FADPNet: Frequency-Aware Dual-Path Network for Face Super-Resolution
Pith reviewed 2026-05-19 09:53 UTC · model grok-4.3
The pith
A dual-path network processes low- and high-frequency facial features separately to improve super-resolution quality and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
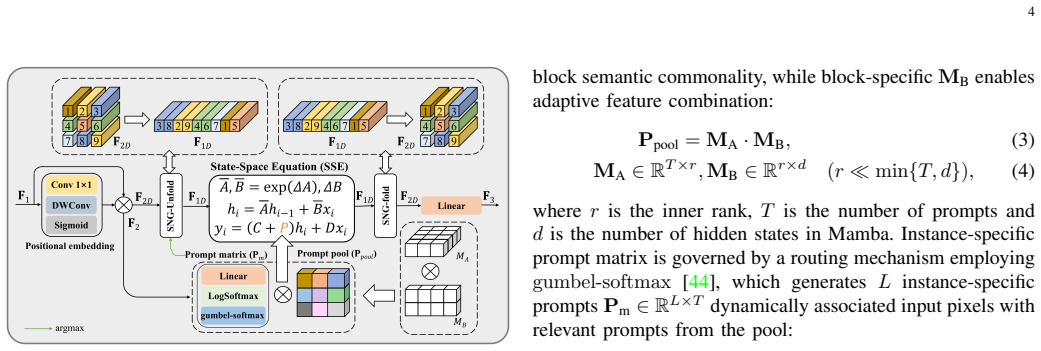
The authors claim that their Frequency-Aware Dual-Path Network, by routing low-frequency features through a Mamba-based Low-Frequency Enhancement Block incorporating state-space attention and squeeze-and-excitation, and high-frequency features through a CNN-based Deep Position-Aware Attention module followed by a High-Frequency Refinement module, achieves an improved trade-off between restoration quality and computational efficiency compared to existing approaches.
What carries the argument
The frequency-aware dual-path architecture that assigns low-frequency processing to Mamba and high-frequency to CNN modules.
If this is right
- Improved performance on face super-resolution benchmarks with reduced computational cost.
- More effective capture of both global facial attributes and local structural details.
- Potential for hybrid models that combine the strengths of state-space models and convolutional networks.
- Resource-efficient design suitable for deployment in real-time systems.
Where Pith is reading between the lines
- This separation strategy could be applied to other vision tasks involving both global context and fine details, such as image denoising or inpainting.
- Testing the network on diverse datasets with varying face poses and lighting could reveal the robustness of the frequency-based routing.
- Exploring adaptive frequency decomposition methods might further optimize the balance between the two paths.
Load-bearing premise
That dedicated processing of low-frequency attributes with Mamba and high-frequency features with CNN leads to better overall performance than uniform or single-model processing.
What would settle it
Demonstrating equivalent or superior results using a model that does not separate frequencies or uses only one architecture type on standard face super-resolution test sets.
Figures










read the original abstract
Face super-resolution (FSR) under limited computational budgets remains challenging. Existing methods often treat all facial pixels equally, leading to suboptimal resource allocation and degraded performance. CNNs are sensitive to high-frequency facial features such as contours and outlines, while Mamba excels at capturing low-frequency attributes like facial color and texture with lower complexity than Transformers. Motivated by this, we propose FADPNet, a Frequency-Aware Dual-Path Network that decomposes facial features into low- and high-frequency components for dedicated processing. The low-frequency branch employs a Mamba-based Low-Frequency Enhancement Block (LFEB) that integrates state-space attention with squeeze-and-excitation to restore global interactions and emphasize informative channels. The high-frequency branch uses a CNN-based Deep Position-Aware Attention (DPA) module to refine structural details, followed by a lightweight High-Frequency Refinement (HFR) module for further frequency-specific refinement. These designs enable FADPNet to achieve a strong balance between FSR quality and efficiency, outperforming existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FADPNet, a Frequency-Aware Dual-Path Network for face super-resolution under limited computational budgets. It decomposes facial features into low- and high-frequency components, processing the low-frequency branch with a Mamba-based Low-Frequency Enhancement Block (LFEB) that combines state-space attention and squeeze-and-excitation, and the high-frequency branch with a CNN-based Deep Position-Aware Attention (DPA) module followed by a lightweight High-Frequency Refinement (HFR) module. The authors claim this design achieves a superior balance between reconstruction quality and efficiency by exploiting the respective strengths of Mamba for global low-frequency attributes and CNNs for local high-frequency details, outperforming existing FSR methods.
