MCompassRAG: Topic Metadata as a Semantic Compass for Paragraph-Level Retrieval
Pith reviewed 2026-06-27 00:11 UTC · model grok-4.3
The pith
Topic metadata enriches chunk embeddings to guide paragraph retrieval without extra LLM calls at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
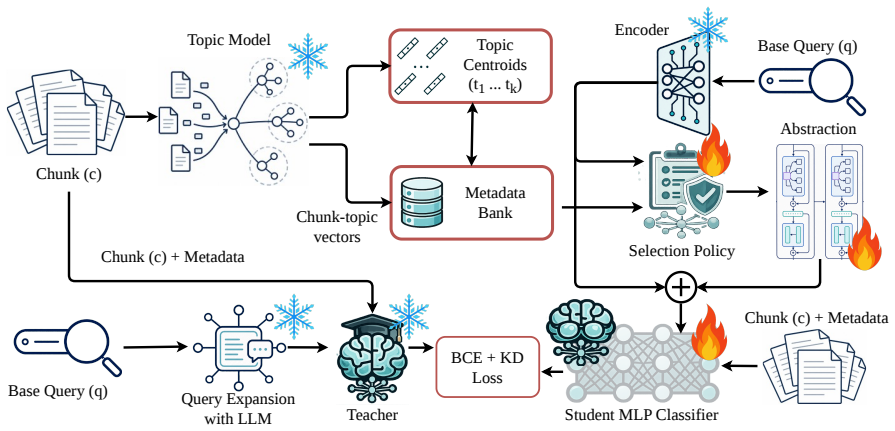
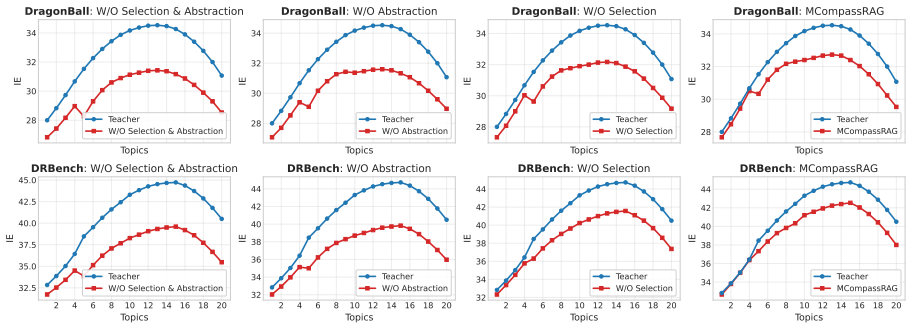
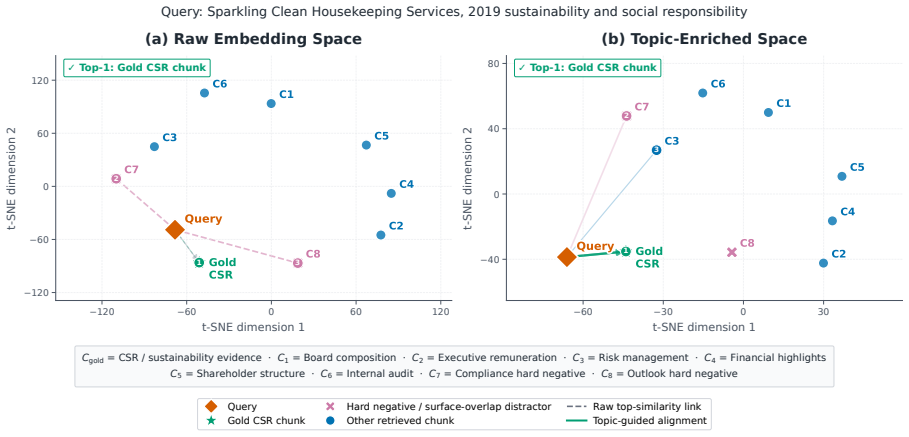
MCompassRAG enriches chunk representations with topic metadata inside the identical embedding space and trains a lightweight retriever through LLM-teacher distillation; at inference the resulting model performs topic-aware retrieval without additional LLM calls, delivering an 8.24 percent average rise in information efficiency and over five times lower latency than the strongest efficient RAG baselines on six complex retrieval benchmarks.
