When Does Demographic Information Help? Data and Modeling Regimes for Perspective-Aware Hate Speech Detection
Pith reviewed 2026-06-29 18:54 UTC · model grok-4.3
The pith
Demographic information aids hate speech detection primarily in data regimes featuring low training disagreement and high test disagreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
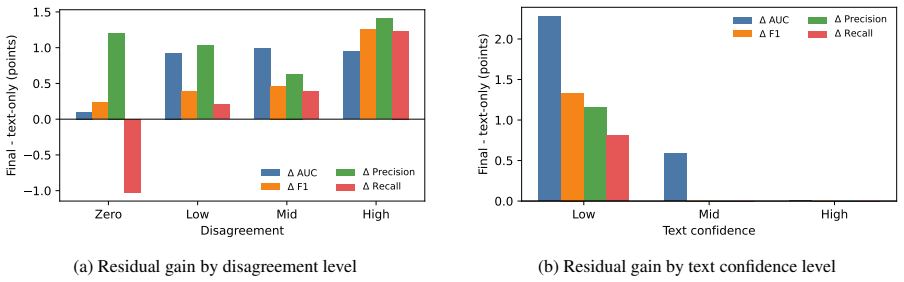
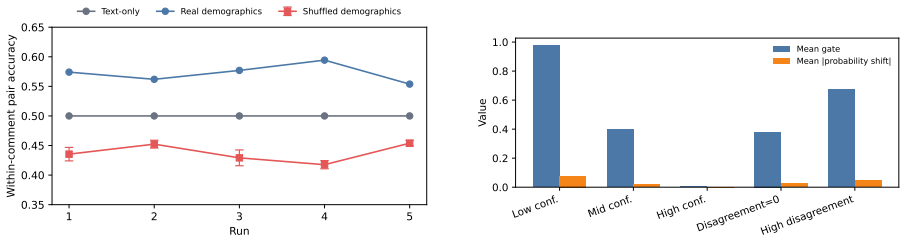
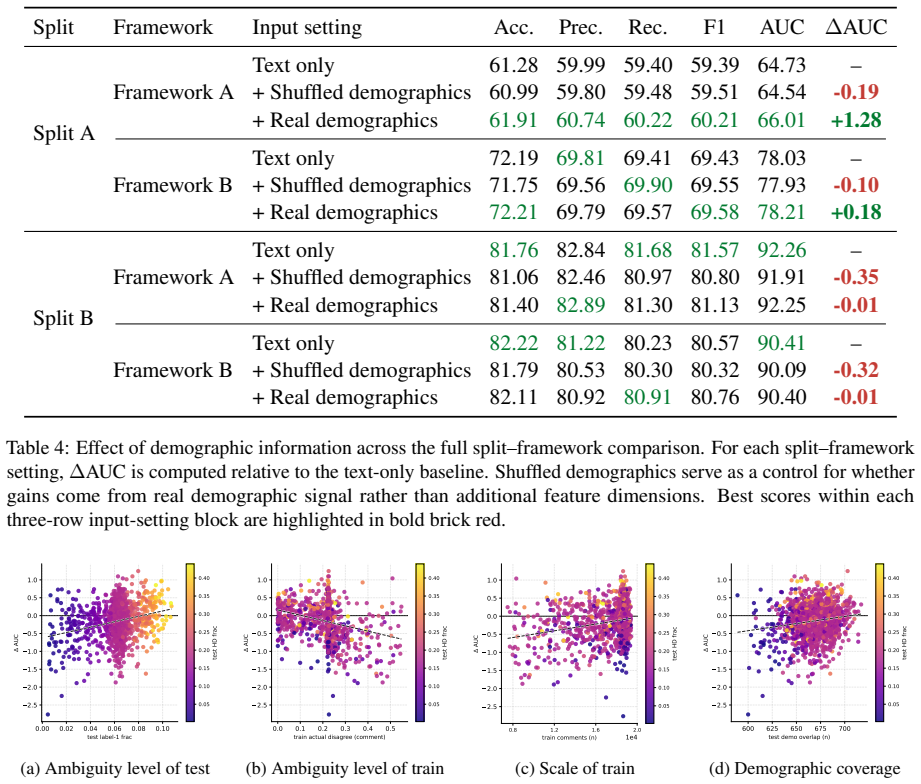
The paper claims that demographic gains concentrate in regimes with low training disagreement, high test disagreement, fine-grained ambiguity measurement, sufficient training data, and greater demographic overlap. A gated demographic residual model that treats demographics as a selective adjustment to text-only predictions is effective, especially on high disagreement or low confidence examples. Demographics should not be assumed useful by default; their value depends jointly on the data regime and the modeling framework.
What carries the argument
The gated demographic residual model, which selectively adjusts text-only predictions using demographic information.
