Weight Adaptation for Improving Parallel Performance of Adaptive Stochastic Natural Gradient
Pith reviewed 2026-06-26 15:25 UTC · model grok-4.3
The pith
WA-ASNG adapts weights by maximizing estimated signal from natural gradient accumulations to improve binary optimization over ASNG and PBIL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
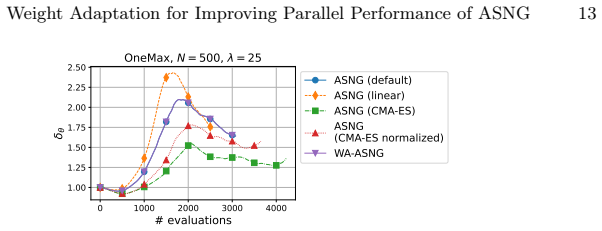
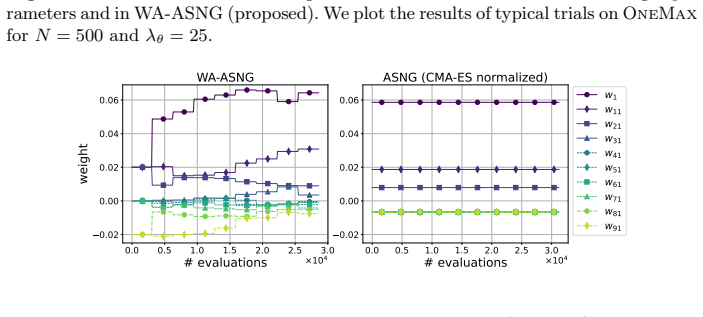
WA-ASNG calculates the estimated signal of the update direction from the accumulations of the natural gradient. Then, to maximize the signal, WA-ASNG adaptively updates its weight parameters by a gradient ascent over the optimization. While the learning rate adaptation plays a role in satisfying a sufficient condition for monotonic improvement of the expected objective value, the mechanism of weight adaptation is intended to maximize this improvement.
What carries the argument
Weight adaptation mechanism that performs gradient ascent on the estimated signal computed from accumulated natural gradients.
If this is right
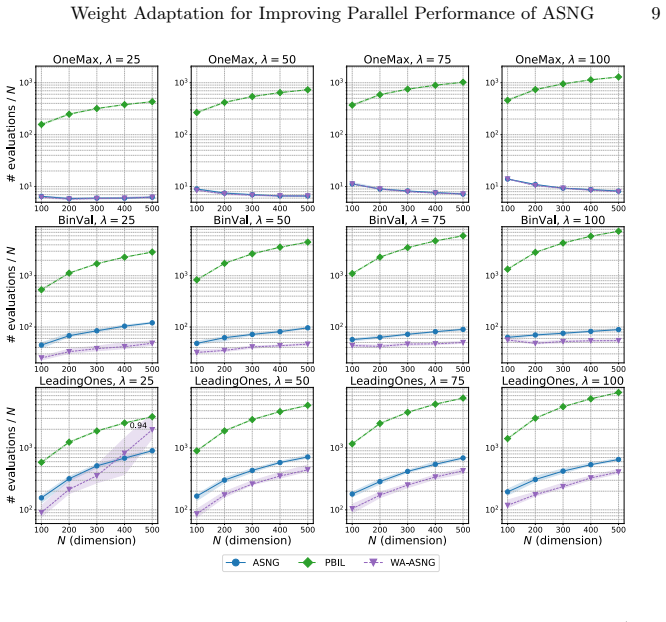
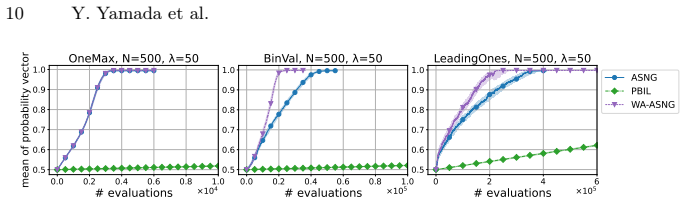
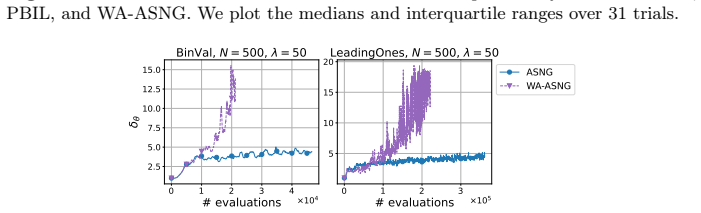
