Minimal Data, Maximum Clarity: A Heuristic for Explaining Optimization
Pith reviewed 2026-05-18 17:43 UTC · model grok-4.3
The pith
EZR uses active sampling on minimal data to reach over 90% of top optimization performance while producing clearer cohort explanations than LIME or SHAP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Maximum Clarity Heuristic makes it possible and often preferable to generate effective multi-objective optimization and transparent explanations from far fewer but better-chosen examples rather than from complete supervised data, with EZR reliably delivering over 90 percent of best-known performance across real-world software engineering datasets while supplying cohort-based rationales that practitioners find clearer than those from LIME, SHAP, or BreakDown.
What carries the argument
The EZR pipeline, which interleaves Naive Bayes active sampling to locate high-quality configurations and decision-tree distillation to convert optimization logic into concise, readable rationales for both global trends and local choices.
If this is right
- Fewer labels suffice for competitive optimization results when sampling focuses on informative cases rather than uniform coverage.
- Decision trees distilled from the sampled data supply both global and local rationales that users rate higher in clarity than attribution scores from LIME, SHAP, or BreakDown.
- The same lightweight pipeline can be reused across many different software engineering optimization tasks without per-problem redesign.
- The endorsement of 'less but better' data directly reduces the labeling burden that currently limits practical deployment of optimization tools.
Where Pith is reading between the lines
- The same sampling-plus-tree pattern could be tested on configuration problems outside software engineering, such as hardware or cloud resource tuning.
- If the decision trees remain compact on higher-dimensional spaces, they might serve as a lightweight surrogate model for rapid what-if analysis during iterative design.
- Combining the active sampler with other base learners besides Naive Bayes might improve performance on datasets where the current assumption of feature independence does not hold.
Load-bearing premise
Naive Bayes active sampling will reliably locate high-quality configurations on diverse software engineering datasets without needing extra tuning or suffering from mismatch with the underlying distribution.
What would settle it
A fresh collection of software configuration datasets on which EZR either falls below 90 percent of the best-known performance or receives lower clarity ratings from practitioners than the same tasks explained by SHAP or LIME.
Figures








read the original abstract
Efficient, interpretable optimization is a critical but underexplored challenge in software engineering, where practitioners routinely face vast configuration spaces and costly, error-prone labeling processes. This paper introduces EZR, a novel and modular framework for multi-objective optimization that unifies active sampling, learning, and explanation within a single, lightweight pipeline. Departing from conventional wisdom, our Maximum Clarity Heuristic demonstrates that using less (but more informative) data can yield optimization models that are both effective and deeply understandable. EZR employs an active learning strategy based on Naive Bayes sampling to efficiently identify high-quality configurations with a fraction of the labels required by fully supervised approaches. It then distills optimization logic into concise decision trees, offering transparent, actionable explanations for both global and local decision-making. Extensive experiments across 60 real-world datasets establish that EZR reliably achieves over 90% of the best-known optimization performance in most cases, while providing clear, cohort-based rationales that surpass standard attribution-based explainable AI (XAI) methods (LIME, SHAP, BreakDown) in clarity and utility. These results endorse "less but better"; it is both possible and often preferable to use fewer (but more informative) examples to generate label-efficient optimization and explanations in software systems. To support transparency and reproducibility, all code and experimental materials are publicly available at https://github.com/amiiralii/Minimal-Data-Maximum-Clarity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EZR, a modular framework for multi-objective optimization in software engineering. It combines Naive Bayes active sampling to identify high-quality configurations using minimal labels, followed by distillation into concise decision trees that provide global and local cohort-based explanations. Experiments on 60 real-world datasets claim that EZR reaches over 90% of best-known optimization performance while delivering clearer, more actionable rationales than attribution-based XAI baselines (LIME, SHAP, BreakDown), endorsing a 'less but better' data heuristic. All code and materials are released publicly.
Significance. If the central performance and clarity claims hold after addressing sampling assumptions, the work would offer a practical, label-efficient alternative to black-box optimization and post-hoc explanation methods in SE configuration tuning. The emphasis on minimal informative data and the public release of code and experimental materials are notable strengths that support reproducibility and adoption. The results, if robust, could shift practice toward inherently interpretable pipelines rather than separate optimization and explanation stages.
major comments (2)
- [§3] §3 (Active Sampling and Naive Bayes): The headline claim of reliably achieving ≥90% of best-known performance depends on the active sampler surfacing high-quality points. The method factors P(x) = ∏ P(x_i) and therefore cannot model parameter interactions common in SE configuration spaces (e.g., compiler flags or hyper-parameter dependencies). No ablation replacing Naive Bayes with an interaction-aware sampler (e.g., random forest or Gaussian-process-based) is reported, leaving the performance numbers unsupported when interactions dominate.
