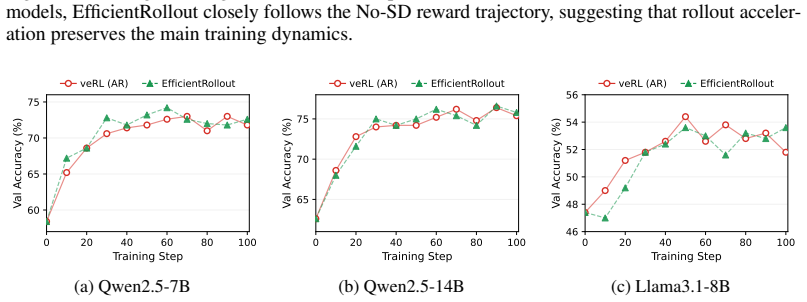
EfficientRollout: System-Aware Self-Speculative Decoding for RL Rollouts
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
EfficientRollout induces a quantized drafter from the target model to accelerate RL rollouts by up to 19.6 percent while keeping the output distribution unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
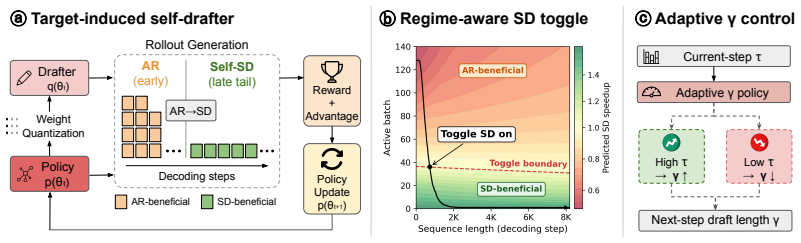
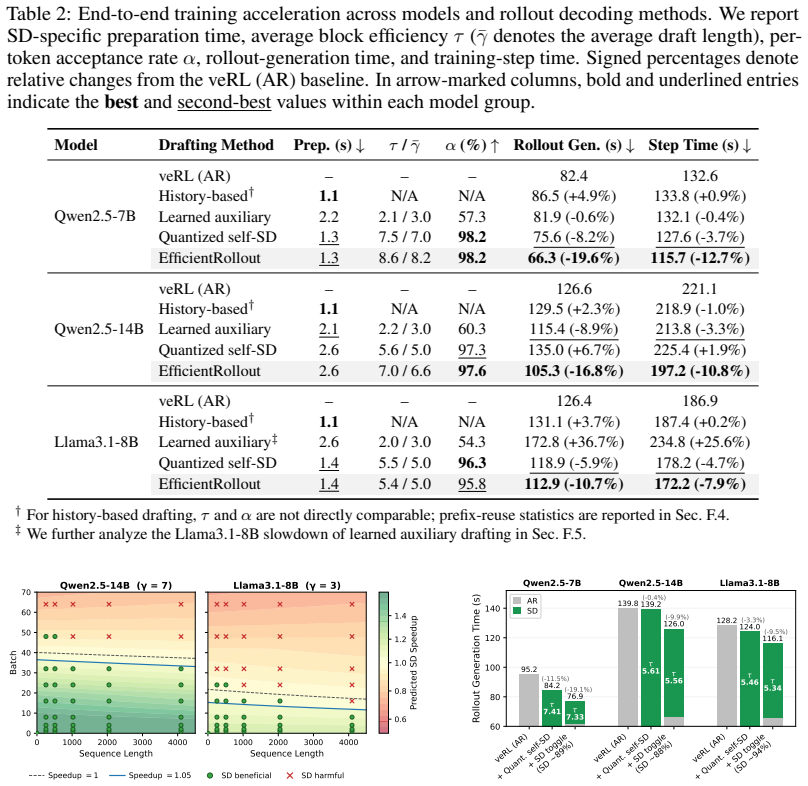
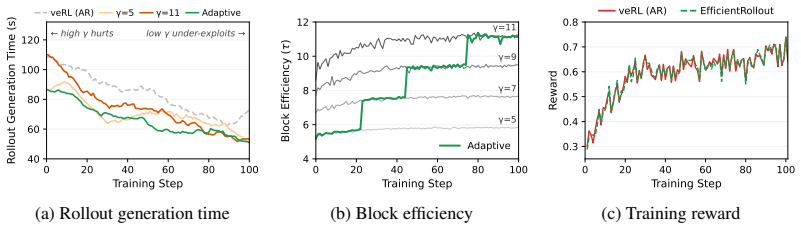
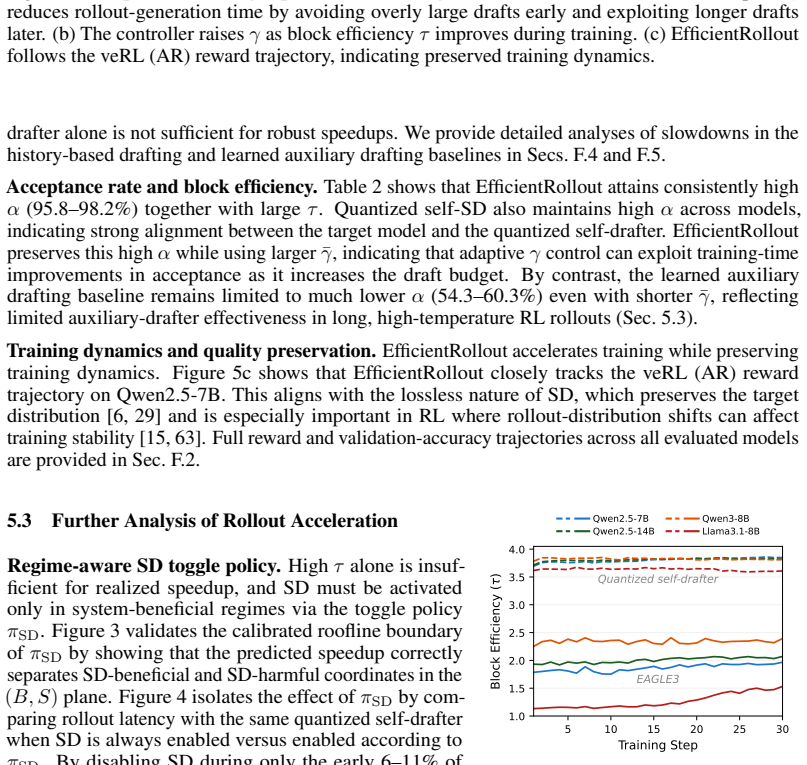
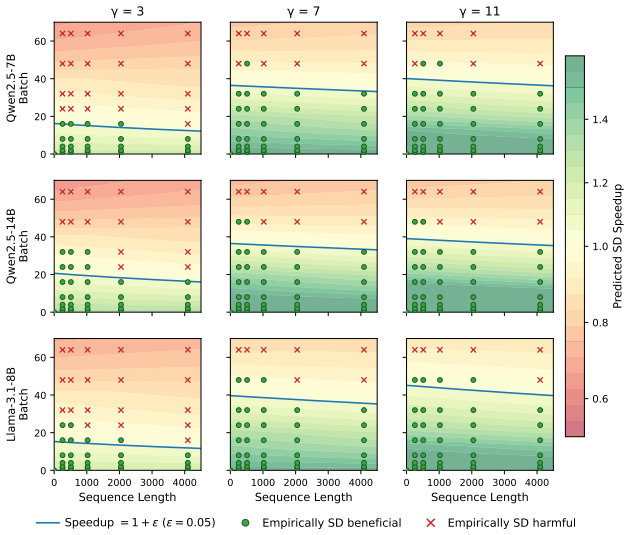
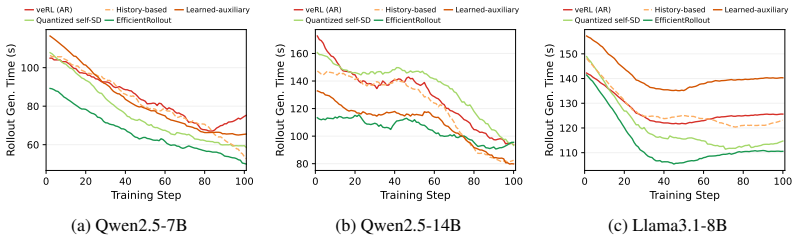
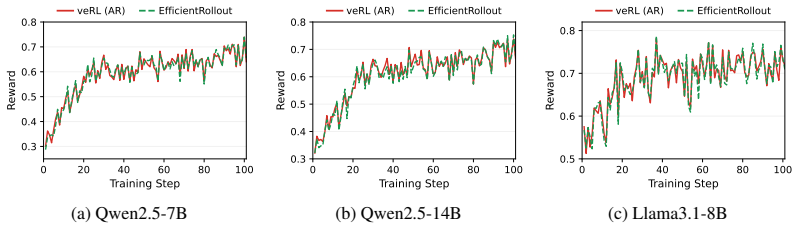
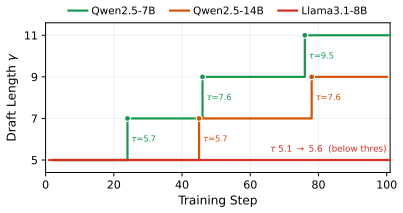