Significance. If the empirical claims hold after proper validation, the work could offer a practical contribution to efficient face super-resolution by showing how explicit frequency decomposition allows better allocation of architectural inductive biases (Mamba for long-range low-frequency modeling, CNN for detail-oriented high-frequency refinement). The motivation grounded in differing frequency sensitivities is a clear strength, and the lightweight modules suggest potential applicability in resource-constrained settings.
major comments (2)
- [Ablation studies / Experiments] The central claim that explicit low/high-frequency decomposition plus Mamba-for-LF / CNN-for-HF assignment produces the reported gains is load-bearing, yet the manuscript does not isolate this factor. Ablation studies that swap the Mamba and CNN branches or compare against a dual-path baseline without frequency separation (while holding total compute fixed) are required to confirm that the frequency-aware split, rather than simply adding heterogeneous modules, drives the improvement.
- [Experimental results] Quantitative support for outperformance is not visible in the provided abstract and design description. The results section must report PSNR, SSIM, LPIPS, and efficiency metrics (FLOPs, parameters, runtime) with comparisons to recent FSR baselines, including error bars or statistical significance over multiple runs, to substantiate the efficiency-quality trade-off claim.
minor comments (2)
- [Method] Clarify the exact frequency decomposition operator (e.g., wavelet, Fourier, or learned filter) and how the split is performed at each scale in the network diagram or §3.
- [Method] Ensure consistent notation for the LFEB, DPA, and HFR modules across text, equations, and figures.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have reviewed the major comments carefully and outline our responses below, including planned revisions to strengthen the empirical validation of our claims.
read point-by-point responses
-
Referee: [Ablation studies / Experiments] The central claim that explicit low/high-frequency decomposition plus Mamba-for-LF / CNN-for-HF assignment produces the reported gains is load-bearing, yet the manuscript does not isolate this factor. Ablation studies that swap the Mamba and CNN branches or compare against a dual-path baseline without frequency separation (while holding total compute fixed) are required to confirm that the frequency-aware split, rather than simply adding heterogeneous modules, drives the improvement.
Authors: We agree that isolating the contribution of the explicit frequency decomposition and the Mamba/CNN assignment is essential to support the core motivation. In the revised manuscript we will add the requested ablations: (i) swapping the Mamba-based LFEB and CNN-based DPA modules between the low- and high-frequency branches, and (ii) a dual-path baseline that uses the same modules without frequency separation, with total FLOPs and parameters held constant. These experiments will be reported using the same evaluation protocol as the main results. revision: yes
-
Referee: [Experimental results] Quantitative support for outperformance is not visible in the provided abstract and design description. The results section must report PSNR, SSIM, LPIPS, and efficiency metrics (FLOPs, parameters, runtime) with comparisons to recent FSR baselines, including error bars or statistical significance over multiple runs, to substantiate the efficiency-quality trade-off claim.
Authors: The full manuscript contains a results section that already reports PSNR, SSIM, LPIPS, FLOPs, parameter counts, and runtime against recent FSR baselines. To address the concern directly, we will expand this section to make the metrics and comparisons more prominent, add error bars derived from multiple independent runs, and include a brief discussion of statistical significance where the variance permits. These additions will be incorporated in the revised version. revision: partial
Circularity Check
No circularity; design motivated by external inductive biases of Mamba and CNN
full rationale
The paper motivates its frequency decomposition and Mamba-for-LF / CNN-for-HF assignment by citing differing sensitivities of the architectures to low- versus high-frequency facial content. These properties are presented as known characteristics rather than results derived from the current model or its fitted parameters. No equations, self-definitions, or load-bearing self-citations reduce the central architectural claim to its own inputs by construction. The derivation remains self-contained against external benchmarks of architecture behavior.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decomposes facial features into low- and high-frequency components for dedicated processing with Mamba-based LFEB and CNN-based DPA plus HFR modules
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mamba excels at capturing low-frequency attributes ... with lower complexity than Transformers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Transformer-Progressive Mamba Network for Lightweight Image Super-Resolution
T-PMambaSR is a hybrid Transformer-Mamba architecture for lightweight image super-resolution that uses progressive scale interactions and high-frequency refinement to outperform prior methods at lower computational cost.
