Recognition: unknown
MMEB-V3: Measuring the Performance Gaps of Omni-Modality Embedding Models
Pith reviewed 2026-05-08 07:24 UTC · model grok-4.3
The pith
Multimodal embedding models cannot reliably enforce instructions to retrieve a target modality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using MMEB-V3 and OmniSET, the work shows that current full-modality embeddings often retrieve an unintended modality, that cross-modal performance is asymmetric and driven by query-modality bias, and that instruction-induced embedding shifts remain too weak or misdirected to produce reliable modality-aware retrieval.
What carries the argument
OmniSET tuples of semantically equivalent instances across modalities, which separate semantic similarity from modality-specific effects inside the MMEB-V3 benchmark.
If this is right
- Retrieval accuracy will remain limited by query-modality bias until models treat modality as an explicit constraint.
- Instruction tuning alone does not produce aligned shifts toward the requested modality.
- Benchmarks limited to partial modalities cannot reveal the full set of cross-modal asymmetries observed here.
- Agent-centric scenarios will inherit the same modality-selection errors unless the underlying embeddings improve.
Where Pith is reading between the lines
- Search or recommendation systems that mix modalities will continue to surface irrelevant results when users specify a preferred input type.
- Training objectives may need additional terms that penalize modality mismatch even when semantic similarity is high.
- Extending the same diagnostic tuples to new modalities or tasks would test whether the observed failures generalize beyond the current benchmark.
Load-bearing premise
That the constructed OmniSET tuples truly carry identical semantics across modalities with no leftover modality-specific cues that could explain the retrieval failures.
What would settle it
An embedding model that consistently retrieves the exact target modality named in the instruction on held-out OmniSET-style tests would contradict the reported gaps.
Figures











read the original abstract
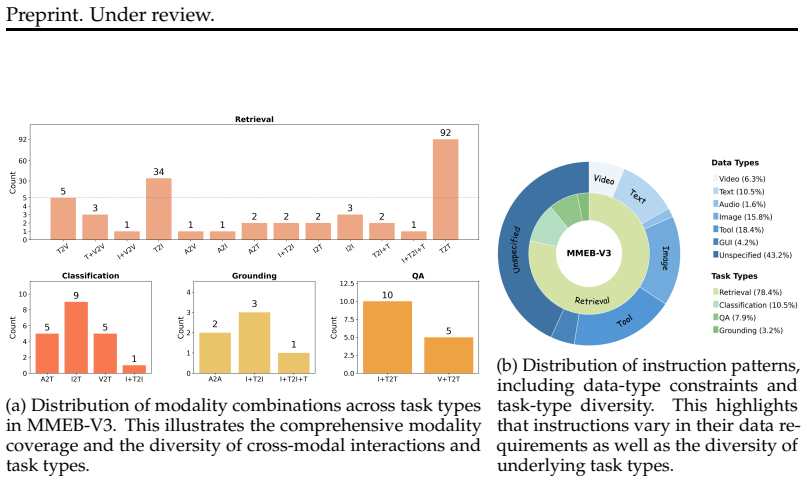
Multimodal embedding models aim to map heterogeneous inputs, such as text, images, videos, and audio, into a shared semantic space. However, existing methods and benchmarks remain largely limited to partial modality coverage, making it difficult to systematically evaluate full-modality representation learning. In this work, we take a step toward the full-modality setting. We introduce MMEB-V3, a comprehensive benchmark that evaluates embeddings across text, image, video, audio, as well as agent-centric scenarios. To enable more fine-grained diagnosis, we further construct OmniSET (Omni-modality Semantic Equivalence Tuples), where semantically equivalent instances are represented across modalities, allowing us to disentangle semantic similarity from modality effects. Through experiments on MMEB-V3, we conduct a systematic analysis of full-modality embeddings and identify three key findings: (1) models often fail to retrieve the intended target modality; (2) cross-modal retrieval is highly asymmetric and dominated by query-modality bias; and (3) instruction-induced shifts are either insufficient or misaligned with the target modality, and therefore do not reliably improve retrieval. These results indicate that current multimodal embeddings are not yet capable of reliably enforcing modality constraints specified by instructions, and consequently fail to exhibit consistent modality-aware retrieval behavior. We hope MMEB-V3 provides a useful benchmark for understanding and diagnosing these limitations, and for guiding future research on full-modality embeddings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMEB-V3, a benchmark for full-modality embedding models spanning text, image, video, audio, and agent scenarios. It constructs OmniSET (Omni-modality Semantic Equivalence Tuples) to represent semantically equivalent content across modalities, enabling separation of semantic similarity from modality effects. Experiments on MMEB-V3 yield three findings: models frequently fail to retrieve the intended target modality; cross-modal retrieval is asymmetric and dominated by query-modality bias; and instruction-induced embedding shifts are insufficient or misaligned with targets, failing to improve retrieval. The authors conclude that current omni-modality embeddings cannot reliably enforce instruction-specified modality constraints.