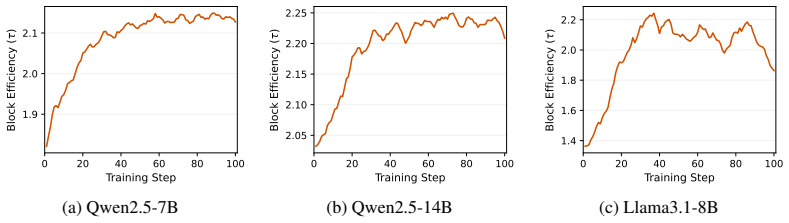
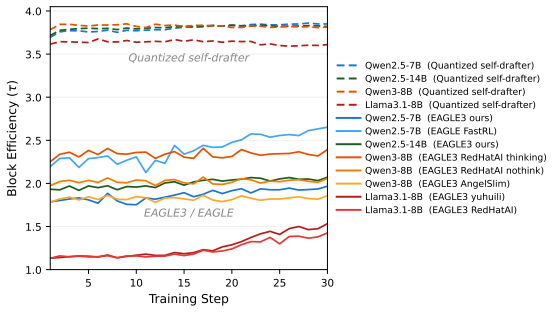
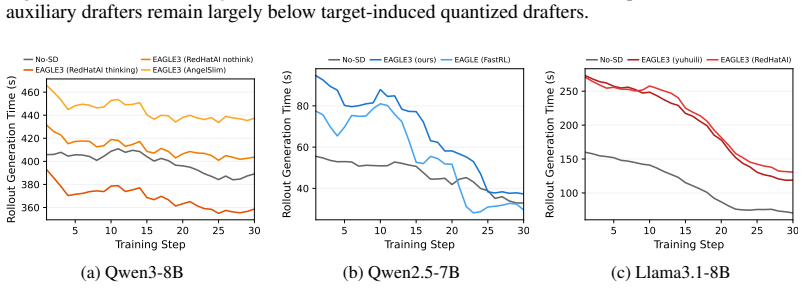
EfficientRollout induces a quantized drafter from the target model for self-speculative decoding, keeping it coupled to the evolving policy without separate drafter pretraining or online adaptation. It coordinates a system-aware SD toggle policy with acceptance-aware draft-length adaptation, enabling speculation only in beneficial memory-bound regimes. This produces up to 19.6 percent reduction in rollout latency and 12.7 percent in end-to-end latency over an accelerated autoregressive baseline while preserving final model quality.
What carries the argument
A quantized drafter induced from the target model, coordinated with a system-aware SD toggle policy and acceptance-aware draft-length adaptation.
If this is right
- Rollout latency drops by up to 19.6 percent and end-to-end latency by up to 12.7 percent relative to accelerated autoregressive baselines.
- The target-model distribution is exactly preserved, so final model quality after RL training stays unchanged.
- No separate drafter pretraining or online adaptation is required because the drafter is induced from the target model itself.
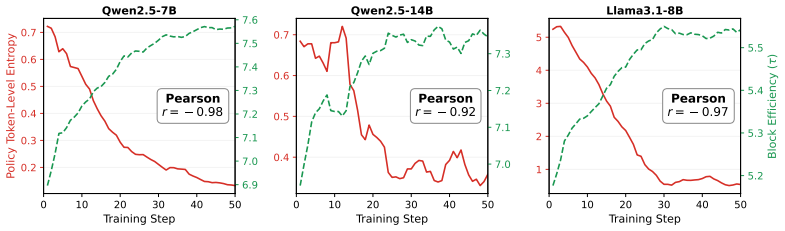
- Speculation is applied only in memory-bound regimes where active batch sizes have shrunk, avoiding overhead in compute-bound phases.
