RTSGameBench: An RTS Benchmark for Strategic Reasoning by Vision-Language Models
Pith reviewed 2026-06-26 20:59 UTC · model grok-4.3
The pith
State-of-the-art vision-language models perform poorly on RTS tasks requiring tighter coordination and larger scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
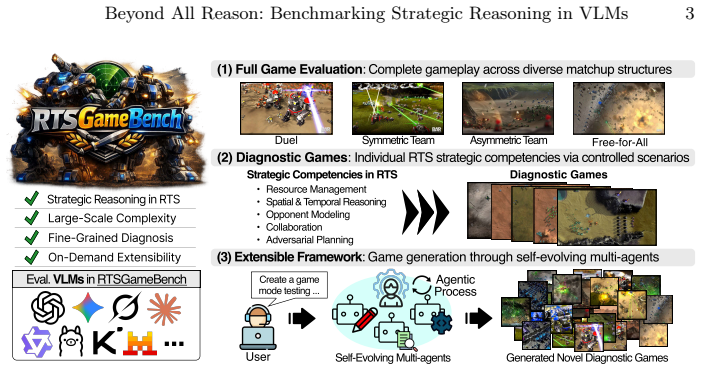
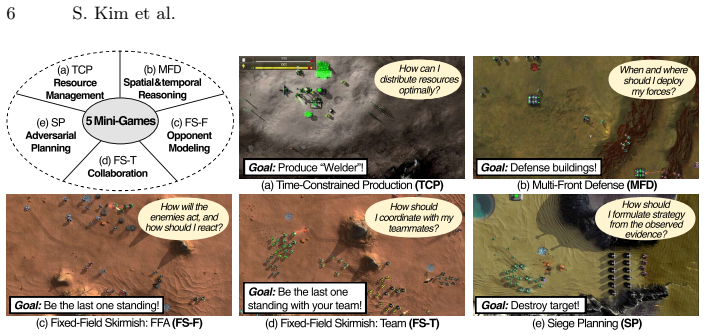
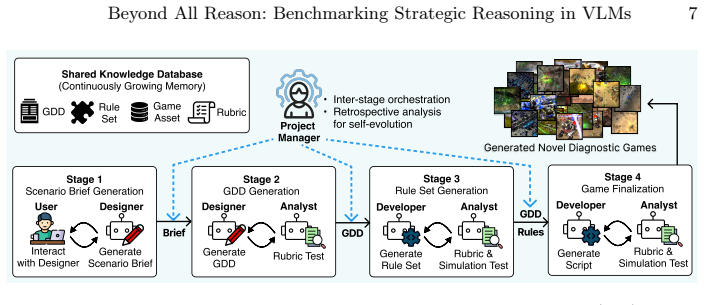
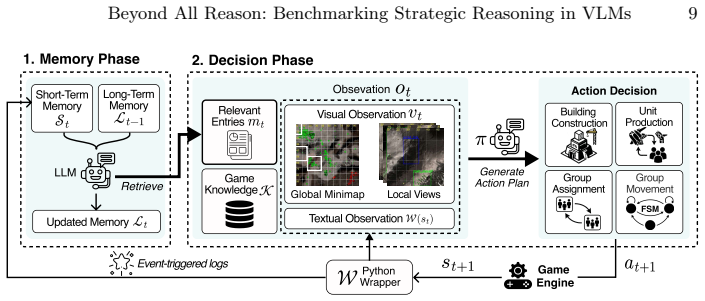
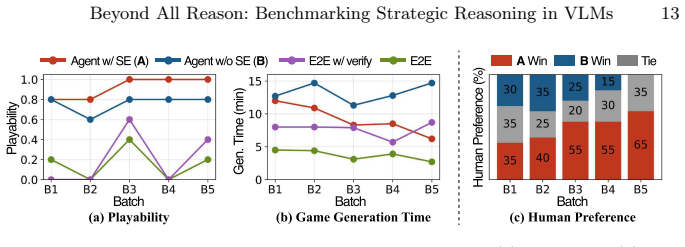
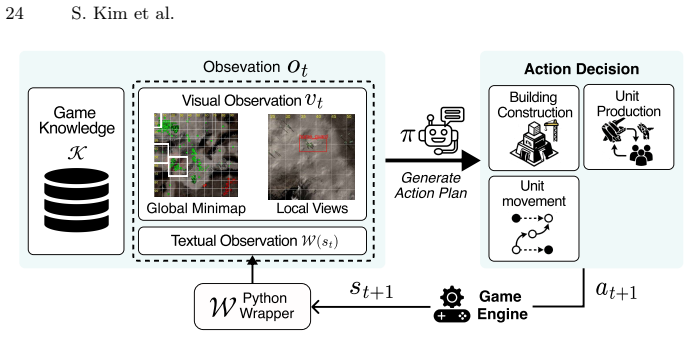
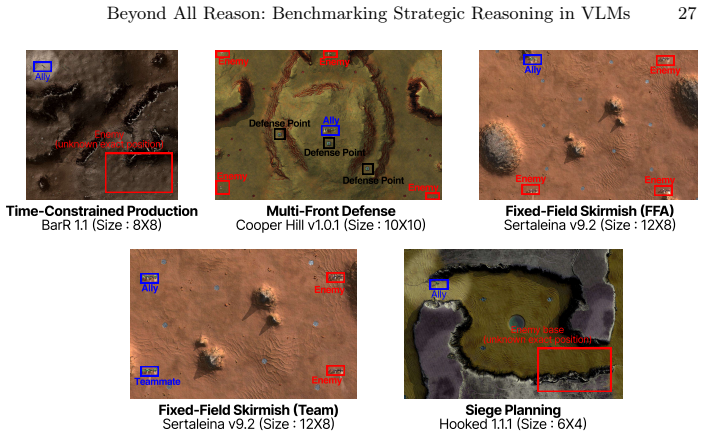
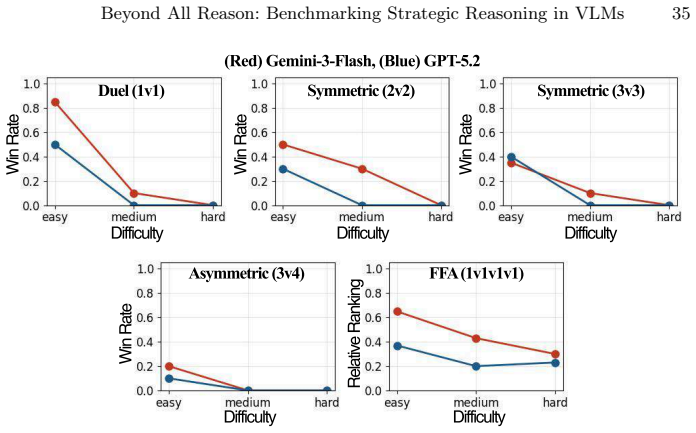
RTSGameBench provides evaluations through diverse gameplay across various matchup structures, diagnostic assessment via mini-games each targeting an individual strategic competency, and extensible coverage via a self-evolving generation framework that converts free-form queries into new mini-games improving over successive cycles. RTSGameAgent manages units by an FSM with agentic memory. Multiple state-of-the-art VLMs do not perform well when matchups demand tighter coordination, multiagent coordination and when task scale increases.
What carries the argument
RTSGameBench's diagnostic mini-games, each targeting an individual strategic competency, together with its self-evolving generation framework that converts free-form queries into new mini-games.
If this is right
- VLMs require improved handling of multi-agent coordination under partial observability.
- Performance drops occur as RTS task scale increases.
- The benchmark enables systematic isolation and diagnosis of specific strategic weaknesses.
- Self-evolving scenario generation expands test coverage automatically across cycles.
Where Pith is reading between the lines
- The benchmark's structure could be adapted to evaluate VLMs in non-game domains that also require opponent modeling and long-horizon coordination, such as multi-robot task allocation.
- The identified coordination and scaling failures suggest that hybrid VLM-plus-classical-planner systems may be needed before reliable deployment in uncertain multi-agent settings.
- Successive cycles of the self-evolving framework could be used to generate progressively harder tests that track whether model improvements close the observed gaps.
Load-bearing premise
The mini-games each target an individual strategic competency and the self-evolving generation framework converts free-form queries into new mini-games that improve coverage over successive cycles.
