From Reconstruction to Decision: A Post-Encoder Plug-in Adapter for Curvilinear Segmentation
Pith reviewed 2026-06-26 08:53 UTC · model grok-4.3
The pith
PEPA improves structural continuity in curvilinear segmentation when plugged after frozen encoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
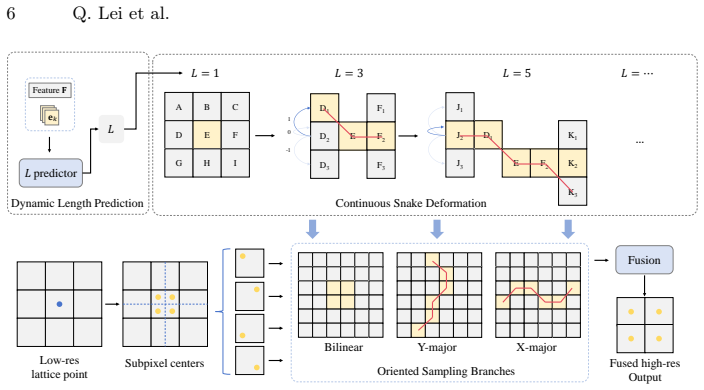
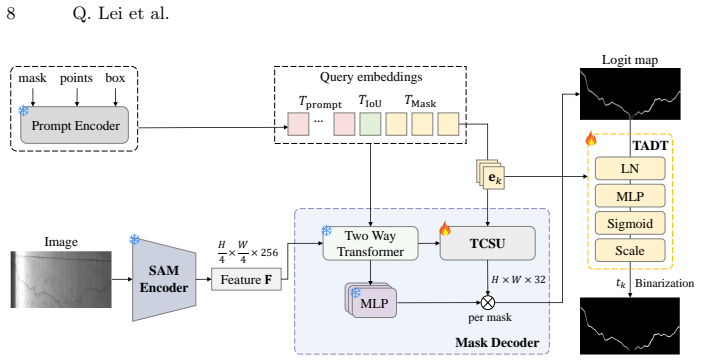
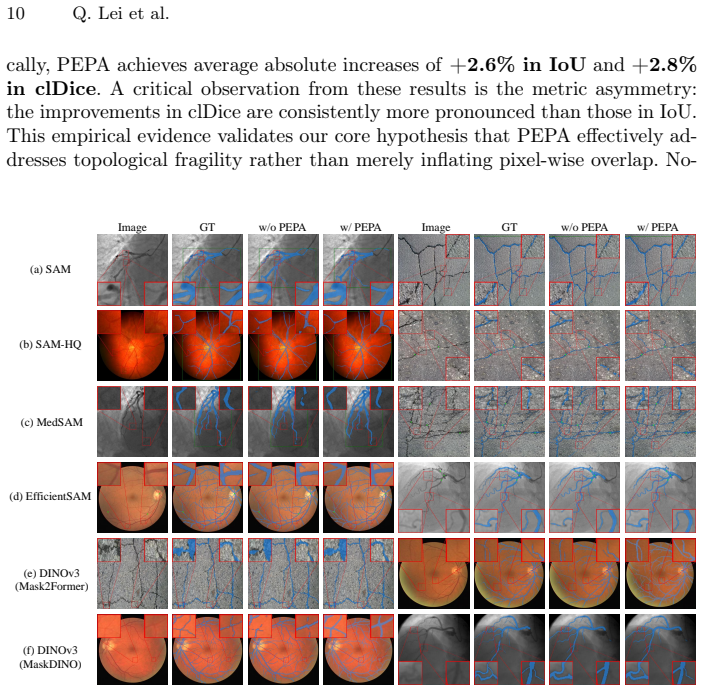
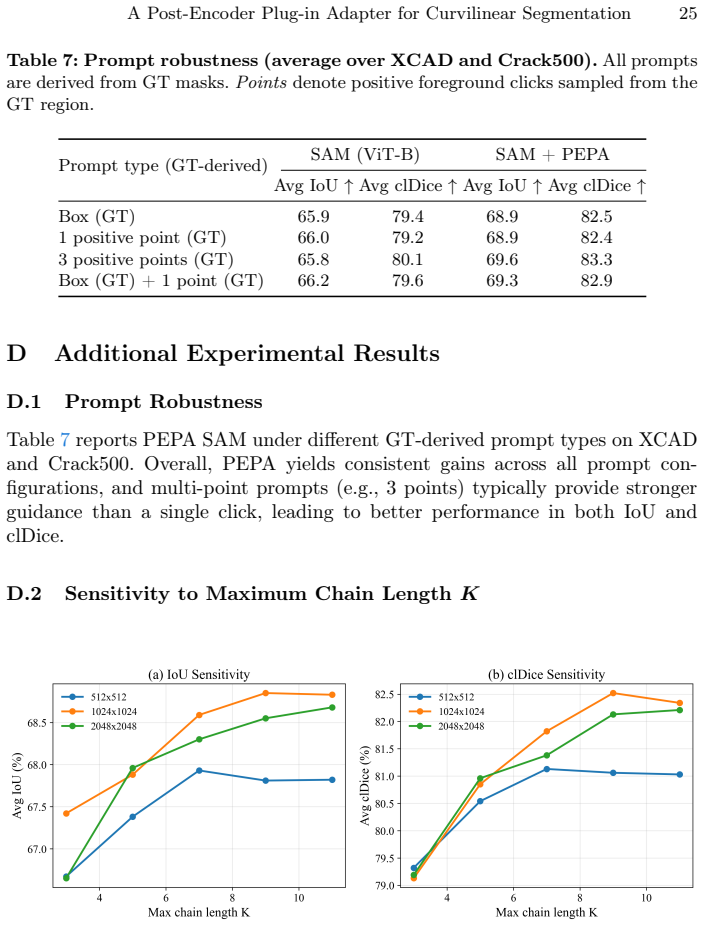
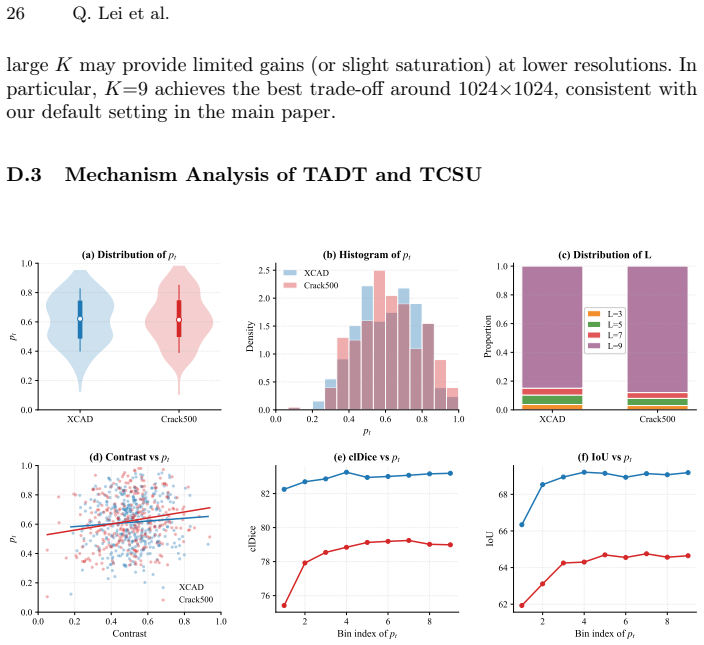
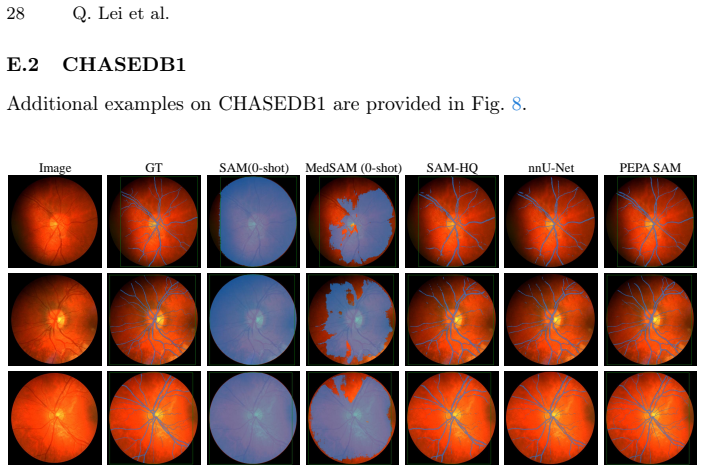
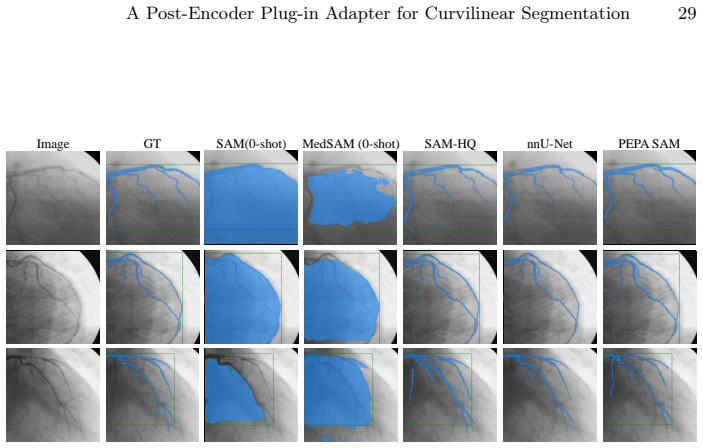
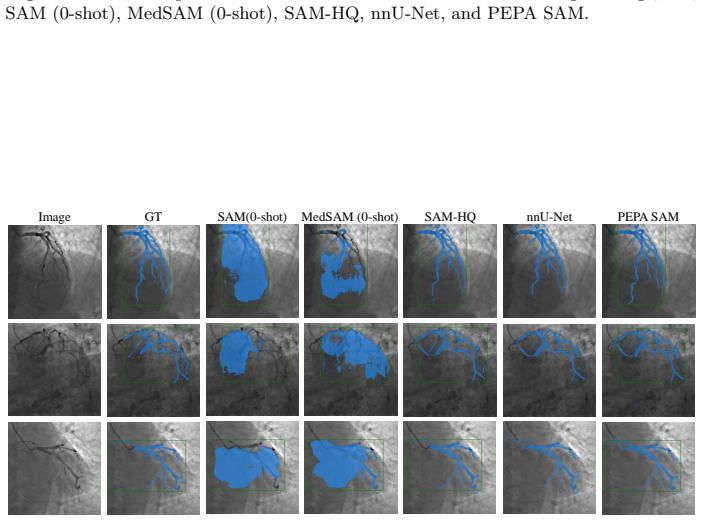
PEPA couples Target-Conditioned Snake Upsampling (TCSU), which uses target-conditioned continuous snake-like sampling to better recover thin and tortuous structures during upsampling, and Target-Adaptive Differentiable Thresholding (TADT), which predicts target-specific thresholds and optimizes a soft-threshold surrogate with