Where Pith is reading between the lines
- The same self-speculative construction could be tested in other online training loops where the model distribution shifts continuously.
- Lower overall wall-clock time for RL post-training might allow more frequent policy updates or larger batch sizes within fixed compute budgets.
- Varying the quantization precision of the induced drafter offers a direct knob for trading acceptance rate against drafting speed in future implementations.
Load-bearing premise
The quantized drafter remains sufficiently matched to the evolving high-temperature policy distribution throughout training so that acceptance rates stay high enough to produce net speedup.
What would settle it
An experiment that measures acceptance rates on long high-temperature rollouts from the trained policy and finds that the overhead of drafting exceeds the gains from parallel verification would eliminate the reported latency reduction.
Figures

read the original abstract
Reinforcement learning (RL) has become a representative post-training paradigm for LLMs, enabling strong reasoning and agentic capabilities. However, rollout generation remains a dominant latency bottleneck because autoregressive sampling decodes responses sequentially and a small number of long-tailed generations often determine completion time. Speculative decoding (SD) offers a natural way to address this bottleneck, as it is a well-established technique for serving fixed LLMs that reduces latency by rapidly drafting tokens and accepting them through parallel verification while preserving the target-model distribution. However, its practical speedups do not directly carry over to RL rollouts: (i) the evolving target policy makes any fixed drafter increasingly mismatched with the policy's output distribution; and (ii) active batch sizes shrink throughout rollout decoding, shifting decoding from compute-bound to memory-bound regimes where parallel verification can exploit underutilized compute. Therefore, accelerating RL rollouts requires both a drafter that remains effective under long, high-temperature generations from an evolving policy and system-aware use of SD that avoids compute-bound regimes. We present EfficientRollout, a system-aware self-SD framework designed to address this gap for RL rollouts. EfficientRollout induces a quantized drafter from the target model (i.e. self-speculative decoding), keeping it coupled to the evolving policy without separate drafter pretraining or online adaptation. It further coordinates a system-aware SD toggle policy with acceptance-aware draft-length adaptation, enabling speculation only in beneficial regimes while matching the drafting budget to evolving drafter quality. EfficientRollout reduces rollout and end-to-end latency by up to 19.6% and 12.7%, respectively, over an accelerated AR rollout baseline, while preserving final model quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EfficientRollout, a system-aware self-speculative decoding method for RL rollouts in LLMs. It induces a single quantized drafter from the target model (self-SD) to stay coupled to the evolving policy without separate pretraining or online adaptation, and combines this with a system-aware SD toggle policy plus acceptance-aware draft-length adaptation to speculate only in memory-bound regimes. The central empirical claim is that this yields up to 19.6% rollout latency reduction and 12.7% end-to-end latency reduction versus an accelerated autoregressive baseline while preserving final model quality.
Significance. If the reported speedups are robust, the work addresses a practical bottleneck in LLM post-training by making speculative decoding viable under shifting high-temperature policies and shrinking batch sizes without extra training overhead. The system-aware components and self-induced drafter are pragmatic contributions that could improve efficiency of RL-based reasoning and agent training pipelines.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The speedup claims rest on the precondition that the once-induced quantized drafter maintains sufficiently high acceptance rates as the target policy distribution shifts during RL training. No acceptance-rate curves versus training step or temperature are referenced; if acceptance falls below the breakeven point in later epochs, the system-aware toggle and draft-length adaptation cannot deliver the stated net latency reductions.
- [§3.1] §3.1 (Drafter Induction): The manuscript states the drafter is induced once from the target model and remains effective without online adaptation, yet provides no quantitative comparison of acceptance rates between the initial induction distribution and the final high-temperature policy distribution after RL. This leaves the central assumption unverified.
minor comments (2)
- [§4.2] Figure captions and §4.2 should explicitly state the number of random seeds, error-bar computation method, and whether the reported 19.6% / 12.7% figures are means or best-case values.
- [§3.3] Notation for the draft-length adaptation rule (Eq. X) should be defined before first use and cross-referenced in the system-aware toggle description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the robustness of the induced drafter. The comments correctly note the absence of explicit acceptance-rate analyses. We address each point below and will incorporate the requested quantitative evidence in revision.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The speedup claims rest on the precondition that the once-induced quantized drafter maintains sufficiently high acceptance rates as the target policy distribution shifts during RL training. No acceptance-rate curves versus training step or temperature are referenced; if acceptance falls below the breakeven point in later epochs, the system-aware toggle and draft-length adaptation cannot deliver the stated net latency reductions.
