Entanglement and Classical Simulability in Quantum Extreme Learning Machines
Pith reviewed 2026-05-18 17:50 UTC · model grok-4.3
The pith
Moderate entanglement from local XX dynamics boosts QELM classification accuracy while remaining classically simulable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
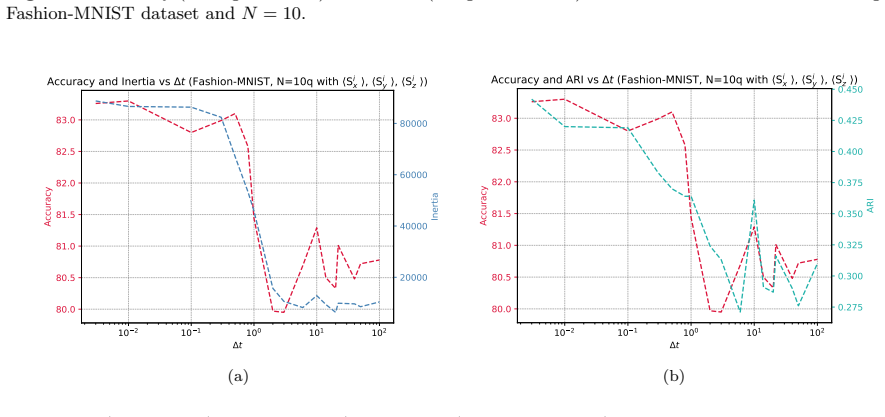
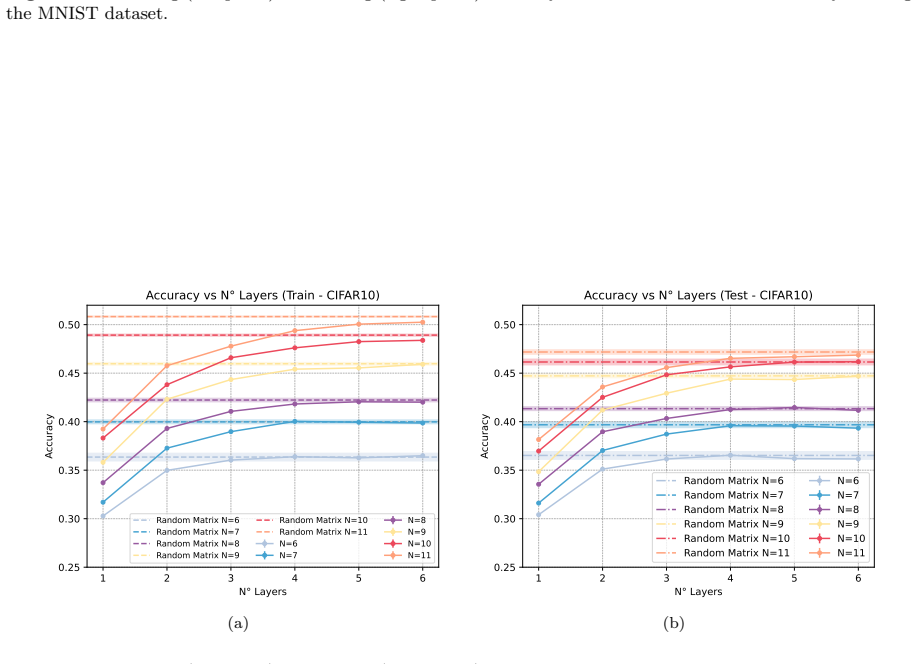
The central claim is that the increase in QELM performance correlates with the onset of entanglement under XX evolution, which improves the embedding of classical data in Hilbert space and produces more separable clusters in measurement probability space. For image classification tasks, this occurs at evolution times consistent with short-range information exchange that does not scale with system size, allowing the model to rely on limited entanglement while remaining classically simulable. The performance matches that achievable with maximally complex dynamics.
What carries the argument
Evolution under the XX Hamiltonian, which generates moderate short-range entanglement that structures the quantum feature representation for improved classical learnability.
