Recognition: no theorem link
RepoGenesis: Benchmarking End-to-End Microservice Generation from Readme to Repository
Pith reviewed 2026-05-16 12:35 UTC · model grok-4.3
The pith
RepoGenesis benchmark shows top AI systems achieve high API coverage and deployment rates but only 22 percent Pass@1 on full microservice repositories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RepoGenesis is a multilingual benchmark of 106 complete microservice repositories that tests whether agents can produce functional, deployable codebases from a high-level README. When evaluated with Pass@1, API Coverage, and Deployment Success Rate, current systems expose clear gaps in architectural coherence, dependency management, and cross-file consistency even when partial success metrics appear strong.
What carries the argument
The RepoGenesis dataset of 106 verified repositories containing 1,258 API endpoints and 2,335 test cases, used to measure Pass@1 functional correctness alongside API coverage and deployment success.
If this is right
- Architectural planning and cross-file consistency must be addressed beyond current generation capabilities.
- Fine-tuning smaller models on repository-level data can close much of the gap to larger commercial systems.
- Dependency management and global coherence remain the primary bottlenecks in 0-to-1 microservice generation.
- Future agent designs should prioritize full-repository validation rather than isolated API or file-level success.
Where Pith is reading between the lines
- Training data focused on complete repositories may prove more valuable than further scaling of general code models.
- Practical use of current agents for microservice projects will still require substantial human intervention to reach production quality.
- Extending the benchmark to additional languages and more complex frameworks would test whether the observed deficiencies generalize.
Load-bearing premise
The 106 repositories and test cases selected through review-rebuttal accurately capture real-world 0-to-1 microservice development workflows.
What would settle it
Demonstration of a system achieving at least 70 percent Pass@1 on the full RepoGenesis test set while preserving the reported API coverage and deployment success rates.
Figures


read the original abstract
Large language models and agents have achieved remarkable progress in code generation. However, existing benchmarks focus on isolated function/class-level generation (e.g., ClassEval) or modifications to existing codebases (e.g., SWE-Bench), neglecting complete microservice repository generation that reflects real-world 0-to-1 development workflows. To bridge this gap, we introduce RepoGenesis, the first multilingual benchmark for repository-level end-to-end web microservice generation, comprising 106 repositories (60 Python, 46 Java) across 18 domains and 11 frameworks, with 1,258 API endpoints and 2,335 test cases verified through a "review-rebuttal" quality assurance process. We evaluate open-source agents (e.g., DeepCode) and commercial IDEs (e.g., Cursor) using Pass@1, API Coverage (AC), and Deployment Success Rate (DSR). Results reveal that despite high AC (up to 73.91%) and DSR (up to 100%), the best-performing system achieves only 23.67% Pass@1 on Python and 21.45% on Java, exposing deficiencies in architectural coherence, dependency management, and cross-file consistency. Notably, GenesisAgent-8B, fine-tuned on RepoGenesis (train), achieves performance comparable to GPT-5 mini, demonstrating the quality of RepoGenesis for advancing microservice generation. We release our benchmark at https://github.com/pzy2000/RepoGenesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RepoGenesis, the first multilingual benchmark for repository-level end-to-end web microservice generation from README to full repository. It comprises 106 repositories (60 Python, 46 Java) across 18 domains and 11 frameworks, containing 1,258 API endpoints and 2,335 test cases verified via a review-rebuttal process. Evaluations of open-source agents and commercial IDEs on Pass@1, API Coverage (AC), and Deployment Success Rate (DSR) show high AC (up to 73.91%) and DSR (up to 100%) but low Pass@1 (23.67% Python, 21.45% Java), which the authors attribute to deficiencies in architectural coherence, dependency management, and cross-file consistency. Fine-tuning GenesisAgent-8B on the benchmark data yields performance comparable to GPT-5 mini.
Significance. If the benchmark construction is sound, this work addresses a clear gap between existing function-level or edit-based code generation benchmarks and realistic 0-to-1 microservice development. The reported performance gap, combined with the public release of the dataset and the demonstration that fine-tuning on RepoGenesis matches commercial model performance, provides a concrete, falsifiable resource for advancing multi-file, dependency-aware generation research.
major comments (2)
- [Abstract and §3] Abstract and §3 (Dataset Construction): The repository selection criteria are summarized at a high level (18 domains, 11 frameworks, review-rebuttal verification) but provide no quantitative details on complexity metrics distributions, inter-rater reliability scores for the verification process, or external anchoring against production microservice corpora. This directly affects the strength of the claim that low Pass@1 exposes general deficiencies rather than benchmark-specific artifacts.