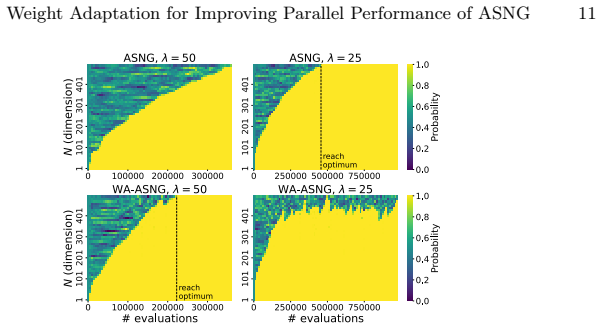
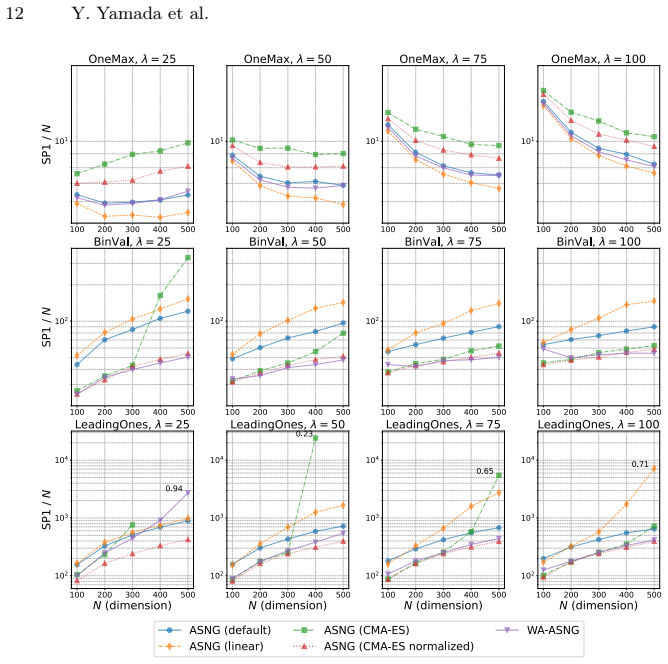
- WA-ASNG outperforms PBIL and ASNG across population sizes 25 to 100 on binary optimization problems.
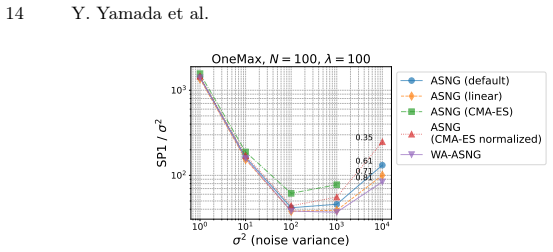
- WA-ASNG performs efficiently in the presence of strong noise.
- Weight adaptation maximizes the improvement that learning rate adaptation already guarantees to be monotonic.
- The method addresses the need for suitable weights when using larger populations for parallel evaluation of time-consuming tasks.
Where Pith is reading between the lines
- The signal-maximization idea could be tested as a general addition to other probabilistic model-based evolutionary algorithms.
- Weight adaptation may reduce manual tuning effort when scaling population size for parallel black-box optimization.
- The same estimated-signal approach might be examined for continuous rather than binary search spaces.
Load-bearing premise
The estimated signal computed from accumulations of the natural gradient is a reliable proxy that weight updates can maximize to produce genuine improvement rather than amplifying noise or bias.