explicit safeguards against trivial bias shifting. Under this post-encoder interface, PEPA can be attached to both prompt-based decoders and conventional dense predictors. Experiments on five medical and industrial benchmarks show that adding PEPA to frozen-encoder baselines yields consistent improvements, with gains in topological connectivity (clDice) typically exceed
What carries the argument
PEPA (Post-Encoder Plug-in Adapter) that combines TCSU for structure-aware upsampling and TADT for per-target threshold prediction, conditioned on decoder features and target or class descriptors.
If this is right
- Consistent improvements appear when PEPA is added to frozen-encoder baselines across five benchmarks.
- Gains in clDice connectivity typically exceed gains in IoU overlap, indicating better structural continuity.
- The adapter works with both prompt-based decoders and conventional dense predictors.
- Only approximately 0.26 million additional parameters are required.
- The design targets the reconstruction bottleneck in high-resolution feature recovery and the decision bottleneck in binarization.
Where Pith is reading between the lines
- PEPA could be tested on 3D volumes or other sparse-structure tasks where full encoder retraining is costly.
- The post-encoder conditioning pattern might apply to related problems such as road or filament extraction that also suffer from topological breaks.
- Similar lightweight modules could reduce reliance on end-to-end fine-tuning when strong encoders are already available.
Load-bearing premise
The post-encoder stage supplies accessible decoder or head features together with target, query, or class descriptors that the adapter modules can use directly for conditioning.
What would settle it
An experiment attaching PEPA to a frozen encoder on a curvilinear benchmark where clDice shows no gain or where connectivity gains fail to exceed IoU gains.