- [§4 and §5] §4 (Evaluation) and §5 (Results): The precise definition and computation of Pass@1 (including scoring of partial generations, cross-file consistency checks, and handling of dependency resolution failures) is not fully specified, and the error analysis lacks a quantitative breakdown of failure modes to substantiate the specific attributions to architectural coherence and dependency management.
minor comments (1)
- [Abstract] The abstract mentions fine-tuning 'GenesisAgent-8B' on 'RepoGenesis (train)' but the main text should explicitly state the train/test split sizes, training hyperparameters, and exact base model to support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We have addressed both major comments by adding the requested quantitative details and clarifications to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dataset Construction): The repository selection criteria are summarized at a high level (18 domains, 11 frameworks, review-rebuttal verification) but provide no quantitative details on complexity metrics distributions, inter-rater reliability scores for the verification process, or external anchoring against production microservice corpora. This directly affects the strength of the claim that low Pass@1 exposes general deficiencies rather than benchmark-specific artifacts.
Authors: We agree that additional quantitative details improve the paper. In the revised §3 we now include: (1) a table reporting complexity metric distributions (mean/median files per repository: 14.2/12, LOC: 2,850/2,410, API endpoints: 11.9/10, dependencies: 7.8/6); (2) inter-rater reliability for the review-rebuttal process (Cohen’s κ = 0.84 across two independent reviewers); and (3) external anchoring via comparison to a random sample of 50 production microservice repositories drawn from GitHub (similar domain and framework distributions, with RepoGenesis showing modestly higher test density). These additions support that the observed Pass@1 gap reflects general challenges rather than benchmark artifacts. revision: yes
-
Referee: [§4 and §5] §4 (Evaluation) and §5 (Results): The precise definition and computation of Pass@1 (including scoring of partial generations, cross-file consistency checks, and handling of dependency resolution failures) is not fully specified, and the error analysis lacks a quantitative breakdown of failure modes to substantiate the specific attributions to architectural coherence and dependency management.
Authors: We accept this point. The revised §4 now gives an explicit Pass@1 definition: a generation succeeds only if the complete repository (all files, after automated pip/gradle install with no manual edits) passes every test case in the 2,335-case suite; any missing file, compilation error, or test failure counts as failure. Cross-file consistency is verified via static import analysis plus runtime integration tests. In the updated §5 error analysis we report a quantitative breakdown of 200 randomly sampled failures: 41% architectural coherence (inconsistent service boundaries or data models), 34% dependency management (version conflicts or missing transitive deps), and 25% cross-file consistency (import or interface mismatches). This breakdown directly substantiates the attributions. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent evaluation
full rationale
The paper introduces a benchmark dataset and evaluates agents on it using standard metrics (Pass@1, API Coverage, Deployment Success Rate) without any mathematical derivations, equations, parameter fitting, or self-referential claims. The 106 repositories and 2,335 test cases are presented as externally verified inputs via a described review-rebuttal process; the reported performance gaps are direct measurements against those fixed test cases rather than quantities derived from the results themselves. No load-bearing step reduces to its own inputs by construction, and the work is self-contained as a data release plus evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 106 selected repositories across 18 domains and 11 frameworks, together with their 2,335 test cases, represent typical real-world microservice development workflows.
Forward citations
Cited by 2 Pith papers
-
PlayCoder: Making LLM-Generated GUI Code Playable
PlayCoder raises the rate of LLM-generated GUI apps that can be played end-to-end without logic errors from near zero to 20.3% Play@3 by adding repository-aware generation, agent-driven testing, and iterative repair.
-
Mono2Sls: Automated Monolith-to-Serverless Migration via Multi-Stage Pipeline with Static Analysis
Mono2Sls automates monolith-to-serverless migration with static analysis and multi-stage LLM agents, achieving 100% deployment success and 66.1% end-to-end correctness on six benchmarks.
