PHF: Privileged Hidden Flow for On-Policy Self-Distillation
Pith reviewed 2026-06-30 07:23 UTC · model grok-4.3
The pith
Privileged Hidden Flow extends on-policy self-distillation by aligning hidden-state transition directions and trajectory geometry from a privileged teacher.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
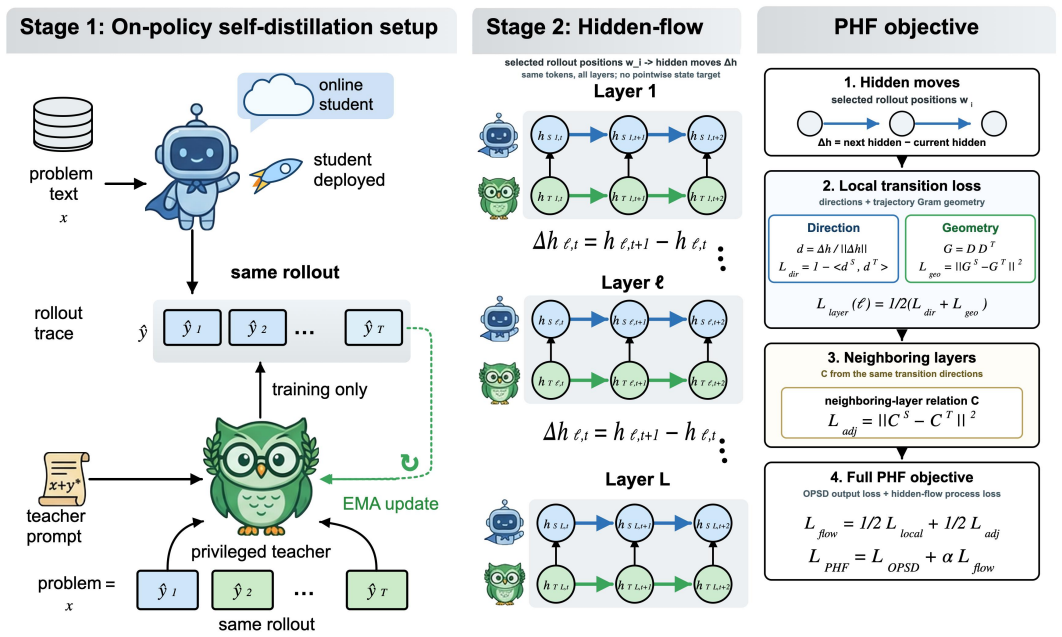
PHF distills how a privileged teacher's hidden states move along the same rollout by aligning token-to-token transition directions and trajectory geometry over selected generated positions, together with an adjacent-layer relation computed from those transitions, without any pointwise hidden-state imitation; the transport objective is invariant to shared offsets and the geometry term is invariant to orthogonal transformations of the directions.
What carries the argument
Privileged Hidden Flow (PHF) alignment of transition directions and trajectory geometry over generated positions, with adjacent-layer relations.
If this is right
- The transport objective stays exactly invariant to shared trajectory offsets.
- The local geometry term remains invariant to orthogonal transformations of the transition directions.
- Ablations separate the full PHF recipe from pointwise hidden-state matching, single-channel losses, and different layer subsets.
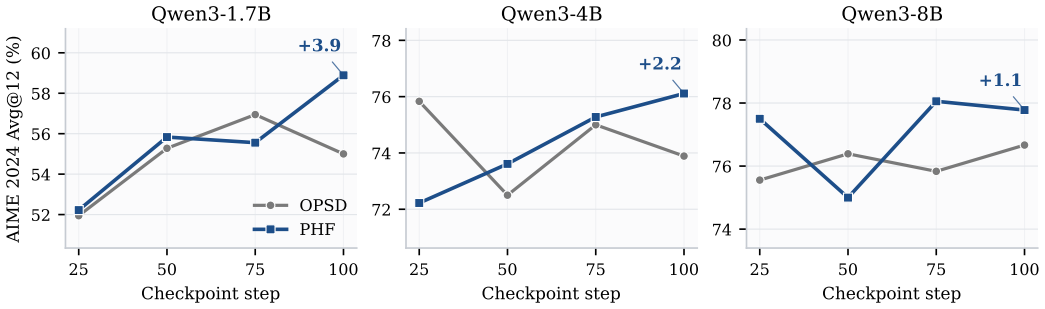
- Gains of roughly +2.2, +1.5, and +1.7 points appear on the Average@12 aggregate for the three tested model sizes.