Figures


read the original abstract
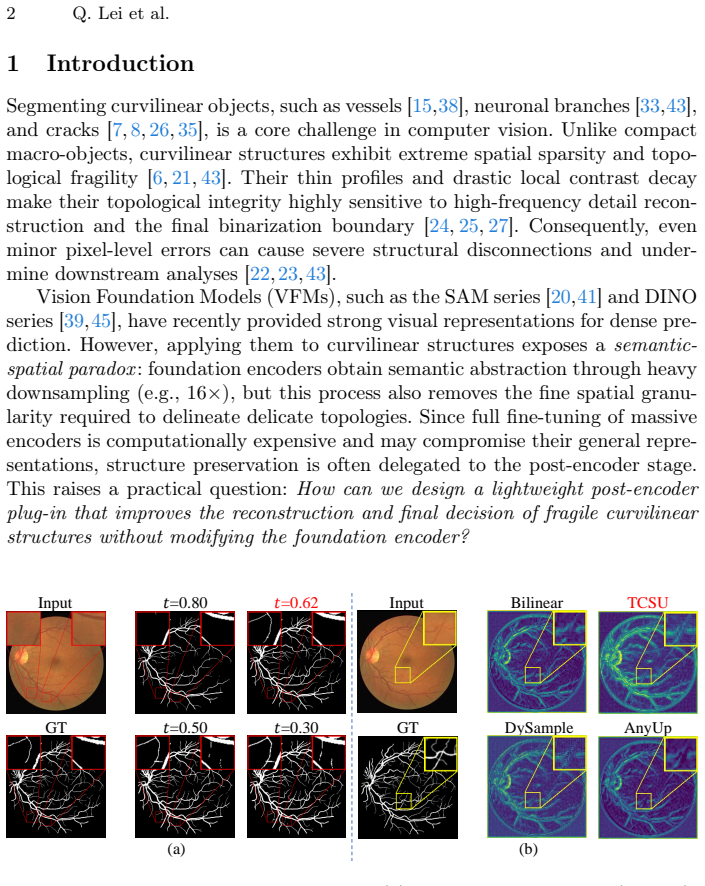
Curvilinear object segmentation, including vessels and cracks, is challenging due to extreme spatial sparsity and topological fragility, where small local errors can cause severe structural disconnections. Meanwhile, modern segmentation pipelines increasingly rely on strong but hard-to-modify foundation encoders whose heavy downsampling limits fine structural recovery. Motivated by this, we focus on the post-encoder stage and study two recurring and actionable failure modes: a reconstruction bottleneck in high-resolution feature restoration and a decision bottleneck in binarization. We present PEPA, a lightweight Post-Encoder Plug-in Adapter for 2D curvilinear segmentation pipelines with accessible decoder/head features and target, query, or class descriptors. PEPA couples (i) Target-Conditioned Snake Upsampling (TCSU), which uses target-conditioned continuous snake-like sampling to better recover thin and tortuous structures during upsampling, and (ii) Target-Adaptive Differentiable Thresholding (TADT), which predicts target-specific thresholds and optimizes a soft-threshold surrogate with explicit safeguards against trivial bias shifting. Under this post-encoder interface, PEPA can be attached to both prompt-based decoders and conventional dense predictors. Experiments on five medical and industrial benchmarks show that adding PEPA to frozen-encoder baselines yields consistent improvements, with gains in topological connectivity (clDice) typically exceeding those in region overlap (IoU), indicating improved structural continuity. With only $\sim$0.26M additional parameters, PEPA offers a practical post-encoder enhancement for structure-centric segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PEPA, a lightweight (~0.26M-parameter) post-encoder plug-in adapter for 2D curvilinear segmentation. It comprises Target-Conditioned Snake Upsampling (TCSU), which performs target-conditioned continuous snake-like sampling to recover thin structures during upsampling, and Target-Adaptive Differentiable Thresholding (TADT), which predicts target-specific thresholds and optimizes a soft-threshold surrogate. PEPA attaches to frozen-encoder pipelines (both prompt-based and conventional) at the post-encoder stage using accessible decoder/head features and descriptors. Experiments on five medical and industrial benchmarks report consistent gains, with clDice improvements typically exceeding those in IoU, indicating better structural continuity.
Significance. If the empirical deltas hold under scrutiny, the work supplies a practical, low-overhead enhancement for topological fidelity in sparse-structure segmentation without retraining heavy encoders. This is relevant for vessel, crack, and similar applications where connectivity matters more than region overlap, and the small parameter budget supports easy integration into existing pipelines.
major comments (2)
- [Experiments] Experiments section: the central claim of 'consistent improvements' on five benchmarks with clDice gains outpacing IoU rests on quantitative results. The manuscript must include full tables with per-dataset IoU/clDice values for baselines and PEPA variants, parameter counts, ablation breakdowns for TCSU vs. TADT, and any statistical tests; absence of these details prevents verification that gains are robust rather than implementation-dependent.