If this is right
- Classification accuracy exhibits a sharp transition to high values upon the onset of entanglement.
- Saturated accuracy matches Haar-random unitary performance despite integrability of the XX model.
- More separable clusters form in measurement probability space due to the entanglement-enhanced embedding.
- The relevant evolution time remains independent of system size within tested scales, preserving classical simulability.
Where Pith is reading between the lines
- If this pattern holds, then entanglement level could be tuned as a design parameter to balance performance and simulation cost in quantum learning models.
- Classical simulation techniques focused on short-time local dynamics might replicate QELM benefits at larger scales.
- Other quantum machine learning architectures might similarly benefit from moderate entanglement for feature enhancement without full quantum advantage.
Load-bearing premise
The relevant evolution times remain independent of system size and the resulting limited entanglement continues to suffice for performance at scales beyond those numerically tested.
What would settle it
A demonstration that for larger qubit numbers the time to reach high accuracy scales with system size and generates entanglement that is no longer efficiently classically simulable would falsify the simulability claim.
Figures










read the original abstract
Quantum Machine Learning (QML) has emerged as a promising framework for exploring how quantum dynamics may enhance data processing tasks. Here we investigate Quantum Extreme Learning Machines (QELMs), a quantum analogue of classical Extreme Learning Machines in which training is restricted to the output layer. Our architecture combines dimensionality reduction (via PCA or Autoencoders), quantum state encoding, evolution under an XX Hamiltonian, and projective measurement to produce features for a classical single-layer classifier. By analyzing the classification accuracy as a function of evolution time, we observe a sharp transition between low- and high-accuracy regimes, followed by saturation. Remarkably, the saturated performance is comparable to that obtained using Haar-random unitaries that generate maximally complex dynamics, even though the XX model is integrable and local. Our results indicate that this increase in performance correlates with the onset of entanglement, which improves the embedding of classical data in Hilbert space and leads to more separable clusters in measurement probability space. Thus, moderate entanglement can contribute positively to the structure of the data representation, improving learnability without necessarily implying quantum computational advantage. For the image-classification tasks studied here, namely MNIST, Fashion-MNIST, and CIFAR-10, the relevant evolution time is consistent with information exchange over short distances and, within the explored system sizes, does not show evidence of scaling with the full system size. This suggests that QELM performance in this regime relies only on limited entanglement and remains compatible with efficient classical simulation. Our results clarify how local quantum dynamics and moderate quantum correlations are already sufficient to generate useful feature representations for learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines Quantum Extreme Learning Machines (QELMs) that encode classical image data (MNIST, Fashion-MNIST, CIFAR-10) via PCA or autoencoders, evolve the state under a local XX Hamiltonian, and extract features from projective measurements for a classical linear classifier. Numerical results show a sharp rise in classification accuracy with evolution time that saturates at values comparable to those obtained with Haar-random unitaries; this improvement correlates with the growth of entanglement entropy. The authors conclude that moderate, short-range entanglement suffices for useful feature maps and that the relevant evolution times remain independent of system size within the explored regimes, preserving classical simulability.
Significance. If the central numerical correlation holds and the limited-entanglement regime persists at scale, the work provides concrete evidence that local integrable dynamics can generate classically useful representations without requiring maximal entanglement or quantum advantage. The direct comparison to Haar-random unitaries and the explicit link to entanglement measures are strengths; the absence of free parameters in the core dynamical model further strengthens the result.
major comments (2)
- [Abstract and §4] Abstract and §4 (results on scaling): the statement that 'the relevant evolution time is consistent with information exchange over short distances and, within the explored system sizes, does not show evidence of scaling with the full system size' is load-bearing for the classical-simulability claim, yet no scaling collapse, finite-size extrapolation, or analytic light-cone argument is supplied to support independence of t_sat from N in the thermodynamic limit. If t_sat grows even logarithmically, entanglement volume could become extensive and undermine both the 'moderate entanglement' and 'efficient classical simulation' conclusions.
