A prism hierarchy of learning regimes in large linear autoencoders
Pith reviewed 2026-06-28 07:23 UTC · model grok-4.3
The pith
Extreme regimes of large linear autoencoders map to faces of a triangular prism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
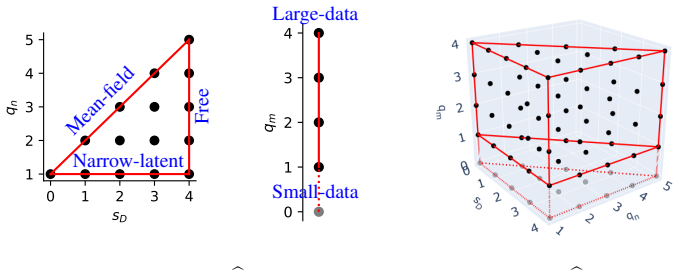
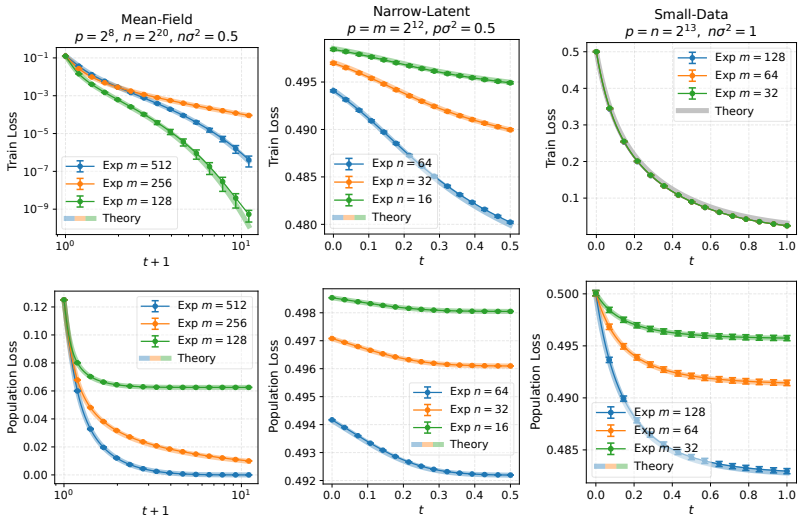
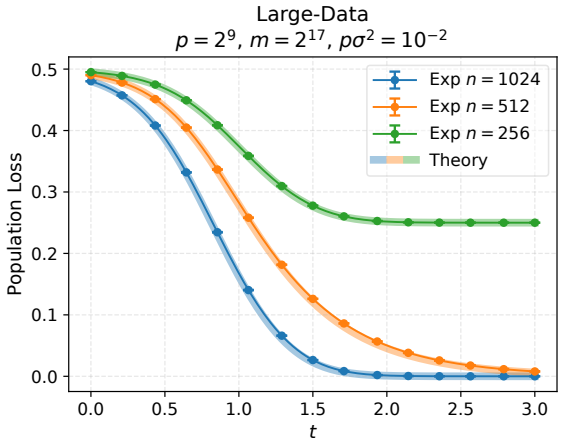
At the level of the formal loss-expansion hierarchy, the extreme regimes of large weight-tied linear autoencoders are naturally associated with faces of a triangular prism. In particular, there are five basic extreme regimes associated with the 2-faces: large-data, small-data, mean-field, narrow-latent, and free. For the first four regimes, explicit expressions are derived for both train and population limiting loss evolutions under gradient flow.
What carries the argument
The triangular prism hierarchy, in which each face corresponds to a distinct scaling regime of the input dimension, latent dimension, initialization, and dataset size that produces a separate limiting form of the loss expansion.
If this is right
- Both training and population losses admit explicit closed-form limiting expressions in the large-data, small-data, mean-field, and narrow-latent regimes.
- The derived expressions agree closely with direct simulations of gradient flow on large weight-tied linear autoencoders.
- The five extreme regimes cover the qualitatively different behaviors at the extremes of the parameter space defined by input size, latent size, initialization, and data size.
- The prism structure provides a geometric organization that unifies previously separate limiting analyses.
Where Pith is reading between the lines
- The prism geometry may suggest similar hierarchical structures in other models where loss expansions can be ordered by scaling parameters.
- Targeting a specific face of the prism could guide selection of initialization or architecture to reach a regime with reliable theoretical predictions.