Authors: We agree that acceptance-rate curves versus training step and temperature are not present and would strengthen the central claim. The reported end-to-end latency reductions and unchanged final model quality provide indirect support that the drafter remains above breakeven, because the system-aware toggle disables speculation when acceptance is insufficient. To address the concern directly, we will add acceptance-rate plots over training steps and across temperatures in the revised manuscript. revision: yes
-
Referee: [§3.1] §3.1 (Drafter Induction): The manuscript states the drafter is induced once from the target model and remains effective without online adaptation, yet provides no quantitative comparison of acceptance rates between the initial induction distribution and the final high-temperature policy distribution after RL. This leaves the central assumption unverified.
Authors: The manuscript does not contain a direct side-by-side comparison of acceptance rates at induction versus at the end of RL training. While the overall speedups without quality loss are consistent with the assumption holding, we acknowledge that an explicit quantitative comparison would better verify it. We will add this comparison (initial vs. final acceptance rates under the final high-temperature policy) to §3.1 in the revision. revision: yes
Circularity Check
No circularity: empirical latency measurements from system implementation
full rationale
The paper describes an engineering system (quantized self-drafter induced once from target, plus toggle and draft-length adaptation) and reports measured speedups (19.6% rollout, 12.7% end-to-end) against an AR baseline. No derivation chain, equations, or fitted parameters are shown that reduce a claimed prediction back to the inputs by construction. The drafter-induction step is a one-time engineering choice, not a self-definitional loop or renamed fit. Self-citations, if present, are not load-bearing for the latency numbers, which are externally falsifiable via timing benchmarks. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ShareGPT_Vicuna_unfiltered
Aeala. ShareGPT_Vicuna_unfiltered. https://huggingface.co/datasets/Aeala/ ShareGPT_Vicuna_unfiltered, 2023. Hugging Face dataset. Accessed: 2026-05-03
2023
-
[2]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
2023
-
[3]
Qwen3-8B_eagle3
AngelSlim. Qwen3-8B_eagle3. https://huggingface.co/AngelSlim/Qwen3-8B_ eagle3, 2025. Hugging Face model. Accessed: 2026-06-06
2025
-
[4]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. InForty-first International Conference on Machine Learning, 2024. URL https: //openreview.net/forum?id=PEpbUobfJv. 10
2024
-
[5]
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
Pith/arXiv arXiv 2025
-
[6]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
Pith/arXiv arXiv 2023
-
[7]
Clasp: In-context layer skip for self-speculative decoding
Longze Chen, Renke Shan, Huiming Wang, Lu Wang, Ziqiang Liu, Run Luo, Jiawei Wang, Hamid Alinejad-Rokny, and Min Yang. Clasp: In-context layer skip for self-speculative decoding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31608–31618, 2025
2025
-
[8]
Respec: Towards optimizing speculative decoding in reinforcement learning systems
Qiaoling Chen, Zijun Liu, Peng Sun, Shenggui Li, Guoteng Wang, Ziming Liu, Yonggang Wen, Siyuan Feng, and Tianwei Zhang. Respec: Towards optimizing speculative decoding in reinforcement learning systems. InNinth Conference on Machine Learning and Systems, 2026. URLhttps://openreview.net/forum?id=HhDSxs7x2R
2026
-
[9]
Do NOT think that much for 2+3=? on the overthinking of long reasoning models
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT think that much for 2+3=? on the overthinking of long reasoning models. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=...
2025
-
[10]
Zhuoming Chen, Hongyi Liu, Yang Zhou, Haizhong Zheng, and Beidi Chen. Jackpot: Optimal budgeted rejection sampling for extreme actor-policy mismatch reinforcement learning.arXiv preprint arXiv:2602.06107, 2026
arXiv 2026
-
[11]
Multi-head attention: Collaborate instead of concatenate.arXiv preprint arXiv:2006.16362, 2020
Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. Multi-head attention: Collaborate instead of concatenate.arXiv preprint arXiv:2006.16362, 2020
arXiv 2006
-
[12]
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
Pith/arXiv arXiv 2025
-
[13]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=OUIFPHEgJU
2023
-
[14]
Marlin: Mixed- precision auto-regressive parallel inference on large language models
Elias Frantar, Roberto L Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. Marlin: Mixed- precision auto-regressive parallel inference on large language models. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 239–251, 2025
2025
-
[15]
AREAL: A large-scale asynchronous reinforcement learning system for language reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, WANG JIASHU, Tongkai Yang, Binhang Yuan, and Yi Wu. AREAL: A large-scale asynchronous reinforcement learning system for language reasoning. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id...
