R2MED: A Benchmark for Reasoning-Driven Medical Retrieval
Pith reviewed 2026-05-22 13:48 UTC · model grok-4.3
The pith
R2MED benchmark shows current retrieval models achieve only 31.4 nDCG@10 on reasoning-intensive medical tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present R2MED, the first benchmark designed specifically for reasoning-driven medical retrieval. It features 876 queries across Q&A reference retrieval, clinical evidence retrieval, and clinical case retrieval, sourced from five medical scenarios and twelve body systems. Testing reveals that the strongest retrieval model reaches just 31.4 nDCG@10, while incorporating large reasoning models for intermediate inference generation improves results only up to 41.4 nDCG@10, highlighting the gap between existing methods and the demands of clinical reasoning.
What carries the argument
R2MED benchmark with its three tasks that require retrieving documents aligned with inferred diagnoses rather than direct lexical or semantic matches to symptoms.
Load-bearing premise
That the core challenge in medical retrieval stems from evidence matching an inferred diagnosis instead of the patient's reported symptoms, creating low overlap.
What would settle it
Development of a retrieval model that scores above 70 nDCG@10 across the R2MED tasks without relying on additional medical knowledge injection would challenge the identified gap.
Figures












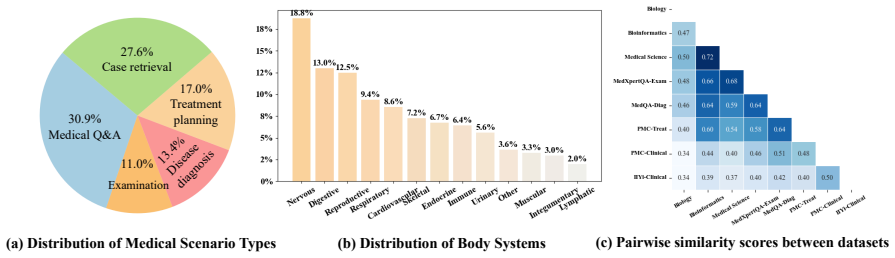

read the original abstract
Current medical retrieval benchmarks primarily emphasize lexical or shallow semantic similarity, overlooking the reasoning-intensive demands that are central to clinical decision-making. In practice, physicians often retrieve authoritative medical evidence to support diagnostic hypotheses. Such evidence typically aligns with an inferred diagnosis rather than the surface form of a patient's symptoms, leading to low lexical or semantic overlap between queries and relevant documents. To address this gap, we introduce R2MED, the first benchmark explicitly designed for reasoning-driven medical retrieval. It comprises 876 queries spanning three tasks: Q&A reference retrieval, clinical evidence retrieval, and clinical case retrieval. These tasks are drawn from five representative medical scenarios and twelve body systems, capturing the complexity and diversity of real-world medical information needs. We evaluate 15 widely-used retrieval systems on R2MED and find that even the best model achieves only 31.4 nDCG@10, demonstrating the benchmark's difficulty. Classical re-ranking and generation-augmented retrieval methods offer only modest improvements. Although large reasoning models improve performance via intermediate inference generation, the best results still peak at 41.4 nDCG@10. These findings underscore a substantial gap between current retrieval techniques and the reasoning demands of real clinical tasks. We release R2MED as a challenging benchmark to foster the development of next-generation medical retrieval systems with enhanced reasoning capabilities. Data and code are available at https://github.com/R2MED/R2MED
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces R2MED, a benchmark with 876 queries across three tasks (Q&A reference retrieval, clinical evidence retrieval, and clinical case retrieval) drawn from five medical scenarios and twelve body systems. It evaluates 15 retrieval systems and finds that even the best achieves only 31.4 nDCG@10, with large reasoning models reaching at most 41.4 nDCG@10 via intermediate inference generation, and claims this demonstrates a substantial gap between current techniques and the reasoning demands of real clinical tasks.
Significance. If the benchmark construction ensures that queries target inferred diagnoses with demonstrably low lexical/semantic overlap to gold documents, the work would be significant for medical IR by providing a challenging, reasoning-focused testbed that exposes limitations in lexical, semantic, and even reasoning-augmented retrieval. The release of data and code supports reproducibility and future work.
major comments (1)
- [§3] §3 (or equivalent section on query construction for the three tasks): The central interpretation that low nDCG@10 scores (31.4 baseline, 41.4 with reasoning models) specifically demonstrate unmet reasoning requirements rests on queries having low overlap with relevant documents because they target inferred diagnoses rather than surface symptoms. The manuscript does not report lexical/semantic overlap statistics, detail how queries were generated to start from diagnoses, or describe expert review confirming the mismatch. Without this, alternative explanations such as domain terminology, data sparsity, or general medical knowledge gaps cannot be ruled out.
