Data Flow Control: Data Safety Policies for AI Agents
Pith reviewed 2026-06-27 23:26 UTC · model grok-4.3
The pith
Data Flow Control enforces safety policies on AI-generated SQL queries inside the DBMS through query rewriting without materializing provenance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
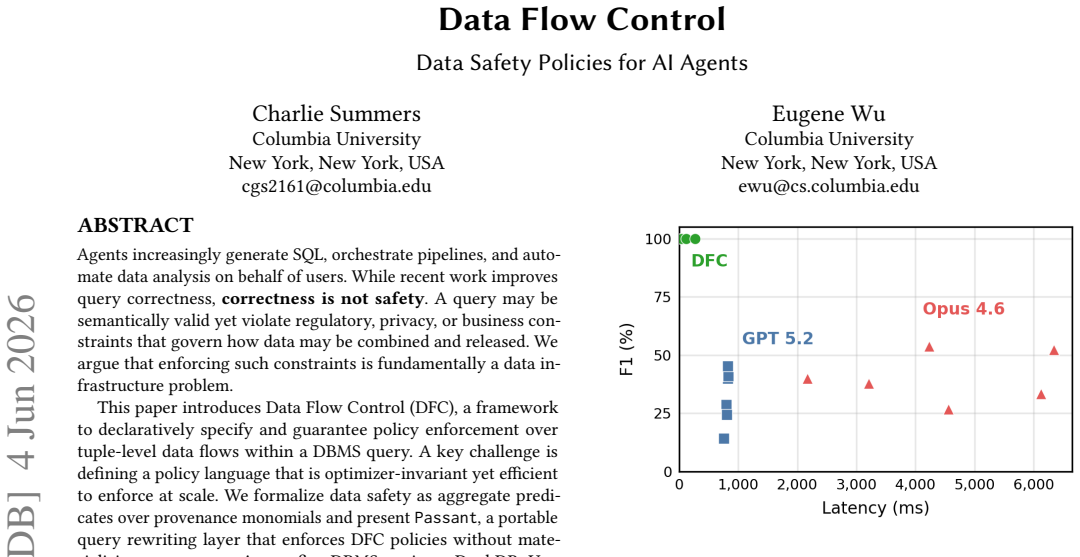
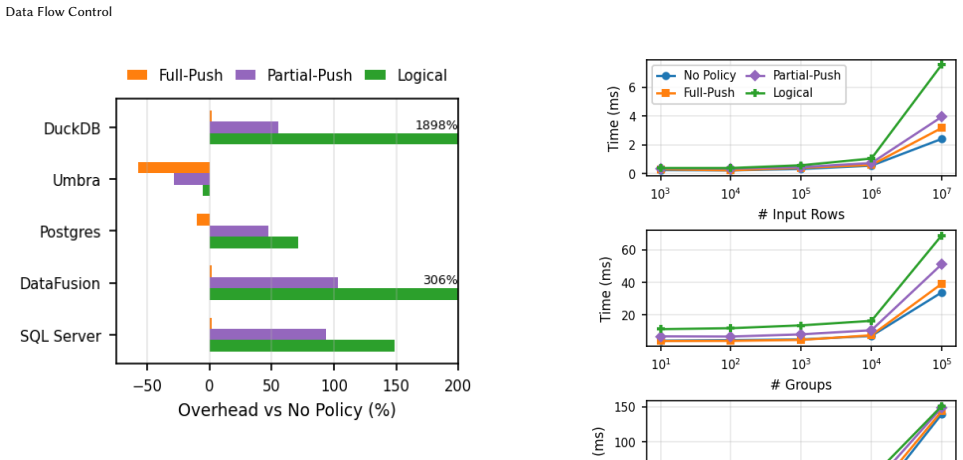
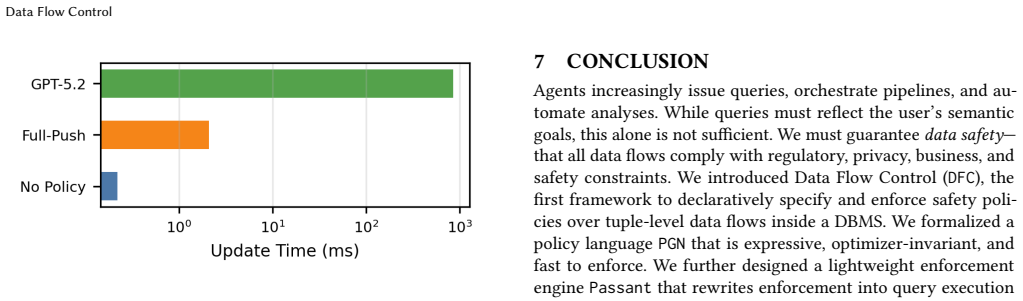
Data Flow Control formalizes data safety as aggregate predicates over provenance monomials. Passant enforces these predicates by rewriting queries in an optimizer-invariant way that requires no provenance materialization and no changes to the underlying DBMS, delivering near-zero overhead across DuckDB, Umbra, PostgreSQL, DataFusion, and SQLServer while outperforming materializing alternatives by orders of magnitude.