- [§3.1–3.2] §3.1–3.2: the definitions of the snake sampling in TCSU and the soft-threshold surrogate plus bias safeguards in TADT must be accompanied by explicit equations and pseudocode. Without them, reproducibility of the claimed remedies for the reconstruction and decision bottlenecks cannot be assessed.
minor comments (2)
- [Abstract, §1] Abstract and §1: the phrase 'accessible decoder/head features and target, query, or class descriptors' should be illustrated with a diagram or explicit list of tensor shapes for both prompt-based and dense-predictor cases.
- [§3] Notation: introduce a consistent symbol for the soft-threshold function and ensure all conditioning inputs (target descriptors) are denoted uniformly across TCSU and TADT descriptions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of 'consistent improvements' on five benchmarks with clDice gains outpacing IoU rests on quantitative results. The manuscript must include full tables with per-dataset IoU/clDice values for baselines and PEPA variants, parameter counts, ablation breakdowns for TCSU vs. TADT, and any statistical tests; absence of these details prevents verification that gains are robust rather than implementation-dependent.
Authors: We agree that the current presentation of results is insufficient for full verification. The revised manuscript will expand the Experiments section with complete per-dataset tables reporting IoU and clDice for all baselines and PEPA variants, explicit parameter counts, ablation studies isolating TCSU and TADT, and statistical significance tests (e.g., paired t-tests across runs) to substantiate the robustness of the observed gains. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2: the definitions of the snake sampling in TCSU and the soft-threshold surrogate plus bias safeguards in TADT must be accompanied by explicit equations and pseudocode. Without them, reproducibility of the claimed remedies for the reconstruction and decision bottlenecks cannot be assessed.
Authors: We accept that the manuscript lacks the necessary formal detail for reproducibility. In the revision we will insert explicit equations defining the target-conditioned continuous snake sampling procedure in TCSU and the soft-threshold surrogate with bias safeguards in TADT, together with corresponding pseudocode blocks in §3.1 and §3.2. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical architectural proposal: a lightweight post-encoder adapter (PEPA) with two modules (TCSU and TADT) that is attached to frozen encoders and evaluated on five benchmarks for gains in clDice and IoU. The abstract and description contain no equations, no claimed derivations from first principles, and no predictions that reduce to fitted inputs by construction. The design is explicitly conditioned on accessible post-encoder features and descriptors, with the central claim resting on reported experimental deltas rather than any self-referential definition, uniqueness theorem, or self-citation chain. This is a standard additive-module contribution whose validity is tested externally on held-out data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Applied Sciences9(24), 5507 (2019)
Cervantes-Sanchez, F., Cruz-Aceves, I., Hernandez-Aguirre, A., Hernandez- Gonzalez, M.A., Solorio-Meza, S.E.: Automatic segmentation of coronary arter- ies in x-ray angiograms using multiscale analysis and artificial neural networks. Applied Sciences9(24), 5507 (2019)
2019
-
[2]
arXiv preprint arXiv:2408.04579 (2024)
Chen, T., Lu, A., Zhu, L., Ding, C., Yu, C., Ji, D., Li, Z., Sun, L., Mao, P., Zang,Y.:Sam2-adapter:Evaluating&adaptingsegmentanything2indownstream tasks: Camouflage, shadow, medical image segmentation, and more. arXiv preprint arXiv:2408.04579 (2024)
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, T., Zhu, L., Deng, C., Cao, R., Wang, Y., Zhang, S., Li, Z., Sun, L., Zang, Y., Mao, P.: Sam-adapter: Adapting segment anything in underperformed scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3367–3375 (2023)
2023
-
[4]
Advances in Neural Information Processing Systems37, 30651–30669 (2024)
