Delay-Adaptive Speculation Control for Low-Latency Edge-Cloud LLM Inference
Pith reviewed 2026-06-30 19:45 UTC · model grok-4.3
The pith
The optimal draft length for edge-cloud speculative LLM decoding is a finite delay-monotone threshold that grows logarithmically with communication delay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
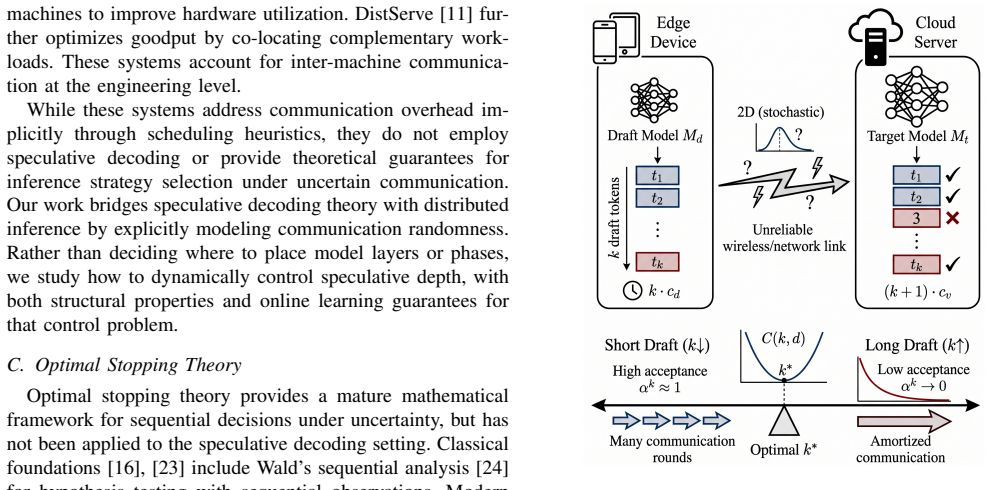
We formulate this tradeoff as a ratio-type optimal stopping problem and prove that the optimal draft length is a finite delay-monotone threshold. The analysis identifies a critical delay below which single-token speculation is optimal and shows that the optimal length grows only logarithmically with communication delay. For time-varying networks, we extend the model to Markov-modulated channels and establish, under a bounded horizon and monotone stopping-region conditions, a state-dependent threshold policy. For unknown environments, we propose UCB-SpecStop with gap-free and gap-dependent expected regret bounds.
What carries the argument
Ratio-type optimal stopping problem that produces a delay-monotone threshold policy for choosing draft length.
If this is right
- Below a critical delay value, single-token speculation becomes optimal.
- Optimal draft length increases only logarithmically as communication delay rises.
- UCB-SpecStop achieves sublinear regret bounds of O(L_max sqrt(K_max T log(K_max T))) in unknown delay environments.
- A state-dependent threshold policy applies when channel state follows a Markov process under the stated conditions.
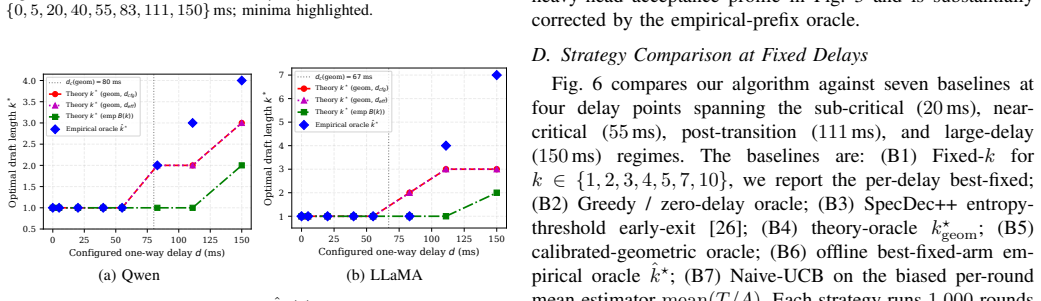
- Experiments show up to 22.4 percent per-token latency reduction over SpecDec++ and near-oracle performance in communication-heavy regimes.
