Noise-Adaptive High-Probability Regret Bounds for Online Convex Optimization
Pith reviewed 2026-06-27 20:09 UTC · model grok-4.3
The pith
In full-information online convex optimization with strongly convex losses, high-probability regret bounds scale with the sub-Gaussian noise level σ rather than the gradient bound G.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For full-information OCO with sub-Gaussian stochastic gradients, the analysis introduces an exponential supermartingale argument that allows the martingale deviation term to scale with the noise level σ rather than the gradient bound G, yielding a multiplicative improvement of G/σ over the classical Azuma-Hoeffding baseline while bypassing the bounded-difference requirement of Freedman's inequality. For bandit feedback the paper proves a minimax lower bound establishing that high-probability regret scales linearly in log(1/δ), in contrast to the square-root scaling under full information. For constrained OCO with stochastic constraints satisfying a Slater condition, simultaneous high-probabi
What carries the argument
Exponential supermartingale argument that handles unbounded sub-Gaussian noise directly without truncation.
If this is right
- The high-probability regret improves multiplicatively by G/σ over Azuma-Hoeffding baselines when noise is smaller than the worst-case bound.
- Bandit-feedback high-probability regret scales linearly in log(1/δ) rather than sqrt(log(1/δ)).
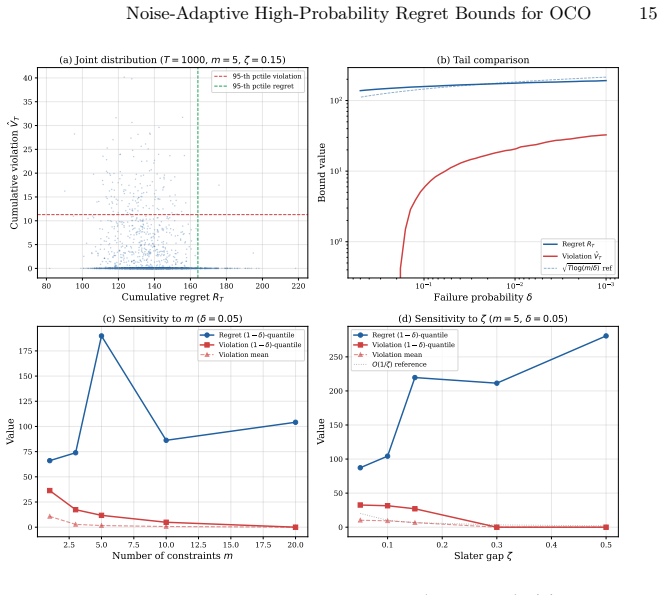
- Constrained OCO under a Slater condition simultaneously achieves O(sqrt(T log(m/δ))) regret and O(sqrt(T)/(ζ δ) + m sqrt(T log(m/δ))) violation with high probability.
Where Pith is reading between the lines
- The supermartingale technique may extend to other sequential decision settings that involve unbounded but sub-Gaussian noise.
- The linear versus square-root separation in confidence cost could motivate algorithm selection rules that depend on whether full or partial feedback is available.
- Similar adaptivity arguments might apply to time-varying noise levels or to problems with only weak convexity after suitable regularization.
- keywords:[
Load-bearing premise
The stochastic gradients are sub-Gaussian and the losses are strongly convex.
What would settle it
An experiment in which the observed high-probability regret fails to decrease proportionally when the noise level σ is reduced while the gradient bound G is held fixed would falsify the adaptivity claim.
Figures
read the original abstract
We study high-probability regret bounds for online convex optimization (OCO) with strongly convex losses and establish three results that resolve open questions at the intersection of noise adaptivity, feedback structure, and constraint satisfaction. For the full-information setting with sub-Gaussian stochastic gradients, we prove a noise-adaptive high-probability regret bound in which the martingale deviation term scales with the noise level $\sigma$ rather than the gradient bound $G$, yielding a multiplicative improvement of $G/\sigma$ over the classical Azuma-Hoeffding baseline. Our analysis introduces an exponential supermartingale argument that bypasses the bounded-difference requirement of Freedman's inequality, enabling direct treatment of unbounded sub-Gaussian noise without truncation artifacts. For bandit feedback, we prove a minimax lower bound: the high-probability regret scales linearly in $\log(1/\delta)$, in contrast to the $\sqrt{\log(1/\delta)}$ confidence cost under full information. This constitutes a formal separation in the confidence cost of strongly convex OCO across feedback models. Regarding constrained OCO with stochastic constraints satisfying a Slater condition, we provide simultaneous high-probability guarantees for both cumulative regret and long-run constraint violation, achieving $\mathcal{O}(\sqrt{T\log(m/\delta)})$ regret and $\mathcal{O}(\sqrt{T}/(\zeta\delta) + m\sqrt{T\log(m/\delta)})$ violation. Synthetic experiments corroborate all theoretical predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes three results on high-probability regret bounds for online convex optimization with strongly convex losses. In the full-information setting with sub-Gaussian stochastic gradients, it derives a noise-adaptive bound in which the martingale deviation term scales with the noise level σ (rather than the gradient bound G) via an exponential supermartingale construction that avoids truncation and the bounded-difference requirement of Freedman's inequality. For bandit feedback it proves a minimax lower bound showing that high-probability regret scales linearly with log(1/δ), in contrast to the √log(1/δ) cost under full information. For constrained OCO with stochastic constraints satisfying a Slater condition, it gives simultaneous high-probability guarantees of O(√(T log(m/δ))) regret and O(√T/(ζδ) + m √(T log(m/δ))) violation. Synthetic experiments are reported to corroborate the predictions.