What would settle it
Demonstrating that multiple state-of-the-art VLMs achieve high win rates or strong competency scores on the coordination-heavy mini-games and on larger-scale RTS matchups would falsify the reported performance limitations.
Figures































read the original abstract
Modern Vision-Language Models (VLMs) often struggle with strategic reasoning, i.e., anticipating and influencing other agents' actions, under uncertainty in competitive and cooperative settings. Real-time strategy (RTS) games can be a natural testbed for diagnosing this limitation, as they demand coordination with allies, adaptation to opponents' strategy, and long-horizon planning under partial observability. However, existing RTS benchmarks offer limited evaluation scope, lack systematic competency diagnosis, and remain fixed in the pre-designed scenario coverage. To address these limitations, we present RTSGameBench, which is built on Beyond All Reason, a large-scale RTS game with an expanded battlefield that demands broader strategy diversity than the existing testbeds. The proposed benchmark provides evaluations through diverse gameplay across various matchup structures, diagnostic assessment via mini-games, each targeting an individual strategic competency, and extensible coverage via a self-evolving generation framework that converts free-form queries into new mini-games, improving over successive cycles. Additionally, for VLMs to operate in large-scale RTS games, we provide RTSGameAgent that manages units by an FSM with agentic memory. We empirically validate that multiple state-of-the-art VLMs do not perform well when matchups demand tighter coordination, multiagent coordination and when task scale increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RTSGameBench, a benchmark built on the Beyond All Reason RTS game for evaluating vision-language models on strategic reasoning tasks. It features diverse matchup structures, diagnostic mini-games targeting individual competencies, a self-evolving framework to generate new scenarios from free-form queries, and the RTSGameAgent (an FSM augmented with agentic memory) to enable VLMs to control units in large-scale settings. The central empirical claim is that multiple state-of-the-art VLMs perform poorly in matchups requiring tighter coordination, multi-agent coordination, and at increased task scales.
