Hierarchical Reinforcement Learning
Pith reviewed 2026-06-26 10:46 UTC · model grok-4.3
The pith
A hierarchical safe RL method learns a world model so high-level subgoals and low-level imagined rollouts together keep agents within safety budgets on long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
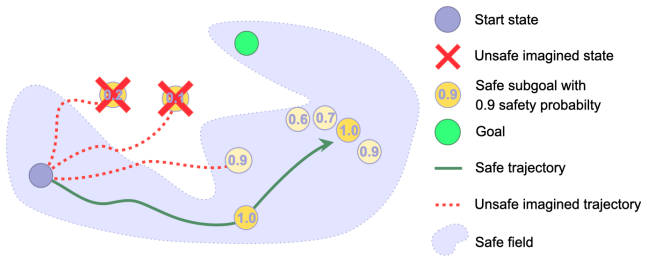
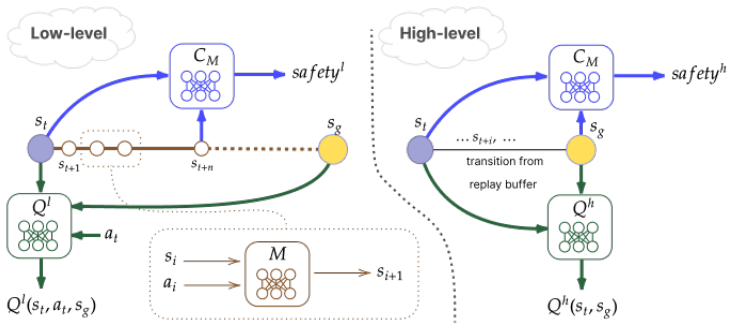
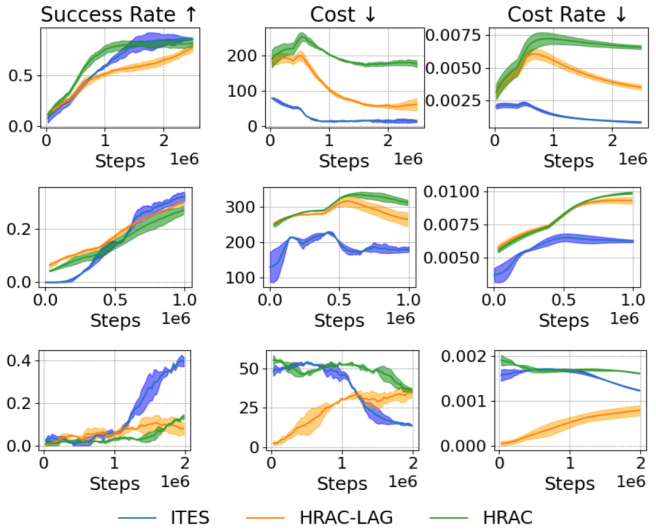
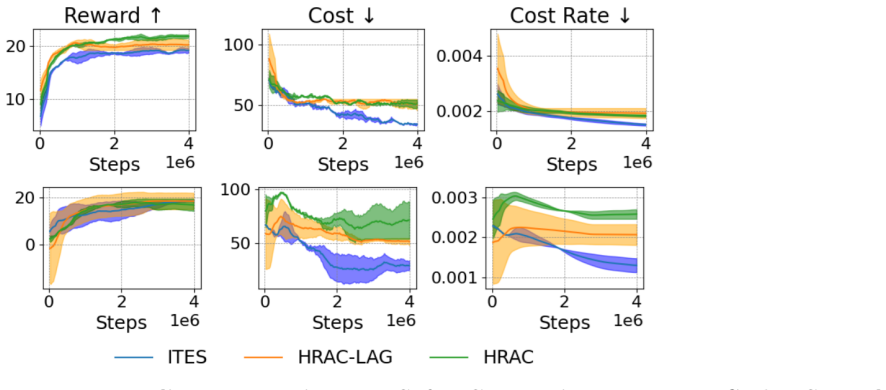
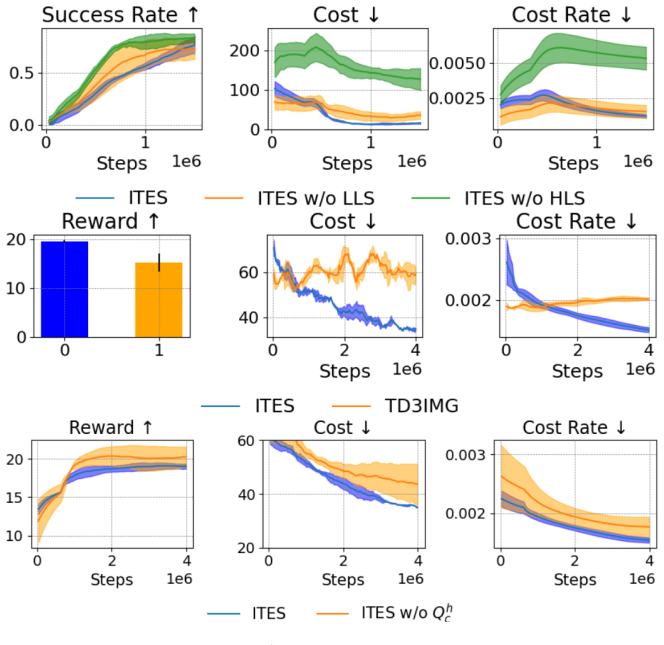
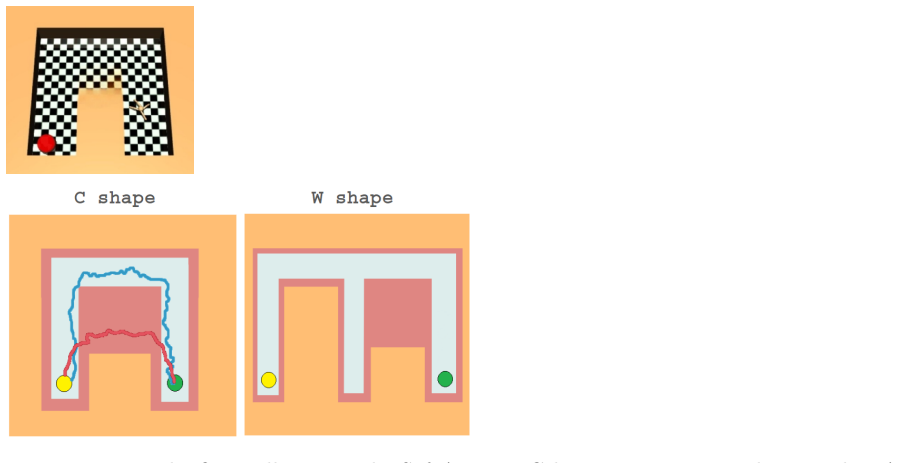
By training a world model, the high-level policy generates intermediate subgoals that bias exploration toward safe areas and the low-level policy selects actions via imagined trajectories in that model to reach the subgoals while staying inside the safety budget; this combination yields higher success rates and stronger empirical constraint satisfaction than existing safe RL baselines on long-horizon navigation and manipulation tasks with high-dimensional actions.
What carries the argument
The central mechanism is the learned world model that supplies imagined rollouts to the low-level policy for constraint-aware action selection while the high-level policy supplies safe subgoals.
If this is right
- The approach solves long-horizon tasks with high-dimensional action spaces that prior safe methods cannot handle effectively.
- Safety budgets are met consistently across random seeds where earlier methods fail.
- Both success rate and empirical constraint satisfaction improve simultaneously.
- The same hierarchical structure with imagined rollouts can be applied to other long-horizon navigation and manipulation problems.
Where Pith is reading between the lines
- If the world model remains accurate over long horizons, the method could reduce the amount of real unsafe interaction needed during training.
- The subgoal-plus-imagination split might transfer to other hierarchical control problems that require both planning and safety.
- Combining this structure with different constraint formulations could extend the safety guarantees beyond the budgets tested here.
Load-bearing premise