- [§3.2] §3.2 (entanglement and accuracy plots): the reported correlation between entanglement onset and accuracy saturation is supported by direct simulation, but the manuscript does not quantify how much of the performance gain is attributable to entanglement versus other dynamical features (e.g., spreading of local operators) that would also appear in a classical tensor-network simulation of the same short-time dynamics.
minor comments (2)
- [Abstract] Abstract: no error bars, statistical tests, or data-exclusion criteria are mentioned for the accuracy-versus-time curves.
- [§3] Figure captions and §3: clarify whether the reported entanglement measures are averaged over the training set or computed on a single representative state.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major comment below, indicating the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results on scaling): the statement that 'the relevant evolution time is consistent with information exchange over short distances and, within the explored system sizes, does not show evidence of scaling with the full system size' is load-bearing for the classical-simulability claim, yet no scaling collapse, finite-size extrapolation, or analytic light-cone argument is supplied to support independence of t_sat from N in the thermodynamic limit. If t_sat grows even logarithmically, entanglement volume could become extensive and undermine both the 'moderate entanglement' and 'efficient classical simulation' conclusions.
Authors: We agree that a more rigorous justification for the lack of N-dependence in t_sat would strengthen the classical-simulability claim. In the revised manuscript we will add a finite-size scaling analysis of t_sat(N) using the system sizes already simulated plus additional accessible sizes, together with an explicit light-cone argument based on the Lieb-Robinson bound for the XX Hamiltonian. This bound establishes a finite propagation velocity, implying that the time required for short-distance information exchange remains O(1) and independent of N. We will incorporate these elements into §4 and update the abstract accordingly. While a complete extrapolation to the thermodynamic limit lies beyond the present computational scope, the added analysis will better support our statements within the regimes explored. revision: yes
-
Referee: [§3.2] §3.2 (entanglement and accuracy plots): the reported correlation between entanglement onset and accuracy saturation is supported by direct simulation, but the manuscript does not quantify how much of the performance gain is attributable to entanglement versus other dynamical features (e.g., spreading of local operators) that would also appear in a classical tensor-network simulation of the same short-time dynamics.
Authors: We thank the referee for this observation. While the manuscript shows a clear temporal correlation between entanglement entropy growth and accuracy saturation, we acknowledge that the relative contribution of entanglement versus classical operator spreading has not been quantified. In the revision we will add a comparison of the XX-evolved features to those obtained from a classical tensor-network simulation of the identical short-time dynamics (e.g., via matrix-product states with controlled bond dimension). This will allow us to isolate the additional benefit arising from entanglement. The new discussion and any supporting plots will be placed in §3.2. revision: yes
Circularity Check
No circularity: claims rest on direct numerical simulation of XX dynamics and entanglement measures
full rationale
The paper's central results on accuracy saturation, correlation with entanglement onset, and limited scaling of relevant evolution time are obtained from explicit numerical simulations on MNIST, Fashion-MNIST, and CIFAR-10. The abstract states that performance increases correlate with entanglement and that, within explored sizes, the time 'does not show evidence of scaling with the full system size.' This is an empirical observation from the simulations rather than any equation that defines the output in terms of itself or renames a fitted parameter as a prediction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the architecture or conclusions. The derivation chain therefore remains independent of the target claims and is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard postulates of quantum mechanics govern unitary evolution under the XX Hamiltonian and projective measurements.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the required evolution time corresponds to information exchange among nearest neighbors and is independent of the system size... limited entanglement and remains classically simulable
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Theory and interpretability of Quantum Extreme Learning Machines: a Pauli-transfer matrix approach
A Pauli-transfer-matrix analysis of QELMs reveals the full set of nonlinear Pauli features generated by encoding and transformed by quantum channels, producing an interpretable classical nonlinear vector autoregressio...
-
Optimal quantum reservoir learning in proximity to universality
A tunable mixing parameter p in random quantum circuits controls the transition from classically simulable to expressive quantum reservoir dynamics via entanglement and nonstabilizer content.