Significance. If the central derivations hold, the results resolve open questions on noise-adaptive high-probability bounds and establish a formal separation in confidence cost between full-information and bandit feedback for strongly convex OCO. The exponential-supermartingale technique for handling unbounded sub-Gaussian noise without truncation is a technically clean contribution that could be useful beyond this setting. The constrained result simultaneously controls regret and violation under stochastic constraints, which is practically relevant.
minor comments (3)
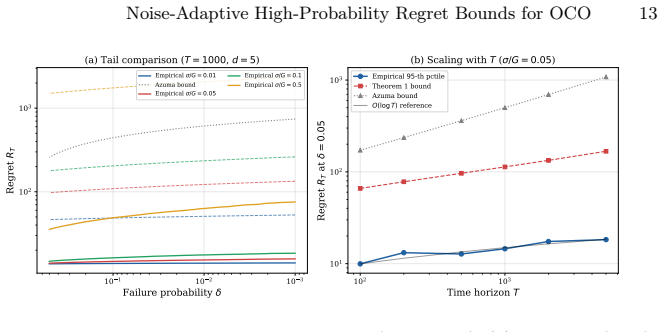
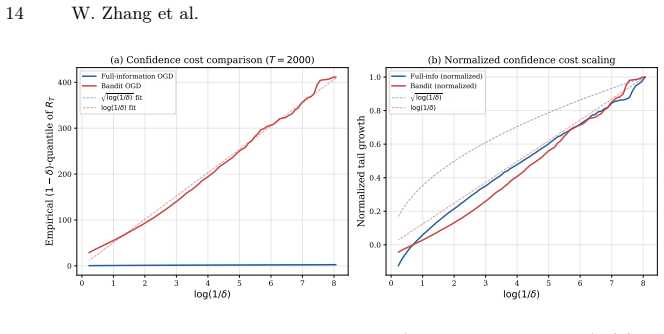
- The synthetic experiments section should specify the number of independent runs, the precise generation of sub-Gaussian noise (including the value of σ relative to G), and whether any data points were excluded; without these details it is difficult to assess how strongly the plots corroborate the claimed G/σ improvement and the linear log(1/δ) scaling.
- In the statement of the constrained result, the dependence on the Slater constant ζ and the number of constraints m appears only in the final bound; a brief remark on where these parameters enter the proof (e.g., in the dual update or the concentration argument) would improve readability.
- Notation for the failure probability δ is used uniformly across all three results; a short paragraph clarifying whether the same δ is used for the union bound over the three settings or whether separate δ's are intended would prevent minor confusion.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, accurate description of the three main results, and recommendation of minor revision. The referee's assessment aligns closely with the contributions we aimed to make.
