Temporal Causal Prior-Data Fitted Networks for Panel Data with Learned Reliability Signals
Pith reviewed 2026-06-26 18:01 UTC · model grok-4.3
The pith
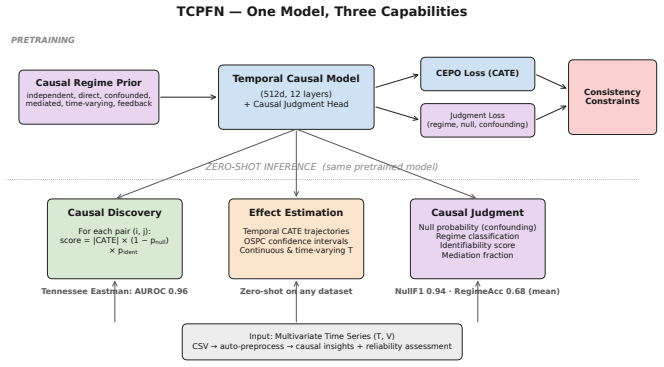
TCPFN performs zero-shot causal discovery on temporal panel data by training a foundation model on mixed causal regimes and outputs learned reliability signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
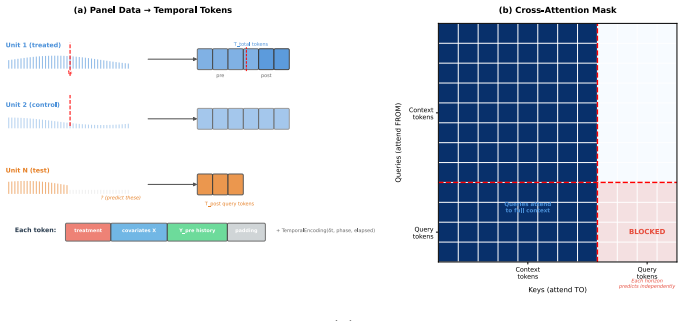
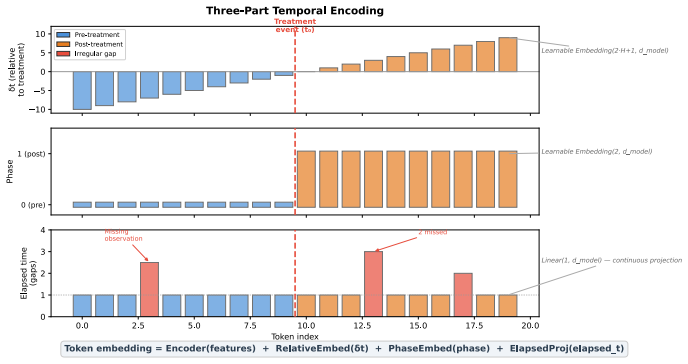
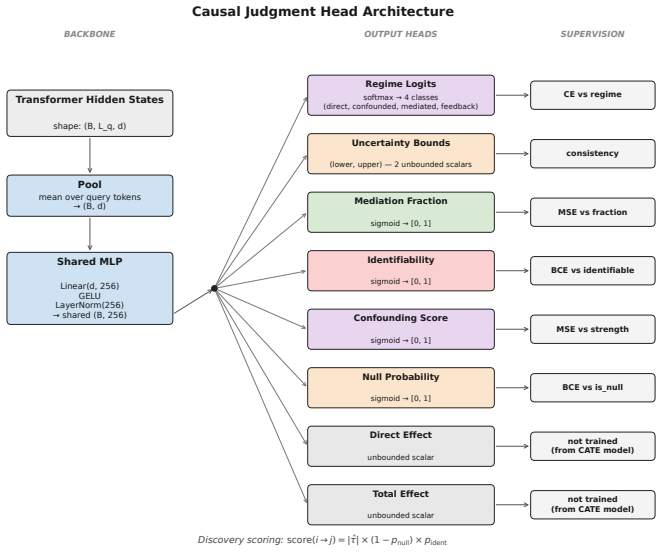
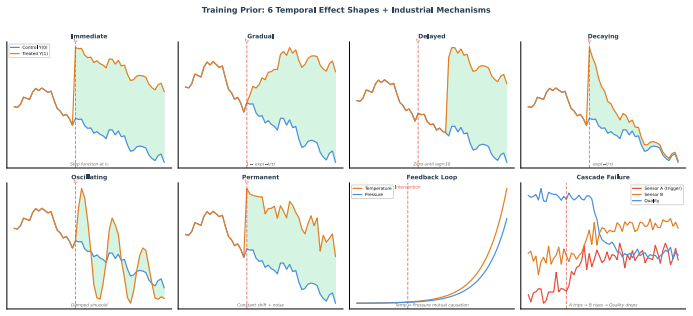
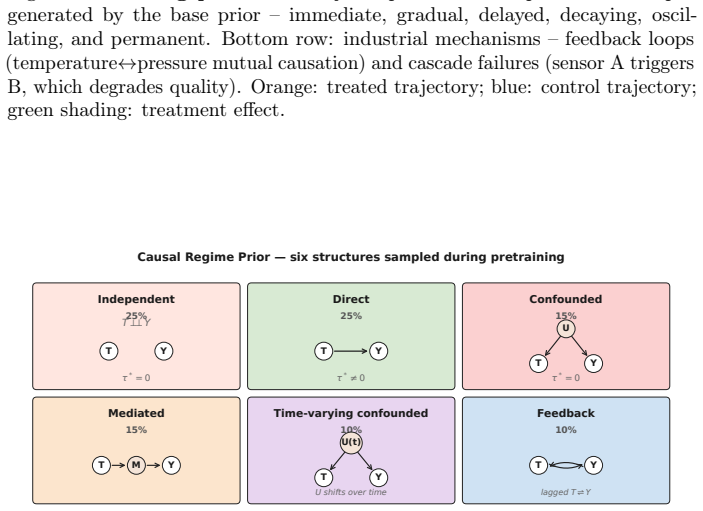
The central discovery is that a prior-data fitted network can be trained to jointly predict causal effects along with null-effect probability, confounding strength, identifiability, mediation, and regime type for temporal panel data in a zero-shot manner. This is achieved through a mixed training distribution covering multiple causal regimes and a discrete-token architecture that prevents inter-horizon leakage during inference.
What carries the argument
The Causal Judgment Head that jointly outputs several reliability and causal regime predictions, backed by the mixed causal regime training prior and the cross-attention masked panel architecture.
If this is right
- Causal discovery can be performed without per-dataset training or fine-tuning on new temporal data.
- The model provides explicit per-pair signals for reliability of the causal estimates.
- Large-scale industrial datasets with over a thousand variables can be processed in hours on a single GPU.
- Top identified causal edges can reveal cross-subsystem relationships in complex systems.
Where Pith is reading between the lines
- This suggests foundation models may become practical for causal tasks in domains with abundant but varied temporal data.
- The learned reliability signals could serve as a way to rank potential interventions for further study.
- Applying the same prior-data fitting idea to other causal problems like effect estimation under different assumptions could be explored.
Load-bearing premise
The collection of causal regimes used in training is broad enough to cover the structures present in unseen real-world industrial time series.
What would settle it
A new dataset from an industrial process whose causal structure falls outside the six regimes plus front-door and instrumental priors would show poor zero-shot performance if the claim holds.
Figures
read the original abstract
