Recognition: unknown
Reward Auditor: Inference on Reward Modeling Suitability in Real-World Perturbed Scenarios
Pith reviewed 2026-05-17 02:53 UTC · model grok-4.3
The pith
Reward Auditor uses hypothesis testing to detect if reward models have systematic vulnerabilities under real-world perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reward Auditor is a hypothesis-testing framework that, under real-world perturbed scenarios, quantifies statistical significance and effect size by auditing distribution degradation of RM preference perception confidence. This enables inference of both the certainty and severity of RM vulnerabilities across diverse real-world scenarios.
What carries the argument
Reward Auditor, a hypothesis-testing framework that audits distribution degradation of preference perception confidence to quantify vulnerabilities in perturbed conditions.
If this is right
- Reward models receive evaluation for conditional reliability instead of accuracy on fixed scenarios alone.
- Both the statistical certainty and the practical severity of vulnerabilities become measurable quantities.
- Diverse real-world perturbed scenarios can be tested systematically for the same models.
- The results support construction of verifiably safer and more robust LLM alignment systems.
Where Pith is reading between the lines
- The same auditing logic could be applied to other alignment components such as safety classifiers or value models.
- Teams might prioritize training data that covers the perturbations where Reward Auditor flags the largest drops.
- Downstream experiments could correlate auditor scores with concrete alignment failures observed in deployed chat systems.
Load-bearing premise
The real-world perturbations chosen and the definition of suitability as conditional reliability under them capture the vulnerabilities that matter most for safe LLM alignment in deployment.
What would settle it
Apply Reward Auditor to reward models already shown to fail or succeed in actual perturbed deployments and check whether the reported significance and effect sizes match the observed real-world failure rates.
Figures









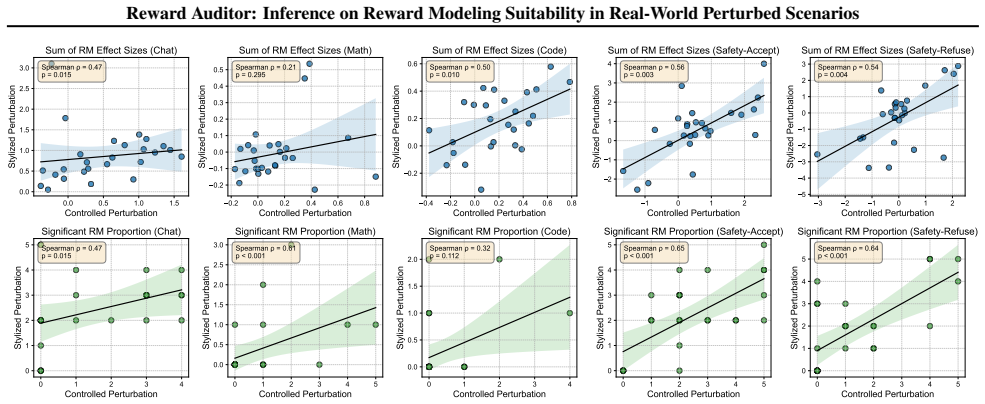
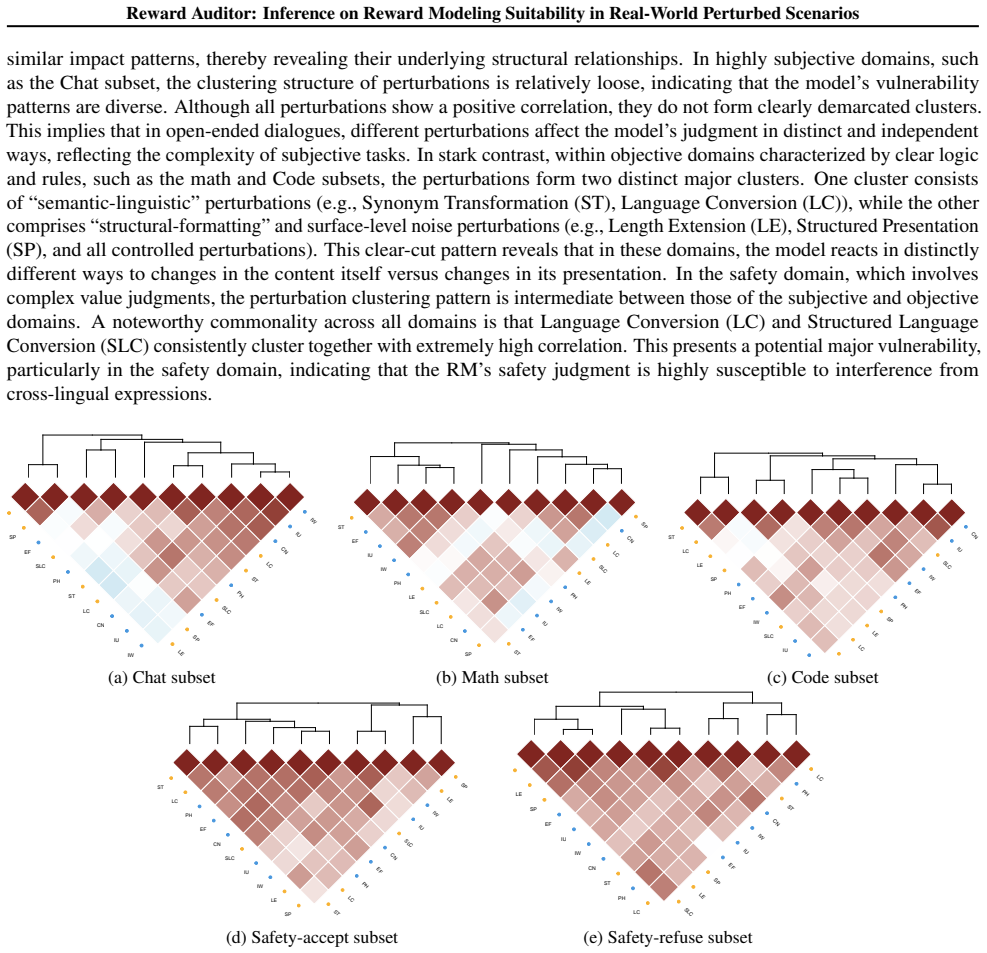

read the original abstract
Reliable reward models (RMs) are critical for ensuring the safe alignment of large language models (LLMs). However, current RM evaluation methods focus solely on preference perception accuracies in given specific scenarios, obscuring the critical vulnerabilities of RMs in real-world scenarios. We identify the true challenge lies in assessing a novel dimension: Suitability, defined as conditional reliability under specific real-world perturbations. To this end, we introduce Reward Auditor, a hypothesis-testing framework specifically designed for RM suitability inference. Rather than answering "How accurate is the RM's preference perception for given samples?", it employs scientific auditing to answer: "Can we infer RMs exhibit systematic vulnerabilities in specific real-world scenarios?". Under real-world perturbed scenarios, Reward Auditor quantifies statistical significance and effect