2026
-
[16]
Ai and memory wall.IEEE Micro, 44(3):33–39, 2024
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W Mahoney, and Kurt Keutzer. Ai and memory wall.IEEE Micro, 44(3):33–39, 2024
2024
-
[17]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[18]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[19]
Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen. History rhymes: Accelerating llm reinforcement learning with rhymerl.arXiv preprint arXiv:2508.18588, 2025. 11
arXiv 2025
-
[20]
Rest: Retrieval-based speculative decoding
Zhenyu He, Zexuan Zhong, Tianle Cai, Jason Lee, and Di He. Rest: Retrieval-based speculative decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1582–1595, 2024
2024
-
[21]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[22]
Taming the long-tail: Efficient reasoning rl training with adaptive drafter
Qinghao Hu, Shang Yang, Junxian Guo, Xiaozhe Yao, Yujun Lin, Yuxian Gu, Han Cai, Chuang Gan, Ana Klimovic, and Song Han. Taming the long-tail: Efficient reasoning rl training with adaptive drafter. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 1933–1948, 2026
1933
-
[23]
Ash, and Akshay Krishnamurthy
Audrey Huang, Adam Block, Dylan J Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T. Ash, and Akshay Krishnamurthy. Self-improvement in language models: The sharp- ening mechanism. InThe Thirteenth International Conference on Learning Representations,
-
[24]
URLhttps://openreview.net/forum?id=WJaUkwci9o
-
[25]
Hayate Iso, Tiyasa Mitra, Sudipta Mondal, Rasoul Shafipour, Venmugil Elango, Terry Kong, Yuki Huang, Seonjin Na, Izzy Putterman, Benjamin Chislett, et al. Accelerating rl post-training rollouts via system-integrated speculative decoding.arXiv preprint arXiv:2604.26779, 2026
Pith/arXiv arXiv 2026
-
[26]
Renren Jin, Pengzhi Gao, Yuqi Ren, Zhuowen Han, Tongxuan Zhang, Wuwei Huang, Wei Liu, Jian Luan, and Deyi Xiong. Revisiting entropy in reinforcement learning for large reasoning models.arXiv preprint arXiv:2511.05993, 2025
Pith/arXiv arXiv 2025
-
[27]
Minseo Kim, Coleman Hooper, Aditya Tomar, Chenfeng Xu, Mehrdad Farajtabar, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. Beyond next-token prediction: A perfor- mance characterization of diffusion versus autoregressive language models.arXiv preprint arXiv:2510.04146, 2025
arXiv 2025
-
[28]
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Fahad Shahbaz Khan, and Salman Khan. Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321, 2025
arXiv 2025
-
[29]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[30]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[31]
QuRL: Low-precision reinforcement learning for efficient reasoning
Yuhang Li, Reena Elangovan, Xin Dong, Priyadarshini Panda, and Brucek Khailany. QuRL: Low-precision reinforcement learning for efficient reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=eG0bpCwdKn
2026
-
[32]
EAGLE: Speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=1NdN7eXyb4
2024
-
[33]
EAGLE-3: Scaling up inference acceleration of large language models via training-time test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-3: Scaling up inference acceleration of large language models via training-time test. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=4exx1hUffq. 12
2026
-
[34]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[35]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
Pith/arXiv arXiv 2024
-
[36]
Spec-rl: Accelerating on-policy reinforcement learning via speculative rollouts
Bingshuai Liu, Ante Wang, Zijun Min, Liang Yao, Haibo Zhang, Yang Liu, Anxiang Zeng, and Jinsong Su. Spec-rl: Accelerating on-policy reinforcement learning via speculative rollouts. arXiv preprint arXiv:2509.23232, 2025
arXiv 2025
-
[37]
Speculative decoding: Performance or illusion? InNinth Conference on Machine Learning and Systems, 2026
Xiaoxuan Liu, Jiaxiang Yu, Jongseok Park, Ion Stoica, and Alvin Cheung. Speculative decoding: Performance or illusion? InNinth Conference on Machine Learning and Systems, 2026. URL https://openreview.net/forum?id=fzkqtezFEi