minor comments (1)
- Provide more explicit details on the relevance judgment process and inter-annotator agreement to allow readers to calibrate the benchmark's difficulty and reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on R2MED. The concern about substantiating the low-overlap claim is well-taken, and we outline below how we will strengthen the manuscript while preserving the core contribution.
read point-by-point responses
-
Referee: [§3] §3 (or equivalent section on query construction for the three tasks): The central interpretation that low nDCG@10 scores (31.4 baseline, 41.4 with reasoning models) specifically demonstrate unmet reasoning requirements rests on queries having low overlap with relevant documents because they target inferred diagnoses rather than surface symptoms. The manuscript does not report lexical/semantic overlap statistics, detail how queries were generated to start from diagnoses, or describe expert review confirming the mismatch. Without this, alternative explanations such as domain terminology, data sparsity, or general medical knowledge gaps cannot be ruled out.
Authors: We agree that quantitative evidence of low lexical and semantic overlap would strengthen the central claim. In the revised manuscript we will expand §3 to include: (1) explicit description of the query-generation pipeline, in which medical experts first selected target diagnoses or clinical inferences from the source materials and then formulated queries that describe the preceding symptoms or presentation; (2) a table reporting average lexical overlap (token overlap, BM25 scores) and semantic overlap (cosine similarity of embeddings from a medical BERT model) between each query and its gold document(s), showing that the majority of pairs fall below the thresholds observed in existing medical IR benchmarks; and (3) a brief account of the expert review process, including the number of reviewers, their qualifications, and the criteria used to confirm that queries target inferred diagnoses rather than surface-level symptoms. These additions will help rule out alternative explanations such as domain terminology or data sparsity. We do not claim the new statistics will be exhaustive, but they will provide direct empirical support for the reasoning-driven nature of the benchmark. revision: yes
Circularity Check
No significant circularity in benchmark construction or performance claims
full rationale
R2MED is an empirical benchmark paper whose central results are nDCG@10 scores obtained by running 15 external retrieval systems on a curated set of 876 queries. These scores are computed directly from standard evaluation protocols applied to the released dataset; they do not reduce to any fitted parameter, self-defined quantity, or prior self-citation inside the paper. The motivating claim of low lexical/semantic overlap is presented as a design rationale for the three tasks rather than a derived prediction, and the benchmark itself is independently verifiable through the public data and code. No equations, ansatzes, or uniqueness theorems appear that would create a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption nDCG@10 is an appropriate metric for ranking quality in medical retrieval
Forward citations
Cited by 3 Pith papers
-
MMEB-V3: Measuring the Performance Gaps of Omni-Modality Embedding Models
MMEB-V3 benchmark shows omni-modality embedding models fail to enforce instruction-specified modality constraints and exhibit asymmetric, query-biased retrieval.
-
A Survey of Reasoning-Intensive Retrieval: Progress and Challenges
A survey that categorizes RIR benchmarks by domain and modality, proposes a taxonomy for integrating reasoning into retrieval pipelines, and outlines key challenges.
-
GroupRank: A Groupwise Paradigm for Effective and Efficient Passage Reranking with LLMs
GroupRank uses groupwise LLM reranking with answer-free data synthesis and a group-ranking reward to reach 65.2 NDCG@10 on BRIGHT while providing 6.4x faster inference than listwise baselines.
Reference graph
Works this paper leans on
-
[1]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator,
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. arXiv preprint arXiv:2402.09742. Giacomo Frisoni, Miki Mizutani, Gianluca Moro, and Lorenzo Valgimigli. 2022. Bioreader: a retrieval- enhanced text-to-text transformer for biomedical lit- erature. InProceedings of the 2022 conference on empirical methods in nat...
-
[2]
Precise zero-shot dense retrieval without relevance labels,
Precise zero-shot dense retrieval without rele- vance labels.arXiv preprint arXiv:2212.10496. Lorraine Goeuriot, Gareth JF Jones, Liadh Kelly, Hen- ning Müller, and Justin Zobel. 2016. Medical in- formation retrieval: introduction to the special issue. Information Retrieval Journal, 19:1–5. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande...
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Ruihui Hou, Shencheng Chen, Yongqi Fan, Lifeng Zhu, Jing Sun, Jingping Liu, and Tong Ruan. 2024. Msdi- agnosis: An emr-based dataset for clinical multi-step diagnosis.arXiv preprint arXiv:2408.10039. IIYi. 2026. Iiyi online consultation platform. https: //bingli.iiyi.com...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
Shuyang Jiang, Yusheng Liao, Zhe Chen, Ya Zhang, Yanfeng Wang, and Yu Wang
medikal: Integrating knowledge graphs as assistants of llms for enhanced clinical diagnosis on emrs.arXiv preprint arXiv:2406.14326. Shuyang Jiang, Yusheng Liao, Zhe Chen, Ya Zhang, Yanfeng Wang, and Yu Wang. 2025. Meds 3: To- wards medical slow thinking with self-evolved soft dual-sided process supervision.arXiv preprint arXiv:2501.12051. Bowen Jin, Hans...