Estimating causal effects in industrial time series requires handling temporal dynamics, time-varying treatments, and unobserved confounders. Existing causal foundation models (CausalPFN, CausalFM) operate only on static cross-sectional data; neural temporal methods (CRN, G-Net) require per-dataset training; and concurrent temporal-PFN proposals have not been demonstrated at industrial scale. None output explicit per-pair reliability signals alongside their CATE estimates. We introduce Temporal Causal Prior-Data Fitted Networks (TCPFN), a foundation model for zero-shot temporal causal discovery with learned reliability signals. TCPFN makes four contributions: (1) a Causal Judgment Head that jointly predicts null-effect probability, confounding strength, identifiability, mediation fraction, and causal regime; (2) a mixed training prior covering six causal regimes (independent, direct, confounded, mediated, time-varying confounded, feedback) plus CausalFM-style front-door and instrumental-variable priors; (3) a discrete-token panel-data architecture with cross-attention masking that prevents inter-horizon leakage; (4) zero-shot inference at industrial scale via FAISS-based context selection and one-step posterior correction. On 19 benchmark datasets across five domains, TCPFN achieves competitive zero-shot causal discovery: AUROC 0.96 on Tennessee Eastman, 0.93 on SWaT, 0.98 on Causal Rivers, 0.97 on CAUSRCA. The null detector reaches NullF1 0.94, AUROC 0.99. TCPFN scales to V=1,275 on a proprietary Kraft pulp-and-paper dataset in 6 hours on a single GPU; PCMCI, a CPU-only library, on a V=666 sub-panel of the same data took 81.5 hours, extrapolating by O(V^2) to ~12.5 days at V=1,275. TCPFN's top edges identify cross-subsystem causal relationships while PCMCI's surface within-instrument controller-measurement coupling -- a scalability case study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Temporal Causal Prior-Data Fitted Networks (TCPFN), a foundation model for zero-shot temporal causal discovery on panel data. It trains on a mixed prior covering six causal regimes (independent, direct, confounded, mediated, time-varying confounded, feedback) plus CausalFM-style front-door and instrumental-variable priors, employs a discrete-token architecture with cross-attention masking to avoid inter-horizon leakage, and adds a Causal Judgment Head that jointly predicts null-effect probability, confounding strength, identifiability, mediation fraction, and causal regime. The model reports competitive zero-shot AUROCs on 19 benchmarks (0.96 on Tennessee Eastman, 0.93 on SWaT, 0.98 on Causal Rivers, 0.97 on CAUSRCA) with a null detector at NullF1 0.94 / AUROC 0.99, and scales to V=1,275 variables on a proprietary dataset in 6 GPU-hours versus PCMCI extrapolation to ~12.5 days.