Significance. If the benchmark construction and empirical results hold, the work is significant for providing a systematic diagnostic tool for limitations in full-modality embeddings, an area of growing importance. The creation of MMEB-V3 and OmniSET represents a concrete contribution that can guide future research on modality-aware representations. The identification of specific failure modes (asymmetry, instruction misalignment) offers actionable insights beyond existing partial-modality benchmarks.
major comments (2)
- [Abstract and §3] Abstract and §3 (OmniSET construction): The assertion that OmniSET 'disentangle[s] semantic similarity from modality effects' is not backed by any quantitative verification such as human equivalence ratings, cue-ablation experiments, or cross-modal retrieval baselines on the tuples themselves. This is load-bearing for the central claim, because residual modality-specific cues (e.g., visual style, audio timbre, or trajectory statistics) could explain the reported retrieval failures and asymmetries without requiring the interpretation that models intrinsically fail to enforce modality constraints.
- [§4] §4 (Experiments and results): The three key findings are presented without reported dataset scales for MMEB-V3 or OmniSET, precise definitions of retrieval metrics across modalities, statistical significance tests for the observed asymmetries, or explicit controls for confounds such as data leakage or annotation quality. These omissions undermine assessment of whether the evidence robustly supports the conclusion that models 'fail to exhibit consistent modality-aware retrieval behavior.'
minor comments (1)
- [Abstract] Abstract: Consider adding one sentence on the approximate scale of MMEB-V3 and OmniSET to give readers immediate context for the strength of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on MMEB-V3 and OmniSET. The feedback identifies valid gaps in verification and reporting that we will address in revision. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (OmniSET construction): The assertion that OmniSET 'disentangle[s] semantic similarity from modality effects' is not backed by any quantitative verification such as human equivalence ratings, cue-ablation experiments, or cross-modal retrieval baselines on the tuples themselves. This is load-bearing for the central claim, because residual modality-specific cues (e.g., visual style, audio timbre, or trajectory statistics) could explain the reported retrieval failures and asymmetries without requiring the interpretation that models intrinsically fail to enforce modality constraints.
Authors: We agree that explicit quantitative verification of semantic equivalence would strengthen the disentanglement claim. OmniSET was constructed by selecting content from existing aligned multimodal datasets and applying manual curation to ensure semantic equivalence while varying modality. However, the current manuscript lacks human ratings or ablation studies. In the revised version we will add: (1) human equivalence ratings on a random subset of 200 tuples (three annotators per tuple, reporting inter-annotator agreement), and (2) simple cross-modal retrieval baselines (e.g., CLIP-style models) on the tuples themselves to quantify residual modality cues. These additions will directly test whether modality-specific signals remain after equivalence curation. revision: yes
-
Referee: [§4] §4 (Experiments and results): The three key findings are presented without reported dataset scales for MMEB-V3 or OmniSET, precise definitions of retrieval metrics across modalities, statistical significance tests for the observed asymmetries, or explicit controls for confounds such as data leakage or annotation quality. These omissions undermine assessment of whether the evidence robustly supports the conclusion that models 'fail to exhibit consistent modality-aware retrieval behavior.'