- [Experimental Evaluation] Experimental Evaluation (results across 60 datasets): The comparisons to LIME, SHAP, and BreakDown report superior clarity and utility, yet provide no details on baseline implementations, hyper-parameter settings, statistical significance tests, or controls for data leakage. Without these, it is impossible to verify whether the clarity advantage is robust or an artifact of particular choices.
minor comments (2)
- [Abstract and §1] The abstract and introduction repeatedly use 'cohort-based rationales' without a precise definition or example until later sections; a brief forward reference would improve readability.
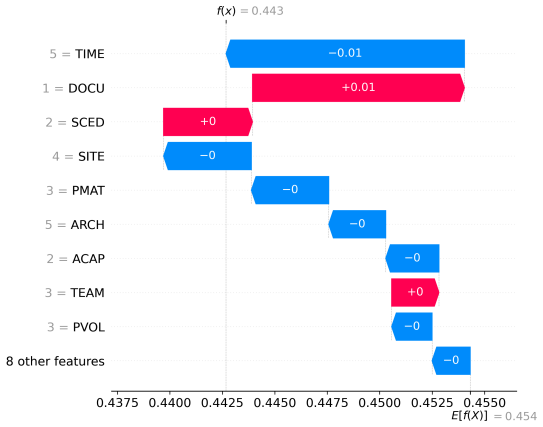
- [Figures] Figure captions for the decision-tree visualizations could explicitly state the dataset and objective being illustrated to aid quick interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the two major comments point by point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Active Sampling and Naive Bayes): The headline claim of reliably achieving ≥90% of best-known performance depends on the active sampler surfacing high-quality points. The method factors P(x) = ∏ P(x_i) and therefore cannot model parameter interactions common in SE configuration spaces (e.g., compiler flags or hyper-parameter dependencies). No ablation replacing Naive Bayes with an interaction-aware sampler (e.g., random forest or Gaussian-process-based) is reported, leaving the performance numbers unsupported when interactions dominate.
Authors: We agree that the independence assumption in Naive Bayes limits its ability to capture parameter interactions. At the same time, the reported results across 60 real-world datasets show that the active-sampling heuristic still reaches over 90 % of best-known performance in the great majority of cases. This empirical outcome is what underpins the 'less but better' claim. To directly address the referee's concern, the revised manuscript will add an ablation that substitutes the Naive Bayes sampler with an interaction-aware model (random forest) and reports the resulting performance delta. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation (results across 60 datasets): The comparisons to LIME, SHAP, and BreakDown report superior clarity and utility, yet provide no details on baseline implementations, hyper-parameter settings, statistical significance tests, or controls for data leakage. Without these, it is impossible to verify whether the clarity advantage is robust or an artifact of particular choices.
Authors: We appreciate the need for full reproducibility details. The revised Experimental Evaluation section will specify the exact library versions and hyper-parameter settings used for LIME, SHAP, and BreakDown; describe the statistical tests performed (Wilcoxon signed-rank tests with reported p-values and effect sizes); and clarify that all active sampling, model training, and explanation generation were conducted independently within each of the 60 datasets, eliminating cross-dataset leakage. revision: yes
Circularity Check
No significant circularity; claims rest on external datasets and standard baselines
full rationale
The paper describes EZR as an active-learning pipeline (Naive Bayes sampling to select configurations, followed by decision-tree distillation for explanations) and reports empirical results on 60 public real-world SE datasets, measuring performance against independently established best-known optimization outcomes and comparing explanations to LIME/SHAP/BreakDown. No derivation step equates the reported ≥90% performance or clarity metrics to a fitted parameter, self-citation, or input by construction; the sampling and tree steps are presented as procedural choices whose outputs are then evaluated on held-out or external benchmarks. The method is self-contained against those external references, with code released for reproduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Naive Bayes provides a sufficiently accurate surrogate for guiding active sampling in multi-objective software configuration spaces
Forward citations
Cited by 1 Pith paper
-
Zoom, Don't Wander: Why Regional Search Outperforms Pareto Reasoning and Global Optimization in Budget-Constrained SBSE
A minimal greedy regional zoom method outperforms Pareto and global Bayesian optimization in budget-constrained SBSE, winning or tying in 84-89% of cases at equal budget and even at one-fifth budget, because optimal s...