What carries the argument
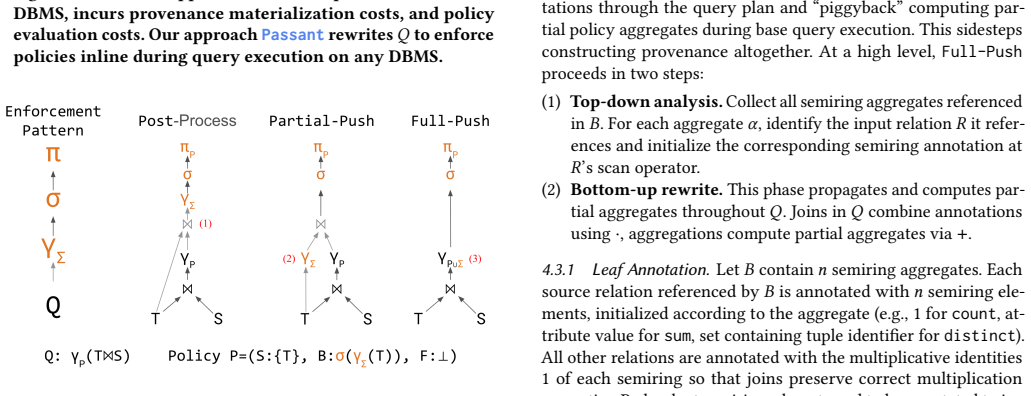
Passant, a portable query rewriting layer that translates DFC policies expressed as aggregate provenance predicates into equivalent rewritten queries.
If this is right
- AI agents can generate and run queries while data combination rules are guaranteed at execution time inside the engine.
- The same rewritten-query mechanism applies without modification to five different DBMS engines.
- Policy enforcement does not require storing or querying complete provenance records.
- Overhead remains negligible relative to the original query cost.
Where Pith is reading between the lines
- Agents could safely orchestrate longer data-analysis pipelines if DFC policies were attached to common analysis templates.
- The rewriting technique may extend to other infrastructure-level constraints such as differential privacy or regulatory release rules.
- Integration with query optimizers that already track provenance statistics could further reduce any residual cost.
Load-bearing premise
Data safety policies can always be expressed as aggregate predicates over provenance monomials that remain optimizer-invariant and can be enforced solely by query rewriting without materializing full provenance or modifying the DBMS.
What would settle it
A concrete data safety policy that cannot be expressed as an aggregate predicate over provenance monomials, or a rewritten query produced by Passant that fails to block a violating result on one of the five tested engines.
