Scalable Inference-Time Annealing with Surrogate Likelihood Estimators
Pith reviewed 2026-06-28 22:53 UTC · model grok-4.3
The pith
SITA retrains flow-based models with energy-based surrogate likelihoods to anneal samples down a temperature ladder without computing divergences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
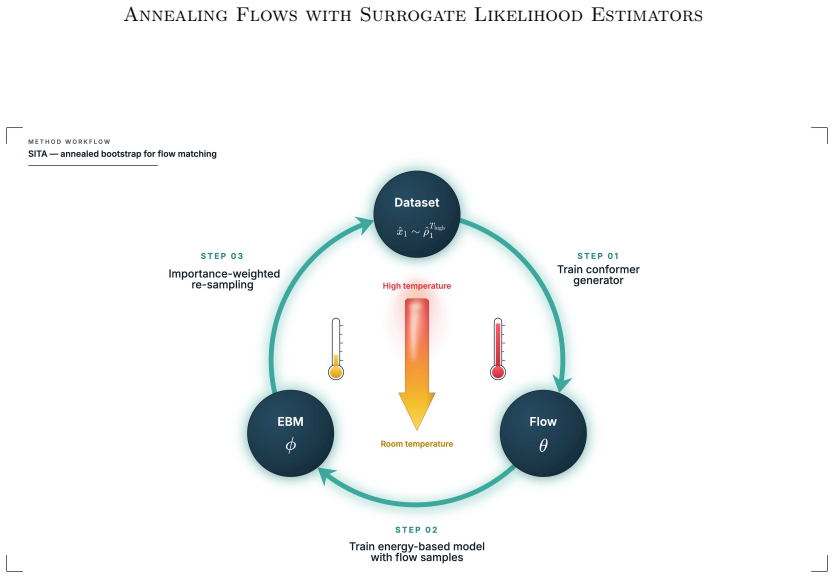
SITA performs scalable inference-time annealing by retraining flow-based generative models along a temperature ladder, where an auxiliary energy-based model supplies surrogate likelihood estimates that replace the divergence-based importance weights required in prior methods.
What carries the argument
energy-based surrogate likelihood estimator that replaces divergence-based importance weights during retraining of the flow model at each temperature step
If this is right
- The method becomes applicable to molecular systems where computing the score-field divergence is intractable.
- Retraining cost is reduced because surrogate likelihood evaluation is cheaper than divergence estimation at each annealing step.
- Sample quality at low temperatures improves without the overhead that previously limited annealing depth.
- The approach stays within the flow-model family while sidestepping a specific computational bottleneck.
Where Pith is reading between the lines
- The same surrogate-likelihood trick might transfer to other generative architectures that currently rely on divergence weighting.
- If the energy-based surrogate remains accurate at very low temperatures, the method could reach conformational states that are inaccessible to standard molecular dynamics.
- Testing the surrogate accuracy on a held-out set of configurations would give an early diagnostic before full annealing runs.
Load-bearing premise
An auxiliary energy-based model can supply sufficiently accurate and unbiased surrogate likelihood estimates to stand in for the true divergence terms across the entire temperature ladder.
What would settle it
Running SITA and a divergence-based baseline on alanine dipeptide or tripeptide and finding that the surrogate version produces distributions with measurably higher deviation from the reference Boltzmann density or lower effective sample size.