Where Pith is reading between the lines
- The same threshold structure could guide draft-length adaptation in other distributed inference settings such as multi-hop wireless links.
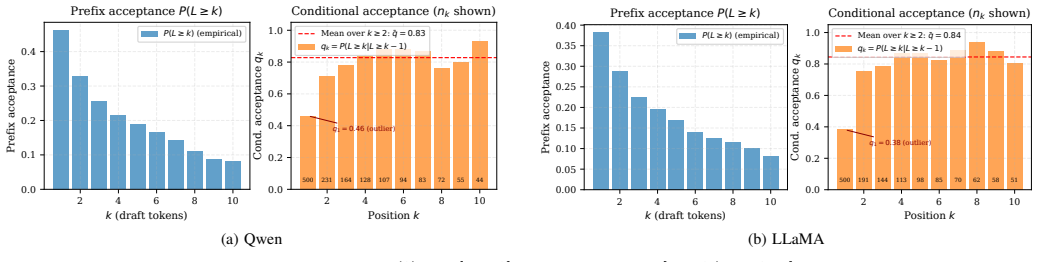
- Models whose acceptance rates deviate from geometric (as seen with Llama) may require a short empirical prefix calibration step before the threshold rule applies.
- The logarithmic scaling suggests the policy remains practical even when edge-cloud round-trip times reach several hundred milliseconds.
Load-bearing premise
The Markov-modulated delay process satisfies bounded horizon and monotone stopping-region conditions so that a state-dependent threshold remains optimal.
What would settle it
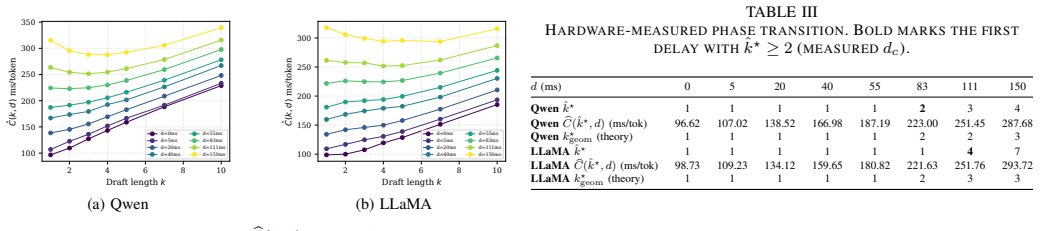
Run controlled delay sweeps on the Jetson-Orin/RTX testbed and check whether measured best draft lengths exhibit sharp phase transitions at predicted critical delays and follow the claimed logarithmic growth curve.
Figures


read the original abstract
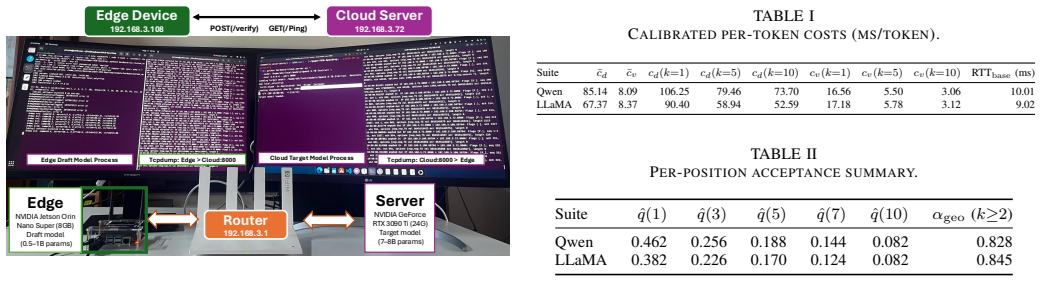
Speculative decoding accelerates large language model (LLM) inference by using a lightweight draft model to propose tokens and a larger target model to verify them in parallel. In distributed edge-cloud inference, however, draft length must be controlled online: longer drafts amortize communication delay but reduce token acceptance, whereas shorter drafts preserve acceptance but trigger more communication rounds. We formulate this tradeoff as a ratio-type optimal stopping problem and prove that the optimal draft length is a finite delay-monotone threshold. The analysis identifies a critical delay below which single-token speculation is optimal and shows that the optimal length grows only logarithmically with communication delay. For time-varying networks, we extend the model to Markov-modulated channels and establish, under a bounded horizon and monotone stopping-region conditions, a state-dependent threshold policy. For unknown environments, we propose UCB-SpecStop, an online control algorithm with gap-free and gap-dependent expected regret bounds of $O(L_{\max}\sqrt{K_{\max}T\log(K_{\max}T)})$ and $O(\sum_{k:\Delta_k>0}L_{\max}^2\log(K_{\max}T)/\Delta_k)$. We implement the method on a real edge-cloud testbed with a Jetson Orin Nano Super edge node and an RTX~3090 Ti cloud node, using Qwen and Llama draft--target pairs. Experiments validate the predicted phase transition, with transition points near 83~ms and 111~ms. Qwen matches the geometric prediction, while Llama requires empirical-prefix calibration due to heavy-head acceptance. Across