What would settle it
An experiment showing that WA-ASNG with weight adaptation produces equal or worse results than fixed-weight ASNG on the same binary problems with population sizes 25-100 would falsify the claimed benefit.
Figures
read the original abstract
Probabilistic model-based evolutionary algorithms are promising for black-box optimization. Specifically, the adaptive stochastic natural gradient (ASNG) adaptively updates its learning rate, a typical hyperparameter in probabilistic model-based evolutionary algorithms, thereby realizing efficient and robust optimization. Although weight parameters are common hyperparameters, with the increasing demand for parallel evaluation of time-consuming tasks, it remains unclear how to set suitable weights for larger population sizes. In this paper, we propose Weight Adaptation ASNG (WA-ASNG), which incorporates a weight adaptation mechanism into ASNG. We calculated the estimated signal of the update direction from the accumulations of the natural gradient. Then, to maximize the signal, WA-ASNG adaptively updates its weight parameters by a gradient ascent over the optimization. While the learning rate adaptation plays a role in satisfying a sufficient condition for monotonic improvement of the expected objective value, the mechanism of weight adaptation is intended to maximize this improvement. The experimental results demonstrate that WA-ASNG outperforms PBIL and ASNG across various settings with population sizes ranging from 25 to 100 for binary optimization problems. Furthermore, WA-ASNG can perform efficiently in the presence of strong noise. Our code is available at https://github.com/shiralab/WA-ASNG .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Weight Adaptation ASNG (WA-ASNG) as an extension of adaptive stochastic natural gradient (ASNG) for probabilistic model-based evolutionary algorithms. It adds a weight adaptation mechanism that computes an estimated signal from accumulations of the natural gradient and performs gradient ascent on the weight parameters to maximize this signal. The authors state that learning-rate adaptation satisfies a sufficient condition for monotonic improvement of the expected objective value, while weight adaptation is intended to maximize this improvement. Experiments claim that WA-ASNG outperforms PBIL and ASNG on binary optimization problems for population sizes 25-100 and remains efficient under strong noise. The code is made available at a public GitHub repository.
Significance. If the weight adaptation mechanism is shown to produce reliable gains beyond the learning-rate adaptation and the reported performance improvements hold under scrutiny, the work could aid parallel scalability of evolutionary algorithms on noisy black-box problems. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that weight adaptation 'maximizes this improvement' lacks any derivation, bound, or monotonicity argument showing that gradient ascent on the estimated signal from natural-gradient accumulations necessarily increases the true expected objective improvement (in contrast to the sufficient condition stated for learning-rate adaptation). This is load-bearing for the central claim that WA-ASNG outperforms ASNG.
- [Abstract] Abstract: the performance claim that WA-ASNG 'outperforms PBIL and ASNG across various settings' with population sizes 25-100 is presented without reference to statistical tests, error bars, number of runs, or specific benchmark instances, making it impossible to assess whether the reported gains are robust or could be explained by noise amplification in the weight-update proxy.
minor comments (1)
- The abstract refers to 'various settings' and 'strong noise' without naming the concrete binary problems or noise models used; adding these details would improve clarity even if they appear later in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we respond point-by-point to the major comments and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that weight adaptation 'maximizes this improvement' lacks any derivation, bound, or monotonicity argument showing that gradient ascent on the estimated signal from natural-gradient accumulations necessarily increases the true expected objective improvement (in contrast to the sufficient condition stated for learning-rate adaptation). This is load-bearing for the central claim that WA-ASNG outperforms ASNG.