Figures


read the original abstract
Agents increasingly generate SQL, orchestrate pipelines, and automate data analysis on behalf of users. While recent work improves query correctness, correctness is not safety. A query may be semantically valid yet violate regulatory, privacy, or business constraints that govern how data may be combined and released. We argue that enforcing such constraints is fundamentally a data infrastructure problem. This paper introduces Data Flow Control (DFC), a framework to declaratively specify and guarantee policy enforcement over tuple-level data flows within a DBMS query. A key challenge is defining a policy language that is optimizer-invariant yet efficient to enforce at scale. We formalize data safety as aggregate predicates over provenance monomials and present Passant, a portable query rewriting layer that enforces DFC policies without materializing provenance. Across five DBMS engines -- DuckDB, Umbra, PostgreSQL, DataFusion, and SQLServer -- Passant achieves ~0% overhead and outperforms alternatives by orders of magnitude. As a result, Data Flow Control is the first step towards moving data safety from prompts and post-hoc checks into the data infrastructure. Data Flow Control is available open source at https://github.com/dataflowcontrol/data-flow-control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Data Flow Control (DFC), a framework to declaratively specify and guarantee policy enforcement over tuple-level data flows within a DBMS query. It formalizes data safety as aggregate predicates over provenance monomials and presents Passant, a portable query rewriting layer that enforces DFC policies without materializing provenance. Across five DBMS engines (DuckDB, Umbra, PostgreSQL, DataFusion, and SQLServer), Passant achieves ~0% overhead and outperforms alternatives by orders of magnitude, positioning DFC as a step toward embedding data safety in data infrastructure rather than prompts or post-hoc checks.