Figures
read the original abstract
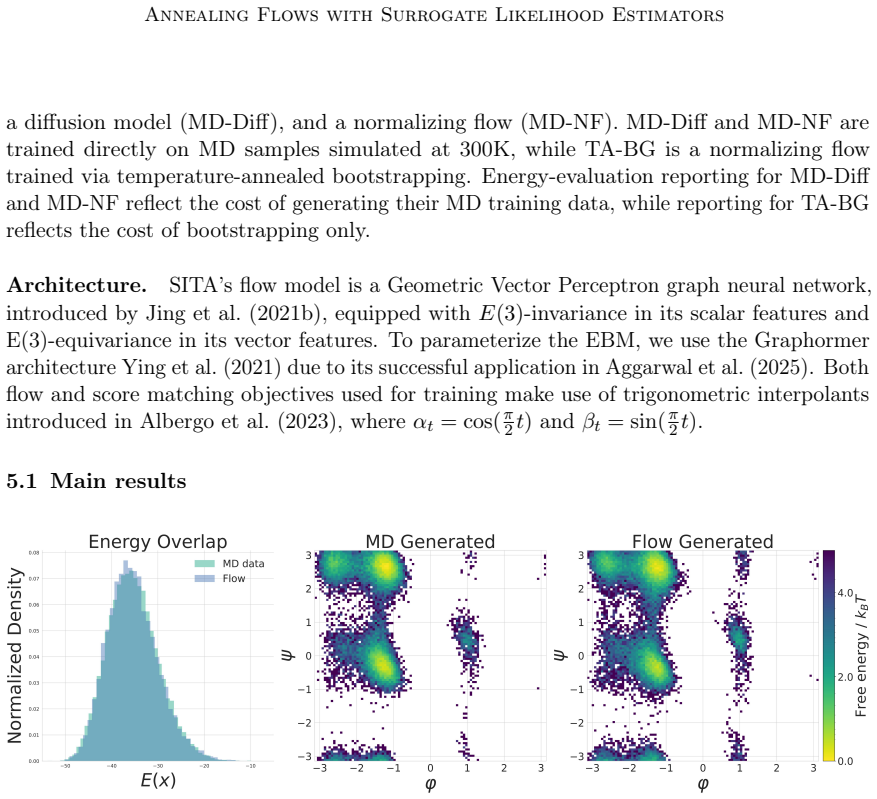
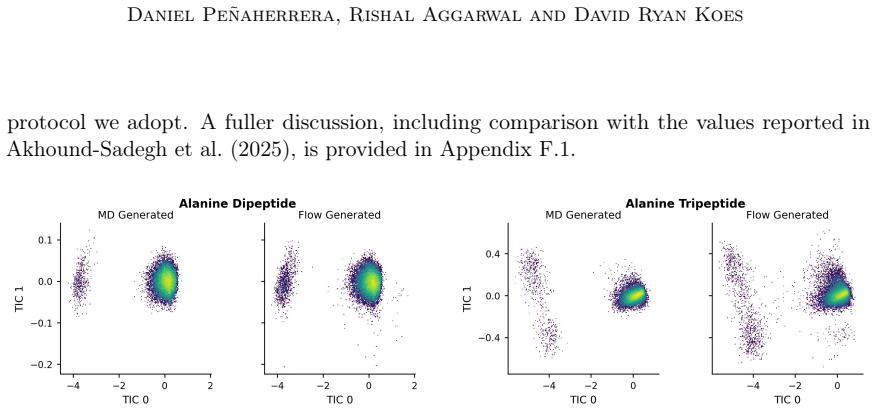
A long standing challenge in computational chemistry and biophysics is efficiently sampling the Boltzmann distribution of molecules. Advances in generative modeling have been proposed to address the limitations of conventional sampling techniques by eliminating the computational cost of simulation. A promising direction is iteratively finetuning diffusion models along a temperature ladder whereby training data is generated via importance sampling during inference-time annealing. Unfortunately, these methods require computing a divergence over the score field to estimate importance weights, rendering them intractable for larger systems. Here we present scalable inference-time annealing (SITA), which retrains flow-based models to generate samples at progressively lower temperatures using an energy-based model to facilitate fast surrogate likelihoods. We demonstrate state-of-the-art performance on both Alanine Dipeptide and Alanine Tripeptide while avoiding costly divergence terms. Our code is available at https://github.com/countrsignal/sita.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Scalable Inference-Time Annealing (SITA), a method that retrains flow-based models along a temperature ladder for sampling Boltzmann distributions of molecules. It replaces divergence-based importance weights with fast surrogate likelihoods obtained from an auxiliary energy-based model, claiming this enables scalable inference-time annealing and yields state-of-the-art performance on Alanine Dipeptide and Alanine Tripeptide while avoiding costly divergence computations. Code is released at https://github.com/countrsignal/sita.git.
