SPARC: Spatial-Aware Path Planning via Attentive Agent Communication
Pith reviewed 2026-05-21 11:53 UTC · model grok-4.3
The pith
Embedding Manhattan distances into attention lets robots prioritize nearby teammates and reach 75 percent success when scaling from 8 to 128 agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
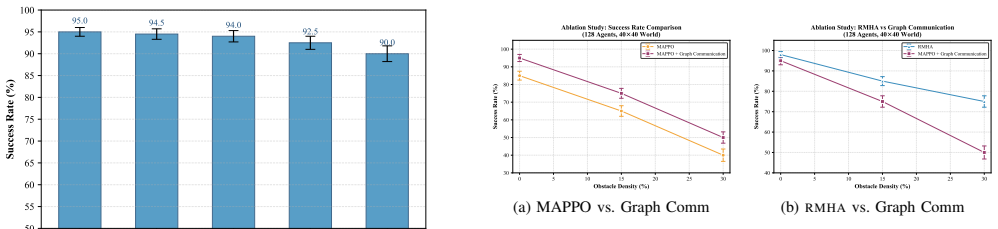
RMHA embeds pairwise Manhattan distances directly into the attention weight computation so each robot can assign higher weight to messages from spatially close neighbors. Paired with a distance-constrained attention mask and GRU-gated fusion, the module plugs into MAPPO for end-to-end training. On 40 by 40 grids with 30 percent obstacle density, the resulting policy generalizes zero-shot from 8 training robots to 128 test robots at approximately 75 percent success rate, exceeding the strongest baseline by more than 25 percentage points. Ablation experiments identify the distance-relation encoding as the decisive factor behind gains in high-density regimes.
What carries the argument
Relation enhanced Multi Head Attention (RMHA), which augments standard multi-head attention by injecting pairwise Manhattan distances into the weight computation to let robots dynamically favor messages from nearby agents.
If this is right
- Focused attention on nearby robots improves coordination precisely where obstacles force frequent local replanning.
- The same architecture trains stably inside MAPPO without additional regularization.
- Zero-shot scaling from 8 to 128 robots occurs without retraining or architecture changes.
- Ablation results show that distance encoding, rather than extra heads or fusion alone, accounts for most of the observed lift.
Where Pith is reading between the lines
- The same distance-aware attention pattern could be reused in other multi-agent settings that require selective long-range communication, such as formation control or distributed sensing.
- Because distant messages are masked, total communication volume may drop in large swarms, offering a route to lower bandwidth use.
- Physical-robot trials with noisy range sensors would test whether the learned prioritization survives the gap from simulation to hardware.
Load-bearing premise
That explicitly embedding pairwise Manhattan distances into the attention weight computation, combined with a distance-constrained mask and GRU fusion, will enable robots to prioritize spatially relevant neighbors sufficiently to produce the claimed performance gains in congested high-density environments.
What would settle it
Re-training and testing the identical MAPPO setup on the 128-robot 30-percent-obstacle cases but with the Manhattan-distance embedding removed from RMHA; if success rate then falls below 50 percent, the centrality of spatial embedding is falsified.
Figures








read the original abstract
Efficient communication is critical for decentralized Multi-Robot Path Planning (MRPP), yet existing learned communication methods treat all neighboring robots equally regardless of their spatial proximity, leading to diluted attention in congested regions where coordination matters most. We propose Relation enhanced Multi Head Attention (RMHA), a communication mechanism that explicitly embeds pairwise Manhattan distances into the attention weight computation, enabling each robot to dynamically prioritize messages from spatially relevant neighbors. Combined with a distance-constrained attention mask and GRU gated message fusion, RMHA integrates seamlessly with MAPPO for stable end-to-end training. In zero-shot generalization from 8 training robots to 128 test robots on 40x40 grids, RMHA achieves approximately 75 percent success rate at 30 percent obstacle density outperforming the best baseline by over 25 percentage points. Ablation studies confirm that distance-relation encoding is the key contributor to success rate improvement in high-density environments. Index Terms-Multi-robot path planning, graph attention mechanism, multi-head attention, communication optimization, cooperative decision-making
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPARC, a framework for decentralized multi-robot path planning that introduces Relation-enhanced Multi-Head Attention (RMHA). RMHA embeds pairwise Manhattan distances into attention weight computation, applies a distance-constrained attention mask, and uses GRU-gated message fusion, all integrated with MAPPO for end-to-end training. The central claim is strong zero-shot generalization: from 8 training robots to 128 test robots on 40x40 grids, RMHA reaches ~75% success rate at 30% obstacle density, outperforming the best baseline by >25 percentage points, with ablations attributing gains to the distance-relation encoding.
