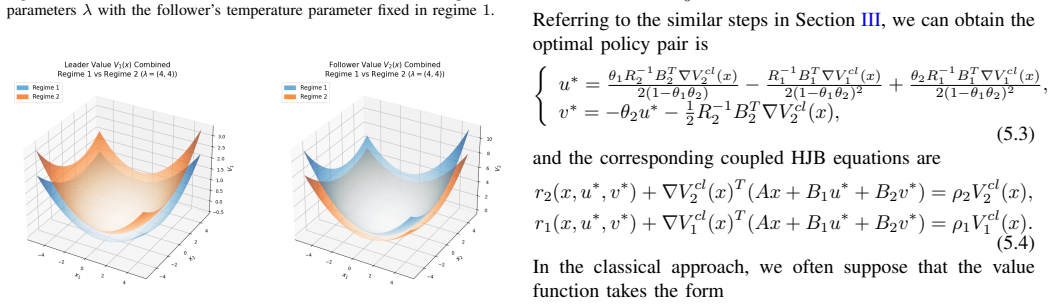
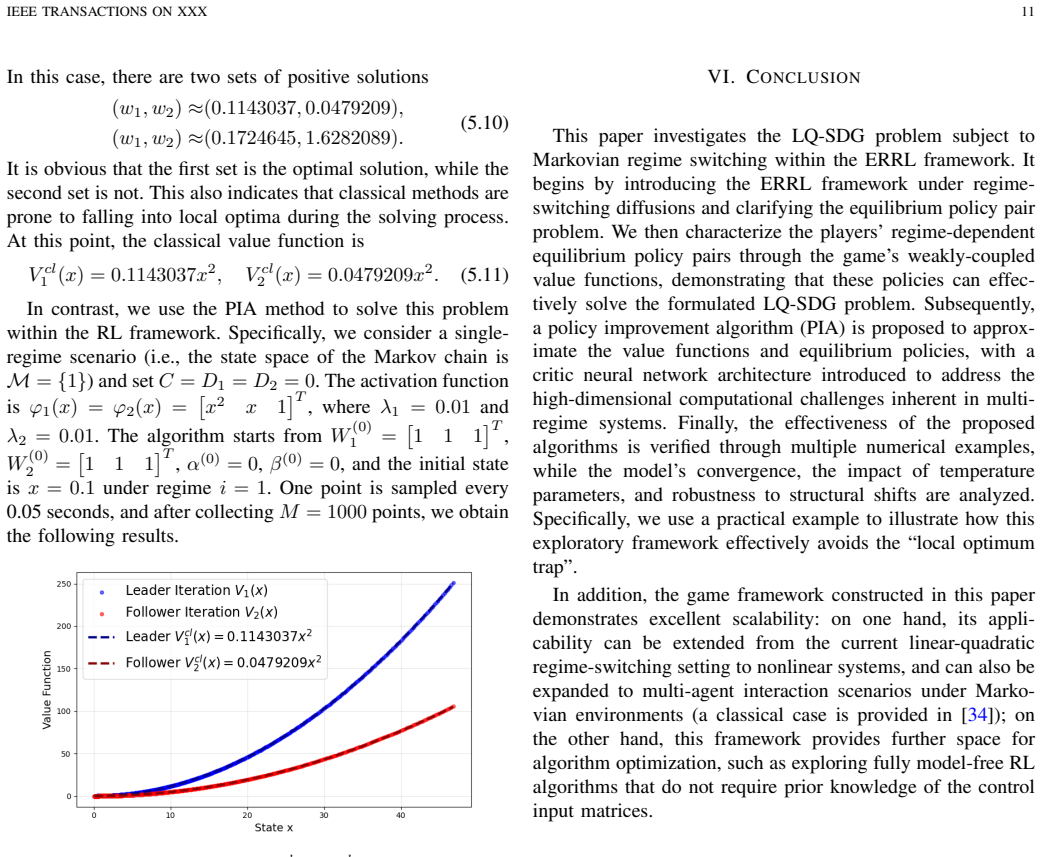
Entropy-Regularized Reinforcement Learning for Linear-Quadratic Stackelberg Differential Games in Regime-Switching Diffusion Models
Pith reviewed 2026-06-30 09:31 UTC · model grok-4.3
The pith
Entropy regularization in reinforcement learning produces stochastic policies that avoid suboptimal equilibria for linear-quadratic Stackelberg games in regime-switching diffusions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that entropy regularization applied to reinforcement learning for these games produces exploratory weakly-coupled HJBI equations whose solutions are stochastic policies capable of escaping suboptimal equilibria, with neural-network approximations and a sampling technique rendering the high-dimensional regime-switching PDEs solvable.