Where Pith is reading between the lines
- The same transition-alignment idea could be tested in off-policy distillation settings where the teacher and student policies differ more substantially.
- Because the method never requires pointwise vector matching, it might tolerate larger architectural mismatches between teacher and student than conventional hidden-state distillation.
- If the geometry term captures useful structure, the approach could be combined with other rollout-based objectives that already operate on sequences of hidden states.
Load-bearing premise
That matching transition directions and trajectory geometry from the privileged teacher supplies useful extra supervision on internal computation beyond what output-distribution matching already provides.
What would settle it
Running the identical 100-step schedule on Qwen3-1.7B, 4B, or 8B and observing that the PHF variant produces no gain or a loss relative to the reproduced OPSD baseline would falsify the utility of the added hidden-flow terms.
Figures
read the original abstract
On-policy self-distillation (OPSD) trains a reasoning model on rollouts sampled from its own policy by matching a privileged teacher that also sees verified reference solutions. Existing OPSD objectives supervise only the output distribution, so privileged context affects training through a token-level divergence without directly supervising the internal computation that produced that distribution. We propose Privileged Hidden Flow (PHF), which additionally distills how a privileged teacher's hidden states move along the same rollout. Rather than forcing each student hidden vector to match the teacher vector at the same token position, PHF aligns token-to-token transition directions and trajectory geometry over selected generated positions. The all-layer recipe also includes an adjacent-layer relation computed from these same transitions, without pointwise hidden-state imitation. Under the same 100-step training schedule, PHF improves the Average@12 aggregate over our reproduced OPSD baseline on Qwen3-1.7B, 4B, and 8B, with observed gains of about +2.2, +1.5, and +1.7 points. The transport objective is exactly invariant to shared trajectory offsets; its local geometry term is also invariant to orthogonal transformations of transition directions. Ablations distinguish the fixed PHF recipe from pointwise hidden-state matching, single-channel transition losses, and layer-subset choices, supporting PHF as a compact hidden-flow extension to OPSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Privileged Hidden Flow (PHF) as an extension to on-policy self-distillation (OPSD) for reasoning models. Instead of supervising only output distributions via token-level KL divergence, PHF additionally aligns token-to-token transition directions and trajectory geometry of hidden states from a privileged teacher (with access to reference solutions) over selected generated positions from the student's rollout, plus an adjacent-layer relation term. The method is claimed to be exactly invariant to shared trajectory offsets and invariant to orthogonal transformations in its local geometry term. Under a fixed 100-step schedule, PHF yields observed gains of +2.2, +1.5, and +1.7 points on Average@12 versus a reproduced OPSD baseline on Qwen3-1.7B, 4B, and 8B models. Ablations are said to distinguish the full recipe from pointwise hidden-state matching, single-channel losses, and layer-subset variants.
Significance. If the reported gains prove robust and the transition/geometry alignment demonstrably supplies supervision on internal computation that is not reducible to the existing OPSD KL term, the approach would offer a compact, invariance-preserving way to distill privileged internal dynamics without pointwise hidden-state imitation. This could be relevant for scaling reasoning models where direct hidden-state matching is undesirable. The invariance properties, if formally derived and verified in the implementation, would be a positive theoretical feature.
major comments (2)
- [Abstract] Abstract: The central empirical claim reports gains of approximately +2.2, +1.5, and +1.7 points on Average@12 but provides no error bars, standard deviations across runs, number of independent trials, or explicit definition of the metric and data exclusion rules. This directly affects assessment of whether the improvements are statistically reliable and reproducible.