the tested delay grid, UCB-SpecStop reduces per-token latency over SpecDec++ by up to 22.4\%, approaches an offline oracle within 0.2--2.4\% in communication-dominated regimes, improves over naive UCB by up to 7.5\%, removes the 14.0--18.7\% gap caused by static tuning under delay drift, and gains 3.0--6.8\% with contextual channel-state information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models draft-length control in edge-cloud speculative decoding as a ratio-type optimal stopping problem. It claims to prove that the optimal draft length is a finite delay-monotone threshold, identifies a critical delay below which single-token speculation is optimal, and shows logarithmic growth of the optimum with communication delay. For time-varying networks the model is extended to Markov-modulated channels, yielding a state-dependent threshold policy once bounded-horizon and monotone stopping-region conditions are imposed. An online algorithm UCB-SpecStop is proposed with gap-free and gap-dependent regret bounds O(L_max sqrt(K_max T log(K_max T))) and O(sum Delta_k^{-1} L_max^2 log(K_max T)). Real-testbed experiments with Qwen/Llama pairs on Jetson Orin Nano and RTX 3090 Ti hardware report up to 22.4% latency reduction versus SpecDec++ and close approach to an offline oracle.
Significance. If the derivations are supplied and the monotonicity conditions are verified, the work supplies a principled optimal-stopping treatment of the acceptance-versus-delay tradeoff together with online-learning regret guarantees. The real-hardware implementation and the explicit phase-transition predictions constitute concrete strengths that could inform adaptive control in distributed LLM serving.
major comments (3)
- [Abstract / optimal-stopping formulation] Abstract and the optimal-stopping analysis section: the manuscript asserts that the ratio-type objective yields a finite delay-monotone threshold policy and supplies explicit regret bounds, yet provides no derivation steps showing that the ratio objective satisfies the conditions required for the threshold result or that the bounds follow from the stated formulation.
- [Markov-modulated extension] Markov-modulated channels paragraph (abstract and corresponding analysis section): the state-dependent threshold policy is claimed once a bounded horizon and monotone stopping-region conditions are imposed, but no derivation or verification is given that the acceptance-rate function or the delay-transition kernel of the edge-cloud model actually satisfies monotonicity; this assumption is load-bearing for the time-varying-network claim.