What carries the argument
Exploratory weakly-coupled Hamilton-Jacobi-Bellman-Isaacs equations obtained by adding entropy regularization to the leader-follower objective; neural networks approximate the regime-dependent value functions that solve these equations.
If this is right
- Stochastic policies emerge naturally from the entropy-augmented equations instead of deterministic controls.
- The method scales to high-dimensional regime-switching problems that defeat direct dynamic programming.
- Exploration induced by entropy prevents convergence to the suboptimal Stackelberg equilibria found by non-regularized methods.
- A sampling technique combined with neural-network function approximation makes the PDEs computationally feasible.
Where Pith is reading between the lines
- The same entropy-regularization device could be tested on non-linear-quadratic Stackelberg games to check whether the avoidance property survives.
- Regime-switching models appear in finance and energy systems; the framework supplies a concrete way to compute robust hierarchical policies under sudden parameter jumps.
- If the neural-network error grows with dimension, the claimed equilibrium-avoidance benefit may shrink, suggesting a need for error bounds on the approximation step.
Load-bearing premise
Neural-network approximations of the regime-dependent value functions remain accurate enough that the entropy term still forces policies away from suboptimal equilibria.
What would settle it
A numerical experiment in which the entropy-regularized policies converge to the same equilibrium payoffs as the classical deterministic solution despite the added exploration term.
Figures

read the original abstract
Stackelberg differential games (SDGs) provide a powerful framework for hierarchical decision-making in stochastic and continuous-time environments, yet their solution remains computationally challenging due to the complexity of traditional dynamic programming and Hamilton-Jacobi-Bellman-Isaacs (HJBI) methods, especially in high-dimensional systems. This paper proposes an entropy-regularized reinforcement learning (ERRL) approach for linear-quadratic SDGs (LQ-SDGs) within a continuous-time diffusion framework governed by Markovian regime switching. The key innovation lies in deriving exploratory weakly-coupled HJBI equations with entropy regularization, which promotes stochastic policies that actively avoid suboptimal equilibria -- a limitation of classical SDG methods. Neural networks are integrated to approximate regime-dependent value functions and solve high-dimensional partial differential equations (PDEs) efficiently, while a novel sampling technique enhances computational tractability. Numerical results demonstrate the effectiveness of the framework compared to conventional approaches, particularly in escaping suboptimal traps through exploratory policies. The study highlights the critical role of entropy regularization and neural network approximations in achieving robust solutions for hierarchical decision-making problems under abrupt environmental shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an entropy-regularized reinforcement learning (ERRL) framework for linear-quadratic Stackelberg differential games (LQ-SDGs) in continuous-time regime-switching diffusion models. It derives exploratory weakly-coupled Hamilton-Jacobi-Bellman-Isaacs (HJBI) equations incorporating entropy regularization to generate stochastic policies that avoid suboptimal equilibria, employs neural networks to approximate regime-dependent value functions and solve the resulting high-dimensional PDEs, introduces a novel sampling technique for tractability, and reports numerical experiments demonstrating improved performance and escape from traps relative to classical methods.
Significance. If the derivations are correct and the numerical results are robust to approximation error, the work would offer a computationally tractable method for hierarchical stochastic control under regime shifts, addressing a recognized limitation of deterministic Stackelberg solutions. The explicit use of entropy regularization to promote exploration in continuous-time games is a potentially useful technical contribution for applications in finance and control.
major comments (2)
- [Numerical experiments] Numerical experiments section: the claim that entropy-regularized policies 'actively avoid suboptimal equilibria' and 'escape suboptimal traps' rests on NN approximations of the regime-dependent HJBI PDEs, yet no error bounds, convergence rates, or comparisons against exact solutions (even in low-dimensional regime-switching cases) are provided. Without such validation, it is impossible to confirm that the observed avoidance is attributable to the regularization rather than approximation artifacts.