Reference graph
Works this paper leans on
-
[1]
Simulating physics with com- puters,
R. P. Feynman, “Simulating physics with com- puters,”International journal of theoretical physics, vol. 21, no. 6/7, pp. 467–488, 1982
work page 1982
-
[2]
Quantum algorithms: an overview,
A. Montanaro, “Quantum algorithms: an overview,”npj Quantum Information, vol. 2, Jan. 2016
work page 2016
-
[3]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, 2010
work page 2010
-
[4]
Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,
P. W. Shor, “Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,”SIAM Journal on Computing, vol. 26, no. 5, pp. 1484–1509, 1997
work page 1997
-
[5]
Quan- tum supremacy using a programmable su- perconducting processor,
F. Arute, K. Arya, R. Babbush, D. Bacon, J. Bardin, R. Barends, R. Biswas, S. Boixo, F. Brandao, D. Buell, B. Burkett, Y. Chen, J. Chen, B. Chiaro, R. Collins, W. Court- ney, A. Dunsworth, E. Farhi, B. Foxen, A. Fowler, C. M. Gidney, M. Giustina, 14 R. Graff, K. Guerin, S. Habegger, M. Har- rigan, M. Hartmann, A. Ho, M. R. Hoff- mann, T. Huang, T. Humble,...
work page 2019
-
[6]
Quantum computational advantage using photons,
H.-S. Zhonget al., “Quantum computational advantage using photons,”Science, vol. 370, no. 6523, pp. 1460–1463, 2020
work page 2020
-
[7]
Quantum advantage in learning from experiments,
H.-Y. Huanget al., “Quantum advantage in learning from experiments,”Science, vol. 376, no. 6598, p. abn7293, 2022
work page 2022
-
[8]
Quantum Computing in the NISQ era and beyond,
J. Preskill, “Quantum Computing in the NISQ era and beyond,”Quantum, vol. 2, p. 79, 2018
work page 2018
-
[9]
J. Biamonte, P. Wittek, N. Pancotti, P. Reben- trost, N. Wiebe, and S. Lloyd, “Quantum ma- chine learning,”Nature, vol. 549, no. 7671, pp. 195–202, 2017
work page 2017
-
[10]
M. Schuld and F. Petruccione,Machine Learn- ing with Quantum Computers. Springer, 01 2021
work page 2021
-
[11]
M. Schuld and F. Petruccione,Supervised Learning with Quantum Computers. Quan- tum Science and Technology, Springer, 2018
work page 2018
-
[12]
Quan- tum convolutional neural networks,
I. Cong, S. Choi, and M. Lukin, “Quan- tum convolutional neural networks,”Nature Physics, vol. 15, pp. 1–6, 12 2019
work page 2019
-
[13]
Z. Liu, P.-X. Shen, W. Li, L. M. Duan, and D.- L. Deng, “Quantum capsule networks,”Quan- tum Sci. Technol., vol. 8, no. 1, p. 015016, 2023
work page 2023
-
[14]
The quest for a quantum neural network,
M. Schuld, I. Sinayskiy, and F. Petruccione, “The quest for a quantum neural network,” Quantum Information Processing, vol. 13, 08 2014
work page 2014
-
[15]
Supervised learning with quantum-enhanced feature spaces,
V. Havlicek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum-enhanced feature spaces,”Nature, vol. 567, pp. 209–212, 2019
work page 2019
-
[16]
Quantum algorithms for supervised and unsu- pervised machine learning,
S. Lloyd, M. Mohseni, and P. Rebentrost, “Quantum algorithms for supervised and unsu- pervised machine learning,” 7 2013
work page 2013
-
[17]
Assessing quan- tum computing performance for energy opti- mization in a prosumer community,
C. Mastroianni, F. Plastina, L. Scarcello, J. Settino, and A. Vinci, “Assessing quan- tum computing performance for energy opti- mization in a prosumer community,”IEEE Transactions on Smart Grid, vol. 15, no. 1, pp. 444–456, 2023
work page 2023
-
[18]
Variational quantum algorithms for the allocation of resources in a cloud/edge ar- chitecture,