- [Abstract] Abstract: The claim that aligning transition directions and trajectory geometry 'supplies useful additional supervision on internal computation beyond token-level output divergence' is load-bearing for the contribution. Because positions are drawn from the student's own rollout and the teacher differs only by reference-solution access, the transport objective may largely encode information already captured by the OPSD KL term; the described ablations (pointwise matching, single-channel, layer-subset) do not appear to include a control that isolates this correlation (e.g., a non-privileged teacher or randomized transitions).
minor comments (1)
- [Abstract] Abstract: The phrase 'selected generated positions' is used without specifying the selection criterion or whether it is fixed before training or chosen post-hoc; a brief clarification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the empirical presentation and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim reports gains of approximately +2.2, +1.5, and +1.7 points on Average@12 but provides no error bars, standard deviations across runs, number of independent trials, or explicit definition of the metric and data exclusion rules. This directly affects assessment of whether the improvements are statistically reliable and reproducible.
Authors: We agree that the current presentation lacks sufficient detail on statistical reliability. The reported gains reflect single training runs under the fixed 100-step schedule. In revision we will perform multiple independent trials (different random seeds) and report means with standard deviations. We will also explicitly define Average@12 as the mean across the 12 evaluation benchmarks and state any data exclusion or filtering rules in both the abstract and experimental section. revision: yes
-
Referee: [Abstract] Abstract: The claim that aligning transition directions and trajectory geometry 'supplies useful additional supervision on internal computation beyond token-level output divergence' is load-bearing for the contribution. Because positions are drawn from the student's own rollout and the teacher differs only by reference-solution access, the transport objective may largely encode information already captured by the OPSD KL term; the described ablations (pointwise matching, single-channel losses, layer-subset) do not appear to include a control that isolates this correlation (e.g., a non-privileged teacher or randomized transitions).
Authors: The existing ablations show that full PHF outperforms both pointwise hidden-state matching and single-channel transition losses, indicating that the directional and geometric terms supply supervision not reducible to those simpler forms. Nevertheless, we acknowledge that the suggested controls (non-privileged teacher or randomized transitions) would more directly test whether the gains derive specifically from privileged internal dynamics rather than rollout correlation alone. We will add at least one such control ablation in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces PHF as an extension to OPSD by defining a transport objective on hidden-state transitions and adjacent-layer relations, then reports empirical gains on Qwen3 models under fixed training schedules. No equations appear in the provided text that reduce the claimed improvements or invariance properties to fitted parameters, self-referential quantities, or inputs by construction. The method is presented as an independent objective with stated invariances, and the central claim rests on experimental comparisons rather than a derivation that collapses to its own definitions or self-citations. The reader's assessment of score 2.0 aligns with this, as no load-bearing self-citation chains or ansatz smuggling are evident.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A privileged teacher sees verified reference solutions during the rollout.