Significance. If the central claims hold, the work is significant for systems research on AI agent data handling: it provides a declarative, optimizer-invariant policy language grounded in provenance and demonstrates portable enforcement via rewriting with negligible overhead. The cross-engine evaluation and open-source release are strengths that could influence practical adoption in DBMS-backed agent pipelines.
major comments (2)
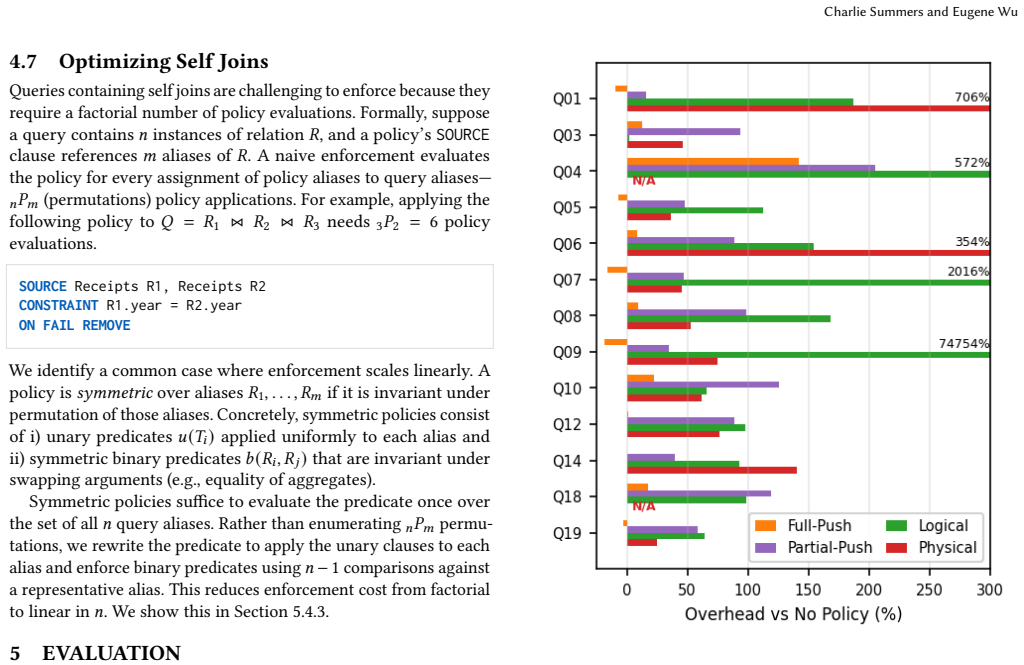
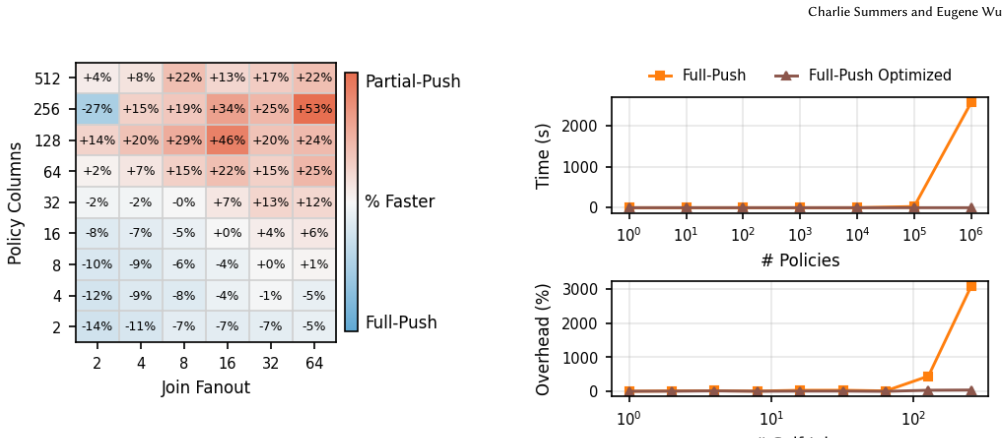
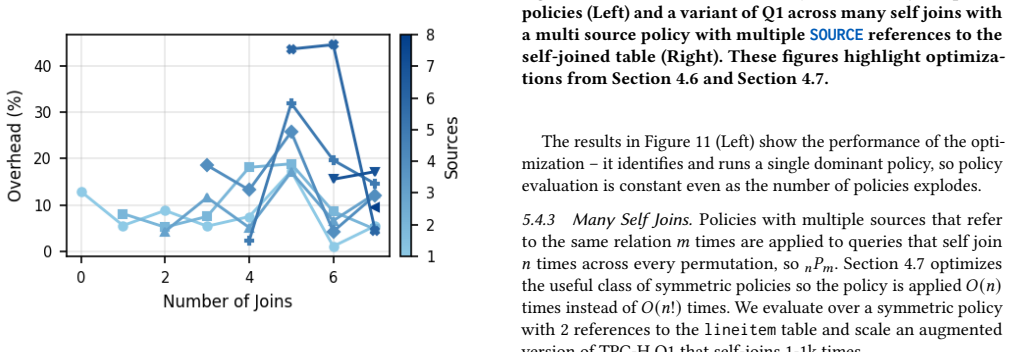
- [§4] §4 (Policy Language): The claim that policies expressed as aggregate predicates over provenance monomials remain optimizer-invariant requires explicit proof that the rewriting rules commute with standard relational optimizations (e.g., join reordering, predicate pushdown); without this, the portability guarantee across engines is not fully substantiated by the presented formalism.
- [§6] §6 (Evaluation, Table 2): The reported ~0% overhead is load-bearing for the central performance claim, yet the methodology section does not detail how query plans were normalized across engines or whether the baseline alternatives included equivalent provenance tracking; this leaves open whether the orders-of-magnitude improvement is due to the rewriting technique or differences in baseline implementation.
minor comments (2)
- [Abstract] Abstract and §1: The term 'provenance monomials' is introduced without a brief inline definition or reference to the standard provenance semiring literature; adding one sentence would improve accessibility.
- [§5] §5 (Passant Implementation): The description of the rewriting algorithm would benefit from a small pseudocode listing or diagram showing the transformation from policy predicate to rewritten query.
Simulated Author's Rebuttal
We thank the referee for the thorough review and positive recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Policy Language): The claim that policies expressed as aggregate predicates over provenance monomials remain optimizer-invariant requires explicit proof that the rewriting rules commute with standard relational optimizations (e.g., join reordering, predicate pushdown); without this, the portability guarantee across engines is not fully substantiated by the presented formalism.
