Implicit Neural Representation-Based Continuous Single Image Super-Resolution: An Empirical Benchmark
Pith reviewed 2026-05-16 11:02 UTC · model grok-4.3
The pith
Complex INR methods for arbitrary-scale image super-resolution deliver only marginal gains over simpler ones when training is controlled.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A unified framework and controlled experiments establish that INR-based arbitrary-scale super-resolution performance depends more on training configuration than on architectural complexity, that auxiliary objectives reliably lift perceptual quality beyond standard L1 loss, and that scaling produces consistent rather than transformative improvements.
What carries the argument
Unified benchmarking framework that enforces identical training configurations, objective choices, and scaling regimes across INR architectures to isolate their true contributions.
If this is right
- Architectural novelty alone is unlikely to produce large leaps in ASSR quality.
- Training configuration details must be matched exactly for any valid performance comparison.
- Auxiliary objectives should be adopted as a default to improve texture preservation.
- Performance can be forecast reliably from model size, compute budget, and data diversity.
- Simpler INR models remain competitive when training protocols are optimized.
Where Pith is reading between the lines
- Researchers should prioritize loss-function design and training protocols before inventing new architectures.
- Reproducibility in the field requires full disclosure of every training hyperparameter, not just model diagrams.
- Similar empirical controls could be applied to other continuous representation tasks such as neural radiance fields.
- The current emphasis on model complexity may be diverting effort from more effective levers.
Load-bearing premise
The selected methods and datasets let controlled training recipes fully separate architecture effects from any remaining implementation or data biases.
What would settle it
Retraining all compared models with identical random seeds, augmentations, optimizer settings, and data splits and still finding large gaps between complex and simple INR methods would falsify the marginal-gains claim.
Figures











read the original abstract
Implicit neural representation (INR) has become the standard approach for arbitrary-scale image super-resolution (ASSR). To date, no empirical study has systematically examined the effectiveness of existing methods, nor investigated the effects of different training recipes, such as scaling laws, objective design, and optimization strategies. A rigorous empirical analysis is essential not only for benchmarking performance and revealing true gains but also for establishing the current state of ASSR, identifying saturation limits, and highlighting promising directions. We fill this gap by comparing existing techniques across diverse settings and presenting aggregated performance results on multiple image quality metrics. We contribute a unified framework for more reliable interpretation of performance comparisons and model evaluation claims. To facilitate reproducible comparisons, a unified codebase is also provided. Furthermore, we investigate the impact of carefully controlled training configurations on perceptual image quality and analyze the role of auxiliary objectives in preserving edges, textures, and fine details during training. We conclude the following key insights that have been previously overlooked: (1) Recent, more complex INR methods provide only marginal improvements over earlier methods. (2) Model performance is strongly correlated to training configurations, a factor overlooked in prior works. (3) Auxiliary objectives consistently enhance texture fidelity across architectures compared to standard L1-Loss, emphasizing the role of objective design for targeted perceptual gains. (4) Scaling laws apply to INR-based ASSR, confirming predictable gains with increased model complexity, training compute, and data diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical benchmark of implicit neural representation (INR) methods for arbitrary-scale single-image super-resolution (ASSR). It introduces a unified training framework and open codebase to compare prior techniques under controlled settings, evaluating the effects of model scaling, training configurations (optimizer, schedules, data), and auxiliary loss objectives on standard image-quality metrics. The central claims are that recent complex INR variants yield only marginal gains over earlier methods, that performance correlates strongly with training recipes rather than architecture, that auxiliary objectives improve texture fidelity over plain L1 loss, and that scaling laws hold for INR-based ASSR.
Significance. If the controlled comparisons are robust, the work supplies a reproducible baseline that shifts emphasis from architectural novelty to training-recipe optimization and objective design in continuous super-resolution. The released codebase directly supports future reproducible studies and could reduce redundant implementation effort in the INR-ASSR literature.
major comments (3)
- [Abstract, Section 4] Abstract and Section 4: the claim that 'model performance is strongly correlated to training configurations' is load-bearing for insight (2), yet the manuscript supplies no explicit list of standardized hyperparameters (optimizer choice, learning-rate schedule, initialization, data-augmentation pipeline) nor ablation tables isolating each factor. Without these, residual method-specific tuning cannot be ruled out as a confounder.