What carries the argument
topic metadata enriched chunk embeddings distilled into a lightweight retriever that acts as a semantic compass for topic-aware selection
If this is right
- Fine-grained paragraph chunks become usable without expanding search-space latency.
- Retrieval remains reliable even when documents contain heterogeneous topics.
- Evidence quality improves while total inference cost stays low.
- Deep research tasks gain both speed and precision from the same system.
- No additional LLM calls are required once the distilled retriever is trained.
Where Pith is reading between the lines
- The same enrichment-plus-distillation pattern could be tested with other metadata signals such as entity types or temporal markers.
- If the distilled retriever generalizes, chunking heuristics that currently dominate RAG pipelines may become less critical.
- The method opens a route to hybrid systems that combine topic guidance with reranking stages without compounding latency.
- Deployment in production RAG stacks would require checking whether topic metadata extraction itself remains stable across domains.
Load-bearing premise
Enriching chunk embeddings with topic metadata in the same space and distilling a lightweight retriever from an LLM teacher yields reliable topic-aware retrieval at inference without extra LLM calls or loss of evidence quality.
What would settle it
A held-out retrieval benchmark on which MCompassRAG fails to raise information efficiency above the strongest efficient baseline or loses the reported latency advantage.
Figures
read the original abstract
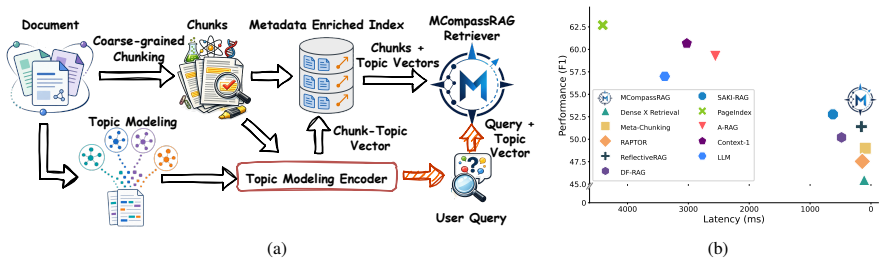
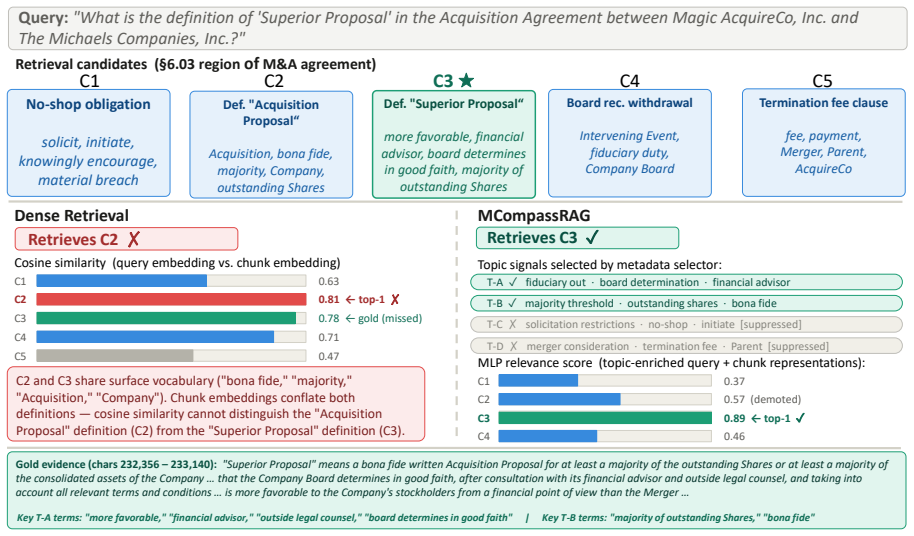
Retrieval-augmented generation (RAG) systems depend critically on how documents are chunked and searched. Fine-grained chunks can improve retrieval precision but expand the search space, increasing latency and cost; larger chunks reduce the number of candidates but make dense similarity less reliable, as the representation for each chunk mixes multiple topics and introduces more semantic noise. This trade-off becomes especially limiting in deep research tasks, where retrieval must be both fast and precise across large, heterogeneous corpora. We introduce MCompassRAG, a metadata-guided retrieval framework that uses topic-level signals as a semantic compass for selecting relevant evidence. Instead of relying only on cosine similarity between queries and noisy chunk embeddings, MCompassRAG enriches chunk representations with topic metadata in the same embedding space and trains a lightweight retriever through LLM-teacher distillation. At inference time, MCompassRAG performs topic-aware retrieval without additional LLM calls, improving both efficiency and evidence quality. Across six complex retrieval benchmarks, MCompassRAG improves information efficiency (IE) by 8.24% on average with over 5 times lower latency than the strongest efficient RAG baselines. Code is available on https://github.com/AmirAbaskohi/MCompassRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MCompassRAG, a metadata-guided retrieval framework for RAG that enriches chunk embeddings with topic metadata in the same embedding space and trains a lightweight retriever via LLM-teacher distillation to enable topic-aware retrieval at inference without extra LLM calls. It claims an average 8.24% improvement in information efficiency (IE) across six complex retrieval benchmarks together with over 5 imes lower latency than the strongest efficient RAG baselines.