Reference graph
Works this paper leans on
-
[1]
T. Xu, X. Jin, P. Huang, Y. Zhou, S. Lu, L. Jin, S. Pasupathy, Early detection of configuration errors to reduce failure damage, in: Proc. OSDI 2016, 2016
work page 2016
-
[2]
T. Chen, M. Li, Adapting multi-objectivized software configuration tuning, Proc. ACM Softw. Eng. (2024)
work page 2024
- [3]
-
[4]
T. Xu, L. Jin, X. Fan, Y. Zhou, S. Pasupathy, R. Talwadker, Hey, you have given me too many knobs!: understanding and dealing with over-designed configuration in system software, in: Proc. FSE 2015, 2015
work page 2015
-
[5]
S. Mühlbauer, F. Sattler, C. Kaltenecker, J. Dorn, S. Apel, N. Siegmund, Analysing the impact of workloads on modeling the performance of config- urable software systems, in: Proc. ICSE 2023, 2023
work page 2023
-
[6]
S. Majumder, J. Chakraborty, T. Menzies, When less is more: on the value of “co-training” for semi-supervised software defect predictors, Empir. Softw. Eng. (2024)
work page 2024
-
[7]
J. A. Pereira, M. Acher, H. Martin, J.-M. Jézéquel, G. Botterweck, A. Ven- tresque, Learning software configuration spaces: A systematic literature re- view, J. Syst. Softw. (2021)
work page 2021
-
[8]
X. Wu, W. Zheng, X. Xia, D. Lo, Data quality matters: A case study on data label correctness for security bug report prediction, IEEE Trans. Softw. Eng. 48 (2021)
work page 2021
-
[9]
A. K. Shakya, G. Pillai, S. Chakrabarty, Reinforcement learning algorithms: A brief survey, Expert Syst. with Appl. 231 (2023)
work page 2023
-
[10]
J. Bergstra, Y. Bengio, Random search for hyper-parameter optimization, The journal of machine learning research (2012)
work page 2012
-
[11]
Z. Li, M. Harman, R. M. Hierons, Search algorithms for regression test case prioritization, IEEE Trans. Softw. Eng. (2007)
work page 2007
-
[12]
M. Khatibsyarbini, M. A. Isa, D. N. Jawawi, R. Tumeng, Test case prioriti- zation approaches in regression testing: A systematic literature review, Inf. Softw. Technol. (2018)
work page 2018
-
[13]
F. Hujainah, R. B. A. Bakar, M. A. Abdulgabber, K. Z. Zamli, Software re- quirements prioritisation: a systematic literature review on significance, stake- holders, techniques and challenges, IEEE Access (2018)
work page 2018
- [14]
-
[15]
A. V. Rezende, L. Silva, A. Britto, R. Amaral, Software project scheduling problem in the context of search-based software engineering: A systematic review, J. Syst. Softw. (2019). 40
work page 2019
-
[16]
Sarro, Search-based software engineering in the era of modern software systems, in: Proc
F. Sarro, Search-based software engineering in the era of modern software systems, in: Proc. IEEE Int. Conf. on Requirements Engineering, 2023
work page 2023
-
[17]
W. Mkaouer, M. Kessentini, A. Shaout, P. Koligheu, S. Bechikh, K. Deb, A. Ouni, Many-objective software remodularization using nsga-iii, ACM TOSEM (2015)
work page 2015
-
[18]
V. Nair, Z. Yu, T. Menzies, N. Siegmund, S. Apel, Finding faster configura- tions using flash, IEEE Trans. Softw. Eng. (2018)
work page 2018
-
[19]
M. Li, T. Chen, X. Yao, How to evaluate solutions in pareto-based search- based software engineering: A critical review and methodological guidance, IEEE Trans. Softw. Eng. (2020)
work page 2020
-
[20]
A. Lustosa, T. Menzies, Less noise, more signal: Drr for better optimizations of se tasks, arxiv:2503.21086 (2025)
-
[21]
B. W. Boehm, Software engineering economics, in: Software pioneers: Con- tributions to Softw. Eng., Springer, 2011
work page 2011
- [22]
- [23]
-
[24]
C. Tantithamthavorn, J. Cito, H. Hemmati, S. Chandra, Explainable ai for se: Challenges and future directions, IEEE Softw. 40 (2023)
work page 2023
-
[25]
C. K. Tantithamthavorn, J. Jiarpakdee, Explainable ai for software engineer- ing, in: Proc. ASE 2021, 2021
work page 2021
-
[26]
R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morgan, R. Ranjan, Explainable ai (xai): Core ideas, techniques, and solutions, ACM Comput. Surv. (2023)
work page 2023
- [27]
-
[28]
M. T. Ribeiro, S. Singh, C. Guestrin, " why should i trust you?" explaining the predictions of any classifier, in: Proc. KDD 2016, 2016
work page 2016
-
[29]