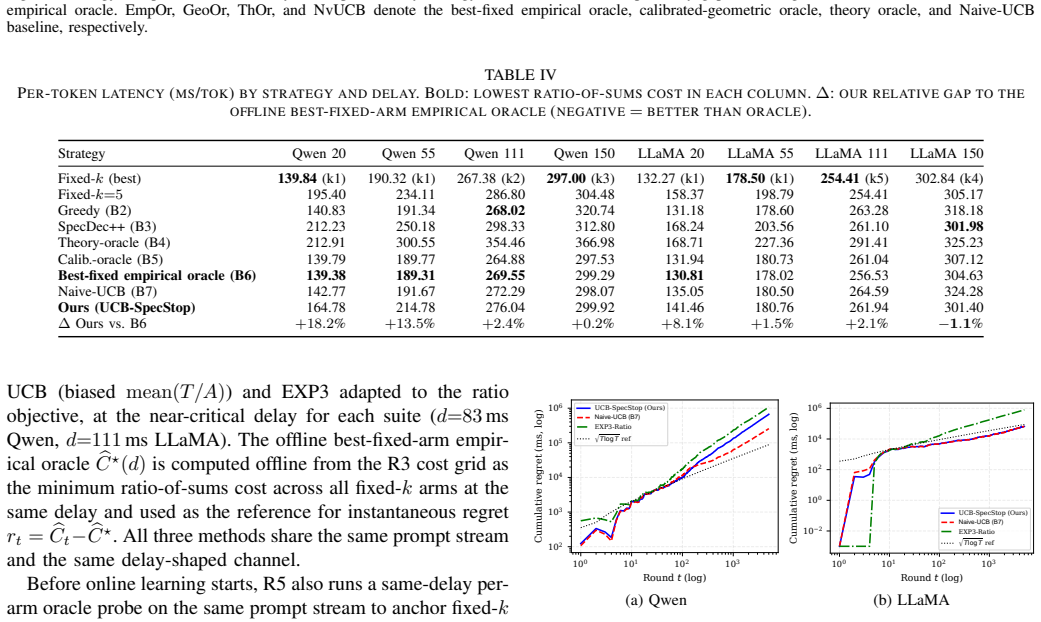
- [Experiments] Experimental evaluation section: performance claims rest on a single testbed without reported variance across runs, without ablation of the acceptance model, and without explicit comparison of the empirical phase-transition points (83 ms, 111 ms) against the theoretically predicted critical delay.
minor comments (2)
- [Abstract] The abstract states the regret bounds using L_max and K_max without defining these quantities or indicating where they are introduced in the text.
- [Theoretical model] Notation for the ratio objective and the acceptance probability should be introduced with explicit equation numbers in the main theoretical section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We agree that additional derivation details and experimental rigor are needed to fully support the claims. We will revise the manuscript by expanding the analysis sections with explicit proof steps and by augmenting the experiments with variance reporting, ablations, and direct theory-experiment comparisons. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract / optimal-stopping formulation] Abstract and the optimal-stopping analysis section: the manuscript asserts that the ratio-type objective yields a finite delay-monotone threshold policy and supplies explicit regret bounds, yet provides no derivation steps showing that the ratio objective satisfies the conditions required for the threshold result or that the bounds follow from the stated formulation.
Authors: We acknowledge that the main text states the threshold policy and regret bounds without reproducing the full sequence of lemmas establishing that the ratio objective meets the required monotonicity and boundedness conditions for optimal stopping. In the revision we will add an appendix containing the complete derivation: first showing that the ratio reward satisfies the necessary continuity and monotonicity properties, then proving existence of a finite delay-monotone threshold, and finally deriving the stated gap-free and gap-dependent regret bounds directly from the UCB-SpecStop formulation. This will make every step verifiable. revision: yes
-
Referee: [Markov-modulated extension] Markov-modulated channels paragraph (abstract and corresponding analysis section): the state-dependent threshold policy is claimed once a bounded horizon and monotone stopping-region conditions are imposed, but no derivation or verification is given that the acceptance-rate function or the delay-transition kernel of the edge-cloud model actually satisfies monotonicity; this assumption is load-bearing for the time-varying-network claim.
Authors: The referee correctly identifies that the manuscript invokes the monotone stopping-region condition without verifying it for the specific acceptance-rate function and delay-transition kernel arising from the edge-cloud speculative decoding model. In revision we will supply both the general theorem statement and a short verification subsection showing that the acceptance probability is non-increasing in delay and that the Markov kernel preserves the required stochastic ordering, thereby justifying the state-dependent threshold policy under the stated bounded-horizon assumption. revision: yes
-
Referee: [Experiments] Experimental evaluation section: performance claims rest on a single testbed without reported variance across runs, without ablation of the acceptance model, and without explicit comparison of the empirical phase-transition points (83 ms, 111 ms) against the theoretically predicted critical delay.