Authors: We agree that the abstract phrasing requires clarification. The manuscript states that learning-rate adaptation satisfies a sufficient condition for monotonic improvement of the expected objective value, while weight adaptation is described as intended to maximize the estimated update signal obtained from natural-gradient accumulations. No formal derivation, bound, or monotonicity guarantee is provided for the weight-adaptation step with respect to the true objective (it remains a heuristic based on the proxy signal). We will revise the abstract to explicitly distinguish the two mechanisms, replacing any implication of guaranteed maximization with the wording 'intended to maximize the estimated signal' and noting that performance gains are supported empirically rather than by a theoretical guarantee equivalent to that for the learning rate. revision: yes
-
Referee: [Abstract] Abstract: the performance claim that WA-ASNG 'outperforms PBIL and ASNG across various settings' with population sizes 25-100 is presented without reference to statistical tests, error bars, number of runs, or specific benchmark instances, making it impossible to assess whether the reported gains are robust or could be explained by noise amplification in the weight-update proxy.
Authors: The abstract is a concise summary; the full manuscript reports experiments on binary optimization problems with population sizes 25-100, using multiple independent runs, error bars on performance plots, and direct comparisons against PBIL and ASNG, including under noise. To make the abstract self-contained and address the concern, we will add a short clause referencing the experimental protocol (e.g., 'based on 10 independent runs with error bars and consistent outperformance across standard binary benchmarks'). This will allow readers to evaluate robustness without altering the reported outcomes. revision: yes
Circularity Check
No significant circularity; weight adaptation is a heuristic justified by experiments
full rationale
The paper describes WA-ASNG as computing an estimated signal from natural-gradient accumulations and performing gradient ascent on weights to maximize that signal, while noting that learning-rate adaptation satisfies a monotonicity condition but weight adaptation is only 'intended to maximize this improvement.' No equations are supplied that reduce the claimed performance gain to a fitted quantity by construction, nor does any step equate a prediction to its own inputs. The central claim of outperformance rests on experimental comparisons with PBIL and ASNG across population sizes and noise levels rather than on a self-referential derivation. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. This is the normal case of an empirical algorithmic proposal whose justification is external to the method definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Theoretical Computer Science832, 42–67 (2020)
Akimoto, Y., Auger, A., Hansen, N.: Quality gain analysis of the weighted re- combination evolution strategy on general convex quadratic functions. Theoretical Computer Science832, 42–67 (2020). https://doi.org/10.1016/j.tcs.2018.05.015
-
[2]
In: International Conference on Machine Learning (ICML)
Akimoto, Y., Shirakawa, S., Yoshinari, N., Uchida, K., Saito, S., Nishida, K.: Adap- tive stochastic natural gradient method for one-shot neural architecture search. In: International Conference on Machine Learning (ICML). pp. 171–180 (2019)
2019
-
[3]
In: 8th International Workshop on Foundations of Genetic Algorithms (FOGA) 2005
Arnold, D.V.: Optimal weighted recombination. In: 8th International Workshop on Foundations of Genetic Algorithms (FOGA) 2005. pp. 215–237. Springer (2005). https://doi.org/10.1007/11513575_12
-
[4]
In: Machine Learning Proceedings 1995, pp
Baluja, S., Caruana, R.: Removing the genetics from the standard genetic algo- rithm. In: Machine Learning Proceedings 1995, pp. 38–46. Morgan Kaufmann, San Francisco (CA) (1995). https://doi.org/10.1016/B978-1-55860-377-6.50014-1
-
[5]
Algorithmica81(2), 668–702 (Feb 2019)