C. Mastroianni, F. Plastina, J. Settino, and A. Vinci, “Variational quantum algorithms for the allocation of resources in a cloud/edge ar- chitecture,”IEEE Transactions on Quantum Engineering, vol. 5, pp. 1–18, 2024
work page 2024
-
[19]
Vari- ational gibbs state preparation on noisy intermediate-scale quantum devices,
M. Consiglio, J. Settino, A. Giordano, C. Mas- troianni, F. Plastina, S. Lorenzo, S. Manis- calco, J. Goold, and T. J. Apollaro, “Vari- ational gibbs state preparation on noisy intermediate-scale quantum devices,”Phys- ical Review A, vol. 110, no. 1, p. 012445, 2024
work page 2024
-
[20]
State estima- tion with quantum extreme learning machines beyond the scrambling time,
M. Vetrano, G. Lo Monaco, L. Innocenti, S. Lorenzo, and G. M. Palma, “State estima- tion with quantum extreme learning machines beyond the scrambling time,” 9 2024
work page 2024
-
[21]
Opportunities in quantum reservoir computing and extreme learning machines,
P. Mujal, R. Mart´ ınez-Pe˜ na, J. Nokkala, J. Garc´ ıa-Beni, G. Giorgi, M. Soriano, and R. Zambrini, “Opportunities in quantum reservoir computing and extreme learning machines,”Advanced Quantum Technologies, vol. 4, 06 2021
work page 2021
-
[22]
Po- tential and limitations of quantum extreme learning machines,
L. Innocenti, S. Lorenzo, I. Palmisano, A. Fer- raro, M. Paternostro, and G. M. Palma, “Po- tential and limitations of quantum extreme learning machines,”Communications Physics, vol. 6, p. 118, May 2023
work page 2023
-
[23]
On fundamental aspects of quantum extreme learning machines,
W. Xiong, G. Facelli, M. Sahebi, O. Agnel, T. Chotibut, S. Thanasilp, and Z. Holmes, “On fundamental aspects of quantum extreme learning machines,” 12 2023
work page 2023
-
[24]
Quantum Extreme Reservoir Computation Utilizing Scale-Free Networks,
A. Sakurai, M. P. Estarellas, W. J. Munro, and K. Nemoto, “Quantum Extreme Reservoir Computation Utilizing Scale-Free Networks,” Phys. Rev. Applied, vol. 17, no. 6, p. 064044, 2022
work page 2022
-
[25]
Effective quantum feature maps in quantum extreme reservoir computation 15 from the XY model,
A. Hayashi, A. Sakurai, W. J. Munro, and K. Nemoto, “Effective quantum feature maps in quantum extreme reservoir computation 15 from the XY model,”Phys. Rev. A, vol. 111, no. 2, p. 022431, 2025
work page 2025
-
[26]
Harnessing quantum extreme learning machines for image classi- fication,
A. De Lorenzis, M. P. Casado, M. P. Estarel- las, N. L. Gullo, T. Lux, F. Plastina, A. Ri- era, and J. Settino, “Harnessing quantum extreme learning machines for image classi- fication,”Phys. Rev. Applied, vol. 23, no. 4, p. 044024, 2025
work page 2025
-
[27]
Ex- perimental property reconstruction in a pho- tonic quantum extreme learning machine,
A. Suprano, D. Zia, L. Innocenti, S. Lorenzo, V. Cimini, T. Giordani, I. Palmisano, E. Polino, N. Spagnolo, F. Sciarrino, G. M. Palma, A. Ferraro, and M. Paternostro, “Ex- perimental property reconstruction in a pho- tonic quantum extreme learning machine,” Phys. Rev. Lett., vol. 132, p. 160802, Apr 2024
work page 2024
-
[28]
Large-scale quantum reservoir learning with an analog quantum computer,
M. Kornjaˇ caet al., “Large-scale quantum reservoir learning with an analog quantum computer,” 7 2024
work page 2024
-
[29]
Temporal information processing on noisy quantum computers,
J. Chen, H. I. Nurdin, and N. Yamamoto, “Temporal information processing on noisy quantum computers,”Phys. Rev. Appl., vol. 14, p. 024065, Aug 2020
