SynQuE: Estimating Synthetic Dataset Quality Without Annotations
Pith reviewed 2026-05-18 01:29 UTC · model grok-4.3
The pith
Proxy metrics rank synthetic datasets by expected real performance using limited unannotated real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
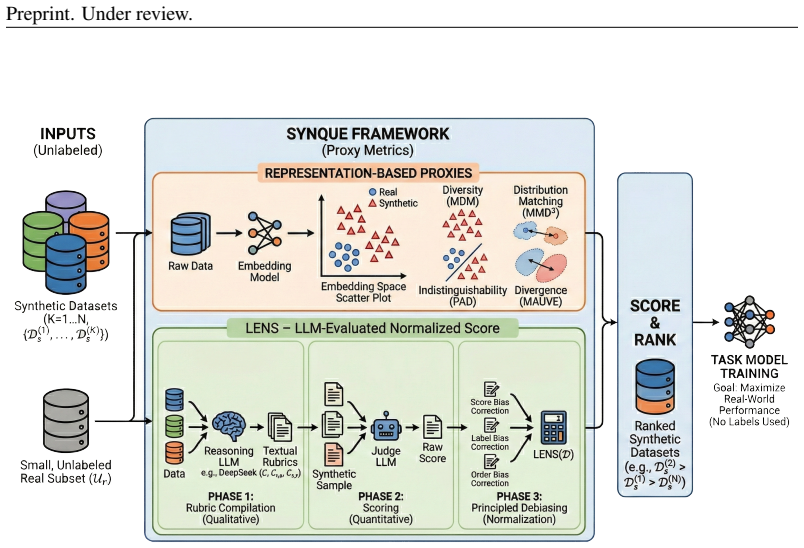
SynQuE establishes that proxy metrics based on embedding distances for distribution and diversity, together with LENS that incorporates LLM reasoning, can rank synthetic datasets so that training on the highest-ranked ones produces measurably higher accuracy on real tasks without any annotations on the real data.
What carries the argument
SynQuE proxy metrics that compare synthetic data to limited unannotated real data via embedding-based distribution and diversity distances, extended by LENS which adds LLM reasoning to capture task-relevant nuances.
If this is right
- Training on the top three synthetic datasets chosen by SynQuE proxies improves average accuracy over indiscriminate selection across tested tasks.
- LENS consistently gives stronger selection results than distance-only proxies on complex planning and reasoning tasks.
- The approach enables synthetic data curation when real labeled data is unavailable due to cost or privacy limits.
- The introduced benchmarks provide a standard way to compare future methods for synthetic dataset quality estimation.
Where Pith is reading between the lines
- These proxies could be used to iteratively refine synthetic data generators by favoring outputs that score higher against the real reference set.
- The same selection logic might transfer to choosing synthetic environments or trajectories in reinforcement learning settings.
- Testing the proxies on additional modalities such as audio or video data would clarify how far the current embedding and reasoning techniques generalize.
Load-bearing premise
The limited unannotated real data is representative of the full target distribution and the proxies measure exactly the data properties that determine downstream task performance.
What would settle it
An experiment in which models trained on the top-ranked synthetic datasets according to the proxies show no accuracy gain or a loss relative to models trained on randomly selected synthetic datasets on a new real task would falsify the proxies' utility.
Figures

read the original abstract
We introduce and formalize the Synthetic Dataset Quality Estimation (SynQuE) problem: ranking synthetic datasets by their expected real-world task performance using only limited unannotated real data. This addresses a critical and open challenge where data is scarce due to collection costs or privacy constraints. We establish the first comprehensive benchmarks for this problem by introducing and evaluating proxy metrics that choose synthetic data for training to maximize task performance on real data. We introduce the first proxy metrics for SynQuE by adapting distribution and diversity-based distance measures to our context via embedding models. To address the shortcomings of these metrics on complex planning tasks, we propose LENS, a novel proxy that leverages large language model reasoning. Our results show that SynQuE proxies correlate with real task performance across diverse tasks, including sentiment analysis, Text2SQL, web navigation, and image classification, with LENS consistently outperforming others on complex tasks by capturing nuanced characteristics. For instance, on text-to-SQL parsing, training on the top-3 synthetic datasets selected via SynQuE proxies can raise accuracy from 30.4% to 38.4 (+8.1)% on average compared to selecting data indiscriminately. This work establishes SynQuE as a practical framework for synthetic data selection under real-data scarcity and motivates future research on foundation model-based data characterization and fine-grained data selection. We release our code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SynQuE problem of ranking synthetic datasets by their expected performance on real-world tasks using only limited unannotated real data. It proposes adapted embedding-based distribution and diversity distance proxies, plus a new LENS proxy that uses LLM reasoning to capture nuanced characteristics. Empirical evaluations across sentiment analysis, Text2SQL, web navigation, and image classification show that the proxies correlate with downstream task accuracy; LENS outperforms on complex tasks, and selecting the top-3 synthetic datasets via SynQuE raises Text2SQL accuracy from 30.4% to 38.4% (+8.1%) on average versus random selection. Code is released.