A sufficiently accurate world model can be learned so that imagined low-level rollouts reliably avoid unsafe behaviors without compounding estimation errors.
What would settle it
Running the method on the same long-horizon navigation and manipulation tasks and finding that it violates the safety budget on multiple random seeds or fails to outperform prior safe RL baselines would falsify the central claim.
Figures



read the original abstract
This work investigates the safe exploration problem in reinforcement learning, where an agent must maximize cumulative performance while simultaneously satisfying safety constraints. This challenge becomes even more pronounced in long-horizon tasks, where existing safe methods face fundamental limitations due to compounding estimation errors and restricted exploration capabilities. To address this problem, we propose a method that combines a learnable world model with two complementary policies a high-level policy and a low-level policy to promote safety at both hierarchical levels. The high-level policy generates intermediate subgoals that bias exploration toward safe regions, while the low-level policy uses imagined rollouts in the learned world model to reduce unsafe behaviors when reaching these subgoals. The proposed method was evaluated on challenging long-horizon navigation and manipulation tasks with high-dimensional action spaces, where it significantly outperforms existing Safe RL baselines in both success rate and strong empirical constraint satisfaction, consistently meeting the prescribed safety budget across seeds, while prior approaches fail to effectively solve these complex long-horizon scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical safe RL framework combining a learnable world model with a high-level policy that generates safe subgoals and a low-level policy that uses imagined rollouts to reduce unsafe actions while pursuing those subgoals. The central claim is that this approach overcomes compounding estimation errors in prior safe RL methods and achieves superior success rates plus reliable constraint satisfaction on long-horizon navigation and manipulation tasks with high-dimensional actions.