- The free regime without an explicit derivation may require separate analysis techniques to obtain closed-form limits.
Load-bearing premise
The formal loss-expansion hierarchy is assumed to be sufficient to identify all qualitatively distinct extreme regimes without missing important dynamical effects arising from the nonlinear dependence on the weights.
What would settle it
A numerical experiment in which the observed train or population loss trajectory in one of the four derived regimes deviates substantially from the explicit limiting expression would falsify the claim.
Figures
read the original abstract
Theoretical studies of machine learning models commonly consider different limiting regimes in which the learning dynamics of gradient descent becomes theoretically tractable. It is, however, desirable to have a systematically obtained picture of all qualitatively different extreme learning regimes for a particular type of models. In this paper we propose such a picture for large weight-tied linear autoencoders characterized by input and latent dimensions, initialization magnitude, and training set size. This model is nonlinear in the weights and its gradient flow does not have a general theoretical solution. We show that at the level of the formal loss-expansion hierarchy, its extreme regimes are naturally associated with faces of a triangular prism. In particular, there are five basic extreme regimes associated with the 2-faces of the prism: (1) large-data, (2) small-data, (3) mean-field, (4) narrow-latent, and (5) free. For regimes (1,2,3,4), we derive explicit expressions for both train and population limiting loss evolutions under gradient flow, obtaining very good agreement with experimental results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that extreme learning regimes for large weight-tied linear autoencoders (parameterized by input/latent dimensions, initialization magnitude, and training set size) are systematically organized by a formal loss-expansion hierarchy into faces of a triangular prism. Five basic extreme regimes are associated with the 2-faces: (1) large-data, (2) small-data, (3) mean-field, (4) narrow-latent, and (5) free. Explicit expressions for both train and population limiting loss evolutions under gradient flow are derived for regimes (1-4), with very good agreement to experiments.
Significance. If the hierarchy is complete and the limiting expressions hold, the work offers a systematic classification of qualitatively distinct regimes for a nonlinear model whose gradient flow lacks a general closed form. The explicit derivations for four regimes and their experimental matches provide concrete, falsifiable predictions for loss trajectories across scaling limits, which is a strength for theoretical ML analysis.
major comments (2)
- Abstract: the central claim that explicit expressions for limiting train/population losses were derived for regimes (1,2,3,4) and match experiments well cannot be verified without the loss-expansion steps, truncation error analysis, or details on how the hierarchy classifies the nonlinear dynamics; this is load-bearing for the explicit expressions.
- Abstract: the assertion that the five 2-face regimes exhaust the qualitatively distinct extreme limits assumes the formal loss-expansion hierarchy is complete, but the manuscript provides no argument or test ruling out additional dynamical effects from higher-order interactions or mixed scalings not aligned with prism axes.
minor comments (1)
- The abstract refers to 'very good agreement with experimental results' without specifying quantitative metrics, error bounds, or which figures/tables demonstrate the match.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting points that strengthen the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim that explicit expressions for limiting train/population losses were derived for regimes (1,2,3,4) and match experiments well cannot be verified without the loss-expansion steps, truncation error analysis, or details on how the hierarchy classifies the nonlinear dynamics; this is load-bearing for the explicit expressions.
Authors: The loss-expansion steps, truncation error bounds, and the mapping from prism faces to dynamical regimes are derived in Sections 3–6 and Appendices A–C. These sections show how the nonlinear gradient-flow equations reduce to closed-form ODEs under each scaling. We will revise the abstract to include a parenthetical pointer to these sections so that the central claim can be traced directly to the supporting derivations. revision: partial
-
Referee: Abstract: the assertion that the five 2-face regimes exhaust the qualitatively distinct extreme limits assumes the formal loss-expansion hierarchy is complete, but the manuscript provides no argument or test ruling out additional dynamical effects from higher-order interactions or mixed scalings not aligned with prism axes.