invented entities (1)
-
Privileged Hidden Flow (PHF) objective
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author =. International Conference on Learning Representations (ICLR) , year =. 2306.13649 , archivePrefix =
-
[2]
2024 , eprint =
Gu, Yuxian and Dong, Li and Wei, Furu and Huang, Minlie , booktitle =. 2024 , eprint =
2024
-
[3]
International Conference on Machine Learning (ICML) , year =
DistiLLM: Towards Streamlined Distillation for Large Language Models , author =. International Conference on Machine Learning (ICML) , year =. 2402.03898 , archivePrefix =
-
[4]
2026 , eprint =
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author =. 2026 , eprint =
2026
-
[5]
2015 , eprint =
Distilling the Knowledge in a Neural Network , author =. 2015 , eprint =
2015
-
[6]
International Conference on Learning Representations (ICLR) , year =
FitNets: Hints for Thin Deep Nets , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
Patient Knowledge Distillation for
Sun, Siqi and Cheng, Yu and Gan, Zhe and Liu, Jingjing , booktitle =. Patient Knowledge Distillation for
-
[8]
Jiao, Xiaoqi and Yin, Yichun and Shang, Lifeng and Jiang, Xin and Chen, Xiao and Li, Linlin and Wang, Fang and Liu, Qun , booktitle =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Mean Teachers are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
SIAM Journal on Control and Optimization , volume =
Acceleration of Stochastic Approximation by Averaging , author =. SIAM Journal on Control and Optimization , volume =
-
[11]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[12]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Relational Knowledge Distillation , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[13]
International Conference on Learning Representations (ICLR) , year =
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
International Conference on Machine Learning (ICML) , year =
Born-Again Neural Networks , author =. International Conference on Machine Learning (ICML) , year =
-
[15]
2024 , eprint =
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. 2024 , eprint =
2024
-
[16]
2025 , eprint =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
2025
-
[17]
2023 , eprint =
Let's Verify Step by Step , author =. 2023 , eprint =
2023
-
[18]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurabh and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the
-
[19]
Journal of Machine Learning Research , volume =
Learning Using Privileged Information: Similarity Control and Knowledge Transfer , author =. Journal of Machine Learning Research , volume =
-
[20]
Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year =
Model Compression , author =. Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year =
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Do Deep Nets Really Need to be Deep? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[22]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Sequence-Level Knowledge Distillation , author =. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2016
-
[23]
International Conference on Learning Representations (ICLR) , year =
Contrastive Representation Distillation , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation , author =. IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[25]
Conference on Uncertainty in Artificial Intelligence (UAI) , year =
Averaging Weights Leads to Wider Optima and Better Generalization , author =. Conference on Uncertainty in Artificial Intelligence (UAI) , year =
-
[26]
International Conference on Learning Representations (ICLR) , year =
Temporal Ensembling for Semi-Supervised Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[27]
2017 , eprint =
Proximal Policy Optimization Algorithms , author =. 2017 , eprint =
2017
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[30]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[31]
2021 , eprint =
Training Verifiers to Solve Math Word Problems , author =. 2021 , eprint =
2021
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Solving Quantitative Reasoning Problems with Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[33]
International Journal of Computer Vision , volume =
Knowledge Distillation: A Survey , author =. International Journal of Computer Vision , volume =
-
[34]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[35]
IEEE/CVF International Conference on Computer Vision (ICCV) , year =
A Comprehensive Overhaul of Feature Distillation , author =. IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[36]
International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author =. International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[37]
, booktitle =
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D. , booktitle =
-
[38]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
2023
-
[39]
2022 , eprint =
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. 2022 , eprint =
2022
-
[40]
Math-Shepherd: Verify and Reinforce
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , booktitle =. Math-Shepherd: Verify and Reinforce
-
[41]
2024 , eprint =
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author =. 2024 , eprint =
2024
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Self-Distillation Amplifies Regularization in Hilbert Space , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[43]
2024 , eprint =
A Survey on Knowledge Distillation of Large Language Models , author =. 2024 , eprint =
2024
-
[44]
2024 , eprint =
Small Language Models: Survey, Measurements, and Insights , author =. 2024 , eprint =
2024
-
[45]
Sanh, Victor and Debut, Lysandre and Chaumond, Julien and Wolf, Thomas , booktitle =
-
[46]
2023 , eprint =
A Survey of Large Language Models , author =. 2023 , eprint =
2023
-
[47]
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models , author =. Transactions on Machine Learning Research (TMLR) , year =. 2312.06585 , archivePrefix =
-
[48]
Proceedings of the 36th International Conference on Machine Learning (ICML) , year =
Similarity of Neural Network Representations Revisited , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.