Chen, Z., Qin, H., Guo, Y., Su, X., Yuan, X., Kong, L., Zhang, Y.: Binarized diffu- sion model for image super-resolution. Advances in Neural Information Processing Systems37, 30651–30669 (2024)
2024
-
[5]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Zeng, Y., Chen, Z., Gao, H., Chen, L., Liu, J., Zhao, F.: Vfm-adapter: Adapting visual foundation models for dense prediction with dynamic hybrid oper- ation mapping. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2385–2393 (2025)
2025
-
[6]
IEEE Transactions on Industrial Informatics (2025)
Chen, Z., Hu, T., Xu, C., Chen, J., Song, H.H., Wang, L., Li, J.: Self-adaptive fourier augmentation framework for crack segmentation in industrial scenarios. IEEE Transactions on Industrial Informatics (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Lai, Z., Chen, J., Li, J.: Mind marginal non-crack regions: Clustering- inspired representation learning for crack segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12698– 12708 (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, Z., Zhang, J., Lai, Z., Zhu, G., Liu, Z., Chen, J., Li, J.: The devil is in the crack orientation: A new perspective for crack detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6653–6663 (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1290–1299 (2022)
2022
-
[10]
arXiv preprint arXiv:2506.11136 (2025)
Couairon, P., Chambon, L., Serrano, L., Haugeard, J.E., Cord, M., Thome, N.: Ja- far: Jack up any feature at any resolution. arXiv preprint arXiv:2506.11136 (2025)
-
[11]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Esmaeilzadeh, E., Garaaghaji, E., Hallaji Azad, F., Oner, D.: Cape: Connectivity- aware path enforcement loss for curvilinear structure delineation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 183–193. Springer (2025)
2025
-
[12]
IEEE transactions on biomedical engineering59(9), 2538–2548 (2012)
Fraz, M.M., Remagnino, P., Hoppe, A., Uyyanonvara, B., Rudnicka, A.R., Owen, C.G., Barman, S.A.: An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE transactions on biomedical engineering59(9), 2538–2548 (2012)
2012
-
[13]
arXiv preprint arXiv:2403.10516 (2024)
Fu, S., Hamilton, M., Brandt, L., Feldman, A., Zhang, Z., Freeman, W.T.: Fea- tup: A model-agnostic framework for features at any resolution. arXiv preprint arXiv:2403.10516 (2024)
-
[14]
arXiv preprint arXiv:2511.00981 (2025) 16 Q
Fu, S., Sun, R., Ding, X., Dong, J., Yang, Y., Zhu, Y., Ren, M.C.J., Deng, D., Aviles-Rivero, A., Cui, S., et al.: Vessam: Efficient multi-prompting for segmenting complex vessel. arXiv preprint arXiv:2511.00981 (2025) 16 Q. Lei et al
-
[15]
PloS one14(3), e0213539 (2019)
Haft-Javaherian, M., Fang, L., Muse, V., Schaffer, C.B., Nishimura, N., Sabuncu, M.R.: Deep convolutional neural networks for segmenting 3d in vivo multiphoton images of vasculature in alzheimer disease mouse models. PloS one14(3), e0213539 (2019)
2019
-
[16]
Medical Image Analysis102, 103496 (2025)
He, H., Banerjee, A., Choudhury, R.P., Grau, V.: Deep learning based coronary vessels segmentation in x-ray angiography using temporal information. Medical Image Analysis102, 103496 (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, H., Chen, A., Havrylov, V., Geiger, A., Zhang, D.: Loftup: Learning a coordinate-based feature upsampler for vision foundation models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9913–9923 (2025)
2025
-
[18]
Nature methods18(2), 203–211 (2021)
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods18(2), 203–211 (2021)
2021
-
[19]
Advances in Neural Information Processing Systems36, 29914–29934 (2023)
Ke, L., Ye, M., Danelljan, M., Tai, Y.W., Tang, C.K., Yu, F., et al.: Segment anything in high quality. Advances in Neural Information Processing Systems36, 29914–29934 (2023)
2023
-
[20]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[21]
Information Fusion p
Lei, Q., Wu, H., Zhong, J., Xiao, X., Wei, K., Sun, X., Bi, H., Mahmud, M.S.: En- hancing query-based segmentation models with full-pixel integration for curvilinear object segmentation. Information Fusion p. 103793 (2025)
2025
-
[22]
In: 2024 IEEE International Conference on Multimedia and Expo (ICME)
Lei, Q., Yang, R., Zhong, J., Li, R., He, M., Dong, M., Ota, K.: Expanding crack segmentation dataset with crack growth simulation and feature space diversity. In: 2024 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2024)