Significance. If the surrogate estimates remain sufficiently accurate and unbiased across the annealing schedule, the approach could meaningfully extend generative modeling techniques to larger biomolecular systems by eliminating a key computational bottleneck. The public release of code is a positive step toward reproducibility.
major comments (1)
- [Abstract / Method description] The central performance claim depends on the surrogate likelihoods from the retrained energy-based model supplying sufficiently accurate and unbiased estimates to replace divergence-based importance weights throughout the temperature ladder. However, the manuscript provides no direct diagnostic (e.g., KL divergence, log-weight error, or effective sample size comparison between surrogate and exact likelihoods on held-out configurations) at each temperature step, leaving open the possibility that accumulated approximation error degrades sample quality even when final metrics appear competitive.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment below and will revise the manuscript accordingly to strengthen the validation of the surrogate likelihoods.
read point-by-point responses
-
Referee: [Abstract / Method description] The central performance claim depends on the surrogate likelihoods from the retrained energy-based model supplying sufficiently accurate and unbiased estimates to replace divergence-based importance weights throughout the temperature ladder. However, the manuscript provides no direct diagnostic (e.g., KL divergence, log-weight error, or effective sample size comparison between surrogate and exact likelihoods on held-out configurations) at each temperature step, leaving open the possibility that accumulated approximation error degrades sample quality even when final metrics appear competitive.
Authors: We agree that direct diagnostics comparing the surrogate likelihoods to exact divergence-based weights would provide stronger support for the central claim. In the revised manuscript we will add evaluations of KL divergence between surrogate and exact log-weights, log-weight error statistics, and effective sample size ratios on held-out configurations at each temperature step along the annealing ladder. These results will be reported both in the main text and in an expanded supplementary section. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks, not self-defined fits
full rationale
The paper introduces SITA by retraining flow models with an auxiliary energy-based surrogate for likelihoods during temperature annealing, avoiding explicit divergence terms. The central result is an empirical demonstration of state-of-the-art sampling performance on Alanine Dipeptide and Tripeptide. No derivation step reduces a claimed prediction to a quantity defined by the method itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise depends on a self-citation chain or imported uniqueness theorem. The surrogate is presented as an independent modeling choice whose accuracy is assessed via downstream sampling quality on held-out molecular systems, keeping the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Aggarwal, J. Chen, N. M. Boffi, and D. R. Koes. BoltzNCE : Learning likelihoods for boltzmann generation with stochastic interpolants and noise contrastive estimation. arXiv preprint arXiv:2507.00846, 2025
arXiv 2025
-
[2]
T. Akhound-Sadegh, J. Rector-Brooks, A. J. Bose, S. Mittal, P. Lemos, C.-H. Liu, M. Sendera, S. Ravanbakhsh, G. Gidel, Y. Bengio, N. Malkin, and A. Tong. Iterated denoising energy matching for sampling from boltzmann densities, 2024. URL https://arxiv.org/abs/2402.06121
arXiv 2024
-
[3]
T. Akhound-Sadegh, J. Lee, A. J. Bose, V. De Bortoli, A. Doucet, M. M. Bronstein, D. Beaini, S. Ravanbakhsh, K. Neklyudov, and A. Tong. Progressive inference-time annealing of diffusion models for sampling from boltzmann densities. arXiv preprint arXiv:2506.16471, 2025