Significance. If the zero-shot generalization holds, the work would be significant for industrial applications by enabling scalable causal discovery without per-dataset training or fine-tuning while also supplying explicit per-pair reliability signals. The scalability case study and the explicit multi-regime training prior are concrete strengths that address documented limitations of existing temporal causal methods.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): The headline AUROC numbers (0.96/0.93/0.98/0.97) are reported without error bars, number of runs, dataset exclusion rules, or full experimental protocol. This directly undermines verification that the data support the zero-shot and scaling claims.
- [§3] §3 (Training Prior): The zero-shot claim rests on the assumption that the six-regime plus front-door/IV synthetic prior produces posteriors that transfer to real industrial temporal statistics. No quantitative comparison of autocorrelation, cross-lag spectra, or identifiability properties between the generated training distribution and the benchmark panel data is provided, which is load-bearing for the central generalization result.
minor comments (2)
- [Figure captions and §4.3] Figure captions and §4.3: The scalability comparison would be clearer with an explicit statement of the O(V^2) extrapolation formula used for PCMCI and the exact sub-panel size (V=666) on which the 81.5-hour timing was measured.
- [§2] Notation in §2: The cross-attention masking mechanism that prevents inter-horizon leakage is described at a high level; a small pseudocode block or diagram would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting and validation of the training prior. We address each major comment below and will revise the manuscript to strengthen the presentation of results and generalization evidence.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The headline AUROC numbers (0.96/0.93/0.98/0.97) are reported without error bars, number of runs, dataset exclusion rules, or full experimental protocol. This directly undermines verification that the data support the zero-shot and scaling claims.
Authors: We agree that the absence of error bars, run counts, exclusion rules, and a complete protocol in §4 limits verifiability of the zero-shot AUROC and scaling results. In the revised manuscript we will expand §4 to report means and standard deviations over five independent runs with different random seeds, explicitly state dataset exclusion criteria (none applied beyond standard benchmark preprocessing), and provide the full experimental protocol including hyperparameter settings, context selection details, and hardware configuration for the scaling case study. revision: yes
-
Referee: [§3] §3 (Training Prior): The zero-shot claim rests on the assumption that the six-regime plus front-door/IV synthetic prior produces posteriors that transfer to real industrial temporal statistics. No quantitative comparison of autocorrelation, cross-lag spectra, or identifiability properties between the generated training distribution and the benchmark panel data is provided, which is load-bearing for the central generalization result.