Reference graph
Works this paper leans on
-
[1]
Facenet: A unified embed- ding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embed- ding for face recognition and clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 815–823
work page 2015
-
[2]
Face alignment across large poses: A 3d solution,
X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li, “Face alignment across large poses: A 3d solution,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016, pp. 146–155
work page 2016
-
[3]
Hyperextended lightface: A facial attribute analysis framework,
S. I. Serengil and A. Ozpinar, “Hyperextended lightface: A facial attribute analysis framework,” in Proceedings of the International Con- ference on Engineering and Emerging Technologies (ICEET) . IEEE, 2021, pp. 1–4
work page 2021
-
[4]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2015, pp. 3730–3738
work page 2015
-
[5]
Image processing gnn: Breaking rigidity in super-resolution,
Y . Tian, H. Chen, C. Xu, and Y . Wang, “Image processing gnn: Breaking rigidity in super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 24 108–24 117
work page 2024
-
[6]
Rethinking image super resolution from long-tailed distribution learning perspective,
Y . Gou, P. Hu, J. Lv, H. Zhu, and X. Peng, “Rethinking image super resolution from long-tailed distribution learning perspective,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 14 327–14 336
work page 2023
-
[7]
Learning frequency-aware dynamic network for efficient super-resolution,
W. Xie, D. Song, C. Xu, C. Xu, H. Zhang, and Y . Wang, “Learning frequency-aware dynamic network for efficient super-resolution,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 4308–4317
work page 2021
-
[8]
Progressive face super- resolution via attention to facial landmark,
D. Kim, M. Kim, G. Kwon, and D.-S. Kim, “Progressive face super- resolution via attention to facial landmark,” in Proceedings of the 30th British Machine Vision Conference (BMVC) , 2019
work page 2019
-
[9]
Convolutional neural networks,
N. Ketkar, J. Moolayil, N. Ketkar, and J. Moolayil, “Convolutional neural networks,” Deep learning with Python: learn best practices of deep learning models with PyTorch , pp. 197–242, 2021
work page 2021
-
[10]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS) , 2017, pp. 5998–6008
work page 2017
-
[12]
Survey on deep face restoration: From non-blind to blind and beyond,
W. Li, M. Wang, K. Zhang, J. Li, X. Li, Y . Zhang, G. Gao, W. Deng, and C.-W. Lin, “Survey on deep face restoration: From non-blind to blind and beyond,” arXiv:2309.15490, 2023
-
[13]
Fsrnet: End-to-end learning face super-resolution with facial priors,
Y . Chen, Y . Tai, X. Liu, C. Shen, and J. Yang, “Fsrnet: End-to-end learning face super-resolution with facial priors,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018, pp. 2492–2501
work page 2018
-
[14]
C. Ma, Z. Jiang, Y . Rao, J. Lu, and J. Zhou, “Deep face super-resolution with iterative collaboration between attentive recovery and landmark estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2020, pp. 5569–5578. 12
work page 2020
-
[15]
Face super-resolution guided by 3d facial priors,
X. Hu, W. Ren, J. LaMaster, X. Cao, X. Li, Z. Li, B. Menze, and W. Liu, “Face super-resolution guided by 3d facial priors,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2020, pp. 763–780
work page 2020
-
[16]
Learning spatial attention for face super-resolution,
C. Chen, D. Gong, H. Wang, Z. Li, and K.-Y . K. Wong, “Learning spatial attention for face super-resolution,” IEEE Transactions on Image Processing, vol. 30, pp. 1219–1231, 2021
work page 2021
-
[17]
Towards realistic data generation for real-world super-resolution,
L. Peng, W. Li, R. Pei, J. Ren, J. Xu, Y . Wang, Y . Cao, and Z.-J. Zha, “Towards realistic data generation for real-world super-resolution,” in Proceedings of the International Conference on Learning Representa- tions (ICLR), 2025
work page 2025
-
[18]
Face hallucination via split-attention in split-attention network,
T. Lu, Y . Wang, Y . Zhang, Y . Wang, L. Wei, Z. Wang, and J. Jiang, “Face hallucination via split-attention in split-attention network,” in Proceedings of the ACM International Conference on Multimedia (ACM MM), 2021, pp. 5501–5509
work page 2021
-
[19]
Attention-driven graph neural network for deep face super-resolution,
Q. Bao, B. Gang, W. Yang, J. Zhou, and Q. Liao, “Attention-driven graph neural network for deep face super-resolution,” IEEE Transactions on Image Processing, vol. 31, pp. 6455–6470, 2022