Dang, D.C., Lehre, P.K., Nguyen, P.T.: Level-based analysis of the univari- ate marginal distribution algorithm. Algorithmica81(2), 668–702 (Feb 2019). https://doi.org/10.1007/s00453-018-0507-5, https://doi.org/10.1007/s00453-018- 0507-5
-
[6]
Evans, M., Swartz, T.: Approximating Integrals via Monte Carlo and Deterministic Methods. Oxford University Press (2000). https://doi.org/10.1093/oso/9780198502784.001.0001
-
[7]
Exponential Natural Evolution Strategies,
Glasmachers, T., Schaul, T., Yi, S., Wierstra, D., Schmidhuber, J.: Exponential natural evolution strategies. In: Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation. pp. 393–400. Association for Computing Machinery, New York, NY, USA (2010). https://doi.org/10.1145/1830483.1830557
-
[8]
Computers & Chemical Engineering170, 108110 (2023)
González, L.D., Zavala, V.M.: New paradigms for exploiting parallel experiments in bayesian optimization. Computers & Chemical Engineering170, 108110 (2023). https://doi.org/10.1016/j.compchemeng.2022.108110
-
[9]
In: Proceedings of IEEE International Conference on Evolutionary Computation
Hansen, N., Ostermeier, A.: Adapting arbitrary normal mutation distributions in evolution strategies: the covariance matrix adaptation. In: Proceedings of IEEE International Conference on Evolutionary Computation. pp. 312–317 (1996). https://doi.org/10.1109/ICEC.1996.542381
-
[10]
Hansen, N., Auger, A.: Principled Design of Continuous Stochastic Search: From Theory to Practice, pp. 145–180. Springer Berlin Heidelberg, Berlin, Heidelberg (2014). https://doi.org/10.1007/978-3-642-33206-7_8
-
[11]
IEEE Transactions on Evolutionary Computation3, 287–297 (1999)
Harik, G.R., Lobo, F.G., Goldberg, D.E.: The compact genetic algo- rithm. IEEE Transactions on Evolutionary Computation3, 287–297 (1999). https://doi.org/10.1109/4235.797971
-
[12]
In: 2006 IEEE International Conference on Evolutionary Computation
Jastrebski, G., Arnold, D.: Improving evolution strategies through active covari- ance matrix adaptation. In: 2006 IEEE International Conference on Evolutionary Computation. pp. 2814–2821 (2006). https://doi.org/10.1109/CEC.2006.1688662
-
[13]
Algorithmica83(4), 1096–1137 (2021)
Lengler, J., Sudholt, D., Witt, C.: The complex parameter landscape of the compact genetic algorithm. Algorithmica83(4), 1096–1137 (2021). https://doi.org/10.1007/s00453-020-00778-4
-
[14]
Nishida, K., Akimoto, Y.: PSA-CMA-ES: CMA-ES with population size adaptation. In: Proceedings of the Genetic and Evolutionary Computa- tion Conference. pp. 865–872. Association for Computing Machinery (2018). https://doi.org/10.1145/3205455.3205467 16 Y. Yamada et al
-
[15]
ACM Transactions on Evolutionary Learning and Optimization (2024)
Nomura, M., Akimoto, Y., Ono, I.: CMA-ES with learning rate adapta- tion. ACM Transactions on Evolutionary Learning and Optimization (2024). https://doi.org/10.1145/3698203
-
[16]
Journal of Machine Learning Research18(1), 564–628 (2017)
Ollivier, Y., Arnold, L., Auger, A., Hansen, N.: Information-geometric optimiza- tion algorithms: A unifying picture via invariance principles. Journal of Machine Learning Research18(1), 564–628 (2017)
2017
-
[17]
Salimans, T., Ho, J., Chen, X., Sidor, S., Sutskever, I.: Evolution strategies as a scalable alternative to reinforcement learning (2017), https://arxiv.org/abs/1703.03864
Pith/arXiv arXiv 2017
-
[18]
In: Bäck, T., Preuss, M., Deutz, A., Wang, H., Doerr, C., Emmerich, M., Trautmann, H
Yamaguchi, T., Uchida, K., Shirakawa, S.: Adaptive stochastic natural gradient method for optimizing functions with low effective dimensionality. In: Bäck, T., Preuss, M., Deutz, A., Wang, H., Doerr, C., Emmerich, M., Trautmann, H. (eds.) Parallel Problem Solving from Nature – PPSN XVI. pp. 719–731. Springer Inter- national Publishing, Cham (2020)
2020
-
[19]
In: 2009 IEEE Congress on Evolutionary Computation
Yang, S., Richter, H.: Hyper-learning for population-based incremental learning in dynamic environments. In: 2009 IEEE Congress on Evolutionary Computation. pp. 682–689 (2009). https://doi.org/10.1109/CEC.2009.4983011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.