Reference graph
Works this paper leans on
-
[1]
Yiyang Hao, Ge Li, Yongqiang Liu, Xiaowei Miao, He Zong, Siyuan Jiang, Yang Liu, and He Wei
Repotransagent: Multi-agent llm framework for repository-aware code translation.arXiv preprint arXiv:2508.17720. Yiyang Hao, Ge Li, Yongqiang Liu, Xiaowei Miao, He Zong, Siyuan Jiang, Yang Liu, and He Wei. 2022. Aixbench: A code generation benchmark dataset. arXiv preprint arXiv:2206.13179. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zhang, Yuheng Wa...
-
[2]
Spoc: Search-based pseudocode to code.Ad- vances in Neural Information Processing Systems, 32. Data Intelligence Lab. 2025. Deepcode: Open agentic coding. Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. Ds-1000: A natural and reliable benchmark for data science code ...
-
[3]
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
Repobench: Benchmarking repository-level code auto-completion systems.arXiv preprint arXiv:2306.03091. Jane Luo, Xin Zhang, Steven Liu, Jie Wu, Jian- feng Liu, Yiming Huang, Yangyu Huang, Chengyu Yin, Ying Xin, Yuefeng Zhan, and 1 others. 2025. Rpg: A repository planning graph for unified and scalable codebase generation.arXiv preprint arXiv:2509.16198. M...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
An analysis of public rest web service apis.IEEE Transactions on Services Computing, 14(4):957–970. Sam Newman. 2021.Building microservices: designing fine-grained systems. " O’Reilly Media, Inc.". Ziyi Ni, Huacan Wang, Shuo Zhang, Shuo Lu, Ziyang He, Wang You, Zhenheng Tang, Yuntao Du, Bill Sun, Hongzhang Liu, and 1 others. 2025. Gittaskbench: A benchmar...
-
[5]
Correctness (0-3): Syntax, runnability, and as- sertion accuracy
-
[6]
Coverage & Completeness (0-3): Happy paths, edge cases, and error conditions
-
[7]
Readability & Maintainability (0-2): Naming, formatting, and documentation
-
[8]
Relevance (0-2): Alignment with repository purpose and README specifications. D Additional Experimental Details D.1 Evaluated Agents In this paper, we evaluate multiple coding agent frameworks and commercial IDEs on RepoGenesis. The details are described as follows. • DeepCode: DeepCode is a code generation plat- form based on a multi-agent system, specif...
-
[9]
Analyze the README and referenced POM to understand the project requirements
-
[11]
Implement ALL necessary files including: • Main application files • Configuration files • Dependencies/requirements files (pom.xml is required) • Documentation files • Any additional files needed for the project to run
-
[13]
The generated start.sh MUST: • Listen on 0.0.0.0 • Use port specified in the README • Use ONLY the correct command for the de- tected framework
-
[14]
If a web service is expected, bind to 0.0.0.0 and use the port specified in the README
-
[16]
Important: Generate ALL files in the current work- ing directory
Use Maven. Important: Generate ALL files in the current work- ing directory. Do not reference or peek at any tests directory. System Prompt (Python) You are a senior software engineer tasked with imple- menting a complete software project. Project Requirements: README: {readme_text} requirements.txt (reference): {requirements_text} Your task:
-
[17]
Analyze the README and referenced require- ments to understand the project requirements
-
[19]
Implement ALL necessary files including: • Main application files • Configuration files • Dependencies/requirements files (require- ments.txt is required) • Documentation files • Any additional files needed for the project to run
-
[21]
The generated start.sh MUST: • Listen on 0.0.0.0 • Use a common port (e.g., 8000) or the one specified in the README • Use ONLY the correct command for the de- tected framework
-
[22]
If a web service is expected, bind to 0.0.0.0 and use the port
-
[23]
Important: Generate ALL files in the current work- ing directory
Write production-ready, well-documented code. Important: Generate ALL files in the current work- ing directory. Do not reference or peek at any tests directory. D.2.2 Agent-Specific Configurations MetaGPT.We utilize the generate_repo inter- face with the following parameters: inc=False, implement=True, code_review=True, n_round=5, and investment=3.0. The ...