Authors: We agree that the current experimental section would be strengthened by statistical reporting and additional controls. In the revision we will (i) report mean and standard deviation over at least five independent runs for each delay setting, (ii) add an ablation that isolates the effect of the acceptance-rate model, and (iii) include a direct plot and table comparing the empirically observed phase-transition points against the theoretically computed critical delays for both Qwen and Llama pairs. These additions will be placed in a new subsection of the evaluation. revision: yes
Circularity Check
No circularity; derivations apply external optimal-stopping and bandit theory to a new objective.
full rationale
The paper states a ratio-type optimal stopping formulation for the draft-length tradeoff and proves a delay-monotone threshold policy, then extends to Markov-modulated channels under explicitly imposed bounded-horizon and monotone stopping-region conditions to obtain a state-dependent threshold. UCB-SpecStop regret bounds are stated as standard gap-free and gap-dependent forms. No quoted step reduces a claimed result to a fitted parameter, self-definition, or self-citation chain by construction; the central claims rest on external theory applied to the stated model rather than on quantities defined inside the paper itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Communications Surveys & Tutorials, vol. 27, no. 6, pp. 3820–3860, 2025
2025
-
[2]
H2o: Heterogeneity-aware hierarchical orchestration for memory-efficient on- device llm inference,
F. Zeng, F. Lyu, H. Wu, Z. Li, S. Li, F. Xu, and Y . Zhang, “H2o: Heterogeneity-aware hierarchical orchestration for memory-efficient on- device llm inference,”IEEE Transactions on Mobile Computing, 2025
2025
-
[3]
Joint inference offloading and model caching for small and large language model collaboration,
X. Xu, G. Feng, Y . Liu, S. Qin, J. Wang, and Y . Wang, “Joint inference offloading and model caching for small and large language model collaboration,”IEEE Transactions on Mobile Computing, 2025
2025
-
[4]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 274–19 286
2023
-
[5]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Edgellm: Fast on-device llm inference with speculative decoding,
D. Xu, W. Yin, H. Zhang, X. Jin, Y . Zhang, S. Wei, M. Xu, and X. Liu, “Edgellm: Fast on-device llm inference with speculative decoding,” IEEE Transactions on Mobile Computing, vol. 24, no. 4, pp. 3256–3273, 2024
2024
-
[7]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,”ACM SIGARCH Computer Architecture News, vol. 45, no. 1, pp. 615–629, 2017
2017
-
[8]
Jointdnn: An efficient training and inference engine for intelligent mobile cloud computing services,
A. E. Eshratifar, M. S. Abrishami, and M. Pedram, “Jointdnn: An efficient training and inference engine for intelligent mobile cloud computing services,”IEEE Transactions on Mobile Computing, vol. 20, no. 2, pp. 565–576, 2019
2019
-
[9]
Distributed deep neural networks over the cloud, the edge and end devices,
S. Teerapittayanon, B. McDanel, and H.-T. Kung, “Distributed deep neural networks over the cloud, the edge and end devices,” in2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2017, pp. 328–339
2017
-
[10]
Splitwise: Efficient generative llm inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, ´I. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 2024, pp. 118–132
2024
-
[11]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 193–210
2024
-
[12]
Sled: A speculative llm decoding framework for efficient edge serving,
X. Li, D. Spatharakis, S. Ghafouri, J. Fan, H. Vandierendonck, D. John, B. Ji, and D. S. Nikolopoulos, “Sled: A speculative llm decoding framework for efficient edge serving,” inProceedings of the Tenth ACM/IEEE Symposium on Edge Computing, 2025, pp. 1–8
2025
-
[13]
Flexspec: Frozen drafts meet evolving targets in edge-cloud collaborative llm speculative decoding,
Y . Li, R. Kong, Z. Lyu, Q. Li, X. Chen, H. Cai, L. Yan, S. Wang, J. Zhao, G. Zhuet al., “Flexspec: Frozen drafts meet evolving targets in edge-cloud collaborative llm speculative decoding,”arXiv preprint arXiv:2601.00644, 2026