Authors: We acknowledge these reporting omissions. The revised manuscript will include: exact cardinalities for MMEB-V3 (train/test splits) and OmniSET (number of tuples per modality combination); precise metric definitions (e.g., modality-specific Recall@K with query-target modality pairs explicitly stated); paired statistical tests (Wilcoxon signed-rank with Bonferroni correction) for all reported asymmetries; and a dedicated paragraph on controls (train/test leakage checks via embedding similarity thresholds, annotation protocol with quality filters). These changes will allow readers to evaluate the robustness of the three findings without altering the experimental conclusions. revision: yes
Circularity Check
No significant circularity; purely empirical benchmark construction and measurement
full rationale
The paper constructs MMEB-V3 and OmniSET as new evaluation resources, then reports direct experimental measurements of embedding model behavior on them. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps. The central claims rest on observed retrieval failures and asymmetries in the new benchmark data, which are externally falsifiable via replication on the released tuples. This is the standard non-circular pattern for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantically equivalent instances can be represented across modalities without introducing confounding modality-specific signals
invented entities (2)
-
MMEB-V3 benchmark
no independent evidence
-
OmniSET
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Peerqa: A scientific question answering dataset from peer reviews, 2025
Tim Baumgärtner, Ted Briscoe, and Iryna Gurevych. Peerqa: A scientific question answering dataset from peer reviews, 2025. URL https://arxiv.org/abs/2502.13668
-
[2]
Crema-d: Crowd-sourced emotional multimodal actors dataset
Houwei Cao, David G Cooper, Michael K Keutmann, Ruben C Gur, Ani Nenkova, and Ragini Verma. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE transactions on affective computing, 5 0 (4): 0 377--390, 2014
2014
-
[3]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 736--740. IEEE, 2020
2020
-
[4]
Neural audio synthesis of musical notes with wavenet autoencoders, 2017
Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Douglas Eck, Karen Simonyan, and Mohammad Norouzi. Neural audio synthesis of musical notes with wavenet autoencoders, 2017
2017
-
[5]
Finevideo
Miquel Farré, Andi Marafioti, Lewis Tunstall, Leandro Von Werra, and Thomas Wolf. Finevideo. https://huggingface.co/datasets/HuggingFaceFV/finevideo, 2024
2024
-
[6]
Speech-coco: 600k visually grounded spoken captions aligned to mscoco data set
William Havard, Laurent Besacier, and Olivier Rosec. Speech-coco: 600k visually grounded spoken captions aligned to mscoco data set. arXiv preprint arXiv:1707.08435, 2017
-
[7]
Omniret: Efficient and high-fidelity omni modality retrieval, 2026
Chuong Huynh, Manh Luong, and Abhinav Shrivastava. Omniret: Efficient and high-fidelity omni modality retrieval, 2026. URL https://arxiv.org/abs/2603.02098
-
[8]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pp.\ 4904--4916. PMLR, 2021
2021
- [10]
-
[11]
Sophia Koepke, Andreea-Maria Oncescu, João F
A. Sophia Koepke, Andreea-Maria Oncescu, João F. Henriques, Zeynep Akata, and Samuel Albanie. Audio retrieval with natural language queries: A benchmark study. IEEE Transactions on Multimedia, 25: 0 2675–2685, 2023. ISSN 1941-0077. doi:10.1109/tmm.2022.3149712. URL http://dx.doi.org/10.1109/TMM.2022.3149712
-
[12]
Dong-Ho Lee, Adyasha Maharana, Jay Pujara, Xiang Ren, and Francesco Barbieri. Realtalk: A 21-day real-world dataset for long-term conversation, 2025. URL https://arxiv.org/abs/2502.13270
-
[13]
Jie Lei, Tamara L. Berg, and Mohit Bansal. Qvhighlights: Detecting moments and highlights in videos via natural language queries, 2021. URL https://arxiv.org/abs/2107.09609
-
[14]
R2MED: A Benchmark for Reasoning-Driven Medical Retrieval
Lei Li, Xiao Zhou, and Zheng Liu. R2med: A benchmark for reasoning-driven medical retrieval, 2025. URL https://arxiv.org/abs/2505.14558
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Chen Keqin, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review arXiv 2026
-
[16]
arXiv preprint arXiv:2411.02571 , year=
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms, 2025. URL https://arxiv.org/abs/2411.02571
-
[17]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. URL https://arxiv.org/abs/1405.0312
work page internal anchor Pith review arXiv 2015
-
[18]
M ulti C on IR : Towards multi-condition information retrieval
Xuan Lu, Sifan Liu, Bochao Yin, Yongqi Li, Xinghao Chen, Hui Su, Yaohui Jin, Wenjun Zeng, and Xiaoyu Shen. M ulti C on IR : Towards multi-condition information retrieval. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 13471--13494, Suzhou...