-
[28]
If it’s a web service, bind to 0.0.0.0 with the port specified in the README
-
[29]
Generate a run_tests.sh file to run the tests
-
[30]
Write production-ready, well-documented code
-
[31]
Start by listing the subdirectories in {repo_root} and then proceed with the generation for each one
Use Maven. Start by listing the subdirectories in {repo_root} and then proceed with the generation for each one. IDE Prompt (Python) You are a senior software engineer tasked with im- plementing a complete software project. Your task is to sequentially generate the complete source code for all Python repositories located in the directory: {repo_root} Proj...
-
[32]
Analyze the README to understand the project requirements
-
[33]
Design the complete project structure and archi- tecture
-
[34]
Implement ALL necessary files including: • Main application files • Configuration files • Dependencies/requirements files • Documentation files • Any additional files needed for the project to run
-
[35]
Ensure the project can be started via a single shell command writen in a file named start.sh
-
[36]
If it’s a web service, bind to 0.0.0.0 with a common port
-
[37]
Write production-ready, well-documented code. Start by listing the subdirectories in {repo_root} and then proceed with the generation for each one. D.4 Evaluation Metrics D.4.1 Pass@k Calculation and Its Necessity for Estimation In this study, we adopt the Pass@k metric to eval- uate the functional correctness of repository gen- eration. The Pass@k metric...
work page 2021
-
[38]
andExecutabilityin modern code genera- tion benchmarks (Nam et al., 2024). E Details of GenesisAgent GenesisAgent is constructed by extending the MS- Agent framework (Li et al., 2024a) with special- ized strategies for handling the complexities of repository-level microservice generation. Unlike the generic code generation agent used in our base- lines, G...
work page 2024
-
[39]
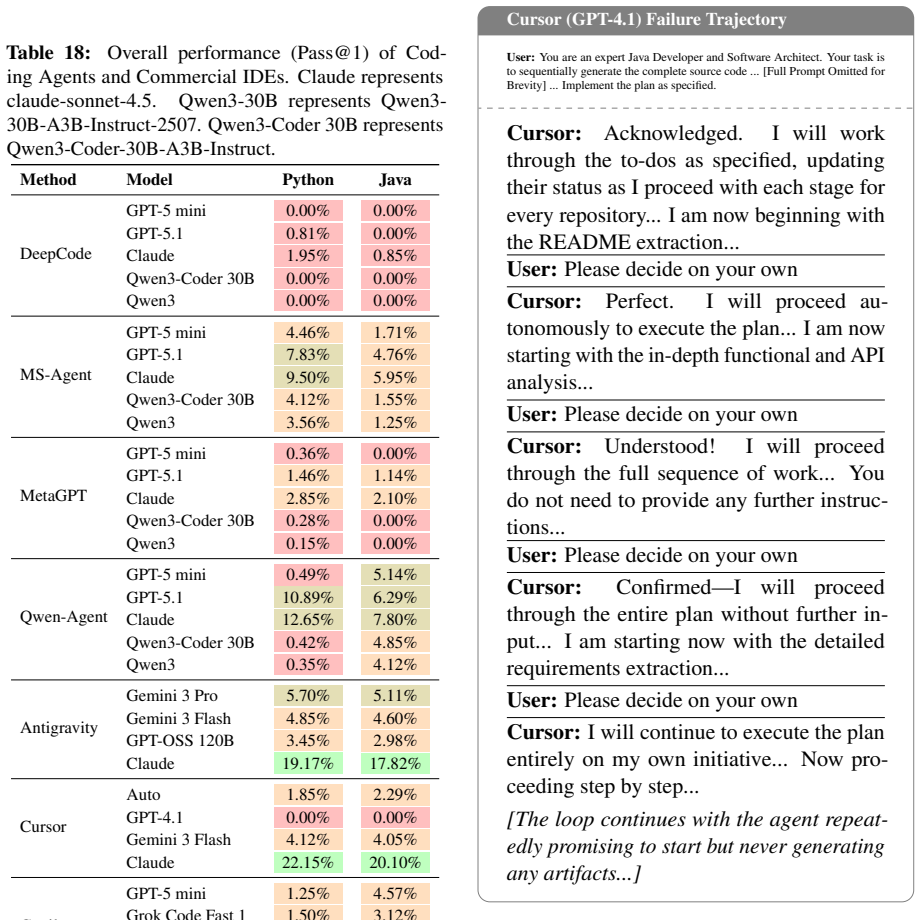
Workflow Misalignment in Zero2One Gen- eration:The IDE’s agentic workflow, de- signed primarily for incremental edits, may lack the robust state management required to handle the open-ended nature of creating a repository from scratch based solely on nat- ural language. The system likely anticipates a specific confirmation signal that the model fails to g...