2024
-
[23]
In: European confer- ence on computer vision
Lei, Q., Zhong, J., Dai, Q.: Enriching information and preserving semantic consis- tency in expanding curvilinear object segmentation datasets. In: European confer- ence on computer vision. pp. 233–250. Springer (2024)
2024
-
[24]
IEEE Transactions on Intelligent Transporta- tion Systems25(7), 6902–6916 (2024)
Lei, Q., Zhong, J., Wang, C.: Joint optimization of crack segmentation with an adaptive dynamic threshold module. IEEE Transactions on Intelligent Transporta- tion Systems25(7), 6902–6916 (2024)
2024
-
[25]
In: 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
Lei, Q., Zhong, J., Wang, C., Dai, Q., Li, R.: Adaptive thresholding based on multi-task learning for refining binary medical image segmentation. In: 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). pp. 3059–
2023
-
[26]
Expert Systems with Applications240, 122552 (2024)
Lei, Q., Zhong, J., Wang, C., Li, X.: Integrating crack causal augmentation frame- work and dynamic binary threshold for imbalanced crack instance segmentation. Expert Systems with Applications240, 122552 (2024)
2024
-
[27]
In: Joint European conference on machine learning and knowledge discovery in databases
Lei, Q., Zhong, J., Wang, C., Xia, Y., Zhou, Y.: Dynamic thresholding for ac- curate crack segmentation using multi-objective optimization. In: Joint European conference on machine learning and knowledge discovery in databases. pp. 389–404. Springer (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, F., Zhang, H., Xu, H., Liu, S., Zhang, L., Ni, L.M., Shum, H.Y.: Mask dino: Towards a unified transformer-based framework for object detection and segmenta- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3041–3050 (2023)
2023
-
[29]
In: Proceedings of the AAAI conference on artificial intelligence
Liao, M., Wan, Z., Yao, C., Chen, K., Bai, X.: Real-time scene text detection with differentiable binarization. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp. 11474–11481 (2020) A Post-Encoder Plug-in Adapter for Curvilinear Segmentation 17
2020
-
[30]
IEEE transactions on pattern analysis and machine intelligence45(1), 919–931 (2022)
Liao, M., Zou, Z., Wan, Z., Yao, C., Bai, X.: Real-time scene text detection with differentiable binarization and adaptive scale fusion. IEEE transactions on pattern analysis and machine intelligence45(1), 919–931 (2022)
2022
-
[31]
In: International Conference on Information Processing in Medical Imaging
Lin, M., Zepf, K., Christensen, A.N., Bashir, Z., Svendsen, M.B.S., Tolsgaard, M., Feragen, A.: Dtu-net: Learning topological similarity for curvilinear structure segmentation. In: International Conference on Information Processing in Medical Imaging. pp. 654–666. Springer (2023)
2023
-
[32]
arXiv preprint arXiv:2502.00333 (2025)
Liu, K., Yang, K., Chen, Z., Li, Z., Guo, Y., Li, W., Kong, L., Zhang, Y.: Bimacosr: Binary one-step diffusion model leveraging flexible matrix compression for real super-resolution. arXiv preprint arXiv:2502.00333 (2025)
-
[33]
In: Neuronal Morphogenesis: Methods and Protocols, pp
Liu, M., Lin, Z., Chen, W., Meijering, E., Wang, Y.: Dneuromat: A deep-learning- based neuron morphology analysis toolbox. In: Neuronal Morphogenesis: Methods and Protocols, pp. 179–197. Springer (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, W., Lu, H., Fu, H., Cao, Z.: Learning to upsample by learning to sample. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6027–6037 (2023)
2023
-
[35]
Neurocomputing338, 139–153 (2019)
Liu, Y., Yao, J., Lu, X., Xie, R., Li, L.: Deepcrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing338, 139–153 (2019)
2019
-
[36]
Nature communications15(1), 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature communications15(1), 654 (2024)
2024
-
[37]
In: proceedings of the IEEE/CVF international conference on computer vision
Ma, Y., Hua, Y., Deng, H., Song, T., Wang, H., Xue, Z., Cao, H., Ma, R., Guan, H.: Self-supervised vessel segmentation via adversarial learning. In: proceedings of the IEEE/CVF international conference on computer vision. pp. 7536–7545 (2021)
2021
-