-
[19]
Tools are under-documented: Simple document expansion boosts tool retrieval
Xuan Lu, Haohang Huang, Rui Meng, Yaohui Jin, Wenjun Zeng, and Xiaoyu Shen. Tools are under-documented: Simple document expansion boosts tool retrieval. In The Fourteenth International Conference on Learning Representations, 2026 a . URL https://openreview.net/forum?id=g9D9MgG7iW
2026
-
[20]
Rethinking reasoning in document ranking: Why chain-of-thought falls short
Xuan Lu, Haohang Huang, Rui Meng, Yaohui Jin, Wenjun Zeng, and Xiaoyu Shen. Rethinking reasoning in document ranking: Why chain-of-thought falls short. In The Fourteenth International Conference on Learning Representations, 2026 b . URL https://openreview.net/forum?id=txmqENuRcc
2026
-
[21]
Beyond global similarity: Towards fine-grained, multi-condition multimodal retrieval, 2026 c
Xuan Lu, Kangle Li, Haohang Huang, Rui Meng, Wenjun Zeng, and Xiaoyu Shen. Beyond global similarity: Towards fine-grained, multi-condition multimodal retrieval, 2026 c . URL https://arxiv.org/abs/2603.01082
-
[22]
arXiv preprint arXiv:2505.17166 , year=
Quentin Macé, António Loison, and Manuel Faysse. Vidore benchmark v2: Raising the bar for visual retrieval, 2025. URL https://arxiv.org/abs/2505.17166
-
[23]
arXiv preprint arXiv:2507.04590 , year=
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, Yingbo Zhou, Wenhu Chen, and Semih Yavuz. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents, 2025. URL https://arxiv.org/abs/2507.04590
-
[24]
Tut database for acoustic scene classification and sound event detection
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. Tut database for acoustic scene classification and sound event detection. In 2016 24th European signal processing conference (EUSIPCO), pp.\ 1128--1132. IEEE, 2016
2016
-
[25]
MTEB: Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark, 2023. URL https://arxiv.org/abs/2210.07316
-
[26]
Esc: Dataset for environmental sound classification
Karol J Piczak. Esc: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, pp.\ 1015--1018, 2015
2015
-
[27]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision, pp.\ 2641--2649, 2015
2015
-
[28]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review arXiv 2021
-
[29]
A dataset and taxonomy for urban sound research
Justin Salamon, Christopher Jacoby, and Juan Pablo Bello. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM international conference on Multimedia, pp.\ 1041--1044, 2014
2014
-
[30]
BRIGHT : A realistic and challenging benchmark for reasoning-intensive retrieval
Hongjin SU, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han yu Wang, Liu Haisu, Quan Shi, Zachary S Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O Arik, Danqi Chen, and Tao Yu. BRIGHT : A realistic and challenging benchmark for reasoning-intensive retrieval. In The Thirteenth International Conference on Learning Representations, 202...