Authors: We acknowledge the need for an explicit proof. In the revised version, we will add to Section 4 a detailed argument establishing that the rewriting rules commute with standard relational optimizations, thereby substantiating the optimizer-invariance and portability claims. revision: yes
-
Referee: [§6] §6 (Evaluation, Table 2): The reported ~0% overhead is load-bearing for the central performance claim, yet the methodology section does not detail how query plans were normalized across engines or whether the baseline alternatives included equivalent provenance tracking; this leaves open whether the orders-of-magnitude improvement is due to the rewriting technique or differences in baseline implementation.
Authors: The evaluation methodology can be clarified. We will revise Section 6 to include details on how query plans were normalized (e.g., by disabling certain optimizations where necessary and using consistent cost models) and confirm that the alternative baselines were equipped with comparable provenance tracking capabilities. This will better isolate the benefits of the Passant rewriting layer. revision: yes
Circularity Check
No significant circularity; derivation is self-contained systems contribution
full rationale
The paper introduces Data Flow Control as a new declarative framework and implements it via the Passant query-rewriting layer. Its central claims rest on formalizing policies as aggregate predicates over provenance monomials and demonstrating portable enforcement through rewriting that avoids materialization. These steps are presented as engineering and systems design choices rather than derivations that reduce by construction to fitted parameters or prior self-citations. Performance results (~0% overhead across five engines) are empirical measurements, not quantities defined by the paper's own equations. No load-bearing step matches any of the enumerated circularity patterns; the work is a self-contained systems artifact whose correctness can be evaluated against external benchmarks and open-source code.
Axiom & Free-Parameter Ledger
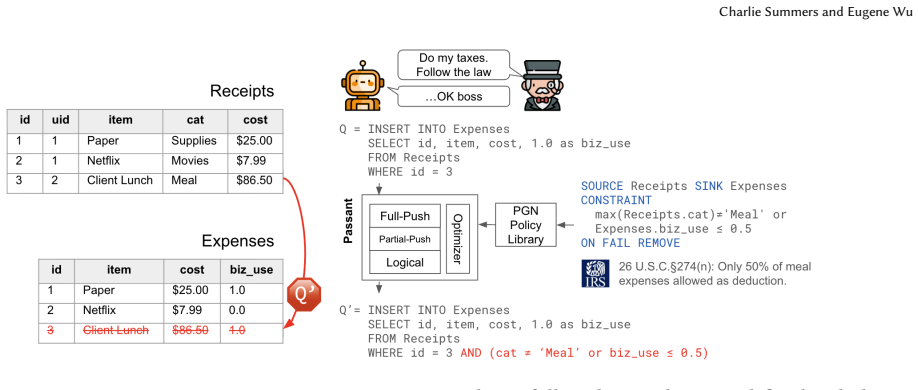
axioms (2)
- domain assumption Data safety policies can be captured as aggregate predicates over provenance monomials
- domain assumption Query rewriting can enforce such predicates without materializing provenance and while remaining optimizer-invariant
invented entities (2)
-
Data Flow Control (DFC)
no independent evidence
-
Passant
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Equal Credit Opportunity Act
1974. Equal Credit Opportunity Act. 15 U.S.C. § 1691(a)
1974
-
[2]
General Data Protection Regulation
2016. General Data Protection Regulation. Regulation (EU) 2016/679, Art.5(1)(c)
2016
-
[3]
Report on Statistical Disclosure Limitation Methodology
2016. Report on Statistical Disclosure Limitation Methodology. Statistical Policy Working Paper 22, Federal Committee on Statistical Methodology
2016
-
[4]
Yael Amsterdamer, Daniel Deutch, and Val Tannen. 2011. On the Limitations of Provenance for Queries with Difference. InProceedings of the 3rd USENIX Workshop on the Theory and Practice of Provenance (TaPP)
2011
-
[5]
2025.Equipping Agents for the Real World with Agent Skills
Anthropic. 2025.Equipping Agents for the Real World with Agent Skills. https://www.anthropic.com/engineering/equipping-agents-for-the-real- world-with-agent-skills
2025
-
[6]