Significance. If the evaluation methodology properly isolates VLM reasoning limitations, the benchmark could provide a scalable, extensible testbed for diagnosing strategic deficiencies in VLMs that existing fixed RTS benchmarks do not address. The self-evolving generation and competency-targeted mini-games represent potentially useful contributions to benchmark design.
major comments (3)
- [RTSGameAgent and empirical validation sections] Evaluation methodology (RTSGameAgent description and VLM results sections): All VLM performance measurements route through RTSGameAgent, which decomposes control via an FSM with agentic memory. No ablation is reported that holds the agent fixed while varying the VLM, substitutes a non-VLM controller, or compares against a pure VLM baseline without the FSM layer. This prevents isolating whether observed shortfalls in coordination and scale arise from VLM strategic reasoning or from limitations in the FSM state machine and memory interface, directly undermining the central claim that VLMs 'do not perform well' due to reasoning deficiencies.
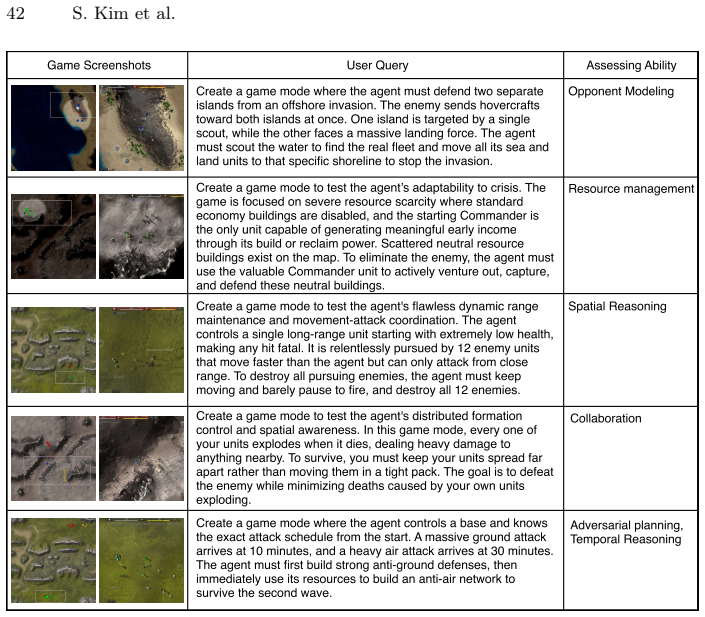
- [Mini-games and self-evolving generation sections] Mini-games and diagnostic assessment section: The claim that each mini-game targets an individual strategic competency (and that the self-evolving framework improves coverage) lacks supporting evidence such as inter-rater validation, correlation analysis with full-game performance, or ablation of the generation cycles. Without this, the diagnostic value of the benchmark for specific competencies cannot be assessed.
- [Empirical results and tables/figures] Results presentation: The abstract states an empirical validation of poor VLM performance under coordination and scale demands, yet the provided manuscript text supplies no quantitative metrics, error bars, baseline comparisons (e.g., rule-based agents or human play), or scoring details. If these are absent from the full results tables/figures, the central empirical claim lacks visible support.
minor comments (2)
- [RTSGameAgent implementation] Clarify the exact interface between VLM outputs and RTSGameAgent actions (e.g., how natural language plans are mapped to FSM states) to improve reproducibility.
- [Related work and benchmark design] Add explicit discussion of partial observability handling and how the benchmark differs quantitatively from prior RTS testbeds (e.g., in battlefield size or agent count).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on RTSGameBench. We address each major comment point by point below, providing clarifications on our methodology and indicating planned revisions where they strengthen the claims without misrepresenting the work.
read point-by-point responses
-
Referee: [RTSGameAgent and empirical validation sections] Evaluation methodology (RTSGameAgent description and VLM results sections): All VLM performance measurements route through RTSGameAgent, which decomposes control via an FSM with agentic memory. No ablation is reported that holds the agent fixed while varying the VLM, substitutes a non-VLM controller, or compares against a pure VLM baseline without the FSM layer. This prevents isolating whether observed shortfalls in coordination and scale arise from VLM strategic reasoning or from limitations in the FSM state machine and memory interface, directly undermining the central claim that VLMs 'do not perform well' due to reasoning deficiencies.
Authors: RTSGameAgent is presented as an enabling component specifically to allow VLMs to operate in large-scale RTS environments, where direct end-to-end control of hundreds of units under partial observability is not feasible. The reported results therefore reflect VLM strategic reasoning as mediated through this practical interface, which we view as the relevant setting for the benchmark. We agree, however, that the absence of ablations (e.g., rule-based controllers using the identical FSM/memory layer or a pure-VLM baseline) limits the ability to fully attribute shortfalls to the VLM. In the revised version we will add these comparisons and a dedicated discussion of the agent's role in isolating reasoning limitations. revision: yes
-
Referee: [Mini-games and self-evolving generation sections] Mini-games and diagnostic assessment section: The claim that each mini-game targets an individual strategic competency (and that the self-evolving framework improves coverage) lacks supporting evidence such as inter-rater validation, correlation analysis with full-game performance, or ablation of the generation cycles. Without this, the diagnostic value of the benchmark for specific competencies cannot be assessed.