- [Section 5.2, Table 3] Section 5.2 and Table 3: the reported 'marginal improvements' of recent INR methods are presented without statistical significance tests or confidence intervals on the metric differences; the tables therefore do not yet establish that the observed gaps are smaller than implementation variance.
- [Section 3.3] Section 3.3: the unified framework description does not detail how originally published loss-scaling or optimizer choices were altered during re-implementation; if any INR variant was re-tuned to a common recipe that differs from its original design, attribution of gains to 'training configurations' rather than architecture-optimizer compatibility remains circular.
minor comments (2)
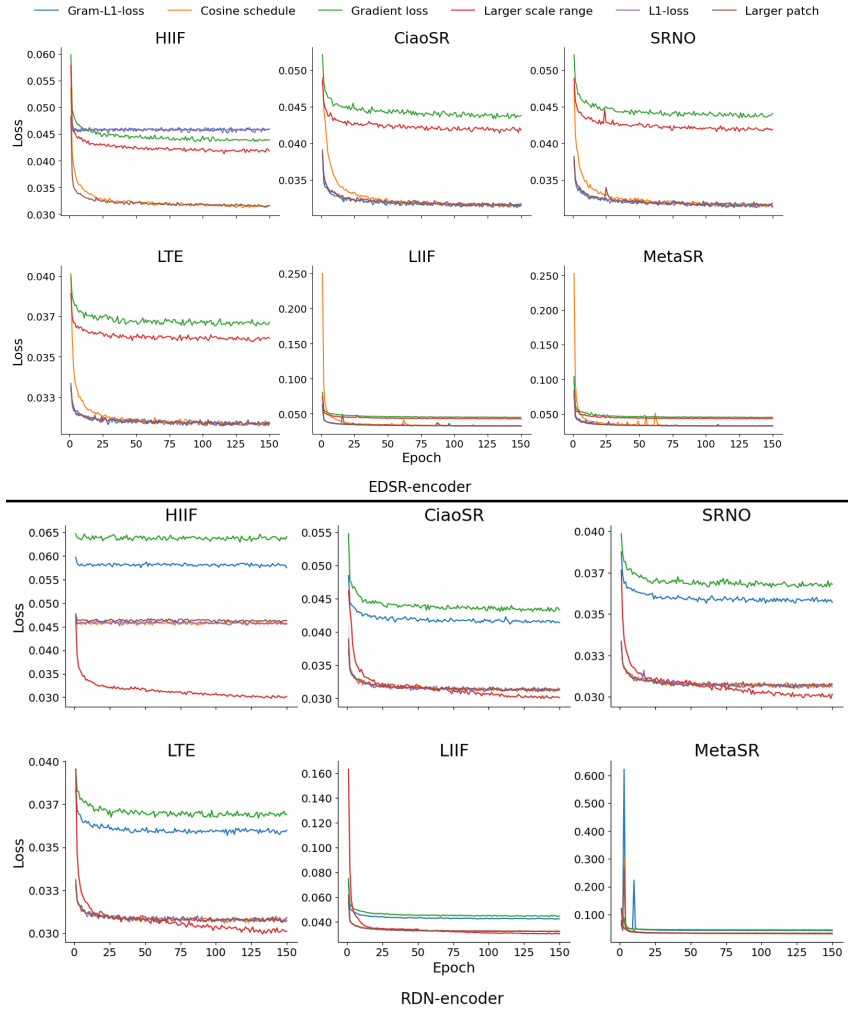
- [Figure 2] Figure 2: the y-axis scale for perceptual metrics is not labeled consistently across sub-plots, making direct visual comparison of auxiliary-objective gains difficult.
- [Section 2] Section 2: several citations to prior INR-ASSR works lack the exact arXiv or conference version numbers used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract, Section 4] Abstract and Section 4: the claim that 'model performance is strongly correlated to training configurations' is load-bearing for insight (2), yet the manuscript supplies no explicit list of standardized hyperparameters (optimizer choice, learning-rate schedule, initialization, data-augmentation pipeline) nor ablation tables isolating each factor. Without these, residual method-specific tuning cannot be ruled out as a confounder.