Significance. If the headline efficiency and latency claims are substantiated, the work would offer a concrete mechanism for mitigating the chunk-size trade-off in paragraph-level retrieval by injecting topic-level signals, which could be useful for latency-sensitive research-oriented RAG pipelines. The public code release is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the central 8.24% IE gain and 5 imes latency claim cannot be evaluated because the abstract (and the provided manuscript excerpt) supplies neither the definition of information efficiency, the identities of the six benchmarks, the precise baseline configurations, nor any statistical significance tests; without these the reported improvement cannot be confirmed to arise from the topic-metadata mechanism rather than model-size or implementation differences.
- [Method] Method description: the claim that topic metadata is injected 'in the same embedding space' and transferred via distillation requires an ablation that isolates the topic-metadata contribution from generic dense retrieval and from the distillation itself; the absence of such an ablation, together with missing teacher-student agreement metrics on retrieved chunks and downstream evidence-quality checks, leaves the load-bearing assumption that the student actually learns the injected topic compass unverified.
minor comments (1)
- [Abstract] The abstract refers to 'six complex retrieval benchmarks' without naming them; an explicit list would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and method validation. We respond to each major point below, clarifying details from the full manuscript and indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 8.24% IE gain and 5 times latency claim cannot be evaluated because the abstract (and the provided manuscript excerpt) supplies neither the definition of information efficiency, the identities of the six benchmarks, the precise baseline configurations, nor any statistical significance tests; without these the reported improvement cannot be confirmed to arise from the topic-metadata mechanism rather than model-size or implementation differences.
Authors: We agree the abstract is space-constrained and omits these details. The full manuscript defines information efficiency in Section 3.2, identifies the six benchmarks (with descriptions) in Section 4.1, specifies baseline configurations in Section 4.2, and reports statistical significance tests in the results tables of Section 5. We will revise the abstract to include a concise definition of IE and name the benchmarks for improved evaluability. revision: partial
-
Referee: [Method] Method description: the claim that topic metadata is injected 'in the same embedding space' and transferred via distillation requires an ablation that isolates the topic-metadata contribution from generic dense retrieval and from the distillation itself; the absence of such an ablation, together with missing teacher-student agreement metrics on retrieved chunks and downstream evidence-quality checks, leaves the load-bearing assumption that the student actually learns the injected topic compass unverified.