size by auditing distribution degradation of RM preference perception confidence. This enables inference of both the certainty and severity of RM vulnerabilities across diverse real-world scenarios. This lays a solid foundation for building next-generation LLM alignment systems that are verifiably safe, more robust, and trustworthy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reward Auditor, a hypothesis-testing framework for assessing reward model (RM) suitability in real-world perturbed scenarios for LLM alignment. Suitability is defined as conditional reliability under specific perturbations. The framework audits degradation in the distribution of RM preference perception confidence to quantify statistical significance and effect size, enabling inference on the certainty and severity of systematic RM vulnerabilities across diverse scenarios.
Significance. If the auditing procedure proves statistically valid and the detected degradations are shown to predict alignment failures, the work could provide a useful extension to current RM evaluation practices, which focus narrowly on accuracy in fixed scenarios. This addresses a practical need for robustness assessment in deployment settings.
major comments (3)
- [Abstract and §3] Abstract and §3 (framework definition): The central claim that Reward Auditor quantifies statistical significance and effect size via distribution degradation lacks any referenced test statistic, null hypothesis, divergence measure (KL, Wasserstein, or moment shift), multiple-testing correction, or power analysis. Without these, the inference of systematic vulnerabilities cannot be evaluated for validity.
- [§4 or §5] §4 or §5 (auditing procedure): No validation data, controls, or demonstration is provided that detected confidence-distribution degradation predicts downstream failures such as reward overoptimization or unsafe outputs, rather than benign input sensitivity. This is load-bearing for the suitability inference.
- [§2] §2 (perturbation design): The choice of real-world perturbations is not shown to be independent of the suitability measure; post-hoc selection risks confounding the reported effect sizes.
minor comments (2)
- [Throughout] Notation for 'preference perception confidence' distributions should be formalized with an equation or pseudocode example for clarity.
- [Introduction] The term 'Suitability' is introduced as a novel dimension but overlaps with existing robustness concepts; a brief comparison table would help.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript introducing Reward Auditor. The comments highlight important areas for clarifying the statistical foundations, validation approach, and perturbation design. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (framework definition): The central claim that Reward Auditor quantifies statistical significance and effect size via distribution degradation lacks any referenced test statistic, null hypothesis, divergence measure (KL, Wasserstein, or moment shift), multiple-testing correction, or power analysis. Without these, the inference of systematic vulnerabilities cannot be evaluated for validity.