work page 2020
-
[30]
Harnessing Quan- tum Dynamics for Robust and Scalable Quan- tum Extreme Learning Machines,
P. D. Solanki and A. Pham, “Harnessing Quan- tum Dynamics for Robust and Scalable Quan- tum Extreme Learning Machines,” 3 2025
work page 2025
-
[31]
Extreme learning machine: a new learning scheme of feedforward neural networks,
G.-B. Huang, Q.-Y. Zhu, and C.-K. Siew, “Extreme learning machine: a new learning scheme of feedforward neural networks,” in 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), vol. 2, pp. 985–990 vol.2, 2004
work page 2004
-
[32]
Trends in extreme learning machines: A re- view,
G. Huang, G.-B. Huang, S. Song, and K. You, “Trends in extreme learning machines: A re- view,”Neural Networks, vol. 61, pp. 32–48, 2015
work page 2015
-
[33]
Extreme learning machine: algorithm, theory and applications,
S. Ding, H. Zhao, Y. Zhang, X. Xu, and R. Nie, “Extreme learning machine: algorithm, theory and applications,”Artif. Intell. Rev., vol. 44, p. 103–115, June 2015
work page 2015
-
[34]
A review on extreme learning machine,
J. Wang, S. Lu, S.-H. Wang, and Y.-D. Zhang, “A review on extreme learning machine,”Mul- timedia Tools and Applications, vol. 81, no. 29, pp. 41611–41660, 2022
work page 2022
-
[35]
Extreme learning machines: a survey. int j mach learn cybern,
G.-B. Huang, D. Wang, and Y. Lan, “Extreme learning machines: a survey. int j mach learn cybern,”International Journal of Machine Learning and Cybernetics, vol. 2, pp. 107–122, 06 2011
work page 2011
-
[36]
Simple hamiltonian dynamics as a powerful resource for image classification,
A. Sakurai, A. Hayashi, W. J. Munro, and K. Nemoto, “Simple hamiltonian dynamics as a powerful resource for image classification,” Phys. Rev. A, vol. 111, p. 052432, May 2025
work page 2025
-
[37]
Impact of the form of weighted networks on the quantum extreme reservoir computation,
A. Hayashi, A. Sakurai, S. Nishio, W. J. Munro, and K. Nemoto, “Impact of the form of weighted networks on the quantum extreme reservoir computation,”Phys. Rev. A, vol. 108, no. 4, p. 042609, 2023
work page 2023
-
[38]
Harnessing disordered-ensemble quantum dynamics for machine learning,
K. Fujii and K. Nakajima, “Harnessing disordered-ensemble quantum dynamics for machine learning,”Physical Review Applied, vol. 8, p. 024030, 8 2017
work page 2017
-
[39]
Reservoir computing approach to quantum state measurement,
G. Angelatos, S. A. Khan, and H. E. T¨ ureci, “Reservoir computing approach to quantum state measurement,”Phys. Rev. X, vol. 11, p. 041062, Dec 2021
work page 2021
-
[40]
An- alytical evidence of nonlinearity in qubits and continuous-variable quantum reservoir computing,
P. Mujal, J. Nokkala, R. Mart´ ınez-Pe˜ na, G. L. Giorgi, M. C. Soriano, and R. Zambrini, “An- alytical evidence of nonlinearity in qubits and continuous-variable quantum reservoir computing,”Journal of Physics: Complexity, vol. 2, p. 045008, nov 2021
work page 2021
-
[41]
Configured quantum reservoir computing for multi-task machine learning,
W. Xia, J. Zou, X. Qiu, F. Chen, B. Zhu, C. Li, D.-L. Deng, and X. Li, “Configured quantum reservoir computing for multi-task machine learning,”Science Bulletin, vol. 68, pp. 2321–2329, 10 2023
work page 2023
-
[42]
Dissipation as a resource for quantum reservoir computing,
A. Sannia, R. Mart´ ınez-Pe˜ na, M. C. Soriano, G. L. Giorgi, and R. Zambrini, “Dissipation as a resource for quantum reservoir computing,” Quantum, vol. 8, p. 1291, 3 2024
work page 2024