Bahareh Sadat Arab, Su Feng, Boris Glavic, Seokki Lee, Xing Niu, and Qitian Zeng. 2018. GProM - A Swiss Army Knife for Your Provenance Needs.IEEE Data Eng. Bull.41 (2018), 51–62
2018
-
[7]
Luca Beurer-Kellner, Beat Buesser, Ana-Maria Creţu, Edoardo Debenedetti, Daniel Dobos, Daniel Fabian, Marc Fischer, David Froelicher, Kathrin Grosse, Daniel Naeff, Ezinwanne Ozoani, Andrew Paverd, Florian Tramèr, and Václav Vol- hejn. 2025. Design Patterns for Securing LLM Agents against Prompt Injections. arXiv:2506.08837 [cs.LG] https://arxiv.org/abs/2506.08837
-
[8]
Uri Braun, Avraham Shinnar, and Margo Seltzer. 2008. Securing provenance. InProceedings of the 3rd Conference on Hot Topics in Security(San Jose, CA) (HOTSEC’08). USENIX Association, USA, Article 4, 5 pages
2008
-
[9]
Peter Buneman, Sanjeev Khanna, and Wang Chiew Tan. 2001. Why and Where: A Characterization of Data Provenance. InInternational Conference on Database Theory. https://api.semanticscholar.org/CorpusID:13791826
2001
-
[10]
Tyrone Cadenhead, Vaibhav Khadilkar, Murat Kantarcioglu, and Bhavani Thu- raisingham. 2011. A language for provenance access control. InProceedings of the First ACM Conference on Data and Application Security and Privacy(San Antonio, TX, USA)(CODASPY ’11). Association for Computing Machinery, New York, NY, USA, 133–144. https://doi.org/10.1145/1943513.1943532
-
[11]
Stefano Ceri, Roberta Cochrane, and Jennifer Widom. 2000. Practical applications of triggers and constraints: Success and lingering issues. InProc. 26th VLDB. 254– 262
2000
-
[12]
Lingjiao Chen and Arun Kumar. 2017. Towards Linear Algebra over Normalized Data.Proceedings of the VLDB Endowment10, 11 (2017), 1214–1225. https: //doi.org/10.14778/3137628.3137632
-
[13]
Sibei Chen, Hanbing Liu, Waiting Jin, Xiangyu Sun, Xiaoyao Feng, Ju Fan, Xi- aoyong Du, and Nan Tang. 2024. ChatPipe: Orchestrating Data Preparation Pipelines by Optimizing Human-ChatGPT Interactions. InCompanion of the 2024 International Conference on Management of Data(Santiago AA, Chile)(SIG- MOD ’24). Association for Computing Machinery, New York, NY,...
-
[14]
James Cheney, Laura Chiticariu, and Wang-Chiew Tan. 2009. Provenance in Databases: Why, How, and Where.Foundations and Trends in Databases1, 4 (2009), 379–474. https://doi.org/10.1561/1900000006 Charlie Summers and Eugene Wu
-
[15]
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russi- novich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella- Béguelin. 2025. Securing AI Agents with Information-Flow Control. arXiv. https://www.microsoft.com/en-us/research/publication/securing-ai- agents-with-information-flow-control/
2025
-
[16]
Umeshwar Dayal, Alejandro P Buchmann, and Dennis R McCarthy. 1988. Rules are objects too: a knowledge model for an active, object-oriented database system. InInternational Workshop on Object-Oriented Database Systems. Springer, 129– 143
1988
-
[17]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design. arXiv:2503.18813 [cs.CR] https://arxiv.org/abs/2503.18813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Saeed Fathollahzadeh, Essam Mansour, and Matthias Boehm. 2025. CatDB: Data- Catalog-Guided, LLM-Based Generation of Data-Centric ML Pipelines.Proc. VLDB Endow.18, 8 (April 2025), 2639–2652. https://doi.org/10.14778/3742728. 3742754
- [19]
-
[20]
Boris Glavic. 2021. Data Provenance.Foundations and Trends®in Databases9, 3-4 (2021), 1–232. https://doi.org/10.1561/1900000068
-
[21]