work page 2022
-
[20]
Learning attention from attention: Efficient self-refinement transformer for face super-resolution
G. Li, J. Shi, Y . Zong, F. Wang, T. Wang, and Y . Gong, “Learning attention from attention: Efficient self-refinement transformer for face super-resolution.” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , 2023, pp. 1035–1043
work page 2023
-
[21]
Q. Bao, Y . Liu, B. Gang, W. Yang, and Q. Liao, “Sctanet: A spatial attention-guided cnn-transformer aggregation network for deep face image super-resolution,” IEEE Transactions on Multimedia, vol. 25, pp. 8554–8565, 2023
work page 2023
-
[22]
Spatial-frequency mutual learning for face super-resolution,
C. Wang, J. Jiang, Z. Zhong, and X. Liu, “Spatial-frequency mutual learning for face super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22 356–22 366
work page 2023
-
[23]
Efficient face super-resolution via wavelet-based feature enhancement network,
W. Li, H. Guo, X. Liu, K. Liang, J. Hu, Z. Ma, and J. Guo, “Efficient face super-resolution via wavelet-based feature enhancement network,” in Proceedings of the ACM International Conference on Multimedia (ACM MM), 2024, pp. 4515–4523
work page 2024
-
[24]
Ef- ficient image super-resolution with feature interaction weighted hybrid network,
W. Li, J. Li, G. Gao, W. Deng, J. Yang, G.-J. Qi, and C.-W. Lin, “Ef- ficient image super-resolution with feature interaction weighted hybrid network,” IEEE Transactions on Multimedia , vol. 27, pp. 2256–2267, 2025
work page 2025
-
[25]
Ctcnet: A cnn- transformer cooperation network for face image super-resolution,
G. Gao, Z. Xu, J. Li, J. Yang, T. Zeng, and G.-J. Qi, “Ctcnet: A cnn- transformer cooperation network for face image super-resolution,” IEEE Transactions on Image Processing , vol. 32, pp. 1978–1991, 2023
work page 1978
-
[26]
Swinir: Image restoration using swin transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “Swinir: Image restoration using swin transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2021, pp. 1833–1844
work page 2021
-
[27]
Cross-receptive focused inference network for lightweight image super- resolution,
W. Li, J. Li, G. Gao, W. Deng, J. Zhou, J. Yang, and G.-J. Qi, “Cross-receptive focused inference network for lightweight image super- resolution,” IEEE Transactions on Multimedia , vol. 26, pp. 864–877, 2023
work page 2023
-
[28]
Efficiently Modeling Long Sequences with Structured State Spaces
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,” arXiv preprint arXiv:2111.00396 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
J. Ma, F. Li, and B. Wang, “U-mamba: Enhancing long-range dependency for biomedical image segmentation,” arXiv preprint arXiv:2401.04722, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
L. Peng, X. Di, Z. Feng, W. Li, R. Pei, Y . Wang, X. Fu, Y . Cao, and Z.-J. Zha, “Directing mamba to complex textures: An efficient texture- aware state space model for image restoration,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , 2025
work page 2025
-
[31]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” in Proceedings of the European Conference on Computer Vision (ECCV) . Springer, 2024, pp. 222–241
work page 2024
-
[32]
Mamballie: Implicit retinex-aware low light enhancement with global-then-local state space,
J. Weng, Z. Yan, Y . Tai, J. Qian, J. Yang, and J. Li, “Mamballie: Implicit retinex-aware low light enhancement with global-then-local state space,” arXiv preprint arXiv:2405.16105 , 2024
-
[33]
Mambairv2: Attentive state space restoration,
H. Guo, Y . Guo, Y . Zha, Y . Zhang, W. Li, T. Dai, S.-T. Xia, and Y . Li, “Mambairv2: Attentive state space restoration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[34]
Frequency separation network for image super-resolution,
S. Li, Q. Cai, H. Li, J. Cao, L. Wang, and Z. Li, “Frequency separation network for image super-resolution,” IEEE Access , vol. 8, pp. 33 768– 33 777, 2020
work page 2020
-
[35]
Freqnet: A frequency-domain image super-resolution network with dicrete cosine transform,
R. Cai, Y . Ding, and H. Lu, “Freqnet: A frequency-domain image super-resolution network with dicrete cosine transform,” arXiv preprint arXiv:2111.10800, 2021
-
[36]
Freqformer: frequency-aware transformer for lightweight image super-resolution,