Authors: Within the formal loss-expansion framework the five 2-faces correspond to the leading-order balances obtained by taking each of the four parameters to its extreme while holding the others fixed; any mixed scaling either collapses to one of these faces or produces only sub-dominant corrections that do not alter the qualitative loss trajectory. We will add a short subsection (new Section 2.4) that makes this reduction argument explicit and notes that higher-order interaction terms remain negligible under the same scaling assumptions used for the four explicit derivations. revision: partial
Circularity Check
Derivations from loss-expansion hierarchy are self-contained
full rationale
The paper applies a formal loss-expansion hierarchy to the weight-tied linear autoencoder to classify extreme regimes as prism faces and derives explicit train/population loss trajectories under gradient flow for four of the five 2-face regimes. These derivations are presented as direct consequences of the hierarchy truncation at the relevant scaling limits, with external experimental validation. No quoted step reduces a claimed prediction to a fitted parameter by construction, renames a known result, or relies on a load-bearing self-citation whose content is itself unverified. The hierarchy is treated as an independent organizing tool rather than being defined circularly in terms of the target regimes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient flow on the nonlinear loss of the weight-tied linear autoencoder can be analyzed via a formal loss-expansion hierarchy that identifies distinct extreme regimes.
invented entities (1)
-
triangular prism hierarchy of regimes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
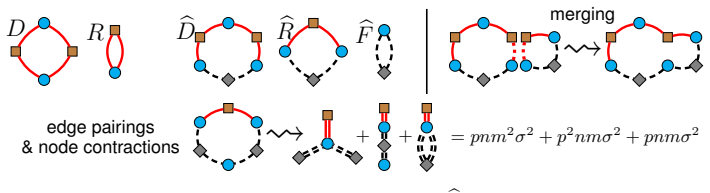
The vertices correspond to the summation indices and can be one of the three types: p (input dimension),n(latent dimension) orm(dataset size)
-
[2]
U-edges connect n-nodes with p-nodes, whileX-edges connectp-nodes withm-nodes
The edges connecting two vertices correspond to respective entries of the matrices U,X and accordingly can be of two types ( U or X). U-edges connect n-nodes with p-nodes, whileX-edges connectp-nodes withm-nodes
-
[3]
Note that: 14
The value associated with the diagram is obtained by multiplying the entries of U,X over the edges and summing resulting products over all configurations of node indices. Note that: 14
-
[4]
Thanks to the trace-product structure of D, R,bD,bR,bF , the associated five diagrams are ring diagrams(see Fig. 1). However, in general diagrams defined by above rules may be more general, e.g. the diagrams obtained by contractions of the ring diagrams (see below) are not ring diagrams
-
[5]
The number of X-edges is twice the number of m-nodes, while the number of U-edges is twice the number ofn-nodes
In the ring diagrams such as D, R,bD,bR,bF , the n, m-nodes alternate with p-nodes. The number of X-edges is twice the number of m-nodes, while the number of U-edges is twice the number ofn-nodes. Diagram merging.Computation of scalar products (37) can be described in terms ofdiagram merging. Let G1, G2 be two functions of the weights represented by diagr...
-
[6]
Consider all pairs of aU-edgeg 1 inG 1 and aU-edgeg 2 inG 2
-
[7]
For each such pair, merge the diagrams G1 and G2 by identifying the n-nodes of g1, g2, identifying thep-nodes ofg 1, g2, and removing the edgesg 1, g2 (see Fig. 1)
-
[8]
Note that:
Add the resulting diagrams. Note that:
-
[9]
Merger of two diagrams produces a linear combination of diagrams (corresponding to different pairs of edges)
-
[10]
The diagrams are merged only over U-edges and not X-edges (since only the U-edges contain the trainable model weights)
-
[11]
Let q(r) p , q(r) n , q(r) m , q(r) σ denote, respectively, the numbers of p-, n-, m-nodes and edges in Gr, r= 0,1
Merger of two ring diagrams G1, G2 produces again ring diagrams. Let q(r) p , q(r) n , q(r) m , q(r) σ denote, respectively, the numbers of p-, n-, m-nodes and edges in Gr, r= 0,1 . Then in the merged diagrams qp =q (1) p +q (2) p −1,(42) qn =q (1) n +q (2) n −1,(43) qm =q (1) m +q (2) m ,(44) qσ =q (1) σ +q (2) σ −2.(45) We denote the merge operation by⋆...
-
[12]
Consider all pairings of the edges ofG between matching edges (i.e., U-edges with U-edges andX-edges withX-edges)
-
[13]
spectral overfitting
For each pairing: (a) For each pair of edges,contract(i,e., identify) their respective p-, n- and/or m-nodes. The resulting contracted nodes correspond to the degrees of freedom left after imposing all the identity constraints. (b) The resulting contracted diagram contributes to E[G] the term pqp nqn mqm σqσ , where qp, qn, qm are the numbers of respectiv...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.