- [Derivation of exploratory HJBI equations] Derivation of the exploratory weakly-coupled HJBI equations: the paper states that entropy regularization promotes stochastic policies, but the manuscript does not quantify how the regularization parameter interacts with the regime-switching intensity matrix or the leader-follower coupling to guarantee escape from equilibria that are stable under the unregularized dynamics.
minor comments (2)
- [Introduction] The abstract and introduction use 'weakly-coupled' without an explicit definition or reference to prior literature on weakly-coupled HJBI systems; a brief clarification would improve readability.
- [Preliminaries] Notation for the regime-dependent value functions and the entropy term should be introduced with a single consistent symbol table to avoid ambiguity across sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Numerical experiments section: the claim that entropy-regularized policies 'actively avoid suboptimal equilibria' and 'escape suboptimal traps' rests on NN approximations of the regime-dependent HJBI PDEs, yet no error bounds, convergence rates, or comparisons against exact solutions (even in low-dimensional regime-switching cases) are provided. Without such validation, it is impossible to confirm that the observed avoidance is attributable to the regularization rather than approximation artifacts.
Authors: We agree that the current numerical section lacks direct validation against exact solutions. In the revised manuscript we will add a low-dimensional LQ-SDG example (two regimes, scalar state) for which the unregularized and entropy-regularized equilibria can be solved exactly via coupled Riccati equations. We will report the NN approximation error relative to these exact solutions and demonstrate that the escape from the suboptimal equilibrium occurs only when the entropy term is present, thereby isolating the effect of regularization from approximation artifacts. revision: yes
-
Referee: Derivation of the exploratory weakly-coupled HJBI equations: the paper states that entropy regularization promotes stochastic policies, but the manuscript does not quantify how the regularization parameter interacts with the regime-switching intensity matrix or the leader-follower coupling to guarantee escape from equilibria that are stable under the unregularized dynamics.
Authors: The derivation shows that the entropy term replaces the pointwise maximization with a softmax policy whose support is the entire action space for any finite regularization parameter, thereby guaranteeing positive probability of escape from any deterministic equilibrium. However, we do not provide explicit quantitative bounds relating the regularization strength to the switching rates or the leader-follower coupling. Adding such bounds would require a separate large-deviation or ergodic analysis that lies outside the scope of the present work; we will therefore insert a brief remark clarifying the qualitative mechanism and note the quantitative interaction as an open question for future research. revision: partial
Circularity Check
No significant circularity in derivation of entropy-regularized HJBI equations or NN approximations
full rationale
The paper's core derivation produces exploratory weakly-coupled HJBI equations with entropy regularization from the RL setup for LQ-SDGs under regime-switching diffusions; this step is presented as obtained via standard dynamic programming and entropy augmentation rather than by defining the output in terms of itself or fitting parameters to the target quantity. Neural-network approximation of regime-dependent value functions is introduced explicitly for tractability in high-dimensional PDEs, with numerical results offered as empirical demonstrations of escape from suboptimal equilibria rather than as predictions forced by construction from the fitted inputs. No self-citation load-bearing steps, uniqueness theorems imported from the same authors, or ansatz smuggling appear in the abstract or described chain. The derivation chain therefore remains self-contained against external benchmarks and does not reduce to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
von Stackelberg,Market Structure and Equilibrium
H. von Stackelberg,Market Structure and Equilibrium. Springer, 1934
1934
-
[2]
Bas ¸ar and G