Authors: Mini-games were constructed by mapping established RTS competencies (resource allocation, tactical positioning, multi-unit coordination, etc.) to isolated scenarios derived from Beyond All Reason mechanics. The self-evolving generator is intended to iteratively expand coverage from free-form queries. We acknowledge that the manuscript currently provides only design rationale rather than quantitative validation such as inter-rater agreement or performance correlations. We will add correlation analyses between mini-game and full-matchup results, plus a description of the generation-cycle ablation, in the revision. revision: yes
-
Referee: [Empirical results and tables/figures] Results presentation: The abstract states an empirical validation of poor VLM performance under coordination and scale demands, yet the provided manuscript text supplies no quantitative metrics, error bars, baseline comparisons (e.g., rule-based agents or human play), or scoring details. If these are absent from the full results tables/figures, the central empirical claim lacks visible support.
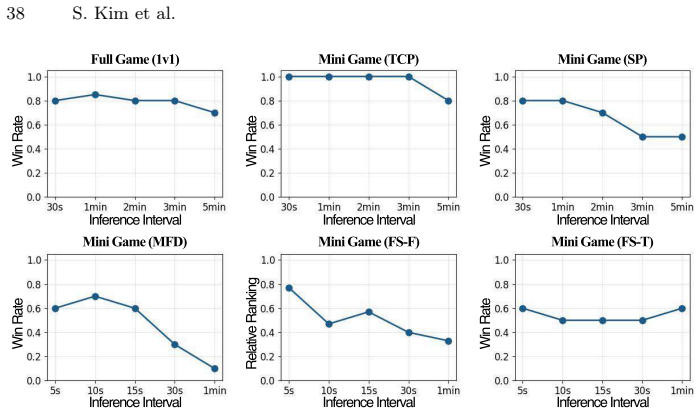
Authors: Section 5 of the full manuscript contains the quantitative results, including win-rate tables across VLMs and matchups, scale-sensitivity plots, coordination metrics, and rule-based baselines. Error bars and scoring definitions are provided in the corresponding figures and appendix. If these elements were not immediately apparent from the text, we will add explicit cross-references from the abstract and results narrative, and ensure all numerical values are highlighted in the revision. revision: partial
Circularity Check
No circularity: empirical benchmark construction with no derivations or self-referential reductions
full rationale
The paper constructs and evaluates an RTS benchmark for VLMs using mini-games, a self-evolving generation process, and an FSM-based agent wrapper. No equations, parameter fits, predictions, or uniqueness theorems appear in the provided text. The central claims are empirical performance measurements on held-out matchups and mini-games; these do not reduce to the benchmark's own inputs by construction. Self-citations are absent from the load-bearing steps. The work is therefore self-contained as an empirical artifact rather than a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
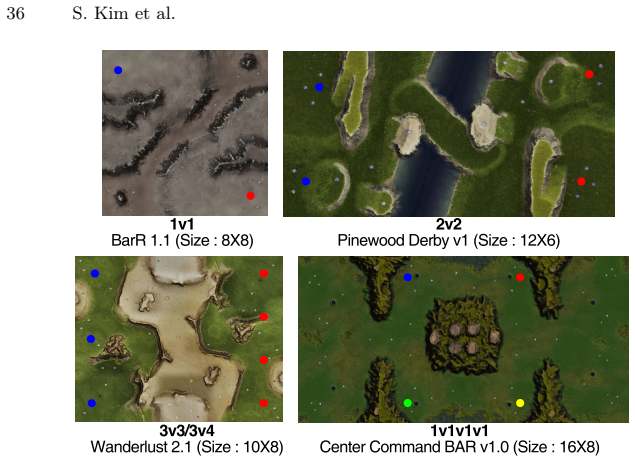
- domain assumption Real-time strategy games demand coordination with allies, adaptation to opponents' strategy, and long-horizon planning under partial observability, making them a natural testbed for strategic reasoning.