Significance. If the empirical results and safety guarantees hold under quantitative scrutiny, the work would address a recognized limitation of safe RL on long-horizon problems by leveraging hierarchy and model-based imagination, potentially enabling safer exploration in robotics domains where existing methods fail to solve the tasks at all.
major comments (2)
- [Abstract] Abstract: the claim that the method 'significantly outperforms existing Safe RL baselines in both success rate and strong empirical constraint satisfaction, consistently meeting the prescribed safety budget across seeds' is presented without any numerical results, baseline names, success-rate values, constraint-violation metrics, or statistical tests; this absence is load-bearing for the central empirical claim.
- [Evaluation] Evaluation section: no ablation isolating world-model prediction error, no quantitative bound on compounding error over the claimed long horizons, and no comparison of imagined-rollout safety against model-free low-level baselines are reported, leaving the key assumption that imagined rollouts reliably reduce unsafe behaviors unverified.
minor comments (1)
- [Abstract] The abstract and method description would benefit from explicit definitions of the safety budget and the precise form of the constraint (e.g., expected cumulative cost or per-step threshold) to allow direct comparison with prior constrained RL work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical presentation. We address each major comment below and commit to revisions that directly respond to the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'significantly outperforms existing Safe RL baselines in both success rate and strong empirical constraint satisfaction, consistently meeting the prescribed safety budget across seeds' is presented without any numerical results, baseline names, success-rate values, constraint-violation metrics, or statistical tests; this absence is load-bearing for the central empirical claim.
Authors: We agree that the abstract would be strengthened by including concrete numerical support for the performance claims. In the revised manuscript we will update the abstract to report specific success rates, constraint-violation metrics, baseline names, and reference to statistical significance across seeds, while remaining within length constraints. revision: yes
-
Referee: [Evaluation] Evaluation section: no ablation isolating world-model prediction error, no quantitative bound on compounding error over the claimed long horizons, and no comparison of imagined-rollout safety against model-free low-level baselines are reported, leaving the key assumption that imagined rollouts reliably reduce unsafe behaviors unverified.
Authors: Our current evaluation demonstrates outperformance on long-horizon tasks, but we acknowledge the absence of the requested targeted analyses. We will add (i) an ablation isolating world-model prediction error, (ii) quantitative analysis or bounds on compounding error across the evaluated horizons, and (iii) direct comparisons of imagined-rollout safety versus model-free low-level baselines. These additions will appear in the revised evaluation section. revision: yes
Circularity Check
No circularity detected; method and claims are self-contained
full rationale
The provided abstract and manuscript description outline a hierarchical safe RL approach using a learnable world model, high-level subgoal policy, and low-level imagined rollouts. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear. The central claims rest on empirical evaluation against baselines on navigation/manipulation tasks, which is independent of the method definition and does not reduce to its inputs by construction. This is the expected non-finding for a method paper whose derivation chain contains no visible circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benchmarking safe exploration in deep reinforce- ment learning.arXiv preprint arXiv:1910.01708, 2019
Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep reinforce- ment learning.arXiv preprint arXiv:1910.01708, 2019
Pith/arXiv arXiv 1910
-
[2]
CRC press, 1999
Eitan Altman.Constrained Markov Decision Processes, volume 7. CRC press, 1999
1999
-
[3]
Safedreamer: Safe reinforcement learning with world models
Weidong Huang, Jiaming Ji, Borong Zhang, Chunhe Xia, and Yaodong Yang. Safedreamer: Safe reinforcement learning with world models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[4]
A comprehensive survey on safe reinforcement learning
Javier Garcıa and Fernando Fernández. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1):1437–1480, 2015
2015
-
[5]
Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
Lukas Brunke, Melissa Greeff, Adam W Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
2022
-
[6]
Model-based safe deep reinforcement learning via a constrained proximal policy optimization algorithm