Boris Glavic and Gustavo Alonso. 2009. Perm: Processing provenance and data on the same data model through query rewriting. InICDE. 174–185
2009
-
[22]
Todd J Green, Grigoris Karvounarakis, and Val Tannen. 2007. Provenance semir- ings. InProceedings of the twenty-sixth ACM SIGMOD-SIGACT-SIGART sympo- sium on Principles of database systems. 31–40
2007
-
[23]
Zezhou Huang and Eugene Wu. 2023. Lightweight materialization for fast dashboards over joins.Proceedings of the ACM on Management of Data1, 4 (2023), 1–27
2023
-
[24]
Zhen Ming Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. 2025. AIDE: AI-Driven Exploration in the Space of Code.ArXivabs/2502.13138 (2025). https://api.semanticscholar.org/CorpusID: 276421281
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Andrew Lamb, Yijie Shen, Daniël Heres, Jayjeet Chakraborty, Mehmet Ozan Kabak, Liang-Chi Hsieh, and Chao Sun. 2024. Apache Arrow DataFusion: A Fast, Embeddable, Modular Analytic Query Engine. InCompanion of the 2024 International Conference on Management of Data(Santiago AA, Chile)(SIGMOD ’24). Association for Computing Machinery, New York, NY, USA, 5–17....
-
[26]
Samuele Langhi, Angela Bonifati, and Riccardo Tommasini. 2025. Evaluating Continuous Queries with Inconsistency Annotations.Proceedings of the VLDB Endowment18, 5 (2025), 1321–1334. https://doi.org/10.14778/3718057.3718062
- [27]
- [28]
-
[29]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C. C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. arXiv:2305.03111 [cs....
-
[30]
Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, and Zhengzhong Tu. 2025. SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems. arXiv:2506.07564 [cs.AI] https://arxiv.org/abs/ 2506.07564
-
[31]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2025. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. arXiv:2509.00997 [cs.AI] https://arxiv.org/a...
-
[32]
2026.Microsoft SQL Server
Microsoft Corporation. 2026.Microsoft SQL Server. Microsoft Corporation. https://www.microsoft.com/sql-server Relational database management system
2026
-
[33]
Haneen Mohammed, Charlie Summers, Sughosh Kaushik, and Eugene Wu. 2023. SmokedDuck Demonstration: SQLStepper. InCompanion of the 2023 International Conference on Management of Data. 183–186. https://doi.org/10.1145/3555041. 3589731
-
[34]
Tobias Müller, Benjamin Dietrich, and Torsten Grust. 2018. You say ’what’, i hear ’where’ and ’why’: (mis-)interpreting SQL to derive fine-grained provenance.Proc. VLDB Endow.11, 11 (July 2018), 1536–1549. https://doi.org/10.14778/3236187. 3236204
-
[35]
Thomas Neumann and Michael J. Freitag. 2020. Umbra: A Disk-Based System with In-Memory Performance. InConference on Innovative Data Systems Research. https://api.semanticscholar.org/CorpusID:209379505
2020
-
[36]
Kimberly Nguyen, Kristal Lew, and Amal Trivedi. 2022. Trends in Collection of Disaggregated Asian American, Native Hawaiian, and Pacific Islander Data: Opportunities in Federal Health Surveys.American Journal of Public Health112, 10 (2022), 1429–1435. https://doi.org/10.2105/AJPH.2022.306969
-
[37]
Daly, Michael Hind, Werner Geyer, Ambrish Rawat, Kush R
Inkit Padhi, Manish Nagireddy, Giandomenico Cornacchia, Subhajit Chaudhury, Tejaswini Pedapati, Pierre Dognin, Keerthiram Murugesan, Erik Miehling, Martín Santillán Cooper, Kieran Fraser, Giulio Zizzo, Muhammad Zaid Hameed, Mark Purcell, Michael Desmond, Qian Pan, Inge Vejsbjerg, Elizabeth M. Daly, Michael Hind, Werner Geyer, Ambrish Rawat, Kush R. Varshn...