invented entities (1)
-
RTSGameAgent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Conference on Language Modeling (COLM) (2025)
Ahn, D., Kim, S., Choi, J.: Society of mind meets real-time strategy: A hierarchical multi-agent framework for strategic reasoning. In: Conference on Language Modeling (COLM) (2025)
2025
-
[2]
IEEE Transactions on Games (2025)
Anne, T., Syrkis, N., Elhosni, M., Turati, F., Legendre, F., Jaquier, A., Risi, S.: Harnessing language for coordination: A framework and benchmark for llm-driven multi-agent control. IEEE Transactions on Games (2025)
2025
-
[3]
In: Psychology of Learning and Motivation, vol
Atkinson, R.C., Shiffrin, R.M.: Human memory: A proposed system and its control processes. In: Psychology of Learning and Motivation, vol. 2, pp. 89–195. Academic Press (1968)
1968
-
[4]
Beyond All Reason Developers: Beyond all reason: Main game repository.https: //github.com/beyond-all-reason/Beyond-All-Reason(2019)
2019
-
[5]
https://github.com/beyond-all-reason/RecoilEngine (2023), a hard fork of the SpringRTS engine (version 105 tree)
Beyond All Reason Developers: Recoil engine: A powerful free cross-platform RTS game engine. https://github.com/beyond-all-reason/RecoilEngine (2023), a hard fork of the SpringRTS engine (version 105 tree)
2023
-
[6]
https://www.beyondallreason
Beyond All Reason Team: Beyond all reason. https://www.beyondallreason. info/(2024), open-source real-time strategy game
2024
-
[7]
In: Robotics: Science and Systems (2023)
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrish- nan, K., Hausman, K., Herzog, A., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jackson, T., Jesmonth, S., Joshi, N.J., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, K.H., Levine, S., Lu, Y., Malla, U., Manjunath, D., Mordatch, I., Nachum, O., Parada, C., Peralta, J...
2023
-
[8]
In: Advances in Neural Information Processing Systems (NeurIPS)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 33, pp. 1877–1901 (2020)
1901
-
[9]
Jones & Bartlett Learning (2004)
Buckland, M.: Programming Game AI by Example. Jones & Bartlett Learning (2004)
2004
-
[10]
In: Proceedings of the 18th International Joint Conference on Artificial Intelligence (IJCAI)
Buro, M.: Real-time strategy games: A new ai research challenge. In: Proceedings of the 18th International Joint Conference on Artificial Intelligence (IJCAI). pp. 1534–1535 (2003) 16 S. Kim et al
2003
-
[11]
In: International Conference on Machine Learning (ICML)
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. In: International Conference on Machine Learning (ICML). pp. 8469–8488 (2023)
2023
-
[12]
In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023),https://openreview
Ellis, B., Cook, J., Moalla, S., Samvelyan, M., Sun, M., Mahajan, A., Foerster, J.N., Whiteson, S.: SMACv2: An improved benchmark for cooperative multi- agent reinforcement learning. In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023),https://openreview. net/forum?id=5OjLGiJW3u
2023
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS)
Fan, L., Wang, G., Jiang, Y., Mandlekar, A., Yang, Y., Zhu, H., Tang, A., Huang, D.A., Zhu, Y., Anandkumar, A.: Minedojo: Building open-ended embodied agents with internet-scale knowledge. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 35, pp. 18343–18362 (2022)
2022
-
[14]
com/wiki/StarCraft_II(2024), accessed: 2025
Fandom Contributors: StarCraft II — StarCraft wiki.https://starcraft.fandom. com/wiki/StarCraft_II(2024), accessed: 2025
2024
-
[15]
CRC Press, Boca Raton, FL, 3rd edn
Fullerton, T.: Game Design Workshop: A Playcentric Approach to Creating Inno- vative Games. CRC Press, Boca Raton, FL, 3rd edn. (2014)
2014
-
[16]
arXiv preprint arXiv:2305.19165 (2023)
Gandhi, K., Sadigh, D., Goodman, N.D.: Strategic reasoning with language models. arXiv preprint arXiv:2305.19165 (2023)
arXiv 2023
-
[17]
In: NeurIPS (2024)
Guan, Z., Kong, X., Zhong, F., Wang, Y.: Richelieu: Self-evolving llm-based agents for ai diplomacy. In: NeurIPS (2024)
2024
-
[18]
arXiv preprint arXiv:2308.00352 (2024)
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, Z., Yau, S.K.S., Lin, Z., Zhou, L., Ran, C., Xiao, L., Wu, C., Schmidhuber, J.: Metagpt: Meta programming for a multi-agent collaborative framework. arXiv preprint arXiv:2308.00352 (2024)
Pith/arXiv arXiv 2024
-
[19]
Hu, L., Huo, M., Zhang, Y., Yu, H., Xing, E.P., Stoica, I., Rosing, T., Jin, H., Zhang, H.: lmgame-bench: How good are llms at playing games? arXiv preprint arXiv:2505.15146 (2025)
arXiv 2025
-
[20]
arXiv preprint arXiv:2402.01118 (2024)
Hu, S., Huang, T., Liu, L.: Pokéllmon: A human-parity agent for pokémon battles with large language models. arXiv preprint arXiv:2402.01118 (2024)
arXiv 2024
-
[21]
Lua.org (2006)
Ierusalimschy, R.: Programming in Lua. Lua.org (2006)
2006
-
[22]