2026
-
[38]
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Pith/arXiv arXiv 2025
-
[39]
Qwen2.5-7B-Eagle-RL
MIT HAN Lab. Qwen2.5-7B-Eagle-RL. https://huggingface.co/mit-han-lab/Qwen2. 5-7B-Eagle-RL, 2025. Hugging Face model. Accessed: 2026-06-08
2025
-
[40]
OpenThoughts2-1M
open-thoughts. OpenThoughts2-1M. https://huggingface.co/datasets/ open-thoughts/OpenThoughts2-1M, 2025. Hugging Face dataset. Accessed: 2026- 06-08
2025
-
[41]
Lossless acceleration of large language model via adaptive n-gram parallel decoding
Jie Ou, Yueming Chen, et al. Lossless acceleration of large language model via adaptive n-gram parallel decoding. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), pages 10–22, 2024
2024
-
[42]
Llama-3.1-8B-Instruct-speculator.eagle3
RedHatAI. Llama-3.1-8B-Instruct-speculator.eagle3. https://huggingface.co/ RedHatAI/Llama-3.1-8B-Instruct-speculator.eagle3 , 2025. Hugging Face model. Accessed: 2026-05-04
2025
-
[43]
Qwen3-8B-speculator.eagle3
RedHatAI. Qwen3-8B-speculator.eagle3. https://huggingface.co/RedHatAI/ Qwen3-8B-speculator.eagle3, 2025. Hugging Face model. Accessed: 2026-06-06
2025
-
[44]
Qwen3-8B-Thinking-speculator.eagle3
RedHatAI. Qwen3-8B-Thinking-speculator.eagle3. https://huggingface.co/RedHatAI/ Qwen3-8B-Thinking-speculator.eagle3 , 2026. Hugging Face model. Accessed: 2026- 06-06
2026
-
[45]
Magicdec: Breaking the latency- throughput tradeoff for long context generation with speculative decoding
Ranajoy Sadhukhan, Jian Chen, Zhuoming Chen, Vashisth Tiwari, Ruihang Lai, Jinyuan Shi, Ian En-Hsu Yen, Avner May, Tianqi Chen, and Beidi Chen. Magicdec: Breaking the latency- throughput tradeoff for long context generation with speculative decoding. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/f...
2025
-
[46]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[47]
Beat the long tail: Distribution-aware speculative decoding for RL training
Zelei Shao, Vikranth Srivatsa, Sanjana Srivastava, Qingyang Wu, Alpay Ariyak, Xiaoxia wu, Ameen Patel, Jue Wang, Percy Liang, Tri Dao, Ce Zhang, Yiying Zhang, Ben Athiwaratkun, Chenfeng Xu, and Junxiong Wang. Beat the long tail: Distribution-aware speculative decoding for RL training. InNinth Conference on Machine Learning and Systems, 2026. URL https: //...
2026
-
[48]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 13
Pith/arXiv arXiv 2024
-
[49]
Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
Pith/arXiv arXiv 1911
-
[50]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[51]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
Pith/arXiv arXiv 1909
-
[52]
Knn-ssd: Enabling dynamic self-speculative decoding via nearest neighbor layer set optimization
Mingbo Song, Heming Xia, Jun Zhang, Chak Tou Leong, Qiancheng Xu, Wenjie Li, and Sujian Li. Knn-ssd: Enabling dynamic self-speculative decoding via nearest neighbor layer set optimization. InFindings of the Association for Computational Linguistics: EACL 2026, pages 641–655, 2026
2026
-
[53]
Lawrence Stewart, Matthew Trager, Sujan Kumar Gonugondla, and Stefano Soatto. The n- grammys: Accelerating autoregressive inference with learning-free batched speculation.arXiv preprint arXiv:2411.03786, 2024
arXiv 2024
-
[54]
QUEST: Query-aware sparsity for efficient long-context LLM inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. QUEST: Query-aware sparsity for efficient long-context LLM inference. InForty-first Inter- national Conference on Machine Learning, 2024. URLhttps://openreview.net/forum? id=KzACYw0MTV
2024
-
[55]
Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Pith/arXiv arXiv 2025
-
[56]
Mahoney, Kurt Keutzer, and Amir Gholami
Rishabh Tiwari, Haocheng Xi, Aditya Tomar, Coleman Richard Charles Hooper, Sehoon Kim, Maxwell Horton, Mahyar Najibi, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. Quantspec: Self-speculative decoding with hierarchical quantized KV cache. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=7SHbJENgHX
2025
-
[57]
Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLMs
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum...