Authors: We agree that explicit documentation is required to support the claim. In the revised manuscript we will add a comprehensive table in Section 4 that lists all standardized hyperparameters, including optimizer, learning-rate schedule, initialization scheme, and data-augmentation pipeline. We will also include additional ablation tables in the supplementary material that isolate the contribution of each training-configuration factor. revision: yes
-
Referee: [Section 5.2, Table 3] Section 5.2 and Table 3: the reported 'marginal improvements' of recent INR methods are presented without statistical significance tests or confidence intervals on the metric differences; the tables therefore do not yet establish that the observed gaps are smaller than implementation variance.
Authors: We acknowledge the need for statistical rigor. We will augment Table 3 with confidence intervals and report the results of paired statistical significance tests (e.g., Wilcoxon signed-rank or t-tests) on the metric differences to demonstrate that the observed gaps fall within or below typical implementation variance. revision: yes
-
Referee: [Section 3.3] Section 3.3: the unified framework description does not detail how originally published loss-scaling or optimizer choices were altered during re-implementation; if any INR variant was re-tuned to a common recipe that differs from its original design, attribution of gains to 'training configurations' rather than architecture-optimizer compatibility remains circular.
Authors: Standardization to a common training recipe is intentional in our unified framework precisely to isolate the effect of training configurations from architectural differences. We will expand Section 3.3 with a new table that explicitly lists the original published settings for each method alongside the modifications applied during re-implementation, thereby removing any ambiguity about the procedure. revision: partial
Circularity Check
Empirical benchmark with controlled comparisons; no derivation reduces to inputs
full rationale
The paper is a comparative empirical study that unifies training recipes across prior INR methods and reports performance on standard external metrics (PSNR, SSIM, LPIPS) using released code. No equations, predictions, or uniqueness theorems are derived; the four listed insights follow directly from tabulated results under the stated controlled settings. Self-citations exist only for method descriptions and are not load-bearing for the benchmark conclusions. The central claim that training configurations dominate is an observed correlation from the experiments, not a fitted parameter renamed as prediction or a self-definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard image quality metrics (PSNR, SSIM, perceptual) reliably capture super-resolution performance differences
Forward citations
Cited by 1 Pith paper
-
NAIMA: Semantics Aware RGB Guided Depth Super-Resolution
NAIMA distills global semantic context from DINOv2 token embeddings into RGB-guided depth super-resolution using cross-attention blocks, reporting gains over prior GDSR methods on multiple datasets and scales.
Reference graph
Works this paper leans on
-
[1]
Hitchhiker’s guide to super-resolution: Introduction and recent advances,
B. B. Moseret al., “Hitchhiker’s guide to super-resolution: Introduction and recent advances,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 1
work page 2023
-
[2]
Single image super- resolution via a holistic attention network,
B. Niu, W. Wen, W. Ren, X. Zhang, L. Yang, S. Wang, K. Zhang, X. Cao, and H. Shen, “Single image super- resolution via a holistic attention network,” inEuropean conference on computer vision. Springer, 2020, pp. 191–
work page 2020
-
[3]
Diffusion models in image super- resolution and everything: A survey. arxiv,
B. Moser, A. Shanbhag, F. Raue, S. Frolov, S. Pala- cio, and A. Dengel, “Diffusion models in image super- resolution and everything: A survey. arxiv,”arXiv preprint arXiv:2401.00736, 2024. 1
-
[4]
Deep learning for image super-resolution: A survey,
Z. Wang, J. Chen, and S. C. Hoi, “Deep learning for image super-resolution: A survey,”IEEE transactions on pattern analysis and machine intelligence, 2020. 1
work page 2020
-
[5]
Arbitrary-scale super-resolution via deep learning: A comprehensive survey,
H. Liu, Z. Li, F. Shang, Y . Liu, L. Wan, W. Feng, and R. Timofte, “Arbitrary-scale super-resolution via deep learning: A comprehensive survey,”Information Fusion, vol. 102, p. 102015, 2024. 1, 3