Jwa, S., Ahn, D., Kim, R., Kang, D., Choi, J.: Becoming experienced judges: Selective test-time learning for evaluators (2025)
2025
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Khan, M.H., Sarvadevabhatla, R.K.: Sketchtopia: A dataset and foundational agents for benchmarking asynchronous multimodal communication with iconic feedback. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18176–18186 (2025)
2025
-
[24]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=Xr73jEYG29
Li, Z., Ni, Y., Qi, R., Lu, C., Jiang, L., Xiaojie, X., Liu, X., Li, P., Guo, Y., Ma, Z., Li, H., wu hui, Xian, G., Huang, K., Zhang, X.: LLM-pySC2: Starcraft II learning environment for large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=Xr73jEYG29
2025
-
[25]
arXiv preprint arXiv:2310.05036 (2023)
Light, J., Cai, M., Shen, S., Hu, Z.: Avalonbench: Evaluating llms playing the game of avalon. arXiv preprint arXiv:2310.05036 (2023)
arXiv 2023
-
[26]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Lin, W., Roberts, J., Yang, Y., Albanie, S., Lu, Z., Han, K.: GAMEBoT: Transparent assessment of LLM reasoning in games. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 7656–
-
[27]
acl-long.378/ Beyond All Reason: Benchmarking Strategic Reasoning in VLMs 17
Association for Computational Linguistics, Vienna, Austria (2025).https: //doi.org/10.18653/v1/2025.acl-long.378, https://aclanthology.org/2025. acl-long.378/ Beyond All Reason: Benchmarking Strategic Reasoning in VLMs 17
-
[28]
arXiv preprint arXiv:2412.05255 (2024)
Long, Q., Li, Z., Gong, R., Wu, Y.N., Terzopoulos, D., Gao, X.: Teamcraft: A benchmark for multi-modal multi-agent systems in minecraft. arXiv preprint arXiv:2412.05255 (2024)
arXiv 2024
-
[29]
arXiv preprint arXiv:2503.05383 (2025)
Ma, W., Fu, Y., Zhang, Z., Ghanem, B., Li, G.: Ava: Attentive vlm agent for mastering starcraft ii. arXiv preprint arXiv:2503.05383 (2025)
Pith/arXiv arXiv 2025
-
[30]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=kEPpD7yETM
Ma, W., Mi, Q., Zeng, Y., Yan, X., Lin, R., Wu, Y., Wang, J., Zhang, H.: Large language models play starcraft II:benchmarks and a chain of summarization ap- proach. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=kEPpD7yETM
2024
-
[31]
In: NeurIPS (2023)
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al.: Self-refine: Iterative refinement with self-feedback. In: NeurIPS (2023)
2023
-
[32]
IEEE Transactions on Computational Intelligence and AI in Games5(4), 293–311 (2013)
Ontañón, S., Synnaeve, G., Uriarte, A., Richoux, F., Churchill, D., Preuss, M.: A survey of real-time strategy game ai research and competition in starcraft. IEEE Transactions on Computational Intelligence and AI in Games5(4), 293–311 (2013)
2013
-
[33]
arXiv preprint arXiv:2303.08774 (2023)
OpenAI: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[34]
OpenAI: Introducing GPT-5.2.https://openai.com/index/introducing-gpt-5- 2/(December 2025), accessed: 2025-12-11
2025
-
[35]
In: Advances in Neural Information Processing Systems (NeurIPS)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 35, pp. 27730–27744 (2022)
2022
-
[36]
arXiv preprint arXiv:2310.08560 (2023)
Packer, C., Wooders, S., Lin, K., Fang, V., Patil, S.G., Stoica, I., Gonzalez, J.E.: MemGPT: Towards llms as operating systems. arXiv preprint arXiv:2310.08560 (2023)
Pith/arXiv arXiv 2023
-
[37]
arXiv preprint arXiv:2411.13543 (2024)
Paglieri, D., Cupiał, B., Coward, S., Piterbarg, U., Wolczyk, M., Khan, A., Pignatelli, E., Kuciński, Ł., Pinto, L., Fergus, R., et al.: Balrog: Benchmarking agentic llm and vlm reasoning on games. arXiv preprint arXiv:2411.13543 (2024)
arXiv 2024
-
[38]
arXiv preprint arXiv:2506.03610 (2025)
Park, D., Kim, M., Choi, B., Kim, J., Lee, K., Lee, J., Park, I., Lee, B.U., Hwang, J., Ahn, J., et al.: Orak: A foundational benchmark for training and evaluating llm agents on diverse video games. arXiv preprint arXiv:2506.03610 (2025)
Pith/arXiv arXiv 2025
-
[39]
In: ACM Symposium on User Interface Software and Technology (UIST)
Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In: ACM Symposium on User Interface Software and Technology (UIST). pp. 1–22 (2023)
2023
-
[40]
arXiv preprint arXiv:2401.10568 (2024)
Qi, S., Chen, S., Li, Y., Kong, X., Wang, J., Yang, B., Wong, P., Zhong, Y., Zhang, X., Zhang, Z., et al.: Civrealm: A learning and reasoning odyssey in civilization for decision-making agents. arXiv preprint arXiv:2401.10568 (2024)
arXiv 2024
-
[41]
arXiv preprint arXiv:2307.07924 (2024)
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., Xu, J., Li, D., Liu, Z., Sun, M.: Chatdev: Communicative agents for software development. arXiv preprint arXiv:2307.07924 (2024)
Pith/arXiv arXiv 2024
-
[42]
https : / / newqualitipedia
Qualitipedia contributors: Beyond all reason. https : / / newqualitipedia . telepedia.net/wiki/Beyond_All_Reason(2024)
2024
-
[43]