arXiv 2025
-
[4]
M. S. Albergo and E. Vanden-Eijnden. Nets: A non-equilibrium transport sampler, 2025. URL https://arxiv.org/abs/2410.02711
arXiv 2025
-
[5]
M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797, 2023
Pith/arXiv arXiv 2023
-
[6]
D. Blessing, J. Berner, L. Richter, and G. Neumann. Underdamped diffusion bridges with applications to sampling, 2025. URL https://arxiv.org/abs/2503.01006
arXiv 2025
-
[7]
D. Blessing, L. Richter, J. Berner, E. Malitskiy, and G. Neumann. Bridge matching sampler: Scalable sampling via generalized fixed-point diffusion matching, 2026. URL https://arxiv.org/abs/2603.00530
arXiv 2026
-
[8]
V. D. Bortoli, M. Hutchinson, P. Wirnsberger, and A. Doucet. Target score matching, 2024. URL https://arxiv.org/abs/2402.08667
arXiv 2024
-
[9]
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equations, 2019. URL https://arxiv.org/abs/1806.07366
Pith/arXiv arXiv 2019
-
[10]
M. Dibak, L. Klein, A. Kr\"amer, and F. No\'e. Temperature steerable flows and boltzmann generators. Phys. Rev. Res., 4: 0 L042005, Oct 2022. doi:10.1103/PhysRevResearch.4.L042005. URL https://link.aps.org/doi/10.1103/PhysRevResearch.4.L042005
-
[11]
I. Dunn and D. R. Koes. Mixed continuous and categorical flow matching for 3d de novo molecule generation. arXiv:2404.19739 [q-bio.BM], 2024. URL https://arxiv.org/abs/2404.19739
arXiv 2024
-
[12]
M. F. Faulkner and S. Livingstone. Sampling algorithms in statistical physics: A guide for statistics and machine learning. Statistical Science, 39 0 (1), Feb. 2024. ISSN 0883-4237. doi:10.1214/23-sts893. URL http://dx.doi.org/10.1214/23-STS893
-
[13]
Flamary, N
R. Flamary, N. Courty, A. Gramfort, M. Z. Alaya, A. Boisbunon, S. Chambon, L. Chapel, A. Corenflos, K. Fatras, N. Fournier, L. Gautheron, N. T. Gayraud, H. Janati, A. Rakotomamonjy, I. Redko, A. Rolet, A. Schutz, V. Seguy, D. J. Sutherland, R. Tavenard, A. Tong, and T. Vayer. Pot: Python optimal transport. Journal of Machine Learning Research, 22 0 (78): ...
2021
-
[14]
M. Gabrié, G. M. Rotskoff, and E. Vanden-Eijnden. Adaptive monte carlo augmented with normalizing flows. Proceedings of the National Academy of Sciences, 119 0 (10): 0 e2109420119, 2022. doi:10.1073/pnas.2109420119. URL https://www.pnas.org/doi/abs/10.1073/pnas.2109420119
-
[15]
Gutmann and A
M. Gutmann and A. Hyv \"a rinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 297--304. JMLR Workshop and Conference Proceedings, 2010
2010
-
[16]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[17]
Hyv \"a rinen
A. Hyv \"a rinen. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6 0 (24): 0 695--709, 2005. URL http://jmlr.org/papers/v6/hyvarinen05a.html
2005
-
[18]
J. Hénin, T. Lelièvre, M. R. Shirts, O. Valsson, and L. Delemotte. Enhanced sampling methods for molecular dynamics simulations [article v1.0]. Living Journal of Computational Molecular Science, 4 0 (1): 0 1583, Dec. 2022. ISSN 2575-6524. doi:10.33011/livecoms.4.1.1583. URL http://dx.doi.org/10.33011/livecoms.4.1.1583
-
[19]
C. Jarzynski. Nonequilibrium equality for free energy differences. Physical Review Letters, 78 0 (14): 0 2690–2693, Apr. 1997. ISSN 1079-7114. doi:10.1103/physrevlett.78.2690. URL http://dx.doi.org/10.1103/PhysRevLett.78.2690
-
[20]
B. Jing, S. Eismann, P. N. Soni, and R. O. Dror. Equivariant graph neural networks for 3d macromolecular structure. arXiv preprint arXiv:2106.03843, 2021 a
arXiv 2021
-
[21]
B. Jing, S. Eismann, P. Suriana, R. J. L. Townshend, and R. Dror. Learning from protein structure with geometric vector perceptrons, 2021 b . URL https://arxiv.org/abs/2009.01411
arXiv 2021
-
[22]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
Pith/arXiv arXiv 2017
- [23]
-
[25]
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URL https://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[26]