work page 2024
-
[6]
Learning continuous im- age representation with local implicit image function,
Y . Chen, S. Liu, and X. Wang, “Learning continuous im- age representation with local implicit image function,” in Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2021, pp. 8628–8638. 1, 3
work page 2021
-
[7]
Super-resolution neural operator,
M. Wei and X. Zhang, “Super-resolution neural operator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 247–18 256. 1, 2, 3, 4, 7
work page 2023
-
[8]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communica- tions of the ACM, vol. 65, no. 1, pp. 99–106, 2021. 1, 3
work page 2021
-
[9]
Learning implicit fields for gener- ative shape modeling,
Z. Chen and H. Zhang, “Learning implicit fields for gener- ative shape modeling,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5939–5948. 1, 3
work page 2019
-
[10]
Sal: Sign agnostic learning of shapes from raw data,
M. Atzmon and Y . Lipman, “Sal: Sign agnostic learning of shapes from raw data,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2565–2574. 1
work page 2020
-
[11]
Meta-sr: A magnification-arbitrary network for super- resolution,
X. Hu, H. Mu, X. Zhang, Z. Wang, T. Tan, and J. Sun, “Meta-sr: A magnification-arbitrary network for super- resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1575–1584. 1, 3
work page 2019
-
[12]
Local texture estimator for implicit representation function,
J. Lee and K. H. Jin, “Local texture estimator for implicit representation function,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1929–1938. 1, 2, 3
work page 2022
-
[13]
En- hanced deep residual networks for single image super- resolution,
B. Lim, S. Son, H. Kim, S. Nah, and K. Mu Lee, “En- hanced deep residual networks for single image super- resolution,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 136–144. 2, 4, 7, 1
work page 2017
-
[14]
Resid- ual dense network for image super-resolution,
Y . Zhang, Y . Tian, Y . Kong, B. Zhong, and Y . Fu, “Resid- ual dense network for image super-resolution,” inProceed- ings of the IEEE conference on computer vision and pat- tern recognition, 2018, pp. 2472–2481. 2, 4, 7, 1
work page 2018
-
[15]
Cascaded local implicit transformer for arbitrary-scale super-resolution,
H.-W. Chen, Y .-S. Xu, M.-F. Hong, Y .-M. Tsai, H.-K. Kuo, and C.-Y . Lee, “Cascaded local implicit transformer for arbitrary-scale super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 257–18 267. 2, 3, 4 11
work page 2023
-
[16]
J. Cao, Q. Wang, Y . Xian, Y . Li, B. Ni, Z. Pi, K. Zhang, Y . Zhang, R. Timofte, and L. Van Gool, “Ciaosr: Contin- uous implicit attention-in-attention network for arbitrary- scale image super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1796–1807. 2, 3, 4
work page 2023
-
[17]
Hiif: Hierarchical encoding based implicit image function for continuous super-resolution,
Y . Jiang, H. M. Kwan, T. Peng, G. Gao, F. Zhang, X. Zhu, J. Sole, and D. Bull, “Hiif: Hierarchical encoding based implicit image function for continuous super-resolution,” inProceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 2289–2299. 2, 3, 4, 6, 7, 1
work page 2025
-
[18]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter, “Sgdr: Stochastic gra- dient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Learning a deep convolutional network for image super-resolution,
C. Dong, C. C. Loy, K. He, and X. Tang, “Learning a deep convolutional network for image super-resolution,” inEu- ropean conference on computer vision. Springer, 2014, pp. 184–199. 3
work page 2014
-
[20]
Accurate image super- resolution using very deep convolutional networks,
J. Kim, J. K. Lee, and K. M. Lee, “Accurate image super- resolution using very deep convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1646–1654. 3
work page 2016
-
[21]
Be- yond a gaussian denoiser: Residual learning of deep cnn for image denoising,
K. Zhang, W. Zuo, Y . Chen, D. Meng, and L. Zhang, “Be- yond a gaussian denoiser: Residual learning of deep cnn for image denoising,”IEEE transactions on image pro- cessing, vol. 26, no. 7, pp. 3142–3155, 2017. 3
work page 2017
-
[22]
Learning deep cnn denoiser prior for image restoration,
K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep cnn denoiser prior for image restoration,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3929–3938. 3
work page 2017
-
[23]