Circularity Check
No significant circularity; derivation self-contained via standard martingale tools
full rationale
The paper establishes noise-adaptive high-probability regret bounds for strongly convex OCO using an exponential supermartingale argument on sub-Gaussian martingale differences. This construction is presented as a direct analytic device that avoids truncation and Freedman's bounded-difference requirement, without any equations reducing a claimed prediction to a fitted input or self-definition. The bandit lower bound is a formal minimax separation, and the constrained result invokes a Slater condition for simultaneous regret/violation bounds. No self-citation chains, ansatzes smuggled via prior work, or renamings of known empirical patterns appear as load-bearing steps. The derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Loss functions are strongly convex
- domain assumption Stochastic gradients are sub-Gaussian
- domain assumption Stochastic constraints satisfy a Slater condition with constant ζ
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 21st Annual Conference on Learning Theory (2008)
Abernethy, J., Bartlett, P.L., Rakhlin, A., Tewari, A.: Optimal strategies and min- imax lower bounds for online convex games. In: Proceedings of the 21st Annual Conference on Learning Theory (2008)
2008
-
[2]
In: Colt
Agarwal,A.,Dekel,O.,Xiao,L.:Optimalalgorithmsforonlineconvexoptimization with multi-point bandit feedback. In: Colt. pp. 28–40 (2010)
2010
-
[3]
The Annals of Statistics33(4), 1497–1537 (2005)
Bartlett, P.L., Bousquet, O., Mendelson, S.: Local rademacher complexities. The Annals of Statistics33(4), 1497–1537 (2005)
2005
-
[4]
In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics
Beygelzimer, A., Langford, J., Li, L., Reyzin, L., Schapire, R.: Contextual bandit algorithms with supervised learning guarantees. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. pp. 19–26. JMLR Workshop and Conference Proceedings (2011)
2011
-
[5]
Advances in Neural In- formation Processing Systems35, 33589–33602 (2022)
Castiglioni, M., Celli, A., Marchesi, A., Romano, G., Gatti, N.: A unifying frame- work for online optimization with long-term constraints. Advances in Neural In- formation Processing Systems35, 33589–33602 (2022)
2022
-
[6]
In: Conference On Learning Theory
Cutkosky, A., Orabona, F.: Black-box reductions for parameter-free online learn- ing in banach spaces. In: Conference On Learning Theory. pp. 1493–1529. PMLR (2018)
2018
-
[7]
In: 21st Annual Conference on Learning Theory
Dani, V., Hayes, T.P., Kakade, S.M.: Stochastic linear optimization under bandit feedback. In: 21st Annual Conference on Learning Theory. pp. 355–366 (2008)
2008
-
[8]
Cambridge University Press (2009)
Dubhashi, D.P., Panconesi, A.: Concentration of measure for the analysis of ran- domized algorithms. Cambridge University Press (2009)
2009
-
[9]
arXiv preprint cs/0408007 (2004)
Flaxman, A.D., Kalai, A.T., McMahan, H.B.: Online convex optimization in the bandit setting: gradient descent without a gradient. arXiv preprint cs/0408007 (2004)
Pith/arXiv arXiv 2004
-
[10]
Advances in Neural Informa- tion Processing Systems35, 36426–36439 (2022)
Guo, H., Liu, X., Wei, H., Ying, L.: Online convex optimization with hard con- straints: Towards the best of two worlds and beyond. Advances in Neural Informa- tion Processing Systems35, 36426–36439 (2022)
2022
-
[11]
In: Conference on Learning Theory
Harvey, N.J., Liaw, C., Plan, Y., Randhawa, S.: Tight analyses for non-smooth stochastic gradient descent. In: Conference on Learning Theory. pp. 1579–1613. PMLR (2019)
2019
-
[12]
Foundations and Trends in Optimization2(3-4), 157–325 (2016) Noise-Adaptive High-Probability Regret Bounds for OCO 17
Hazan, E.: Introduction to online convex optimization. Foundations and Trends in Optimization2(3-4), 157–325 (2016) Noise-Adaptive High-Probability Regret Bounds for OCO 17
2016
-
[13]
Machine Learning69(2), 169–192 (2007)
Hazan, E., Agarwal, A., Kale, S.: Logarithmic regret algorithms for online convex optimization. Machine Learning69(2), 169–192 (2007)
2007
-
[14]
Advances in Neural Information Processing Systems27(2014)
Hazan, E., Levy, K.: Bandit convex optimization: Towards tight bounds. Advances in Neural Information Processing Systems27(2014)
2014
-
[15]
In: International Conference on Machine Learning
Jenatton, R., Huang, J., Archambeau, C.: Adaptive algorithms for online convex optimization with long-term constraints. In: International Conference on Machine Learning. pp. 402–411. PMLR (2016)