T. Bas ¸ar and G. J. Olsder,Dynamic Noncooperative Game Theory. SIAM, 1999
1999
-
[3]
Stack- elberg game-based multi-agent algorithm for resource allocation and task offloading in mec-enabled c-its,
S. Zhang, X. Tong, K. Chi, W. Gao, X. Chen, and Z. Shi, “Stack- elberg game-based multi-agent algorithm for resource allocation and task offloading in mec-enabled c-its,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 10, pp. 17 940–17 951, 2025
2025
-
[4]
Denial-of-service attacks on cyber-physical systems against linear quadratic control: A stackelberg- game analysis,
W. Xing, X. Zhao, Y . Li, and L. Liu, “Denial-of-service attacks on cyber-physical systems against linear quadratic control: A stackelberg- game analysis,”IEEE Transactions on Automatic Control, vol. 70, no. 1, pp. 595–602, 2025
2025
-
[5]
Toward sustainable optimization with stackelberg game between green product family and downstream supply chain,
M. Pakseresht, B. Shirazi, I. Mahdavi, and N. Mahdavi-Amiri, “Toward sustainable optimization with stackelberg game between green product family and downstream supply chain,”Sustainable Production and Consumption, vol. 23, pp. 198–211, 2020
2020
-
[6]
A game-based hierarchical model for mandatory lane change of autonomous vehicles,
P. Huang, H. Ding, Z. Sun, and H. Chen, “A game-based hierarchical model for mandatory lane change of autonomous vehicles,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 9, pp. 11 256–11 268, 2024
2024
-
[7]
Decentralization through tokenization,
M. Sockin and W. Xiong, “Decentralization through tokenization,”The Journal of Finance, vol. 78, no. 1, pp. 247–299, 2023. IEEE TRANSACTIONS ON XXX 15
2023
-
[8]
Yong and X
J. Yong and X. Y . Zhou,Stochastic controls: Hamiltonian systems and HJB equations. Springer, 1999
1999
-
[9]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction. MIT Press, 2018
2018
-
[10]
Spatial anti-jamming scheme for internet of satellites based on the deep reinforcement learning and stackelberg game,
C. Han, L. Huo, X. Tong, H. Wang, and X. Liu, “Spatial anti-jamming scheme for internet of satellites based on the deep reinforcement learning and stackelberg game,”IEEE Transactions on Vehicular Technology, vol. 69, no. 5, pp. 5331–5342, 2020
2020
-
[11]
A curse-of-dimensionality-free numerical method for solution of certain hjb pdes,
W. M. McEneaney, “A curse-of-dimensionality-free numerical method for solution of certain hjb pdes,”SIAM journal on Control and Opti- mization, vol. 46, no. 4, pp. 1239–1276, 2007
2007
-
[12]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[13]
Maximum entropy-regularized multi- goal reinforcement learning,
R. Zhao, X. Sun, and V . Tresp, “Maximum entropy-regularized multi- goal reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 7553–7562
2019
-
[14]
Effective multi-agent deep reinforcement learning control with relative entropy regularization,
C. Miao, Y . Cui, H. Li, and X. Wu, “Effective multi-agent deep reinforcement learning control with relative entropy regularization,” IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 3704–3718, 2025
2025
-
[15]
Exploration versus exploitation in reinforcement learning: A stochastic control approach,
H. Wang, T. Zariphopoulou, and X. Y . Zhou, “Exploration versus exploitation in reinforcement learning: A stochastic control approach,” Social Science Electronic Publishing, vol. 10, no. 4, pp. 1–35, 2019
2019
-
[16]
Exploratory hjb equations and their convergence,
W. Tang, Y . P. Zhang, and X. Y . Zhou, “Exploratory hjb equations and their convergence,”SIAM Journal on Control and Optimization, vol. 60, no. 6, pp. 3191–3216, 2022
2022
-
[17]
A leader-follower stochastic linear quadratic differential game,
J. Yong, “A leader-follower stochastic linear quadratic differential game,” SIAM Journal on Control and Optimization, vol. 41, no. 4, pp. 1015– 1041, 2002
2002
-
[18]
Linear quadratic leader–follower stochastic differential games for mean-field switching diffusions,
S. Lv, J. Xiong, and X. Zhang, “Linear quadratic leader–follower stochastic differential games for mean-field switching diffusions,”Auto- matica, vol. 154, p. 111072, 2023
2023
-
[19]
Zero-sum stackelberg stochastic linear- quadratic differential games,
J. Sun, H. Wang, and J. Wen, “Zero-sum stackelberg stochastic linear- quadratic differential games,”SIAM Journal on Control and Optimiza- tion, vol. 61, no. 1, pp. 252–284, 2023