Accelerating the super-resolution convolutional neural network,
C. Dong, C. C. Loy, and X. Tang, “Accelerating the super-resolution convolutional neural network,” inEuro- pean conference on computer vision. Springer, 2016, pp. 391–407. 3
work page 2016
-
[24]
W. Shi, J. Caballero, F. Husz ´ar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang, “Real-time single image and video super-resolution using an efficient sub- pixel convolutional neural network,” inProceedings of the IEEE conference on computer vision and pattern recogni- tion, 2016, pp. 1874–1883. 3
work page 2016
-
[25]
Second- order attention network for single image super-resolution,
T. Dai, J. Cai, Y . Zhang, S.-T. Xia, and L. Zhang, “Second- order attention network for single image super-resolution,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 065–11 074. 3
work page 2019
-
[26]
Srdiff: Single image super-resolution with diffusion probabilistic models,
H. Li, Y . Yang, M. Chang, S. Chen, H. Feng, Z. Xu, Q. Li, and Y . Chen, “Srdiff: Single image super-resolution with diffusion probabilistic models,”Neurocomputing, vol. 479, pp. 47–59, 2022. 3
work page 2022
-
[27]
Image super-resolution via iterative refine- ment,
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi, “Image super-resolution via iterative refine- ment,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 4, pp. 4713–4726, 2022. 3
work page 2022
-
[28]
Mambair: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “Mambair: A simple baseline for image restoration with state-space model,” inEuropean conference on computer vision. Springer, 2024, pp. 222–241. 3
work page 2024
-
[29]
Mambacsr: Dual-interleaved scanning for com- pressed image super-resolution with ssms,
Y . Ren, X. Li, M. Guo, B. Li, S. Zhao, and Z. Chen, “Mambacsr: Dual-interleaved scanning for com- pressed image super-resolution with ssms,”arXiv preprint arXiv:2408.11758, 2024. 3
-
[30]
Vmambair: Visual state space model for image restoration,
Y . Shi, B. Xia, X. Jin, X. Wang, T. Zhao, X. Xia, X. Xiao, and W. Yang, “Vmambair: Visual state space model for image restoration,”IEEE Transactions on Circuits and Systems for Video Technology, 2025. 3
work page 2025
-
[31]
Local implicit normalizing flow for arbitrary-scale image super-resolution,
J.-E. Yao, L.-Y . Tsao, Y .-C. Lo, R. Tseng, C.-C. Chang, and C.-Y . Lee, “Local implicit normalizing flow for arbitrary-scale image super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2023, pp. 1776–1785. 3
work page 2023
-
[32]
Overnet: Lightweight multi-scale super- resolution with overscaling network,
P. Behjati, P. Rodriguez, A. Mehri, I. Hupont, C. F. Tena, and J. Gonzalez, “Overnet: Lightweight multi-scale super- resolution with overscaling network,” inProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, 2021, pp. 2694–2703. 3
work page 2021
-
[33]
Deep arbitrary-scale image super-resolution via scale- equivariance pursuit,
X. Wang, X. Chen, B. Ni, H. Wang, Z. Tong, and Y . Liu, “Deep arbitrary-scale image super-resolution via scale- equivariance pursuit,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1786–1795. 3
work page 2023
-
[34]
Srwarp: Generalized image super- resolution under arbitrary transformation,
S. Son and K. M. Lee, “Srwarp: Generalized image super- resolution under arbitrary transformation,” inProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, 2021, pp. 7782–7791. 3
work page 2021
-
[35]
Learning shape templates with struc- tured implicit functions,
K. Genova, F. Cole, D. Vlasic, A. Sarna, W. T. Freeman, and T. Funkhouser, “Learning shape templates with struc- tured implicit functions,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7154–7164. 3
work page 2019
-
[36]
Occupancy networks: Learning 3d reconstruc- tion in function space,
L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin, and A. Geiger, “Occupancy networks: Learning 3d reconstruc- tion in function space,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4460–4470. 3 12
work page 2019
-
[37]
Hypernetwork functional image represen- tation,
S. Klocek, Ł. Maziarka, M. Wołczyk, J. Tabor, J. Nowak, and M. ´Smieja, “Hypernetwork functional image represen- tation,” inInternational Conference on Artificial Neural Networks. Springer, 2019, pp. 496–510. 3
work page 2019
-
[38]
Perceptual losses for real-time style transfer and super-resolution,
J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” inEuropean conference on computer vision. Springer, 2016, pp. 694–