Authors: The manuscript includes baseline comparisons to dense retrieval and distillation variants in Section 5.3, but we acknowledge the need for more targeted isolation of the topic-metadata effect. We will add a dedicated ablation study in the revision to separate topic metadata from generic dense retrieval and distillation. We will also incorporate teacher-student agreement metrics on retrieved chunks and downstream evidence-quality checks to verify the topic compass transfer. revision: yes
Circularity Check
No circularity; empirical benchmark gains independent of method description
full rationale
The provided abstract and method description contain no equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations. The core claims rest on measured improvements (8.24% IE, 5x latency) across external benchmarks after describing a distillation procedure; these outcomes are not shown to reduce by construction to the inputs via any of the enumerated circularity patterns. The derivation chain is therefore self-contained as an empirical engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tao, Wenyu and Xing, Xiaofen and Li, Zeliang and Xu, Xiangmin. SAKI - RAG : Mitigating Context Fragmentation in Long-Document RAG via Sentence-level Attention Knowledge Integration. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.63
-
[2]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[3]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[4]
Izacard, Gautier and Grave, Edouard. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.74
-
[5]
Chen, Tong and Wang, Hongwei and Chen, Sihao and Yu, Wenhao and Ma, Kaixin and Zhao, Xinran and Zhang, Hongming and Yu, Dong. Dense X Retrieval: What Retrieval Granularity Should We Use?. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.845
-
[6]
2025 , eprint=
Meta-Chunking: Learning Text Segmentation and Semantic Completion via Logical Perception , author=. 2025 , eprint=
2025
-
[7]
2024 , url=
Parth Sarthi and Salman Abdullah and Aditi Tuli and Shubh Khanna and Anna Goldie and Christopher D Manning , booktitle=. 2024 , url=
2024
-
[8]
Precise Zero-Shot Dense Retrieval without Relevance Labels , booktitle =
Gao, Luyu and Ma, Xueguang and Lin, Jimmy and Callan, Jamie. Precise Zero-Shot Dense Retrieval without Relevance Labels. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.99
-
[9]
Query2doc: Query Expansion with Large Language Models
Wang, Liang and Yang, Nan and Wei, Furu. Query2doc: Query Expansion with Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.585
-
[10]
H y QE : Ranking Contexts with Hypothetical Query Embeddings
Zhou, Weichao and Zhang, Jiaxin and Hasson, Hilaf and Singh, Anu and Li, Wenchao. H y QE : Ranking Contexts with Hypothetical Query Embeddings. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.761
-
[11]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.557
-
[12]
The Twelfth International Conference on Learning Representations , year=
Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[13]
Zhao, Jihao and Ji, Zhiyuan and Fan, Zhaoxin and Wang, Hanyu and Niu, Simin and Tang, Bo and Xiong, Feiyu and Li, Zhiyu. M o C : Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.258
-
[14]
R eflective RAG : Rethinking Adaptivity in Retrieval-Augmented Generation
Verma, Akshay and Gupta, Swapnil and Pillai, Siddharth and Sircar, Prateek and Gupta, Deepak. R eflective RAG : Rethinking Adaptivity in Retrieval-Augmented Generation. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 5: Industry Track). 2026. doi:10.18653/v1/2026.eacl-industry.27
-
[15]
Khan, Saadat Hasan and Hong, Spencer and Wu, Jingyu and Lybarger, Kevin and Yin, Youbing and Babinsky, Erin and Liu, Daben. DF - RAG : Query-Aware Diversity for Retrieval-Augmented Generation. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.150
-
[16]
International Symposium on Information and Communication Technology , pages=
Enhancing retrieval augmented generation with hierarchical text segmentation chunking , author=. International Symposium on Information and Communication Technology , pages=. 2024 , organization=
2024
-
[17]
International Workshop on Knowledge-Enhanced Information Retrieval , pages=
Reconstructing context: Evaluating advanced chunking strategies for retrieval-augmented generation , author=. International Workshop on Knowledge-Enhanced Information Retrieval , pages=. 2025 , organization=
2025
-
[18]
2024 , month = may, day =
Introducing. 2024 , month = may, day =
2024
-
[19]
2025 , eprint=
REFRAG: Rethinking RAG based Decoding , author=. 2025 , eprint=
2025
-
[20]
The Fourteenth International Conference on Learning Representations , year=
Maxime Louis and Thibault Formal and Herv. The Fourteenth International Conference on Learning Representations , year=
-
[21]
SmartChunk Retrieval: Query-Aware Chunk Compression with Planning for Efficient Document
Xuechen Zhang and Koustava Goswami and Samet Oymak and Jiasi Chen and Nedim Lipka , booktitle=. SmartChunk Retrieval: Query-Aware Chunk Compression with Planning for Efficient Document. 2026 , url=
2026
-
[22]
CEMTM : Contextual Embedding-based Multimodal Topic Modeling