-
[5]
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval.Bioinformatics, 39(11):btad651. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Effi- cient memory management for large language model serving w...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Latent Retrieval for Weakly Supervised Open Domain Question Answering
Latent retrieval for weakly supervised open domain question answering.arXiv preprint arXiv:1906.00300. Chaofan Li, Zheng Liu, Jianlyv Chen, Defu Lian, and Yingxia Shao. 2025a. Reinforced information re- trieval.arXiv preprint arXiv:2502.11562. Lei Li, Xiangxu Zhang, Xiao Zhou, and Zheng Liu
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[7]
Automir: Effective zero-shot medical informa- tion retrieval without relevance labels.arXiv preprint arXiv:2410.20050. Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025b. Search-o1: Agentic search- enhanced large reasoning models.arXiv preprint arXiv:2501.05366. 10 Jimmy Lin, Xueguang Ma, Sheng...
-
[8]
Pyserini: A python toolkit for reproducible information retrieval research with sparse and dense representations. InProceedings of the 44th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2356– 2362. Hao Liu, Zhengren Wang, Xi Chen, Zhiyu Li, Feiyu Xiong, Qinhan Yu, and Wentao Zhang. 2025a. Ho- pRAG: Multi-...
-
[9]
InProceedings of the 17th ACM conference on Information and knowledge management, pages 143–152
Medsearch: a specialized search engine for medical information retrieval. InProceedings of the 17th ACM conference on Information and knowledge management, pages 143–152. Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine-tuning llama for multi-stage text retrieval. InProceedings of the 47th Inter- national ACM SIGIR Conference on Rese...
-
[10]
Rodrigo Nogueira, Zhiying Jiang, and Jimmy Lin
Ms marco: A human-generated machine read- ing comprehension dataset. Rodrigo Nogueira, Zhiying Jiang, and Jimmy Lin. 2020. Document ranking with a pretrained sequence-to- sequence model.arXiv preprint arXiv:2003.06713. Rodrigo Nogueira, Wei Yang, Kyunghyun Cho, and Jimmy Lin. 2019. Multi-stage document ranking with bert.arXiv preprint arXiv:1910.14424. Op...
-
[11]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others
Quantifying the reasoning abilities of llms on real-world clinical cases.arXiv preprint arXiv:2503.04691. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Language models are unsupervised multitask learn- ers.OpenAI blog, 1(8):9. Stephen Robertson, Hugo Zaragoza, and 1 others. 2009. The probabilistic rel...
-
[12]
Bright: A realistic and challenging bench- mark for reasoning-intensive retrieval.arXiv preprint arXiv:2407.12883. 11 Qwen Team. 2024. Qwen2.5: A party of foundation models. Qwen Team. 2025a. Qwen3: Think deeper, act faster. Qwen Team. 2025b. Qwq-32b: Embracing the power of reinforcement learning. Nandan Thakur, Nils Reimers, Andreas Rücklé, Ab- hishek Sr...
-
[13]
World Scientific. Ran Xu, Wenqi Shi, Yue Yu, Yuchen Zhuang, Yanqiao Zhu, May D Wang, Joyce C Ho, Chao Zhang, and Carl Yang. 2024. Bmretriever: Tuning large language models as better biomedical text retrievers.arXiv preprint arXiv:2404.18443. Wen-wai Yim, Asma Ben Abacha, Yujuan Fu, Zhaoyi Sun, Fei Xia, Meliha Yetisgen-Yildiz, and Martin Krallinger. 2024. ...
-
[14]
for the Bioinformatics dataset. All docu- ments, from external webpages and Wikipedia, are segmented into smaller passages by sentence-level splitting and regrouped into chunks of approxi- mately 128 tokens. Clinical Evidence Retrieval DatasetsThe clini- cal evidence retrieval task comprises three datasets, each representing a critical stage in clinical d...
work page 2025
-
[15]
Examinations Recommendation (EXM): The question asks for the most appropriate diagnostic test or examination to confirm a suspected condition. The answer should be Laboratory Tests, Imaging Examinations, Endoscopic Examinations, or Other Examinations
-
[16]
Diagnostic Reasoning (DIA): The question asks for the most likely disease, syndrome, etiology, or functional disorder affecting the patient. The answer should be Disease Diagnosis, Syndrome Diagnosis, Etiological Diagnosis, or Functional Disorder Diagnosis
-
[17]
Treatment Planning (TRT): The question asks for the best treatment plan, including pharmacological, surgical, or preventive measures. The answer should be Pharmacological Treatment, Surgical Treatment, Other Therapies, and Preventive Measures. **Task:** For each given Question-Answer (QA) pair, determine the most appropriate classification from the three ...