If this is right
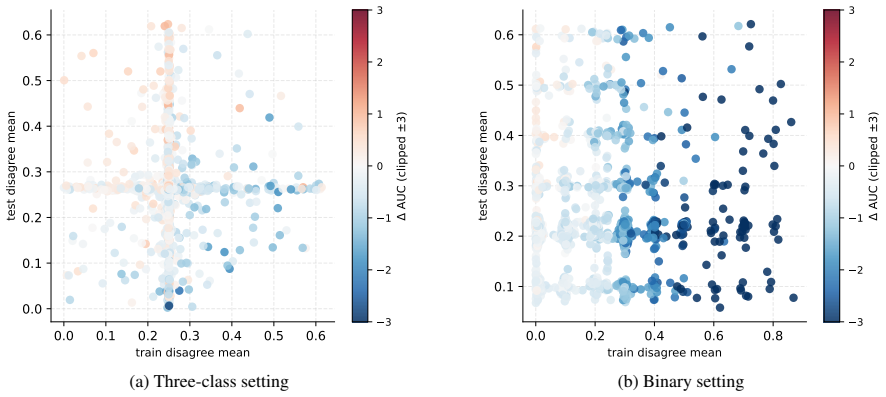
- Demographic performance gains concentrate under low training disagreement and high test disagreement.
- The gated model works best on high disagreement or low confidence examples.
- Greater demographic overlap between train and test sets increases gains.
- Sufficient training data is needed for demographics to help.
- Fine-grained ambiguity measurement reveals the regimes where demographics are useful.
Where Pith is reading between the lines
- The gated residual approach may generalize to other subjective tasks such as sentiment analysis if similar disagreement patterns hold.
- Future modeling work should routinely measure and condition on annotator disagreement levels.
- Selective demographic adjustment could reduce noise in low-confidence predictions across related detection tasks.
Load-bearing premise
Annotator disagreement measured by label differences and demographic overlap are the primary drivers of when demographics help, rather than other unmeasured factors such as label distribution.
What would settle it
A dataset split exhibiting low training disagreement, high test disagreement, and sufficient size where adding demographic features produces no performance gain would challenge the identified concentration of gains.
Figures

read the original abstract
Demographic information is often used to model annotator perspectives in subjective tasks such as hate speech detection, but its benefit is inconsistent: it improves performance in some settings and behaves as noise in others. This paper asks when demographic features help. We analyze demographic gain as a function of both data split properties and modeling frameworks. For data splits, we measure annotator disagreement, namely how often annotators assign different labels to the same example, along with training size and train-test demographic coverage. We find that demographic gains concentrate in regimes with low training disagreement, high test disagreement, fine-grained ambiguity measurement, sufficient training data, and greater demographic overlap. Motivated by these regimes, we introduce a gated demographic residual model that treats demographics as a selective adjustment to text-only predictions. Experiments on MHS and POPQUORN show that this design is effective, especially on high disagreement or low confidence examples. Overall, our results suggest that demographics should not be assumed useful by default; their value depends jointly on the data regime and the modeling framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines when demographic information aids perspective-aware hate speech detection. It analyzes demographic performance gains as a function of data-split properties (annotator disagreement in train vs. test, training size, demographic overlap) and modeling choices. Gains are reported to concentrate in regimes with low training disagreement, high test disagreement, fine-grained ambiguity, sufficient data, and greater overlap. Motivated by these observations, the authors introduce a gated demographic residual model that applies demographics selectively to text-only predictions. Experiments on the MHS and POPQUORN datasets indicate the gated model is particularly effective on high-disagreement or low-confidence examples. The central conclusion is that demographics should not be assumed beneficial by default but depend on joint data regime and modeling framework.
Significance. If the empirical regime findings and gated-model gains hold after appropriate controls, the work supplies actionable guidance for when annotator demographics are worth incorporating in subjective NLP tasks rather than treated as default or noise. The gated residual design is a concrete, motivated modeling contribution that could be adopted more broadly. The paper also supplies a useful empirical decomposition of performance by disagreement and overlap, which is a strength for reproducibility and follow-up work.
major comments (2)
- [§4] §4 (Regime Analysis): The claim that demographic gains concentrate specifically in the low-train/high-test disagreement regime requires evidence that disagreement and overlap are the primary drivers rather than proxies for unmeasured factors such as label entropy or class imbalance. No ablation or matched comparison is described that holds label distribution fixed while varying only disagreement/overlap; without such controls the reported concentration may not isolate the intended causal factors.
- [§5.2] §5.2 (Gated Model Experiments): The effectiveness of the gated demographic residual model on high-disagreement examples is presented as supporting the regime analysis, yet the model itself is motivated post-hoc from the same data splits. It is unclear whether the gating mechanism's gains survive when the underlying regime definitions are replaced by orthogonal difficulty metrics (e.g., model confidence alone or lexical features).
minor comments (2)
- [Table 2] Table 2 and Figure 3: Axis labels and legend entries for disagreement thresholds should be stated explicitly in the caption rather than only in the main text to improve readability.