Significance. If the proxies prove stable and generalizable, the work would provide a practical framework for synthetic data selection in annotation-scarce settings, with direct utility for privacy-sensitive or costly data domains. The introduction of benchmarks, the LENS method, and reproducible code are positive contributions that could motivate further research on foundation-model-based data characterization.
major comments (3)
- [§4.3, §5.2] §4.3 and §5.2: The central claim that proxy scores computed on a small unannotated real set reliably predict which synthetic datasets maximize accuracy on the full real distribution is load-bearing for the Text2SQL +8.1% result, yet no ablation or sensitivity analysis is reported on the size, sampling method, or representativeness of the limited real data used to compute the proxies. Without this, it remains possible that rankings reflect spurious surface features rather than task-relevant characteristics.
- [Table 2] Table 2 (Text2SQL row): The reported accuracy lift from 30.4% to 38.4% is presented as an average, but the manuscript does not state the number of independent runs, standard deviation, or statistical significance test; this weakens the quantitative support for the claim that SynQuE selection is superior to indiscriminate selection.
- [§3.2] §3.2: The LENS proxy is described as leveraging LLM reasoning to address shortcomings of embedding distances on planning tasks, but the exact prompt template, temperature, and aggregation method over multiple LLM calls are not fully specified, making it difficult to assess reproducibility or to isolate whether gains come from reasoning or from other factors.
minor comments (3)
- [Figure 3] Figure 3: Axis labels and legend are too small for readability; consider increasing font size and adding error bars if multiple runs were performed.
- [§2] §2: The related-work discussion focuses on synthetic data generation but omits several recent papers on embedding-based dataset similarity measures; adding these citations would strengthen context.
- [§3.1] Notation: The symbols for distribution distance (D) and diversity distance (V) are introduced without an explicit equation reference in the main text; adding a compact definition in §3.1 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point-by-point below. Where the concerns are valid, we have revised the manuscript to incorporate additional analyses, statistical details, and specifications to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4.3, §5.2] The central claim that proxy scores computed on a small unannotated real set reliably predict which synthetic datasets maximize accuracy on the full real distribution is load-bearing for the Text2SQL +8.1% result, yet no ablation or sensitivity analysis is reported on the size, sampling method, or representativeness of the limited real data used to compute the proxies. Without this, it remains possible that rankings reflect spurious surface features rather than task-relevant characteristics.
Authors: We agree that a sensitivity analysis on the limited real data is important to support the central claim. In the revised manuscript, we have added an ablation study in §5.2 that varies the size of the unannotated real set used for proxy computation (50, 100, 200, and 500 samples). The results show that proxy rankings and downstream gains remain stable for sizes ≥100 samples, with only minor degradation at 50 samples. We specify that sampling was performed uniformly at random and discuss potential limitations regarding representativeness in the updated limitations section. These additions directly strengthen the evidence for the reliability of the proxies. revision: yes
-
Referee: Table 2 (Text2SQL row): The reported accuracy lift from 30.4% to 38.4% is presented as an average, but the manuscript does not state the number of independent runs, standard deviation, or statistical significance test; this weakens the quantitative support for the claim that SynQuE selection is superior to indiscriminate selection.
Authors: We thank the referee for this observation. The reported 30.4% to 38.4% (+8.1%) figures are averages computed over 5 independent runs, each using different random seeds for both synthetic dataset selection and downstream model fine-tuning. Standard deviations are 2.3% for the SynQuE top-3 selection and 3.1% for random selection. We performed a paired t-test across the runs, obtaining p < 0.05. We have revised Table 2 to include these statistics and added a brief description of the multi-run protocol in §4.3. revision: yes
-
Referee: §3.2: The LENS proxy is described as leveraging LLM reasoning to address shortcomings of embedding distances on planning tasks, but the exact prompt template, temperature, and aggregation method over multiple LLM calls are not fully specified, making it difficult to assess reproducibility or to isolate whether gains come from reasoning or from other factors.
Authors: We agree that complete specification is essential for reproducibility. In the revised manuscript, we have added the full prompt template to Appendix C.1, set the LLM temperature to 0.0 to ensure deterministic outputs, and clarified that we issue three independent calls per sample, aggregating the resulting quality scores by simple averaging. The prompt explicitly instructs step-by-step reasoning about task relevance and planning characteristics, which we believe isolates the contribution of LLM reasoning from other factors. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the SynQuE problem and new proxy metrics (adapted embedding distances plus LENS LLM reasoning) as an empirical proposal, then validates them via direct correlation measurements and downstream accuracy gains on held-out real task data across multiple domains. No derivation step reduces by construction to its own inputs, fitted parameters renamed as predictions, or load-bearing self-citations; the +8.1% Text2SQL result and similar claims rest on independent experimental outcomes rather than definitional equivalence or prior-author uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding models capture relevant distributional and diversity properties that relate to downstream task performance.