2026
-
[58]
Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[59]
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding.Findings of the Association for Computational Linguistics: ACL 2024, pages 7655–7671, 2024
2024
-
[60]
SWIFT: On-the-fly self- speculative decoding for LLM inference acceleration
Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, and Wenjie Li. SWIFT: On-the-fly self- speculative decoding for LLM inference acceleration. InThe Thirteenth International Con- ference on Learning Representations, 2025. URL https://openreview.net/forum?id= EKJhH5D5wA
2025
-
[61]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[62]
Chenghao Yang, Sida Li, and Ari Holtzman. Llm probability concentration: How alignment shrinks the generative horizon.arXiv preprint arXiv:2506.17871, 2025. 14
arXiv 2025
-
[63]
Qwen2.5 technical report.ArXiv, abs/2412.15115, 2024
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
Pith/arXiv arXiv 2024
-
[64]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
2026
-
[65]
Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363, 2024
Zhihang Yuan, Yuzhang Shang, Yang Zhou, Zhen Dong, Zhe Zhou, Chenhao Xue, Bingzhe Wu, Zhikai Li, Qingyi Gu, Yong Jae Lee, et al. Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363, 2024
arXiv 2024
-
[66]
Yikang Yue, Yuqi Xue, and Jian Huang. Specattn: Co-designing sparse attention with self- speculative decoding.arXiv preprint arXiv:2602.07223, 2026
Pith/arXiv arXiv 2026
-
[67]
EAGLE3-LLaMA3.1-Instruct-8B
Yuhui Li. EAGLE3-LLaMA3.1-Instruct-8B. https://huggingface.co/yuhuili/ EAGLE3-LLaMA3.1-Instruct-8B, 2024. Hugging Face model. Accessed: 2026-06-06
2024
-
[68]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
Pith/arXiv arXiv 2025
-
[69]
SimpleRL-zoo: Investigating and taming zero reinforcement learning for open base models in the wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun MA, and Junxian He. SimpleRL-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. InSecond Conference on Language Modeling, 2025. URL https://openreview. net/forum?id=vSMCBUgrQj
2025
-
[70]
Draft& verify: Lossless large language model acceleration via self-speculative decoding
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. Draft& verify: Lossless large language model acceleration via self-speculative decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11263–11282, 2024
2024
-
[71]
Yiqi Zhang, Huiqiang Jiang, Xufang Luo, Zhihe Yang, Chengruidong Zhang, Yifei Shen, Dongsheng Li, Yuqing Yang, Lili Qiu, and Yang You. Sortedrl: Accelerating rl training for llms through online length-aware scheduling.arXiv preprint arXiv:2603.23414, 2026
arXiv 2026
-
[72]
FastGRPO: Accelerating policy optimization via concurrency-aware speculative decoding and online draft learning
Yizhou Zhang, Ning Lv, Teng Wang, and Jisheng Dang. FastGRPO: Accelerating policy optimization via concurrency-aware speculative decoding and online draft learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=zuGt6TYYtS
2026
-
[73]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham M. Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: RL post-training amplifies behaviors learned in pretraining. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= dp4KWuSDzj
2025
-
[74]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net...
2024
-
[75]
Distillspec: Improving speculative decoding via knowledge distillation
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Ros- tamizadeh, Sanjiv Kumar, Jean-François Kagy, and Rishabh Agarwal. Distillspec: Improving speculative decoding via knowledge distillation. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=rsY6J3ZaTF
2024
-
[76]
Yuzhen Zhou, Jiajun Li, Yusheng Su, Gowtham Ramesh, Zilin Zhu, Xiang Long, Chenyang Zhao, Jin Pan, Xiaodong Yu, Ze Wang, et al. April: Active partial rollouts in reinforcement learning to tame long-tail generation.arXiv preprint arXiv:2509.18521, 2025. 16 Appendix A Extended Analysis of Shrinking-Batch Dynamics 18 B System Rationale for Weight-Quantized S...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.