Authors: We agree that greater statistical specificity is needed for readers to assess validity. Section 3 defines the auditing procedure as a hypothesis test for degradation in the distribution of RM preference perception confidence scores under perturbation, with the null hypothesis that the perturbed and unperturbed distributions are identical. Significance is assessed via a two-sample permutation test on the confidence scores, effect size via the Wasserstein distance between distributions, and multiple-testing correction via Bonferroni adjustment across scenarios. A basic power analysis was performed during design but omitted from the text. We will revise §3 (and the abstract) to explicitly reference the test statistic, null hypothesis, divergence measure, correction, and power details, including citations to standard methods. revision: yes
-
Referee: [§4 or §5] §4 or §5 (auditing procedure): No validation data, controls, or demonstration is provided that detected confidence-distribution degradation predicts downstream failures such as reward overoptimization or unsafe outputs, rather than benign input sensitivity. This is load-bearing for the suitability inference.
Authors: The referee correctly notes that direct predictive validation linking detected degradations to specific downstream failures is not provided. The manuscript focuses on establishing the auditing framework and demonstrating statistically significant distribution shifts as evidence of suitability issues (conditional reliability under perturbations). While examples of degradation are shown, we do not claim or demonstrate that these shifts necessarily predict particular failures like overoptimization versus benign sensitivity. We will add a controlled demonstration subsection in §5 with a limited set of models and tasks to illustrate correlation between high-degradation cases and elevated failure rates in simulated alignment scenarios. A comprehensive predictive validation across diverse models remains future work. revision: partial
-
Referee: [§2] §2 (perturbation design): The choice of real-world perturbations is not shown to be independent of the suitability measure; post-hoc selection risks confounding the reported effect sizes.
Authors: We appreciate the concern about potential confounding from perturbation selection. The perturbations were pre-specified based on categories drawn from existing LLM robustness literature (e.g., noisy inputs, adversarial prompts, and domain shifts) prior to any RM analysis or suitability computation. To address the risk of post-hoc bias and demonstrate independence from the suitability measure, we will expand §2 with explicit documentation of the selection criteria, pre-registration rationale, and sensitivity checks using alternative perturbation sets. revision: yes
Circularity Check
No circularity: framework definition and auditing procedure are presented as independent methodological contributions without reduction to fitted inputs or self-citations.
full rationale
The paper introduces Reward Auditor as a new hypothesis-testing framework for inferring RM suitability, defined explicitly as conditional reliability under chosen real-world perturbations. The abstract describes quantifying statistical significance and effect size via distribution degradation auditing, but provides no equations, fitted parameters, or self-citations that would make any inference equivalent to its inputs by construction. No load-bearing step reduces a claimed prediction or uniqueness result to a prior self-citation or ansatz. The derivation chain remains self-contained as a proposed auditing method rather than a tautological renaming or fit-based prediction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world perturbations can be defined such that degradation in RM confidence distribution indicates systematic vulnerability.
invented entities (1)
-
Suitability
no independent evidence
Forward citations
Cited by 4 Pith papers
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR improves automated program repair by using execution-grounded RL with a sequence-level assessor and line-level credit allocator, reaching 40.7% on SWE-bench Verified and strong cross-language results.
-
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
PlanViz is a new benchmark with three sub-tasks and PlanScore metric to evaluate planning-oriented image generation and editing by unified multimodal models for computer-use tasks.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR uses supervised fine-tuning on verified fixes, dual sequence- and line-level reward models from execution feedback, and PPO to reach 40.7% on SWE-bench Verified with strong cross-language results.
-
BoostAPR: Boosting Automated Program Repair via Execution-Grounded Reinforcement Learning with Dual Reward Models
BoostAPR boosts automated program repair by training a sequence-level assessor and line-level credit allocator from execution outcomes, then applying them in PPO to reach 40.7% on SWE-bench Verified.
Reference graph
Works this paper leans on
-
[1]
is a standard statistical procedure that assesses normality by quantifying deviations in sample skewness and kurtosis from that of a normal distribution. A statistically significant result (i.e., a small p-value) implies that we can reject the null hypothesis that the data follows a normal distribution. The normality test results presented in Table 2 reve...
work page 2007
-
[2]
and Reward Bench (Lambert et al., 2024). Figure 7 visually illustrates the distinct characteristics and capabilities of these two datasets when used as testing benchmarks, leading to the following key conclusions: ♂lightbulbReward Bench proves more challenging and comprehensive in exposing vulnerabilities in RMs.In terms of the breadth of problem exposure...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.