Journal of Machine Learning Research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research21(140), 1–67 (2020)
2020
-
[44]
AI Magazine 35(4), 75–104 (2014)
Robertson, G., Watson, I.: A review of real-time strategy game ai. AI Magazine 35(4), 75–104 (2014)
2014
-
[45]
arXiv preprint arXiv:2508.10428 (2025) 18 S
Shen, P., Wang, Y., Mu, N., Luan, Y., Xie, R., Yang, S., Wang, L., Hu, H., Xu, S., Yang, Y., et al.: Sc2arena and starevolve: Benchmark and self-improvement frame- work for llms in complex decision-making tasks. arXiv preprint arXiv:2508.10428 (2025) 18 S. Kim et al
arXiv 2025
-
[46]
In: NeurIPS (2023)
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Language agents with verbal reinforcement learning. In: NeurIPS (2023)
2023
-
[47]
Psychological Review99(2), 195–231 (1992)
Squire, L.R.: Memory and the hippocampus: A synthesis from findings with rats, monkeys, and humans. Psychological Review99(2), 195–231 (1992)
1992
-
[48]
arXiv preprint arXiv:2307.07947 (2023)
Tan,S., Ivanovic,B., Weng, X., Pavone, M., Kraehenbuehl,P.:Language conditioned traffic generation. arXiv preprint arXiv:2307.07947 (2023)
arXiv 2023
-
[49]
arXiv preprint arXiv:2503.06047 (2025)
Tang, W., Zhou, Y., Xu, E., Cheng, K., Li, M., Xiao, L.: Dsgbench: A diverse strategic game benchmark for evaluating llm-based agents in complex decision- making environments. arXiv preprint arXiv:2503.06047 (2025)
Pith/arXiv arXiv 2025
-
[50]
arXiv preprint arXiv:2302.13971 (2023)
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[51]
Nature575(7782), 350–354 (2019)
Vinyals, O., Babuschkin, I., Czarnecki, W.M., Mathieu, M., Dudzik, A., Chung, J., Choi, D.H., Powell, R., Ewalds, T., Georgiev, P., et al.: Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature575(7782), 350–354 (2019)
2019
-
[52]
arXiv preprint arXiv:2601.05899 (2026)
Wang, D., Zhou, C., Zhao, D., Liu, X., Ma, M.C., Ushaw, G., Davison, R.: Tower- mind: A tower defence game learning environment and benchmark for llm as agents. arXiv preprint arXiv:2601.05899 (2026)
Pith/arXiv arXiv 2026
-
[53]
In: Proceedings of the 31st International Conference on Computational Linguistics
Wang, S., Long, Z., Fan, Z., Huang, X., Wei, Z.: Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 3310–3328. Association for Computational Linguistics, Abu Dhabi, UAE (2025),https://aclanthology. org/2025.coling-main.223/
2025
-
[54]
Wang, Y., Liu, S., Fang, J., Meng, Z.: Evoagentx: An automated framework for evolving agentic workflows (2025),https://arxiv.org/abs/2507.03616
arXiv 2025
-
[55]
arXiv preprint arXiv:2503.10042 (2025)
Wang, Z., Dong, Y., Luo, F., Ruan, M., Cheng, Z., Chen, C., Li, P., Liu, Y.: Escapecraft: A 3d room escape environment for benchmarking complex multimodal reasoning ability. arXiv preprint arXiv:2503.10042 (2025)
arXiv 2025
-
[56]
In: COLM (2024)
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., et al.: Autogen: Enabling next-gen llm applications via multi-agent conversation. In: COLM (2024)
2024
-
[57]
arXiv preprint arXiv:2502.12110 (2025)
Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., Zhang, Y.: A-MEM: Agentic memory for LLM agents. arXiv preprint arXiv:2502.12110 (2025)
Pith/arXiv arXiv 2025
-
[58]
arXiv preprint arXiv:2506.02387 (2025)
Xu, Z., Xu, Z., Yi, X., Yuan, H., Chen, X., Wu, Y., Yu, C., Wang, Y.: Vs-bench: Evaluating vlms for strategic reasoning and decision-making in multi-agent envi- ronments. arXiv preprint arXiv:2506.02387 (2025)
Pith/arXiv arXiv 2025
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, J., Xu, C., Li, B.: Chatscene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15459–15469 (2024)
2024
-
[60]
arXiv preprint arXiv:2603.01562 (2026)
Zhang, Q., Zhou, J., Wang, Y., Lyu, F., Ming, Y., Xu, C., Sun, Q., Zheng, K., Kang, P., Liu, X., Ma, C.: Rubricbench: Aligning model-generated rubrics with human standards. arXiv preprint arXiv:2603.01562 (2026)
arXiv 2026
-
[61]
In: Conference on Language Modeling (COLM) (2024)
Zhang, Y., Mao, S., Ge, T., Wang, X., de Wynter, A., Xia, Y., Wu, W., Song, T., Lan, M., Wei, F.: Llm as a mastermind: A survey of strategic reasoning with large language models. In: Conference on Language Modeling (COLM) (2024)
2024
-
[62]
Zheng, X., Li, L., Yang, Z., Yu, P., Wang, A.J., Yan, R., Yao, Y., Wang, L.: V-mage: A game evaluation framework for assessing vision-centric capabilities in multimodal large language models. arXiv preprint arXiv:2504.06148 (2025) Beyond All Reason: Benchmarking Strategic Reasoning in VLMs 19
Pith/arXiv arXiv 2025
-
[63]
F r o n t l i n e
Zheng, X., Lin, H., He, K., Wang, Z., Fu, Q., Fu, H., Zheng, Z., Liang, Y.: Mcu: An evaluation framework for open-ended game agents. In: Forty-second International Conference on Machine Learning (2025) Supplementary Material for R TSGameBench: An RTS Benchmark for Strategic Reasoning by Vision-Language Models San Kim*1 , Daechul Ahn*1 , Reokyoung Kim1 , H...