Abaskohi, Amirhossein and Li, Raymond and Li, Chuyuan and Joty, Shafiq and Carenini, Giuseppe. CEMTM : Contextual Embedding-based Multimodal Topic Modeling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.590
-
[23]
arXiv preprint arXiv:2506.18096 , year=
Deep research agents: A systematic examination and roadmap , author=. arXiv preprint arXiv:2506.18096 , year=
-
[24]
Sparse Local Embeddings for Extreme Multi-label Classification , url =
Bhatia, Kush and Jain, Himanshu and Kar, Purushottam and Varma, Manik and Jain, Prateek , booktitle =. Sparse Local Embeddings for Extreme Multi-label Classification , url =
-
[25]
2025 , eprint=
Deep Research: A Survey of Autonomous Research Agents , author=. 2025 , eprint=
2025
-
[26]
Zhao, Wayne Xin and Liu, Jing and Ren, Ruiyang and Wen, Ji-Rong , title =. ACM Trans. Inf. Syst. , month = feb, articleno =. 2024 , issue_date =. doi:10.1145/3637870 , abstract =
-
[27]
2025 , url=
Suchith Chidananda Prabhu and Bhavyajeet Singh and Anshul Mittal and Siddarth Asokan and Shikhar Mohan and Deepak Saini and Yashoteja Prabhu and Lakshya Kumar and Jian Jiao and Amit S and Niket Tandon and Manish Gupta and Sumeet Agarwal and Manik Varma , booktitle=. 2025 , url=
2025
-
[28]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[30]
The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding , author=. The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2023
-
[31]
The Fourteenth International Conference on Learning Representations , year=
Amirhossein Abaskohi and Tianyi Chen and Miguel Mu. The Fourteenth International Conference on Learning Representations , year=
-
[32]
L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi. L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. Proceedings of the 63rd Annual Meeting of the Association for Computational...
-
[33]
2025 , eprint=
Enterprise Deep Research: Steerable Multi-Agent Deep Research for Enterprise Analytics , author=. 2025 , eprint=
2025
-
[34]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi. L ong B ench: A Bilingual, Multitask Benchmark for Long Context Understanding. Proceedings of the 62nd Annual Meeting of the Association for Computation...
-
[35]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[36]
Cohan, Arman and Feldman, Sergey and Beltagy, Iz and Downey, Doug and Weld, Daniel. SPECTER : Document-level Representation Learning using Citation-informed Transformers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.207
-
[37]
2024 , eprint=
LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain , author=. 2024 , eprint=
2024
-
[38]
RAGE val: Scenario Specific RAG Evaluation Dataset Generation Framework
Zhu, Kunlun and Luo, Yifan and Xu, Dingling and Yan, Yukun and Liu, Zhenghao and Yu, Shi and Wang, Ruobing and Wang, Shuo and Li, Yishan and Zhang, Nan and Han, Xu and Liu, Zhiyuan and Sun, Maosong. RAGE val: Scenario Specific RAG Evaluation Dataset Generation Framework. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguisti...
-
[39]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[40]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264. 1606.05250 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d16-1264 2016
-
[41]
PageIndex Blog , year =
Mingtian Zhang and Yu Tang and PageIndex Team , title =. PageIndex Blog , year =
-
[42]
2026 , eprint=
A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces , author=. 2026 , eprint=
2026
-
[43]
2026 , month =
Chroma Context-1: Training a Self-Editing Search Agent , author =. 2026 , month =
2026
-
[44]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[45]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
2005
-
[46]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[47]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[48]
CoRR , volume =
Tri Nguyen and Mir Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and Li Deng , title =. CoRR , volume =. 2016 , url =
2016
-
[49]
2025 , eprint=
CLaRa: Bridging Retrieval and Generation with Continuous Latent Reasoning , author=. 2025 , eprint=
2025
-
[50]
2026 , eprint=
DSL-Topic: Improving Topic Modeling by Distilling Soft Labelsfrom Language Models , author=. 2026 , eprint=
2026
-
[51]
CWTM : Leveraging Contextualized Word Embeddings from BERT for Neural Topic Modeling
Fang, Zheng and He, Yulan and Procter, Rob. CWTM : Leveraging Contextualized Word Embeddings from BERT for Neural Topic Modeling. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[52]
Dieng, Adji B. and Ruiz, Francisco J. R. and Blei, David M. Topic Modeling in Embedding Spaces. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00325
-
[53]
Zheng, Yuxiang and Fu, Dayuan and Hu, Xiangkun and Cai, Xiaojie and Ye, Lyumanshan and Lu, Pengrui and Liu, Pengfei. D eep R esearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.22
-
[54]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[55]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[56]
2019 , eprint=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. 2019 , eprint=
2019
-
[57]
2020 , eprint=
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , author=. 2020 , eprint=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.