2025
-
[31]
Wave: Learning unified & versatile audio-visual embeddings with multimodal llm, 2025
Changli Tang, Qinfan Xiao, Ke Mei, Tianyi Wang, Fengyun Rao, and Chao Zhang. Wave: Learning unified & versatile audio-visual embeddings with multimodal llm, 2025. URL https://arxiv.org/abs/2509.21990
-
[32]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models, 2021. URL https://arxiv.org/abs/2104.08663
work page internal anchor Pith review arXiv 2021
-
[33]
Audio-visual event localization in unconstrained videos, 2018
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. Audio-visual event localization in unconstrained videos, 2018. URL https://arxiv.org/abs/1803.08842
-
[34]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition, 2018. URL https://arxiv.org/abs/1804.03209
work page Pith review arXiv 2018
-
[35]
Uniir: Training and benchmarking universal multimodal information retrievers
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Training and benchmarking universal multimodal information retrievers. arXiv preprint arXiv:2311.17136, 2023
-
[36]
Followir: Evaluating and teaching information retrieval models to follow instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and Luca Soldaini. Followir: Evaluating and teaching information retrieval models to follow instructions. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolo...
2025
-
[37]
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions
Tingyu Wu, Zhisheng Chen, Ziyan Weng, Shuhe Wang, Chenglong Li, Shuo Zhang, Sen Hu, Silin Wu, Qizhen Lan, Huacan Wang, and Ronghao Chen. Knowme-bench: Benchmarking person understanding for lifelong digital companions, 2026. URL https://arxiv.org/abs/2601.04745
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Omni-embed-nemotron: A unified multimodal retrieval model for text, image, audio, and video, 2025
Mengyao Xu, Wenfei Zhou, Yauhen Babakhin, Gabriel Moreira, Ronay Ak, Radek Osmulski, Bo Liu, Even Oldridge, and Benedikt Schifferer. Omni-embed-nemotron: A unified multimodal retrieval model for text, image, audio, and video, 2025. URL https://arxiv.org/abs/2510.03458
-
[39]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Gme: Improving universal multimodal retrieval by multimodal llms, 2025 a . URL https://arxiv.org/abs/2412.16855
work page internal anchor Pith review arXiv 2025
-
[40]
Universal retrieval for multimodal trajectory modeling
Xuan Zhang, Ziyan Jiang, Rui Meng, Yifei Leng, Zhenbang Xiao, Zora Zhiruo Wang, Yanyi Shang, and Dehan Kong. Universal retrieval for multimodal trajectory modeling. In ICML 2025 Workshop on Computer Use Agents, 2025 b
2025
- [41]
-
[42]
LMEB: Long-horizon Memory Embedding Benchmark
Xinping Zhao, Xinshuo Hu, Jiaxin Xu, Danyu Tang, Xin Zhang, Mengjia Zhou, Yan Zhong, Yao Zhou, Zifei Shan, Meishan Zhang, Baotian Hu, and Min Zhang. Lmeb: Long-horizon memory embedding benchmark, 2026. URL https://arxiv.org/abs/2603.12572
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Beyond content relevance: Evaluating instruction following in retrieval models
Jianqun Zhou, Yuanlei Zheng, Wei Chen, Qianqian Zheng, Shang Zeyuan, Wei Zhang, Rui Meng, and Xiaoyu Shen. Beyond content relevance: Evaluating instruction following in retrieval models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=OlRjxSuSwl
2025
-
[44]
Longembed: Extending embedding models for long context retrieval
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, and Sujian Li. Longembed: Extending embedding models for long context retrieval. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 802--816, 2024
2024
-
[45]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[46]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[47]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[48]
J]m | 3M6SL1 `֭N; ޤ Q4 t<묳q >d DF6I>T[ f v-֫ ?xj fڵ] bպFފ 8 Z
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.