T. Dai, J. Wang, H. Guo, J. Li, J. Wang, and Z. Zhu, “Freqformer: frequency-aware transformer for lightweight image super-resolution,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2024, pp. 731–739
work page 2024
-
[37]
Dual-domain modu- lation network for lightweight image super-resolution,
W. Li, H. Guo, Y . Hou, G. Gao, and Z. Ma, “Dual-domain modu- lation network for lightweight image super-resolution,” arXiv preprint arXiv:2503.10047, 2025
-
[38]
Joint sub-bands learning with clique structures for wavelet domain super-resolution,
Z. Zhong, T. Shen, Y . Yang, Z. Lin, and C. Zhang, “Joint sub-bands learning with clique structures for wavelet domain super-resolution,” Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
work page 2018
-
[39]
High-frequency details enhancing densenet for super-resolution,
F. Zhou, X. Li, and Z. Li, “High-frequency details enhancing densenet for super-resolution,” Neurocomputing, vol. 290, pp. 34–42, 2018
work page 2018
-
[40]
Lightweight adaptive feature de-drifting for compressed image classification,
L. Peng, Y . Cao, Y . Sun, and Y . Wang, “Lightweight adaptive feature de-drifting for compressed image classification,” IEEE Transactions on Multimedia, vol. 26, pp. 6424–6436, 2024
work page 2024
-
[41]
Frequency-separated attention network for image super-resolution,
D. Qu, L. Li, and R. Yao, “Frequency-separated attention network for image super-resolution,”Applied Sciences, vol. 14, no. 10, p. 4238, 2024
work page 2024
-
[42]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Inter- vention (MICCAI). Springer, 2015, pp. 234–241
work page 2015
-
[43]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7132–7141
work page 2018
-
[44]
Categorical Reparameterization with Gumbel-Softmax
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,” arXiv preprint arXiv:1611.01144 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Camixersr: Only details need more
Y . Wang, Y . Liu, S. Zhao, J. Li, and L. Zhang, “Camixersr: Only details need more” attention”,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2024, pp. 25 837– 25 846
work page 2024
-
[46]
Interactive facial feature localization,
V . Le, J. Brandt, Z. Lin, L. Bourdev, and T. S. Huang, “Interactive facial feature localization,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2012, pp. 679–692
work page 2012
-
[47]
Restormer: Efficient transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5728–5739
work page 2022
-
[48]
An efficient latent style guided transformer-cnn framework for face super-resolution,
H. Qi, Y . Qiu, X. Luo, and Z. Jin, “An efficient latent style guided transformer-cnn framework for face super-resolution,” IEEE Transac- tions on Multimedia , vol. 26, pp. 1589–1599, 2024
work page 2024
-
[49]
Structure prior-aware dynamic network for face super-resolution,
C. Wang, J. Jiang, K. Jiang, and X. Liu, “Structure prior-aware dynamic network for face super-resolution,” IEEE Transactions on Biometrics, Behavior, and Identity Science , vol. 6, no. 3, pp. 326–340, 2024
work page 2024
-
[50]
Scface–surveillance cameras face database,
M. Grgic, K. Delac, and S. Grgic, “Scface–surveillance cameras face database,” Multimedia Tools and Applications , vol. 51, no. 3, pp. 863– 879, 2011
work page 2011
-
[51]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing , vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 586–595
work page 2018
-
[53]
Image information and visual quality,
H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” IEEE Transactions on Image Processing , vol. 15, no. 2, pp. 430–444, 2006
work page 2006
-
[54]
Image super- resolution using very deep residual channel attention networks,
Y . Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y . Fu, “Image super- resolution using very deep residual channel attention networks,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2018, pp. 286–301
work page 2018
-
[55]
Facial attribute capsules for noise face super resolution,
J. Xin, N. Wang, X. Jiang, J. Li, X. Gao, and Z. Li, “Facial attribute capsules for noise face super resolution,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , 2020, pp. 12 476–12 483
work page 2020
-
[56]
Bisenet: Bilateral segmentation network for real-time semantic segmentation,
C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang, “Bisenet: Bilateral segmentation network for real-time semantic segmentation,” in Proceedings of the European conference on computer vision (ECCV) , 2018, pp. 325–341
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.