Ashish K Jayant and Shalabh Bhatnagar. Model-based safe deep reinforcement learning via a constrained proximal policy optimization algorithm. InAdvances in Neural Information Processing Systems, volume 35, pages 24432–24445. Curran Associates, Inc., 2022
2022
-
[7]
Safe reinforcement learning from pixels using a stochastic latent representation
Yannick Hogewind, Thiago D Simao, Tal Kachman, and Nils Jansen. Safe reinforcement learning from pixels using a stochastic latent representation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[8]
Learning to walk in the real world with minimal human effort
Sehoon Ha, Peng Xu, Zhenyu Tan, Sergey Levine, and Jie Tan. Learning to walk in the real world with minimal human effort. InConference on Robot Learning, pages 1110–1120. PMLR, 2021
2021
-
[9]
Towards safe reinforcement learning with a safety editor policy
Haonan Yu, Wei Xu, and Haichao Zhang. Towards safe reinforcement learning with a safety editor policy. InAdvances in Neural Information Processing Systems, volume 35, pages 2608–2621. Curran Associates, Inc., 2022
2022
-
[10]
Goal-conditioned reinforcement learning with imagined subgoals
Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Goal-conditioned reinforcement learning with imagined subgoals. InInternational Conference on Machine Learning, pages 1430–1440. PMLR, 2021. 23
2021
-
[11]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[12]
Hierarchical reinforcement learning with hindsight
Andrew Levy, Robert Platt, and Kate Saenko. Hierarchical reinforcement learning with hindsight. InInternational Conference on Learning Representations, 2019
2019
-
[13]
Generating adjacency- constrained subgoals in hierarchical reinforcement learning
Tianren Zhang, Shangqi Guo, Tian Tan, Xiaolin Hu, and Feng Chen. Generating adjacency- constrained subgoals in hierarchical reinforcement learning. InAdvances in Neural Information Processing Systems, volume 33, pages 21579–21590. Curran Associates, Inc., 2020
2020
-
[14]
Ajay Mandlekar, Danfei Xu, Roberto Martín-Martín, Silvio Savarese, and Li Fei-Fei. Learn- ing to generalize across long-horizon tasks from human demonstrations.arXiv preprint arXiv:2003.06085, 2020
arXiv 2003
-
[15]
Continuous curriculum learning for reinforcement learning
Andrea Bassich and Daniel Kudenko. Continuous curriculum learning for reinforcement learning. InProceedings of the 2nd Scaling-Up Reinforcement Learning (SURL) Workshop. IJCAI, 2019
2019
-
[16]
Model-free neural lyapunov control for safe robot navigation
Zikang Xiong, Joe Eappen, Ahmed H Qureshi, and Suresh Jagannathan. Model-free neural lyapunov control for safe robot navigation. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5572–5579. IEEE, 2022
2022
-
[17]
Imagination-augmented hierarchical reinforcement learning for safe and interactive autonomous driving in urban environments
Sang-Hyun Lee, Yoonjae Jung, and Seung-Woo Seo. Imagination-augmented hierarchical reinforcement learning for safe and interactive autonomous driving in urban environments. IEEE Transactions on Intelligent Transportation Systems, 2024
2024
-
[18]
Safe robot navigation using constrained hierarchical reinforcement learning
Felippe Schmoeller Roza, Hassan Rasheed, Karsten Roscher, Xiangyu Ning, and Stephan Günnemann. Safe robot navigation using constrained hierarchical reinforcement learning. In 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), pages 737–742. IEEE, 2022
2022
-
[19]
Risk conditioned neural motion planning
Xin Huang, Meng Feng, Ashkan Jasour, Guy Rosman, and Brian Williams. Risk conditioned neural motion planning. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9057–9063. IEEE, 2021
2021
-
[20]
Constrained update projection approach to safe policy optimization
Long Yang, Jiaming Ji, Juntao Dai, Linrui Zhang, Binbin Zhou, Pengfei Li, Yaodong Yang, and Gang Pan. Constrained update projection approach to safe policy optimization. InAdvances in Neural Information Processing Systems, volume 35, pages 9111–9124. Curran Associates, Inc., 2022
2022
-
[21]
First order constrained optimization in policy space
Yiming Zhang, Quan Vuong, and Keith Ross. First order constrained optimization in policy space. InAdvances in Neural Information Processing Systems, volume 33, pages 15338–15349. Curran Associates, Inc., 2020
2020
-
[22]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
-
[23]
When to trust your model: Model-based policy optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. 24
2019
-
[24]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[25]
Xingzhou Lou, Junge Zhang, Ziyan Wang, Kaiqi Huang, and Yali Du. Safe reinforcement learning with free-form natural language constraints and pre-trained language models.arXiv preprint arXiv:2401.07553, 2024
arXiv 2024
-
[26]
Openai gym.arXiv preprint arXiv:1606.01540, 2016
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016. 25
Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.