-
[38]
Granite Guardian: Comprehensive LLM Safeguarding. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track), Weizhu Chen, Yi Yang, Mohammad Kachuee, and Xue-Yong Fu (Eds.). Association for Computational Linguistics, Albuquerque, New M...
-
[39]
Jaehong Park, Dang Nguyen, and Ravi Sandhu. 2012. A provenance-based access control model. In2012 Tenth Annual International Conference on Privacy, Security and Trust. 137–144. https://doi.org/10.1109/PST.2012.6297930
-
[40]
close the books
Penrose. 2025. AccountingBench: A Benchmark for Evaluating Large Language Models on Real Long-Horizon Accounting Tasks. Online. https://accounting. penrose.com/ A benchmark that tests LLMs’ ability to “close the books” using real financial data for a year of accounting records
2025
-
[41]
Fotis Psallidas and Eugene Wu. 2018. Smoke: Fine-grained lineage at interactive speed.arXiv preprint arXiv:1801.07237(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: an Embeddable Analytical Database. InProceedings of the 2019 International Conference on Management of Data(Amsterdam, Netherlands)(SIGMOD ’19). Association for Computing Machinery, New York, NY, USA, 1981–1984. https://doi.org/10.1145/3299869. 3320212
-
[43]
Mizanur Rahman, Amran Bhuiyan, Mohammed Saidul Islam, Md Tahmid Rahman Laskar, Ridwan Mahbub, Ahmed Masry, Shafiq Joty, and Enamul Hoque. 2025. LLM-Based Data Science Agents: A Survey of Capabilities, Challenges, and Future Directions. arXiv:2510.04023 [cs.AI] https://arxiv.org/abs/2510.04023
-
[44]
Maximilian Schleich, Dan Olteanu, Mahmoud Abo Khamis, Hung Q. Ngo, and XuanLong Nguyen. 2019. A Layered Aggregate Engine for Analytics Work- loads. InProceedings of the 2019 International Conference on Management of Data (SIGMOD). ACM, 581–597. https://doi.org/10.1145/3299869.3314037
-
[45]
Amir Shaikhha, Mathieu Huot, Jaclyn Smith, and Dan Olteanu. 2021. Functional Collection Programming with Semi-Ring Dictionaries.Proceedings of the ACM on Programming Languages5, OOPSLA (2021), 1–30. https://doi.org/10.1145/ 3485520
2021
-
[46]
Michael Stonebraker and Lawrence A. Rowe. 1986. The design of POSTGRES. In Proceedings of the 1986 ACM SIGMOD International Conference on Management of Data(Washington, D.C., USA)(SIGMOD ’86). Association for Computing Machinery, New York, NY, USA, 340–355. https://doi.org/10.1145/16894.16888
- [47]
- [48]
-
[49]
Lillian Tsai and Eugene Bagdasarian. 2025. Contextual Agent Security: A Policy for Every Purpose. InProceedings of the Workshop on Hot Topics in Operating Systems (HOTOS ’25). ACM, 8–17. https://doi.org/10.1145/3713082.3730378
-
[50]
United States Congress. 2024. 26 U.S.C. § 274(n): Only 50 percent of meal expenses allowed as deduction. U.S. Code Title 26. https://www.law.cornell.edu/uscode/ text/26/274#n Internal Revenue Code, Section 274(n)
2024
-
[51]
Prasang Upadhyaya, Magdalena Balazinska, and Dan Suciu. 2015. Automatic Enforcement of Data Use Policies with DataLawyer. InProceedings of the 2015 ACM SIGMOD International Conference on Management of Data(Melbourne, Victoria, Australia)(SIGMOD ’15). Association for Computing Machinery, New York, NY, USA, 213–225. https://doi.org/10.1145/2723372.2723721
-
[52]
van der Aalst
Wil M.P. van der Aalst. 2012. Process mining: making knowledge discovery process centric.Commun. ACM55 (2012), 76–83. https://api.semanticscholar. org/CorpusID:36518949
2012
- [53]
-
[54]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
2018
- [55]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.