-
[43]
Dynam- ical phase transitions in quantum reservoir computing,
R. Mart´ ınez-Pe˜ na, G. L. Giorgi, J. Nokkala, M. C. Soriano, and R. Zambrini, “Dynam- ical phase transitions in quantum reservoir computing,”Physical Review Letters, vol. 127, p. 100502, 9 2021
work page 2021
-
[44]
Exploring quantum mechanical advantage for reservoir computing,
N. G¨ otting, F. Lohof, and C. Gies, “Exploring quantum mechanical advantage for reservoir computing,”Physical Review A, vol. 108, 2 2023
work page 2023
-
[45]
Informa- tion processing capacity of spin-based quan- tum reservoir computing systems,
R. Mart´ ınez-Pe˜ na, J. Nokkala, G. L. Giorgi, R. Zambrini, and M. C. Soriano, “Informa- tion processing capacity of spin-based quan- tum reservoir computing systems,”Cognitive Computation, vol. 15, pp. 1440–1451, 9 2023
work page 2023
-
[46]
Quantum reservoir computing for speckle disorder potentials,
P. Mujal, “Quantum reservoir computing for speckle disorder potentials,”Condensed Mat- ter, vol. 7, p. 17, 1 2022. 16
work page 2022
-
[47]
Learning nonlinear input–output maps with dissipative quantum systems,
J. Chen and H. I. Nurdin, “Learning nonlinear input–output maps with dissipative quantum systems,”Quantum Information Processing, vol. 18, no. 7, p. 198, 2019
work page 2019
-
[48]
Boosting computational power through spatial multiplexing in quan- tum reservoir computing,
K. Nakajima, K. Fujii, M. Negoro, K. Mitarai, and M. Kitagawa, “Boosting computational power through spatial multiplexing in quan- tum reservoir computing,”Physical Review Applied, vol. 11, no. 3, p. 034021, 2019
work page 2019
-
[49]
Higher-order quantum reservoir computing,
Q. H. Tran and K. Nakajima, “Higher-order quantum reservoir computing,”arXiv preprint arXiv:2006.08999, 2020
-
[50]
Informa- tion processing capacity of spin-based quan- tum reservoir computing systems,
R. Mart´ ınez-Pe˜ na, J. Nokkala, G. L. Giorgi, R. Zambrini, and M. C. Soriano, “Informa- tion processing capacity of spin-based quan- tum reservoir computing systems,”Cognitive Computation, pp. 1–12, 2020
work page 2020
-
[51]
Memory-augmented hybrid quantum reservoir computing,
J. Settinoet al., “Memory-augmented hybrid quantum reservoir computing,”Phys. Rev. Ap- plied, vol. 24, no. 2, p. 024019, 2025
work page 2025
-
[52]
S. Ghosh, A. Opala, M. Matuszewski, T. Pa- terek, and T. C. H. Liew, “Quantum reservoir processing,”npj Quantum Information, vol. 5, p. 35, 4 2019
work page 2019
-
[53]
Quantum-classical hybrid information process- ing via a single quantum system,
Q. H. Tran, S. Ghosh, and K. Nakajima, “Quantum-classical hybrid information process- ing via a single quantum system,”Physical Review Research, vol. 5, p. 43127, 2023
work page 2023
-
[54]
Benchmarking the role of par- ticle statistics in quantum reservoir comput- ing,
G. Llodr` a, C. Charalambous, G. L. Giorgi, and R. Zambrini, “Benchmarking the role of par- ticle statistics in quantum reservoir comput- ing,”Advanced Quantum Technologies, vol. 6, p. 2200100, 1 2023
work page 2023
-
[55]
Large-scale quantum reservoir learning with an analog quantum computer,
M. Kornjaˇ ca, H.-Y. Hu, C. Zhao, J. Wurtz, P. Weinberg, M. Hamdan, A. Zhdanov, S. H. Cantu, H. Zhou, R. A. Bravo, K. Bagnall, J. I. Basham, J. Campo, A. Choukri, R. Deangelo, P. Frederick, D. Haines, J. Hammett, N. Hsu, M.-G. Hu, F. Huber, P. N. Jepsen, N. Jia, T. Karolyshyn, M. Kwon, J. Long, J. Lopatin, A. Lukin, T. M. Macr‘ı, O. M. Markovi´c, L. A. Ma...