S. M. Lundberg, S.-I. Lee, A unified approach to interpreting model predic- tions, Adv. Neural Inf. Process. Syst. (2017)
work page 2017
-
[30]
M. Staniak, P. Biecek, Explanations of model predictions with live and break- down packages, The R Journal (2018)
work page 2018
-
[31]
D. Chen, W. Fu, R. Krishna, T. Menzies, Applications of psychological science for actionable analytics, in: Proc. FSE, 2018
work page 2018
-
[32]
G. A. Miller, The magical number seven, plus or minus two: Some limits on our capacity for processing information., Psychol. Rev. (1956). 41
work page 1956
-
[33]
R. R. Hoffman, S. T. Mueller, G. Klein, M. Jalaeian, C. Tate, Explainable ai: roles and stakeholders, desirements and challenges, Frontiers in Computer Science (2023)
work page 2023
-
[34]
B. Goodman, S. Flaxman, European union regulations on algorithmic decision making and a “right to explanation”, AI Mag. (2017)
work page 2017
-
[35]
A. Barredo Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garcia, S. Gil-Lopez, D. Molina, R. Benjamins, R. Chatila, F. Herrera, Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai, Information Fusion (2020)
work page 2020
-
[36]
S. Watanabe, Tree-structured parzen estimator: Understanding its algorithm components and their roles for better empirical performance, arxiv:2304.11127 (2023)
-
[37]
Breiman, Random forests, Machine learning (2001)
L. Breiman, Random forests, Machine learning (2001)
work page 2001
-
[38]
O. Arreche, T. Guntur, M. Abdallah, Xai-based feature selection for improved network intrusion detection systems, arxiv:2410.10050 (2024)
-
[39]
A. Hinterleitner, T. Bartz-Beielstein, R. Schulz, S. Spengler, T. Winter, C. Leitenmeier, Enhancing feature selection and interpretability in ai regres- sion tasks through feature attribution, arxiv:2409.16787 (2024)
-
[40]
W. E. Marcílio, D. M. Eler, From explanations to feature selection: assessing shap values as feature selection mechanism, in: Proc. SIBGRAPI 2020, 2020
work page 2020
-
[41]
M. Robnik-Šikonja, I. Kononenko, et al., An adaptation of relief for attribute estimation in regression, in: Machine learning: Proceedings of the fourteenth international conference (ICML’97), 1997
work page 1997
-
[42]
L. St, S. Wold, et al., Analysis of variance (anova), Chemometrics and intel- ligent laboratory systems (1989)
work page 1989
-
[43]
A. J. Scott, M. Knott, A cluster analysis method for grouping means in the analysis of variance, Biometrics (1974)
work page 1974
-
[44]
L. Senthilkumar, T. Menzies, Can large language models improve se active learning via warm-starts? (2024)
work page 2024
-
[45]
K. K. Ganguly, T. Menzies, Bingo! simple optimizers win big if problems collapse to a few buckets (2025)
work page 2025
-
[46]
T. Menzies, T. Chen, Moot repository of multi-objective optimization tests (2025). URLhttp://github.com/timm/moot
work page 2025
-
[47]
S. Amershi, A. Begel, C. Bird, R. DeLine, H. Gall, E. Kamar, N. Nagappan, B. Nushi, T. Zimmermann, Software engineering for machine learning: A case study, in: Proc. ICSE-SEIP 2019, 2019
work page 2019
-
[48]
F. J. Alcaide, J. R. Romero, A. Ramírez, Can explainable artificial intelligence support software modelers in model comprehension?, Software and Syst. Mod- eling (2025). 42
work page 2025
-
[49]
R. R. Hoffman, S. T. Mueller, G. Klein, J. Litman, Metrics for explainable ai: Challenges and prospects, arxiv:1812.04608 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [50]
-
[51]
D.N.Palacio, A.Velasco, N.Cooper, A.Rodriguez, K.Moran, D.Poshyvanyk, Toward a theory of causation for interpreting neural code models, IEEE Trans. Softw. Eng. (2024)
work page 2024
-
[52]
A. Lustosa, T. Menzies, isneak: Partial ordering as heuristics for model-based reasoning in software engineering, IEEE Access (2024)
work page 2024
-
[53]
R. G. Hamlet, Probable correctness theory, Information processing letters (1987)
work page 1987
-
[54]
C. A. Hoare, Algorithm 65: find, Communications of the ACM (1961)
work page 1961
-
[55]
I. Giagkiozis, P. Fleming, Methods for multi-objective optimization: An anal- ysis, Inf. Sci. (2015). 43
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.