- domain assumption Large language model reasoning can identify nuanced data characteristics relevant to complex task performance.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the first proxy metrics for SYNQUE by adapting distribution and diversity-based distance measures... To address the shortcomings... we propose LENS, a novel proxy that leverages large language model reasoning.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LENS first derives a language rubric describing the similarities and differences... We employ a minimal design involving four scoring permutations... score-debiased... label-debiased... order-debiased
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Breaking the Solver Bottleneck: Training Task Generators at the Learnable Frontier
PROPEL amortizes solver evaluation with a trained activation probe to optimize task generators toward a target solve rate, raising the share of learnable tasks from ~10% to ~20% in coding and SWE experiments.
Reference graph
Works this paper leans on
-
[1]
ISSN 1573-0565. doi: 10.1007/s10994-009-5152-4. URL https://doi.org/10. 1007/s10994-009-5152-4. Karsten M. Borgwardt, Arthur Gretton, Malte J. Rasch, Hans-Peter Kriegel, Bernhard Schölkopf, and Alex J. Smola. Integrating structured biological data by Kernel Maximum Mean Dis- crepancy.Bioinformatics, 22(14):e49–e57, July 2006. ISSN 1367-4811, 1367-4803. do...
-
[2]
URL https://proceedings.neurips.cc/paper_files/paper/2014/ hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2014
-
[3]
_eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1890/08-2244.1
URL https://onlinelibrary.wiley.com/doi/abs/10.1890/08-2244.1. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1890/08-2244.1. Joel Lehman and Kenneth O. Stanley. Abandoning Objectives: Evolution Through the Search for Novelty Alone.Evolutionary Computation, 19(2):189–223, June 2011. ISSN 1063-6560. doi: 10.1162/EVCO_a_00025. URL https://ieeexplore.ie...
-
[4]
Association for Computing Machinery. ISBN 978-1-60558-325-9. doi: 10.1145/1569901. 1569923. URLhttps://dl.acm.org/doi/10.1145/1569901.1569923. Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. arXiv, 2023. ...
-
[5]
arXiv preprint arXiv:2412.09605 , year=
URLhttp://arxiv.org/abs/2412.09605. arXiv:2412.09605 [cs]. Jiaxi Yang, Binyuan Hui, Min Yang, Jian Yang, Junyang Lin, and Chang Zhou. Synthesizing Text- to-SQL Data from Weak and Strong LLMs, August 2024. URL http://arxiv.org/abs/ 2408.03256. arXiv:2408.03256 [cs]. Jiacheng Ye, Jiahui Gao, Qintong Li, Hang Xu, Jiangtao Feng, Zhiyong Wu, Tao Yu, and Lingpe...
-
[6]
stage" (b) Sample synthetic images of class
Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.801. URL https://aclanthology.org/2022.emnlp-main.801. Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias. 2023. doi: 10.48550/ARXIV ....
-
[7]
on sentiment analysis. K=3 K=5 K=10 K=20 .85/ .68 .86/ .68 .86/ .69 .86/ .69 The table with varying number of medoid clusters for MDM shows that changing the number of clusters has negligible effect on the correlation betweenMDMand F1 score. B.6 ABLATION STUDY ON USING DIFFERENT ENCODER FOR REPRESENTATION-BASED METRICS The results with BGE-M37 demonstrate...
work page 2019
-
[8]
- Use sentence case formatting (capitalize only the first word and proper nouns)
Format & Style: - Headlines must be concise and mimic real financial news. - Use sentence case formatting (capitalize only the first word and proper nouns). - Some headlines should start with a stock ticker (e.g., $AAPL -), while others should begin with the company name or a broader market trend
-
[12]
- Bullish (1): Indicates positive sentiment about a stock or market trend
Sentiment Labeling: Each headline must be assigned a sentiment label based on its tone: - Bearish (0): Indicates negative sentiment about a stock or market trend. - Bullish (1): Indicates positive sentiment about a stock or market trend. - Neutral (2): Indicates neutral or informational tone. Sentiment Labeling: Each headline must be assigned a sentiment ...
-
[13]
Format & Style: - Headlines must be concise and mimic real financial news. 24 Preprint. Under review. - Use sentence case formatting (capitalize only the first word and proper nouns). - Some headlines should start with a stock ticker (e.g., $AAPL -), while others should begin with the company name or a broader market trend
-
[14]
Alphabet and Meta see price targets cut at Barclays
Ticker Inclusion: - At least one headline should include a stock ticker (e.g., $TSLA - or $NVDA -). - Some headlines should refer to companies by name instead of tickers (e.g., "Alphabet and Meta see price targets cut at Barclays")
-
[15]
Common Financial Themes: Ensure headlines reflect realistic financial news topics, including: - Stock downgrades/upgrades - Price target adjustments - Market trends/economic outlook - Company performance concerns - Company news - Company announcements - Company events
-
[16]
- Do not fabricate research firms-use only well-known institutions
Source Attribution: - When relevant, mention an investment firm, analyst, or research group (e.g., Morgan Stanley, Barclays, Oppenheimer). - Do not fabricate research firms-use only well-known institutions
-
[17]
Sentiment Labeling: Each headline must be assigned a sentiment label based on its tone: - Bearish (0): Indicates negative sentiment about a stock or market trend. - Bullish (1): Indicates positive sentiment about a stock or market trend. - Neutral (2): Indicates neutral or informational tone. Now, generate three new financial news headlines about stock ti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.