work page 2024
-
[56]
Quantum reservoir computing using arrays of rydberg atoms,
R. A. Bravo, K. Najafi, X. Gao, and S. F. Yelin, “Quantum reservoir computing using arrays of rydberg atoms,”PRX Quantum, vol. 3, p. 030325, 8 2022
work page 2022
-
[57]
Quantum computing with neu- tral atoms,
L. Henriet, L. Beguin, A. Signoles, T. La- haye, A. Browaeys, G.-O. Reymond, and C. Jurczak, “Quantum computing with neu- tral atoms,”Quantum, vol. 4, p. 327, 9 2020
work page 2020
-
[58]
Predicting fermionic densities using a projected-quantum-kernel method,
F. Perciavalle, F. Plastina, M. Pisarra, and N. L. Gullo, “Predicting fermionic densities using a projected-quantum-kernel method,” Phys. Rev. A, vol. 112, no. 2, p. 022620, 2025
work page 2025
-
[59]
Quantum superpositions of current states in rydberg-atom networks,
F. Perciavalle, D. Rossini, J. Polo, O. Morsch, and L. Amico, “Quantum superpositions of current states in rydberg-atom networks,” Phys. Rev. Res., vol. 6, p. 043025, Oct 2024
work page 2024
-
[60]
Autoassociative neural networks,
M. Kramer, “Autoassociative neural networks,” Computers & Chemical Engineering, vol. 16, no. 4, pp. 313–328, 1992. Neutral network applications in chemical engineering
work page 1992
-
[61]
Autoencoders, minimum description length and helmholtz free energy,
G. E. Hinton and R. S. Zemel, “Autoencoders, minimum description length and helmholtz free energy,” inNeural Information Processing Systems, 1993
work page 1993
-
[62]
Learning representations by back- propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back- propagating errors,”Nature, vol. 323, pp. 533– 536, 1986
work page 1986
-
[63]
Re- ducing the dimensionality of data with neural networks,
G. E. Hinton and R. R. Salakhutdinov, “Re- ducing the dimensionality of data with neural networks,”Science, vol. 313, no. 5786, pp. 504– 507, 2006
work page 2006
-
[64]
Mnist handwritten digit database
Y. Lecun, C. Cortes, and C. J. Burges, “Mnist handwritten digit database.”ATT Labs [On- line]. Available: http: // yann. lecun. com/ exdb/ mnist, 2010
work page 2010
-
[65]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. Vollgraf, “Fashion- MNIST: a novel image dataset for bench- marking machine learning algorithms,” 2017. https://arxiv.org/abs/1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” tech. rep., Uni- versity of Toronto, 2009. https://www.cs. toronto.edu/~kriz/cifar.html
work page 2009
-
[67]
Evolution of en- tanglement entropy in one-dimensional sys- tems,
P. Calabrese and J. Cardy, “Evolution of en- tanglement entropy in one-dimensional sys- tems,”Journal of Statistical Mechanics: The- ory and Experiment, vol. 2005, p. P04010, apr 2005. 17
work page 2005
-
[68]
A short review on entanglement in quantum spin systems,
J. I. Latorre and A. Riera, “A short review on entanglement in quantum spin systems,” Journal of Physics A: Mathematical and The- oretical, vol. 42, p. 504002, dec 2009
work page 2009
-
[69]
Dynamics of en- tanglement in one-dimensional spin systems,
L. Amico, A. Osterloh, F. Plastina, R. Fazio, and G. Massimo Palma, “Dynamics of en- tanglement in one-dimensional spin systems,” Phys. Rev. A, vol. 69, p. 022304, Feb 2004. 18
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.