-
[18]
Depth of Reasoning: The question should require deeper reasoning. If the question appears too simple, mark it as "Too Simple"
-
[19]
Unambiguous Correct Answer: The question must have a unique and unambiguous correct answer. If the question asks for "incorrect options" or allows for multiple correct answers, mark it as "Ambiguous Answer"
-
[20]
Open-Ended Reformulation Feasibility: The question should be suitable for reformatting into an open-ended format. If the question cannot be easily reformulated into an open-ended problem and a clear ground-truth answer, mark it as "Not Reformulatable"
-
[21]
Medical Entity as the Correct Answer: The correct answer must be a medical entity, such as a disease, drug, symptom, anatomical structure, laboratory test, imaging examination, or treatment method. If the correct option is an abstract concept, behavior, tool, or any non-medical entity, mark it as "Non-Medical Entity". For each question, provide one of the...
-
[22]
Remove the multiple-choice options from the original question
-
[23]
If the original question contains phrases like “Which of the following...”, rewrite it into a self-contained open-ended form, but only minimally modify the wording required to make it complete without the options. **Output Format:** Your output should follow the following format, do not output any additional content: - Open-ended Question: [your rewritten...
work page 2023
-
[24]
augments queries by incorporating poten- tial in-domain answers and prompting an LLM to rewrite the query in a retrieval-friendly form. For search-enhanced large reasoning models, we explore two recent approaches. Search-R1 (Jin et al., 2025) extends DeepSeek-R1 by employing reinforcement learning to enable the model to au- tonomously generate multiple se...
work page 2025
-
[25]
Patient Profile and Presentation: The patient is an 82-year-old woman with a history of moderate aortic stenosis and coronary artery disease (with a drug-eluting stent), currently on dual antiplatelet therapy (aspirin and clopidogrel). She presents with symptomatic hypotension and melena, which are suggestive of gastrointestinal bleeding
-
[26]
High-dose proton-pump inhibitors were started, and her bleeding stabilized
Initial Management: She was resuscitated with intravenous fluids and blood products. High-dose proton-pump inhibitors were started, and her bleeding stabilized. Upper and lower endoscopies were performed but did not reveal any bleeding source
-
[27]
Diagnostic Challenge: When both upper and lower endoscopies are unremarkable in a patient with suspected GI bleeding, the most likely source is the small bowel. The small bowel is not accessible via standard endoscopy, which is why further evaluation is necessary
-
[28]
Next Diagnostic Step: The next appropriate test for evaluating small bowel bleeding is video-capsule endoscopy. This non-invasive procedure allows visualization of the entire small intestine and can detect lesions like angioectasia, tumors, or other small-bowel abnormalities that could be causing occult bleeding
-
[29]
Final Answer: Video-capsule endoscopy
Conclusion:In summary, once upper and lower endoscopies are negative in a patient with GI bleeding, video-capsule endoscopy is the next best step in evaluation. Final Answer: Video-capsule endoscopy. Positive document (ID: wiki20220301en160_42780) Common reasons for using capsule endoscopy include diagnosis of unexplained bleeding, iron deficiency, or abd...
work page 2018
-
[30]
Achieve tumor volume reduction through neoadjuvant chemotherapy and interval debulking surgery
-
[31]
Prevent recurrence and extend progression-free survival through maintenance therapy. - Rationale: - The patient had advanced-stage ovarian cancer with extensive metastases requiring aggressive primary treatment using neoadjuvant chemotherapy followed by surgery. - Adjuvant chemotherapy was employed to further reduce residual disease. - Given the high cost...
-
[32]
This sets the stage for a disorder of sexual development
The patient is a 19-year-old with primary amenorrhea (no menstruation by age 15–16 is concerning). This sets the stage for a disorder of sexual development
-
[33]
The patient is phenotypically female with normal external female genitalia and breast development. Normal breasts indicate that estrogen is present, which often results from the aromatization of androgens
-
[34]
The development of this hair is dependent on androgens
The marked absence of pubic and axillary hair is an important clue. The development of this hair is dependent on androgens. This suggests there is a problem with androgen action despite normal or elevated androgen levels
-
[35]
These are later confirmed by ultrasonogra- phy to be immature testes
Bilateral palpable masses in the inguinal regions are identified on physical exam. These are later confirmed by ultrasonogra- phy to be immature testes. Finding testes in a patient with a female phenotype is a significant finding. ... Putting all this together: The patient has a 46,XY karyotype, presence of testes, normal breast development (due to aroma-...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.