G.-H. Liu, J. Choi, Y. Chen, B. K. Miller, and R. T. Q. Chen. Adjoint schr\"odinger bridge sampler, 2025. URL https://arxiv.org/abs/2506.22565
arXiv 2025
-
[28]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022 b . URL https://arxiv.org/abs/2209.03003
Pith/arXiv arXiv 2022
-
[29]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In European Conference on Computer Vision, pages 23--40. Springer, 2024
2024
-
[30]
L. I. Midgley, V. Stimper, G. N. C. Simm, B. Schölkopf, and J. M. Hernández-Lobato. Flow annealed importance sampling bootstrap, 2023. URL https://arxiv.org/abs/2208.01893
arXiv 2023
-
[31]
P. D. Moral and A. Doucet. Sequential monte carlo samplers, 2002. URL https://arxiv.org/abs/cond-mat/0212648
Pith/arXiv arXiv 2002
-
[32]
R. M. Neal. Annealed importance sampling, 1998. URL https://arxiv.org/abs/physics/9803008
Pith/arXiv arXiv 1998
-
[33]
No \'e , S
F. No \'e , S. Olsson, J. K \"o hler, and H. Wu. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning. Science, 365 0 (6457): 0 eaaw1147, 2019
2019
-
[34]
F. Noé, S. Olsson, J. Köhler, and H. Wu. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning. Science, 365 0 (6457): 0 eaaw1147, 2019. doi:10.1126/science.aaw1147. URL https://www.science.org/doi/abs/10.1126/science.aaw1147
-
[35]
A. v. d. Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[36]
G. Pérez-Hernández, F. Paul, T. Giorgino, G. De Fabritiis, and F. Noé. Identification of slow molecular order parameters for markov model construction. The Journal of Chemical Physics, 139 0 (1), July 2013. ISSN 1089-7690. doi:10.1063/1.4811489. URL http://dx.doi.org/10.1063/1.4811489
-
[37]
L. Richter and J. Berner. Improved sampling via learned diffusions, 2024. URL https://arxiv.org/abs/2307.01198
arXiv 2024
-
[38]
V. G. Satorras, E. Hoogeboom, and M. Welling. E (n) equivariant graph neural networks. In International conference on machine learning, pages 9323--9332. PMLR, 2021
2021
-
[39]
V. G. Satorras, E. Hoogeboom, and M. Welling. E(n) equivariant graph neural networks, 2022. URL https://arxiv.org/abs/2102.09844
arXiv 2022
-
[40]
H. Schopmans and P. Friederich. Temperature-annealed boltzmann generators, 2025. URL https://arxiv.org/abs/2501.19077
arXiv 2025
-
[41]
C. R. Schwantes and V. S. Pande. Improvements in markov state model construction reveal many non-native interactions in the folding of ntl9. Journal of Chemical Theory and Computation, 9 0 (4): 0 2000--2009, 2013. doi:10.1021/ct300878a. URL https://doi.org/10.1021/ct300878a. PMID: 23750122
-
[42]
J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics, 2015. URL https://arxiv.org/abs/1503.03585
Pith/arXiv arXiv 2015
-
[44]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations, 2021. URL https://arxiv.org/abs/2011.13456
Pith/arXiv arXiv 2021
- [45]
- [46]
-
[47]
C. von Klitzing, D. Blessing, H. Schopmans, P. Friederich, and G. Neumann. Learning boltzmann generators via constrained mass transport, 2026. URL https://arxiv.org/abs/2510.18460
arXiv 2026
-
[48]
Wirnsberger, A
P. Wirnsberger, A. J. Ballard, G. Papamakarios, S. Abercrombie, S. Racani \`e re, A. Pritzel, D. Jimenez Rezende, and C. Blundell. Targeted free energy estimation via learned mappings. The Journal of Chemical Physics, 153 0 (14), 2020
2020
-
[49]
J. Yang, Z. Liu, S. Xiao, C. Li, D. Lian, S. Agrawal, A. Singh, G. Sun, and X. Xie. Graphformers: Gnn-nested transformers for representation learning on textual graph, 2023. URL https://arxiv.org/abs/2105.02605
arXiv 2023
-
[50]
C. Ying, T. Cai, S. Luo, S. Zheng, G. Ke, D. He, Y. Shen, and T.-Y. Liu. Do transformers really perform badly for graph representation? Advances in neural information processing systems, 34: 0 28877--28888, 2021
2021
-
[51]
Q. Zhang and Y. Chen. Path integral sampler: a stochastic control approach for sampling, 2022. URL https://arxiv.org/abs/2111.15141
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.