Authors: The mixed prior is explicitly designed to span the six regimes plus front-door/IV structures that appear in industrial panel data. While the original submission relies on downstream benchmark performance as empirical support for transfer, we acknowledge that direct distributional comparisons would strengthen the argument. In revision we will add to §3 a quantitative comparison subsection reporting lag-1 autocorrelation, cross-lag spectral densities, and basic identifiability metrics (e.g., fraction of identifiable pairs) between 10,000 synthetic samples and the benchmark panels. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper's central results are zero-shot AUROC and NullF1 scores on independent benchmark datasets (Tennessee Eastman, SWaT, Causal Rivers, CAUSRCA) after training on an explicitly described mixed prior covering six regimes plus front-door/IV structures. No equations or steps in the abstract reduce these test metrics to fitted inputs, self-definitions, or self-citation chains; the architecture (discrete-token with cross-attention masking) and inference procedure are presented as design choices whose performance is measured externally rather than derived tautologically. The scaling comparison to PCMCI is likewise an empirical runtime observation. This is the standard non-circular case for a foundation-model empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Causalpfn: Prior-data fitted networks for treatment effect estimation.Advances in Neural Information Processing Systems, 2024
Vahid Balazadeh Meresht and Vasilis Syrgkanis. Causalpfn: Prior-data fitted networks for treatment effect estimation.Advances in Neural Information Processing Systems, 2024
2024
-
[2]
Estimating counterfactual treatment outcomes over time through adver- sarially balanced representations.International Conference on Learning Representations, 2020
Ioana Bica, Ahmed M Alaa, James Jordon, and Mihaela van der Schaar. Estimating counterfactual treatment outcomes over time through adver- sarially balanced representations.International Conference on Learning Representations, 2020
2020
-
[3]
Philip Boeken and Joris M. Mooij. Dynamic structural causal models. In UAI 2024 Workshop on Causal Inference for Time Series (CI4TS), 2024
2024
-
[4]
A plant-wide industrial process control problem.Computers & Chemical Engineering, 17(3):245–255, 1993
James J Downs and Ernest F Vogel. A plant-wide industrial process control problem.Computers & Chemical Engineering, 17(3):245–255, 1993
1993
-
[5]
Deep end-to-end causal inference.Advances in Neural Information Processing Systems, 2022
Tomas Geffner, George Papamakarios, and Andriy Mnih. Deep end-to-end causal inference.Advances in Neural Information Processing Systems, 2022. 28
2022
-
[6]
Investigating causal relations by econometric models and cross-spectral methods.Econometrica, 37(3):424–438, 1969
Clive WJ Granger. Investigating causal relations by econometric models and cross-spectral methods.Econometrica, 37(3):424–438, 1969
1969
-
[7]
Tabpfn: A transformer that solves small tabular classification problems in a second.International Conference on Learning Representations, 2023
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.International Conference on Learning Representations, 2023
2023
-
[8]
Improving regression performance with distributional losses.International Conference on Machine Learning, 2018
Ehsan Imani and Martha White. Improving regression performance with distributional losses.International Conference on Machine Learning, 2018
2018
-
[9]
Learning to induce causal structure.International Conference on Learning Representations, 2022
Nan Rosemary Ke, Silvia Chiappa, Jane Liao, Anirudh Goyal, Sungjin Ahn, and Jorg Bornschein. Learning to induce causal structure.International Conference on Learning Representations, 2022
2022
-
[10]
G-net: A recurrent network approach to g-computation for counterfactual prediction under a dynamic treatment regime.Machine Learning for Health, 2021
Rui Li, Stephanie Hu, Mingyu Lu, Yuria Utsumi, Prithwish Chakraborty, Daby Sow, Piyush Mack, Mohamed Ghalwash, et al. G-net: A recurrent network approach to g-computation for counterfactual prediction under a dynamic treatment regime.Machine Learning for Health, 2021
2021
-
[11]
Forecasting treatment responses over time using recurrent marginal structural networks
Bryan Lim, Ahmed M Alaa, and Mihaela van der Schaar. Forecasting treatment responses over time using recurrent marginal structural networks. Advances in Neural Information Processing Systems, 2018
2018
-
[12]
Amortized inference for causal structure learning.Advances in Neural Information Processing Systems, 2022
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Schölkopf. Amortized inference for causal structure learning.Advances in Neural Information Processing Systems, 2022
2022
-
[13]
Yuchen Ma, Dennis Frauen, Emil Javurek, and Stefan Feuerriegel. Foun- dation models for causal inference via prior-data fitted networks.arXiv preprint arXiv:2506.10914, 2026
arXiv 2026
-
[14]
Springer, 2003