- [§3] The abstract states results on MHS and POPQUORN but does not indicate whether the same train/test splits and annotation protocols are used across both; a brief clarification in §3 would help.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our analysis of demographic information in perspective-aware hate speech detection. The comments highlight important opportunities to strengthen causal claims in the regime analysis and to further validate the gated model's robustness. We address each point below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Regime Analysis): The claim that demographic gains concentrate specifically in the low-train/high-test disagreement regime requires evidence that disagreement and overlap are the primary drivers rather than proxies for unmeasured factors such as label entropy or class imbalance. No ablation or matched comparison is described that holds label distribution fixed while varying only disagreement/overlap; without such controls the reported concentration may not isolate the intended causal factors.
Authors: We agree that the current regime analysis would be strengthened by explicit controls that hold label distribution fixed. While our splits already stratify by disagreement levels and we report results across multiple datasets with varying class balances, we did not perform matched ablations isolating disagreement from entropy or imbalance. In revision we will add such matched comparisons on both MHS and POPQUORN, selecting subsets with equivalent label entropy and class distribution while varying train/test disagreement. This will help confirm whether disagreement captures perspective-related variance beyond these factors. We view this as a valuable addition rather than a fundamental flaw in the reported trends. revision: yes
-
Referee: [§5.2] §5.2 (Gated Model Experiments): The effectiveness of the gated demographic residual model on high-disagreement examples is presented as supporting the regime analysis, yet the model itself is motivated post-hoc from the same data splits. It is unclear whether the gating mechanism's gains survive when the underlying regime definitions are replaced by orthogonal difficulty metrics (e.g., model confidence alone or lexical features).
Authors: The gated residual model was motivated by the observed regimes but is evaluated on both disagreement-based and model-confidence-based partitions, as already shown in §5.2 and the abstract. To address the concern about post-hoc motivation and orthogonal metrics, we will add results using lexical difficulty proxies (e.g., sentence length, lexical ambiguity scores) and confirm that gating still yields gains on high-difficulty subsets defined independently of the original disagreement splits. This will demonstrate that the selective demographic adjustment is not tied exclusively to the regime definitions used for motivation. revision: partial
Circularity Check
No circularity: empirical regimes and motivated model are independent of fitted inputs
full rationale
The paper measures annotator disagreement, demographic overlap, training size, and coverage directly from the MHS and POPQUORN datasets to identify regimes where demographic gains concentrate. It then introduces a gated demographic residual model motivated by (not derived from) those observations. No equations or claims reduce a prediction to a fitted parameter by construction, no self-citation chains justify uniqueness theorems, and no ansatz or renaming of known results occurs. The analysis treats disagreement and overlap as observable data properties rather than self-defined quantities, making the central claims externally falsifiable on the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Power of Scale for Parameter-Efficient Prompt Tuning
Semeval-2023 task 11: Learning with disagree- ments (lewidi). InProceedings of the 17th Interna- tional Workshop on Semantic Evaluation (SemEval- 2023), pages 2304–2318. Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691. Marlene Lutz, Indira Sen, Georg Ahnert, Elis...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Matthias Orlikowski, Jiaxin Pei, Paul Röttger, Philipp Cimiano, David Jurgens, and Dirk Hovy
Bertweet: A pre-trained language model for english tweets.arXiv preprint arXiv:2005.10200. Matthias Orlikowski, Jiaxin Pei, Paul Röttger, Philipp Cimiano, David Jurgens, and Dirk Hovy. 2025. Be- yond demographics: Fine-tuning large language mod- els to predict individuals’ subjective text perceptions. InProceedings of the 63rd Annual Meeting of the Associ...
-
[3]
Measuring the Reliability of Hate Speech Annotations: The Case of the European Refugee Crisis
Measuring the reliability of hate speech an- notations: The case of the european refugee crisis. arXiv preprint arXiv:1701.08118. Pratik Sachdeva, Renata Barreto, Geoff Bacon, Alexan- der Sahn, Claudia V on Vacano, and Chris Kennedy
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
InProceedings of the 1st Workshop on Perspectivist Approaches to NLP@ LREC2022, pages 83–94
The measuring hate speech corpus: Leverag- ing rasch measurement theory for data perspectivism. InProceedings of the 1st Workshop on Perspectivist Approaches to NLP@ LREC2022, pages 83–94. Aadi Sanghani, Sarvin Azadi, Virendra Jethra, and Charles Welch. 2025. McMaster at LeWiDi-2025: Demographic-aware RoBERTa. InProceedings of the The 4th Workshop on Pers...
-
[5]
Everyone’s voice matters: Quantifying anno- tation disagreement using demographic information. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 14523–14530. Yinuo Xu, Veronica Derricks, Allison Earl, and David Jurgens. 2025. Modeling annotator disagreement with demographic-aware experts and synthetic per- spectives.arXiv p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.