[38]
Medical image analysis67, 101874 (2021)
Mou, L., Zhao, Y., Fu, H., Liu, Y., Cheng, J., Zheng, Y., Su, P., Yang, J., Chen, L., Frangi, A.F., et al.: Cs2-net: Deep learning segmentation of curvilinear structures in medical imaging. Medical image analysis67, 101874 (2021)
2021
-
[39]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
In: Proceed- ings of the IEEE/CVF international conference on computer vision
Qi, Y., He, Y., Qi, X., Zhang, Y., Yang, G.: Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In: Proceed- ings of the IEEE/CVF international conference on computer vision. pp. 6070–6079 (2023)
2023
-
[41]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
arXiv preprint arXiv:2501.12860 (2025)
Shi, X., Jiang, Y., Jiang, X., Xu, M., Liu, Y.: Crossdiff: Diffusion probabilis- tic model with cross-conditional encoder-decoder for crack segmentation. arXiv preprint arXiv:2501.12860 (2025)
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shit, S., Paetzold, J.C., Sekuboyina, A., Ezhov, I., Unger, A., Zhylka, A., Pluim, J.P., Bauer, U., Menze, B.H.: cldice-a novel topology-preserving loss function for tubular structure segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16560–16569 (2021)
2021
-
[44]
arXiv preprint arXiv:2506.12460 (2025)
Shu, H.: Binarization-aware adjuster for discrete decision learning with an appli- cation to edge detection. arXiv preprint arXiv:2506.12460 (2025)
-
[45]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
IEEE transactions on medical imaging23(4), 501–509 (2004) 18 Q
Staal, J., Abràmoff, M.D., Niemeijer, M., Viergever, M.A., Van Ginneken, B.: Ridge-based vessel segmentation in color images of the retina. IEEE transactions on medical imaging23(4), 501–509 (2004) 18 Q. Lei et al
2004
-
[47]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, J., Chen, K., Xu, R., Liu, Z., Loy, C.C., Lin, D.: Carafe: Content-aware reassembly of features. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3007–3016 (2019)
2019
-
[48]
Entropy27(8), 862 (2025)
Wang, T., Tian, D., Zhao, H., Liu, J., Wang, W., Li, C., Liu, G.: Hierarchical multi-scale mamba with tubular structure-aware convolution for retinal vessel seg- mentation. Entropy27(8), 862 (2025)
2025
-
[49]
arXiv preprint arXiv:2409.11508 (2024)
Wei, X., Lin, X., Liu, H., Zhao, S., Li, Y.: Retinal vessel segmentation with deep graph and capsule reasoning. arXiv preprint arXiv:2409.11508 (2024)
-
[50]
arXiv preprint arXiv:2510.12764 (2025)
Wimmer, T., Truong, P., Rakotosaona, M.J., Oechsle, M., Tombari, F., Schiele, B., Lenssen, J.E.: Anyup: Universal feature upsampling. arXiv preprint arXiv:2510.12764 (2025)
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiong, Y., Varadarajan, B., Wu, L., Xiang, X., Xiao, F., Zhu, C., Dai, X., Wang, D., Sun, F., Iandola, F., et al.: Efficientsam: Leveraged masked image pretraining for efficient segment anything. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16111–16121 (2024)
2024
-
[52]
IEEE transactions on intelligent transportation systems21(4), 1525–1535 (2019)
Yang, F., Zhang, L., Yu, S., Prokhorov, D., Mei, X., Ling, H.: Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE transactions on intelligent transportation systems21(4), 1525–1535 (2019)
2019
-
[53]
Engineering Applications of Artificial Intelligence150, 110536 (2025)
Zhang, J., Li, D., Zeng, Z., Zhang, R., Wang, J.: Dual-branch crack segmenta- tion network with multi-shape kernel based on convolutional neural network and mamba. Engineering Applications of Artificial Intelligence150, 110536 (2025)
2025
-
[54]
Information Fusion115, 102777 (2025)
Zhao, D., Liu, J., Geng, P., Yang, J., Zhang, Z., Zhang, Y.: Mid-net: Rethinking efficient network architectures for small-sample vascular segmentation. Information Fusion115, 102777 (2025)
2025
-
[55]
Zhu, K., Chen, L., Li, D., Cao, Y., Cheng, J.: Ucs: A universal model for curvilinear structure segmentation. arXiv preprint arXiv:2504.04034 (2025) A Post-Encoder Plug-in Adapter for Curvilinear Segmentation 19 Supplementary Material Overview This supplementary material provides additional technical details, experimental protocols, and extended results t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.