Charles F Manski.Partial Identification of Probability Distributions. Springer, 2003
2003
-
[15]
Causal trans- former for estimating counterfactual outcomes.International Conference on Machine Learning, 2022
Valentyn Melnychuk, Dennis Frauen, and Stefan Feuerriegel. Causal trans- former for estimating counterfactual outcomes.International Conference on Machine Learning, 2022
2022
-
[16]
Valentyn Melnychuk, Vahid Balazadeh, Stefan Feuerriegel, and Rahul G Krishnan. Frequentist consistency of prior-data fitted networks for causal inference.arXiv preprint arXiv:2603.12037, 2026
Pith/arXiv arXiv 2026
-
[17]
Transformers can do bayesian inference.International Conference on Learning Representations, 2022
Samuel Müller, Noah Hollmann, Sebastian P Arango, Josif Grabocka, and Frank Hutter. Transformers can do bayesian inference.International Conference on Learning Representations, 2022
2022
-
[18]
Dynotears: Structure learning from time-series data
Roxana Pamfil, Nisara Sriwattanaworachai, Shaan Desai, Philip Pilger- storfer, Konstantinos Georgatzis, Paul Beaumont, and Bryon Aragam. Dynotears: Structure learning from time-series data. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2020. 29
2020
-
[19]
Cambridge University Press, 2nd edition, 2009
Judea Pearl.Causality: Models, Reasoning and Inference. Cambridge University Press, 2nd edition, 2009
2009
-
[20]
Do-pfn: In-context learning for causal effect estimation
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-pfn: In-context learning for causal effect estimation. InAdvances in Neural Information Processing Systems, 2025. Spotlight; arXiv:2506.06039
arXiv 2025
-
[21]
A new approach to causal inference in mortality studies with a sustained exposure period.Mathematical Modelling, 7:1393–1512, 1986
James Robins. A new approach to causal inference in mortality studies with a sustained exposure period.Mathematical Modelling, 7:1393–1512, 1986
1986
-
[22]
Marginal structural models and causal inference in epidemiology.Epidemiology, 11 (5):550–560, 2000
James M Robins, Miguel A Hernán, and Babette Brumback. Marginal structural models and causal inference in epidemiology.Epidemiology, 11 (5):550–560, 2000
2000
-
[23]
Springer, 2nd edition, 2002
Paul R Rosenbaum.Observational Studies. Springer, 2nd edition, 2002
2002
-
[24]
Detecting and quantifying causal associations in large nonlinear time series datasets.Science Advances, 5(11), 2019
Jakob Runge, Sebastian Bathiany, Erik Bollt, Gustau Camps-Valls, Dim Coumou, Ethan Deyle, Clark Glymour, Marlene Kretschmer, Miguel D Mahecha, Jordi Muñoz-Marí, et al. Detecting and quantifying causal associations in large nonlinear time series datasets.Science Advances, 5(11), 2019
2019
-
[25]
Causal protein-signaling networks derived from multipa- rameter single-cell data.Science, 308(5721):523–529, 2005
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multipa- rameter single-cell data.Science, 308(5721):523–529, 2005
2005
-
[26]
Interventional time series priors for causal foundation models
Dennis Thumm and Ying Chen. Interventional time series priors for causal foundation models. InICLR 2026 Workshop on Time Series in the Age of Large Models (TSALM), 2026. arXiv:2603.11090
Pith/arXiv arXiv 2026
-
[27]
Towards continuous- time causal foundation models.arXiv preprint arXiv:2605.28880, 2026
Dennis Thumm, Ruben Wiedemann, and Ying Chen. Towards continuous- time causal foundation models.arXiv preprint arXiv:2605.28880, 2026
Pith/arXiv arXiv 2026
-
[28]
Sensitivity analysis in observational research: Introducing the e-value.Annals of Internal Medicine, 167(4): 268–274, 2017
Tyler J VanderWeele and Peng Ding. Sensitivity analysis in observational research: Introducing the e-value.Annals of Internal Medicine, 167(4): 268–274, 2017
2017
-
[29]
DAG-GNN: DAG structure learning with graph neural networks.International Conference on Machine Learning, 2019
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. DAG-GNN: DAG structure learning with graph neural networks.International Conference on Machine Learning, 2019
2019
-
[30]
not null
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P Xing. DAGs with NO TEARS: Continuous optimization for structure learning.Advances in Neural Information Processing Systems, 2018. 30 A Appendix A.1 Evaluation Metrics We define all evaluation metrics used in this paper. A.1.1 Causal Discovery Metrics • F1@threshold:Harmonic mean of precision and recal...
2018
-
[31]
no effect
Independent: T⊥ ⊥Y. Treatment is randomly assigned with no confounding; true CATE= 0and the model must learn to predict “no effect.”
-
[32]
not validated against real- world causal time series
Direct: T→Y . Standard treatment-outcome with confounded assignment. True CATE̸=0. 3.Confounded:T←U→Y. Strong observed association (3×confounding), but true CATE= 0. 4.Mediated:T→M→Y. Effect flows through mediator. 5.Time-varying confounded:T←U(t)→Y. Time-varying confounders. 6.Feedback:T⇌Y(lagged). Bidirectional causation at different time lags. Sampling...
arXiv 1963
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.