Significance. If the experimental claims hold under rigorous validation, the work would meaningfully advance learned communication for MRPP by addressing attention dilution in congested settings through explicit spatial relations. The zero-shot scaling result from 8 to 128 agents would be a notable contribution if supported by reproducible code, detailed baselines, and statistical analysis; the parameter-free nature of the Manhattan embedding is a potential strength worth highlighting.
major comments (2)
- [Abstract] Abstract: The headline performance numbers (~75% success rate at 30% density with 128 robots, >25pp improvement) are stated without any reference to experimental details, number of trials, error bars, statistical tests, baseline implementations, or specific tables/figures. This is load-bearing for the central generalization claim and prevents verification of whether the data support the result.
- [Abstract] Abstract (and method description): The distance-constrained attention mask is presented as key to prioritizing spatially relevant neighbors, yet no parameterization (e.g., radius value or adaptation rule), sensitivity analysis, or scaling behavior with agent count is supplied. A fixed radius tuned only on 8-robot training would risk either admitting too many neighbors (dilution) or too few (broken coordination) at 128-robot test density, directly undermining the zero-shot claim.
minor comments (1)
- [Abstract] The abstract mentions ablation studies confirming the importance of distance-relation encoding but provides no details on what was ablated or the quantitative impact; this should be expanded with specific results in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of clarity and rigor in presenting our experimental claims and methodological details. We address each major comment point-by-point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers (~75% success rate at 30% density with 128 robots, >25pp improvement) are stated without any reference to experimental details, number of trials, error bars, statistical tests, baseline implementations, or specific tables/figures. This is load-bearing for the central generalization claim and prevents verification of whether the data support the result.
Authors: We agree that the abstract would benefit from explicit pointers to the supporting experimental evidence. In the revised manuscript, we have updated the abstract to reference Table II (which reports success rates with standard deviations over 100 independent trials), Figure 4 (showing statistical comparisons and p-values against baselines), and Section IV-B for the MAPPO training and zero-shot evaluation protocol on 40x40 grids at 30% obstacle density. These additions allow readers to directly verify the ~75% success rate and >25pp improvement claims. revision: yes
-
Referee: [Abstract] Abstract (and method description): The distance-constrained attention mask is presented as key to prioritizing spatially relevant neighbors, yet no parameterization (e.g., radius value or adaptation rule), sensitivity analysis, or scaling behavior with agent count is supplied. A fixed radius tuned only on 8-robot training would risk either admitting too many neighbors (dilution) or too few (broken coordination) at 128-robot test density, directly undermining the zero-shot claim.
Authors: We acknowledge that the original submission did not provide explicit parameterization details or sensitivity analysis for the distance-constrained mask. We have revised the method description in Section III-C to specify that the mask uses a fixed radius selected during 8-robot training to maintain local connectivity. To directly address the zero-shot scaling concern, we have added a new ablation subsection (Section V-D) with sensitivity results across multiple radius values and agent densities, along with analysis of attention distribution to show mitigation of dilution at 128 robots. The complementary pairwise Manhattan distance embedding in RMHA provides additional spatial weighting that supports generalization beyond the hard mask alone. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical proposal
full rationale
The paper introduces RMHA as an architectural proposal that embeds pairwise Manhattan distances into attention weights, adds a distance-constrained mask, and fuses via GRU before training end-to-end with MAPPO. Performance numbers (75% success in zero-shot 8-to-128 robot transfer) are reported as measured outcomes of that training on 40x40 grids, not as quantities that are algebraically or statistically forced by the inputs. No equations or claims in the abstract reduce a prediction to a fitted parameter or to a self-citation chain; the distance embedding is presented as an explicit design choice whose value is then validated by ablation, not presupposed. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RMHA ... explicitly embeds pairwise Manhattan distances into the attention weight computation ... distance-constrained attention mask ... sij = g(oi,oj,di→j,dj→i)
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
zero-shot generalization from 8 training robots to 128 test robots on 40×40 grids
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.