work page 2016
-
[39]
A Neural Algorithm of Artistic Style
L. A. Gatys, A. S. Ecker, and M. Bethge, “A neural algo- rithm of artistic style,”arXiv preprint arXiv:1508.06576,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Image quality assessment: from error visibility to struc- tural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to struc- tural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004. 4
work page 2004
-
[41]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2018, pp. 586–595. 4
work page 2018
-
[42]
Ntire 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super-resolution: Dataset and study,” inPro- ceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 126–135. 4
work page 2017
-
[43]
Low-complexity single-image super-resolution based on nonnegative neighbor embedding,
M. Bevilacqua, A. Roumy, C. Guillemot, and M. L. Alberi- Morel, “Low-complexity single-image super-resolution based on nonnegative neighbor embedding,” 2012. 4
work page 2012
-
[44]
On single image scale- up using sparse-representations,
R. Zeyde, M. Elad, and M. Protter, “On single image scale- up using sparse-representations,” inInternational confer- ence on curves and surfaces. Springer, 2010, pp. 711–
work page 2010
-
[45]
D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecolog- ical statistics,” inProceedings eighth IEEE international conference on computer vision. ICCV 2001, vol. 2. IEEE, 2001, pp. 416–423. 4
work page 2001
-
[46]
Single image super- resolution from transformed self-exemplars,
J.-B. Huang, A. Singh, and N. Ahuja, “Single image super- resolution from transformed self-exemplars,” inProceed- ings of the IEEE conference on computer vision and pat- tern recognition, 2015, pp. 5197–5206. 4
work page 2015
-
[47]
K. Wang and S. Belongie, “Word spotting in the wild,” in European conference on computer vision. Springer, 2010, pp. 591–604. 4
work page 2010
-
[48]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and varia- tion,”arXiv preprint arXiv:1710.10196, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Gradi- ent magnitude similarity deviation: A highly efficient per- ceptual image quality index,
W. Xue, L. Zhang, X. Mou, and A. C. Bovik, “Gradi- ent magnitude similarity deviation: A highly efficient per- ceptual image quality index,”IEEE transactions on image processing, vol. 23, no. 2, pp. 684–695, 2013. 4
work page 2013
-
[50]
Fsim: A feature similarity index for image quality assessment,
L. Zhang, L. Zhang, X. Mou, and D. Zhang, “Fsim: A feature similarity index for image quality assessment,” IEEE transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, 2011. 4
work page 2011
-
[51]
A visual information fi- delity approach to video quality assessment,
H. R. Sheikh and A. C. Bovik, “A visual information fi- delity approach to video quality assessment,” inThe first international workshop on video processing and quality metrics for consumer electronics, vol. 7, no. 2. sn, 2005, pp. 2117–2128. 4
work page 2005
-
[52]
Sr-sim: A fast and high performance iqa index based on spectral residual,
L. Zhang and H. Li, “Sr-sim: A fast and high performance iqa index based on spectral residual,” in2012 19th IEEE international conference on image processing. IEEE, 2012, pp. 1473–1476. 4
work page 2012
-
[53]
The borda and condorcet principles: three medieval applications,
I. McLean, “The borda and condorcet principles: three medieval applications,”Social Choice and Welfare, vol. 7, no. 2, pp. 99–108, 1990. 4
work page 1990
-
[54]
Tex- tural features for image classification,
R. M. Haralick, K. Shanmugam, and I. H. Dinstein, “Tex- tural features for image classification,”IEEE Transactions on systems, man, and cybernetics, no. 6, pp. 610–621,
-
[55]
Ntire 2023 chal- lenge on efficient super-resolution: Methods and results,
Y . Li, Y . Zhang, R. Timofte, L. Van Gool, L. Yu, Y . Li, X. Li, T. Jiang, Q. Wu, M. Hanet al., “Ntire 2023 chal- lenge on efficient super-resolution: Methods and results,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1922–1960. 2
work page 2023
-
[56]
J. Yoo, N. Ahn, and K.-A. Sohn, “Rethinking data augmen- tation for image super-resolution: A comprehensive anal- ysis and a new strategy,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8375–8384. 2 13 Appendix Additional details and analysis are presented here: • Appendix A: Details about experimental sett...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.