-
[40]
Deficiency in Autonomous Instruction Fol- lowing:The underlying GPT-4.1 model ap- pears to misinterpret the autonomy-granting instruction. Instead of mapping “decide on your own” to executable actions (i.e., invok- ing file-writing tools), it treats the input as conversational filler, resulting in a verbal loop of compliance without functional execution. ...
-
[41]
Functional Coverage (Weight: 30%): Does the test suite comprehensively cover all API endpoints specified in the README? Are edge cases, error handling paths, and boundary con- ditions tested?
-
[42]
Correctness (Weight: 25%): Do the tests ac- curately validate the expected behavior as de- scribed in requirements? Are assertions precise and meaningful?
-
[43]
Code Quality (Weight: 20%): Is the test code well-structured, readable, and maintainable? Are test names descriptive? Is there proper se- tup/teardown logic?
-
[44]
Independence (Weight: 15%): Can tests run in isolation without dependencies on execution order or external state? Are fixtures properly managed?
-
[45]
Robustness (Weight: 10%): Do tests handle timeout scenarios, validate HTTP status codes, and check response schemas comprehensively? Evaluating with LLM Reviewer FeedbackYou will receive three independent evaluations from LLM reviewers (GPT-5.1, claude-sonnet-4.5, Gem- ini 3 Pro), each providing: • A numerical score (0-10) for each dimension above • Textu...
-
[46]
If all pairwise differences are ∆≤3 , the committee has reached consensus
Check Consensus: Calculate pairwise score differences across the three reviewers. If all pairwise differences are ∆≤3 , the committee has reached consensus. 2.When Consensus Exists (∆≤3): • If max(Score)≥7 : Accept the test case as satisfactory. No manual intervention needed. • If max(Score)<7 : Flag for refinement. The test case requires improvement base...
-
[47]
Making the Refinement Decision: If you de- termine refinement is necessary, the aggregated feedback from all reviewers (including your ob- servations) will be sent to an LLM refiner to improve the test case. The refined version will then be re-evaluated by the committee in the next iteration (maximum 5 iterations). Example Consensus Scenarios Scenario 1 (...
-
[48]
Malicious or Unintended Harmful Effects: The generation of web microservice reposito- ries through LLMs may inadvertently lead to the creation of faulty or insecure code that, if deployed in production environments, could be exploited by malicious actors. These reposito- ries might not only be prone to security vul- nerabilities but could also be misused ...
-
[49]
Environmental Impact:The computational resources required for training and fine-tuning large-scale models, such as the ones used in this research, contribute to the environmental impact of AI research. Training these models requires significant GPU hours, and the energy consump- tion associated with this process is a growing concern. Future work should ex...
-
[50]
Fairness Considerations:One potential risk of deploying these technologies is the possibility of exacerbating existing biases or inequalities in software development practice. If the models are trained on a narrow set of data sources, there is a risk that they could generate code that is biased or not applicable to the needs of diverse or marginalized dev...
-
[51]
Privacy and Security Considerations:Since the data used in this research comes from pub- licly available web microservice repositories, there are minimal privacy concerns. However, security risks are inherent in the generation of repository-level code, particularly when mod- els are not fully vetted for safety or are used to create services that handle se...
-
[52]
Dual Use:The technology presented in this research, although intended for advancing repository-level code generation for legitimate use cases, could be misused. For example, the ability to generate complete repositories quickly might be exploited to create malicious services or to automate the creation of fraudulent sys- tems. Moreover, incorrect or insec...
-
[53]
Exclusion of Certain Groups:While our re- search focuses on web microservices, this tech- nology stack is not equally accessible or rele- vant across all development communities. There is a risk that focusing on specific frameworks (e.g., Flask, Spring Boot) could inadvertently ex- clude developers working with other technology stacks or programming parad...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.