2023
-
[20]
Linear–quadratic stochastic leader–follower differential games for markov jump-diffusion models,
J. Moon, “Linear–quadratic stochastic leader–follower differential games for markov jump-diffusion models,”Automatica, vol. 147, p. 110713, 2023
2023
-
[21]
Closed-loop solvability of linear quadratic mean-field type stackelberg stochastic differential games,
Z. Li and J. Shi, “Closed-loop solvability of linear quadratic mean-field type stackelberg stochastic differential games,”Applied Mathematics & Optimization, vol. 90, no. 1, p. 22, 2024
2024
-
[22]
Linear-quadratic optimal control problems for mean-field stochastic differential equations,
J. Yong, “Linear-quadratic optimal control problems for mean-field stochastic differential equations,”SIAM Journal on Control and Op- timization, vol. 51, no. 4, pp. 2809–2838, 2013
2013
-
[23]
Linear-quadratic mean field stackelberg games with state and control delays,
A. Bensoussan, M. Chau, Y . Lai, and S. C. P. Yam, “Linear-quadratic mean field stackelberg games with state and control delays,”SIAM Journal on Control and Optimization, vol. 55, no. 4, pp. 2748–2781, 2017
2017
-
[24]
Time-inconsistent lq games for large-population systems and applications,
H. Wang and R. Xu, “Time-inconsistent lq games for large-population systems and applications,”Journal of Optimization Theory and Appli- cations, vol. 197, no. 3, pp. 1249–1268, 2023
2023
-
[25]
Two-player stackelberg game for linear system via value iteration algorithm,
M. Li, J. Qin, and L. Ding, “Two-player stackelberg game for linear system via value iteration algorithm,” in2019 IEEE 28th International Symposium on Industrial Electronics (ISIE). IEEE, 2019, pp. 2289– 2293
2019
-
[26]
Curse of optimality, and how we break it,
X. Y . Zhou, “Curse of optimality, and how we break it,”Available at SSRN 3845462, 2021
2021
-
[27]
Reinforcement learning in continuous time and space: A stochastic control approach,
H. Wang, T. Zariphopoulou, and X. Y . Zhou, “Reinforcement learning in continuous time and space: A stochastic control approach,”Journal of Machine Learning Research, vol. 21, no. 198, pp. 1–34, 2020
2020
-
[28]
Continuous-time mean–variance portfolio selection: A reinforcement learning framework,
H. Wang and X. Y . Zhou, “Continuous-time mean–variance portfolio selection: A reinforcement learning framework,”Mathematical Finance, vol. 30, no. 4, pp. 1273–1308, 2020
2020
-
[29]
Choquet regularization for continuous-time reinforcement learning,
X. Han, R. Wang, and X. Y . Zhou, “Choquet regularization for continuous-time reinforcement learning,”SIAM Journal on Control and Optimization, vol. 61, no. 5, pp. 2777–2801, 2023
2023
-
[30]
Continuous-time q- learning for jump-diffusion models under tsallis entropy,
L. Bo, Y . Huang, X. Yu, and T. Zhang, “Continuous-time q- learning for jump-diffusion models under tsallis entropy,”arXiv preprint arXiv:2407.03888, 2024
-
[31]
Exploratory utility maximization problem with tsallis entropy,
Z. Chen and J. Gu, “Exploratory utility maximization problem with tsallis entropy,”arXiv preprint arXiv:2502.01269, 2025
-
[32]
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms,
Y . Jia and X. Zhou, “Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms,”Journal of Machine Learning Research, vol. 23, no. 275, pp. 1–50, 2022
2022
-
[33]
Actor-critic method for high dimensional static hamilton–jacobi–bellman partial differential equations based on neural networks,
M. Zhou, J. Han, and J. Lu, “Actor-critic method for high dimensional static hamilton–jacobi–bellman partial differential equations based on neural networks,”SIAM Journal on Scientific Computing, vol. 43, no. 6, pp. A4043–A4066, 2021
2021
-
[34]
Hierarchical optimal synchronization for linear systems via reinforcement learning: A stackelberg–nash game perspective,
M. Li, J. Qin, Q. Ma, W. X. Zheng, and Y . Kang, “Hierarchical optimal synchronization for linear systems via reinforcement learning: A stackelberg–nash game perspective,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 4, pp. 1600–1611, 2020
2020
-
[35]
Oksendal,Stochastic differential equations: an introduction with applications
B. Oksendal,Stochastic differential equations: an introduction with applications. Springer, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.