2016
-
[16]
In: Proceedings of the 25th international conference on Machine learning
Kakade, S.M., Shalev-Shwartz, S., Tewari, A.: Efficient bandit algorithms for on- line multiclass prediction. In: Proceedings of the 25th international conference on Machine learning. pp. 440–447 (2008)
2008
-
[17]
In: International Conference on Machine Learning
Liakopoulos, N., Destounis, A., Paschos, G., Spyropoulos, T., Mertikopoulos, P.: Cautious regret minimization: Online optimization with long-term budget con- straints. In: International Conference on Machine Learning. pp. 3944–3952. PMLR (2019)
2019
-
[18]
The Journal of Machine Learning Research 13(1), 2503–2528 (2012)
Mahdavi, M., Jin, R., Yang, T.: Trading regret for efficiency: online convex opti- mization with long term constraints. The Journal of Machine Learning Research 13(1), 2503–2528 (2012)
2012
-
[19]
In: International Conference on Computational Learning Theory
Mannor, S., Tsitsiklis, J.N.: Online learning with constraints. In: International Conference on Computational Learning Theory. pp. 529–543. Springer (2006)
2006
-
[20]
Morgan & Claypool Publishers (2010)
Neely, M.: Stochastic network optimization with application to communication and queueing systems. Morgan & Claypool Publishers (2010)
2010
-
[21]
arXiv preprint arXiv:1702.04783 (2017)
Neely, M.J., Yu, H.: Online convex optimization with time-varying constraints. arXiv preprint arXiv:1702.04783 (2017)
Pith/arXiv arXiv 2017
-
[22]
The Annals of Probability32(3A), 1902–1933 (2004)
de la Pena, V.H., Klass, M.J., Leung Lai, T.: Self-normalized processes: expo- nential inequalities, moment bounds and iterated logarithm laws. The Annals of Probability32(3A), 1902–1933 (2004)
1902
-
[23]
Springer (2009)
De la Pena, V.H., Lai, T.L., Shao, Q.M.: Self-normalized processes: Limit theory and Statistical Applications. Springer (2009)
2009
-
[24]
Advances in Neural Information Processing Systems26(2013)
Rakhlin, S., Sridharan, K.: Optimization, learning, and games with predictable sequences. Advances in Neural Information Processing Systems26(2013)
2013
-
[25]
Statistical Science38(4), 576–601 (2023)
Ramdas, A., Grünwald, P., Vovk, V., Shafer, G.: Game-theoretic statistics and safe anytime-valid inference. Statistical Science38(4), 576–601 (2023)
2023
-
[26]
Foundations and Trends®in Machine Learning4(2), 107–194 (2025)
Shalev-Shwartz, S.: Online learning and online convex optimization. Foundations and Trends®in Machine Learning4(2), 107–194 (2025)
2025
-
[27]
In: International conference on machine learning
Shamir, O., Zhang, T.: Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In: International conference on machine learning. pp. 71–79. PMLR (2013)
2013
-
[28]
In: International conference on machine learning
Steinhardt, J., Liang, P.: Adaptivity and optimism: An improved exponentiated gradient algorithm. In: International conference on machine learning. pp. 1593–
-
[29]
In: International conference on machine learning
Yi, X., Li, X., Yang, T., Xie, L., Chai, T., Johansson, K.: Regret and cumula- tive constraint violation analysis for online convex optimization with long term constraints. In: International conference on machine learning. pp. 11998–12008. PMLR (2021)
2021
-
[30]
Advances in Neural Information Processing Systems30(2017) 18 W
Yu, H., Neely, M., Wei, X.: Online convex optimization with stochastic constraints. Advances in Neural Information Processing Systems30(2017) 18 W. Zhang et al. A Auxiliary Lemmas We collect the auxiliary tools used throughout the proofs. A.1 Freedman’s Inequality Lemma 1 (Freedman, 1975).Let(D t,F t)n t=1 be a martingale difference se- quence with|D t| ≤...
2017
-
[31]
acceptθ k = 0
ThereforePT t=1 E[et]≤ D2 + Ce 2 (1 + logT) 2 + π2Ce 12 =:Q ′(1 + logT) 2, where the constantQ′ absorbs D2,C e/2, and lower-order terms. Remark 3.One might expectE[e t]≤Q/tby analogy with the regret bound. However, the one-step contractionat+1 ≤(1−1/t)a t +C e/t2 has contraction factor1−1/tthat exactly cancels the1/tdecay: an inductive proof ofa t ≤Q/t re...
2009
-
[32]
X t g(i) t (xt) # + ≤[P (i) T ]+ +|M V,i T |. Summing overi: ˆVT = X i
The termM R T is a martingale (each summand has zero conditional mean sinceλ ⋆ is deterministic andg (i) t (xt)−¯g (i)(xt)is zero-mean conditionally on Ft−1). Each difference|λ ⋆ i [g(i) t (xt)−¯g (i)(xt)]|is bounded byλ ⋆ max ·2B g =:b R a.s. (using Assumption 8(d):|g(i) t (x)| ≤B g a.s. implies|g (i) t (x)−¯g(i)(x)| ≤2B g) and has conditional variance≤(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.