2025
-
[64]
Updat e t he memor y b y maintaining t he FINAL list of e xperiences t hat should be r etained
New triggers: R ecent game e v ent s t hat ma y contain v aluable inf ormation Y our job is t o: 1 . Updat e t he memor y b y maintaining t he FINAL list of e xperiences t hat should be r etained
-
[65]
cont ent
R etrie v e r ele v ant memories t hat ar e useful f or t he curr ent decision-making F or memor y updat es, y ou ma y: - K eep e xisting e xperiences t hat ar e still r ele v ant - R emo v e out dat ed or r edundant e xperiences - Add new e xperiences deriv ed fr om triggers - Mer ge similar e xperiences int o one F or each e xperience in updat e_ memor ...
-
[66]
updat e_ memor y
Batt le out comes and t heir causes 3 . Strat egic decisions and t heir r esult s 4 . T errit orial contr ol changes Output f ormat: { "updat e_ memor y": [ {"cont ent": "e xperience sent ence" , "tag": "cat egor y _tag" , "time": game_time}, ... ], "r etrie v e_ memor y": [ {"cont ent": "e xperience sent ence" , "tag": "cat egor y _tag" , "time": game_ti...
-
[67]
w orld": {
Det ermine t he unit pr oduction queue f or each f act or y 3 . Or ganiz e all militar y unit s int o tactical squads, assign each squad a mo v ement tar get Description: {{G AME_DESCRIPTION}} Kno wledge: {{G AME_KNOWLEDGE}} IMA GE INPUT FORMA T : - First image: Minimap view of t he entir e batt lefield - Second image: Scr een view ( on-scr een ar ea, cen...
-
[68]
Start here
'designer': Creates the Game Design (GDD JSON). Start here
-
[69]
Run this after Design is valid
'rule_developer': Writes Lua code for Rules defined by the Designer. Run this after Design is valid
-
[70]
Run this ONLY after Rules are valid
'script_developer': Generates the final Scenario Script (JSON/Text). Run this ONLY after Rules are valid
-
[71]
'finish': All steps are complete and valid. [Current State] - User Intent: {user_intent} - GDD Exists: {has_gdd} - Rules Verified: {rules_valid} - Final Script Exists: {has_final_script} - Last Node Visited: {last_node} - Is Valid: {is_valid} [Feedback History] {feedback_history_summary} [Your Tasks]
-
[72]
ANALYZE the feedback history from all agents (designer, rule_developer, script_developer)
-
[73]
IDENTIFY which stage failed and why
-
[74]
DECIDE the next_node to route to
-
[75]
next_node
SYNTHESIZE a concise meta_feedback that summarizes: - What went wrong (if anything) - Which agent(s) had issues - Key error patterns or trends - Actionable guidance for the next agent [Routing Rules] - If GDD is missing or has invalid feedback -> Route to 'designer' - If GDD is valid but Rules failed verification -> Route to 'rule_developer' - If Rules ar...
-
[76]
**Intent Interpretation**: What did the user actually want? What core gameplay fantasy or experience were they asking for?
-
[77]
**Design Rationale**: Why were these specific mechanics, rules, and rules chosen to fulfill that intent? What design principles guided the choices?
-
[78]
**Key Decisions**: Explain the most important creative choices — map selection, unit composition, custom rules, win conditions — and why each one serves the user's goal
-
[79]
updates": []`). Most workflows should result in zero updates. You may ONLY use the `
**How It Plays**: Briefly describe what a player would actually experience in this GDD and why that matches what the user asked for. Do NOT include: - Internal system details (agent names, validation loops, feedback rounds) - Technical implementation steps or debugging history - Repetitive restatements of the game description ## INPUTS [User's Original Qu...
-
[80]
A single error does NOT justify any change
**IDENTIFY PATTERNS**: Look for the SAME type of failure appearing across 2+ separate feedback entries. A single error does NOT justify any change
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.