-
[14]
Configspec: Profiling-based configuration selection for distributed edge-cloud speculative llm serving,
X. Li, S. Ghafouri, J. Fan, B. Ali, H. Vandierendonck, and D. S. Nikolopoulos, “Configspec: Profiling-based configuration selection for distributed edge-cloud speculative llm serving,” inProceedings of the 4th International Workshop on Testing Distributed Internet of Things Systems, 2026, pp. 1–6
2026
-
[15]
Fast and cost-effective specu- lative edge-cloud decoding with early exits,
Y . Venkatesha, S. Kundu, and P. Panda, “Fast and cost-effective specu- lative edge-cloud decoding with early exits,”Transactions on Machine Learning Research, 2025
2025
-
[16]
Optimal stopping and applications,
T. S. Ferguson, “Optimal stopping and applications,” UCLA Mathematics Dept., lecture notes, 2006. [Online]. Available: https://www.math.ucla.edu/∼tom/Stopping/Contents.html
2006
-
[17]
Blockwise parallel decoding for deep autoregressive models,
M. Stern, N. Shazeer, and J. Uszkoreit, “Blockwise parallel decoding for deep autoregressive models,”Advances in Neural Information Pro- cessing Systems, vol. 31, 2018
2018
-
[18]
Specinfer: Accelerating large language model serving with tree-based speculative inference and ver- ification,
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, Z. Zhang, R. Y . Y . Wong, A. Zhu, L. Yang, X. Shiet al., “Specinfer: Accelerating large language model serving with tree-based speculative inference and ver- ification,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3...
2024
-
[19]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Y . Li, F. Wei, C. Zhang, and H. Zhang, “Eagle: Speculative sampling re- quires rethinking feature uncertainty,”arXiv preprint arXiv:2401.15077, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Medusa: Simple llm inference acceleration framework with multiple decoding heads,
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple llm inference acceleration framework with multiple decoding heads,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 5209–5235
2024
-
[21]
Rest: Retrieval-based speculative decoding,
Z. He, Z. Zhong, T. Cai, J. Lee, and D. He, “Rest: Retrieval-based speculative decoding,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 1582–1595
2024
-
[22]
Online speculative decoding,
X. Liu, L. Hu, P. Bailis, A. Cheung, Z. Deng, I. Stoica, and H. Zhang, “Online speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 31 131–31 146
2024
-
[23]
Great expectations: The theory of optimal stopping,
Y . S. Chow, H. Robbins, D. Siegmundet al., “Great expectations: The theory of optimal stopping,” 1971
1971
-
[24]
Wald,Sequential analysis
A. Wald,Sequential analysis. Courier Corporation, 2004
2004
-
[25]
Minimizing a submodular function on a lattice,
D. M. Topkis, “Minimizing a submodular function on a lattice,”Oper- ations research, vol. 26, no. 2, pp. 305–321, 1978
1978
-
[26]
Specdec++: Boosting speculative decoding via adaptive candidate lengths,
K. Huang, X. Guo, and M. Wang, “Specdec++: Boosting speculative decoding via adaptive candidate lengths,” inSecond Conference on Language Modeling, 2024
2024
-
[27]
Tetris: Optimal draft token selection for batch speculative decoding,
Z. Wu, Z. Zhou, A. Verma, A. Prakash, D. Rus, and B. K. H. Low, “Tetris: Optimal draft token selection for batch speculative decoding,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 33 329– 33 345
2025
-
[28]
Batch speculative decoding done right,
R. H. Zhang, S. Dey, A. Mishra, H. Wu, B. Li, and R. Zhang, “Batch speculative decoding done right,”arXiv preprint arXiv:2510.22876, 2025
-
[29]
On nonlinear fractional programming,
W. Dinkelbach, “On nonlinear fractional programming,”Management science, vol. 13, no. 7, pp. 492–498, 1967
1967
-
[30]
Finite-time analysis of the multiarmed bandit problem,
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,”Machine learning, vol. 47, no. 2, pp. 235– 256, 2002
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.