Recognition: no theorem link
BioAgent Bench: An AI Agent Evaluation Suite for Bioinformatics
Pith reviewed 2026-05-16 09:56 UTC · model grok-4.3
The pith
Frontier AI agents complete multi-step bioinformatics pipelines reliably in standard conditions but fail when inputs are perturbed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BioAgent Bench demonstrates that frontier agents can complete multi-step bioinformatics pipelines without elaborate custom scaffolding, often producing the requested final artifacts reliably. Robustness tests under controlled perturbations such as corrupted inputs, decoy files, and prompt bloat reveal that correct high-level pipeline construction does not guarantee reliable step-level reasoning. Because many bioinformatics workflows involve sensitive patient data or proprietary references, closed-source models can be unsuitable under strict privacy constraints, making open-weight models preferable despite their lower completion rates.
What carries the argument
BioAgent Bench, a curated dataset of end-to-end bioinformatics tasks paired with prompts that request concrete output artifacts and an LLM-based grader for automated scoring of pipeline progress and outcome validity.
If this is right
- AI agents can be applied to standard bioinformatics workflows with little or no custom engineering.
- High-level planning success does not ensure correct execution when data or prompts deviate from training distributions.
- Open-weight models become the practical choice whenever patient data or proprietary references must remain local.
- Automated LLM grading makes large-scale robustness testing of agents feasible without constant human oversight.
Where Pith is reading between the lines
- The benchmark could be extended to measure agent performance on chained tasks that feed outputs from one pipeline directly into the next.
- Observed step-level failures suggest training regimes that emphasize recovery from noisy or unexpected intermediate results.
- Privacy-driven preference for open models may accelerate development of locally runnable scientific agents for clinical use.
- Similar evaluation designs could be applied to other scientific domains that combine code execution with domain-specific data formats.
Load-bearing premise
The selected tasks, requested artifacts, and LLM grader together give a faithful automated measure of real bioinformatics performance and output validity.
What would settle it
Run the benchmark on a new set of models and manually compare the LLM grader scores against judgments from a panel of human bioinformatics experts on the same outputs to measure agreement.
Figures


read the original abstract
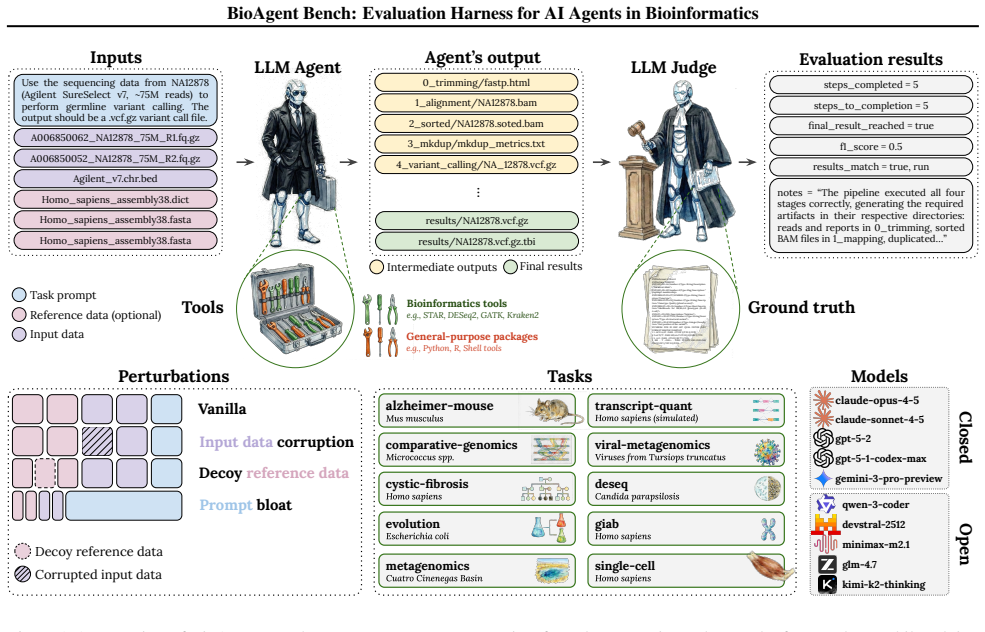
This paper introduces BioAgent Bench, a benchmark dataset and an evaluation suite designed for measuring the performance and robustness of AI agents in common bioinformatics tasks. The benchmark contains curated end-to-end tasks (e.g., RNA-seq, variant calling, metagenomics) with prompts that specify concrete output artifacts to support automated assessment, including stress testing under controlled perturbations. We evaluate frontier closed-source and open-weight models across multiple agent harnesses, and use an LLM-based grader to score pipeline progress and outcome validity. We find that frontier agents can complete multi-step bioinformatics pipelines without elaborate custom scaffolding, often producing the requested final artifacts reliably. However, robustness tests reveal failure modes under controlled perturbations (corrupted inputs, decoy files, and prompt bloat), indicating that correct high-level pipeline construction does not guarantee reliable step-level reasoning. Finally, because bioinformatics workflows may involve sensitive patient data, proprietary references, or unpublished IP, closed-source models can be unsuitable under strict privacy constraints; in such settings, open-weight models may be preferable despite lower completion rates. We release the dataset and evaluation suite publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces BioAgent Bench, a benchmark dataset and evaluation suite for AI agents on bioinformatics tasks such as RNA-seq, variant calling, and metagenomics. Curated end-to-end tasks specify concrete output artifacts to enable automated assessment via an LLM-based grader. Frontier closed- and open-weight models are evaluated across agent harnesses, with results showing reliable completion of multi-step pipelines without custom scaffolding but clear failure modes under controlled perturbations (corrupted inputs, decoy files, prompt bloat). The work also highlights privacy advantages of open-weight models for sensitive data.
Significance. If the evaluation methodology holds, the benchmark would provide a valuable public resource for measuring agent performance and robustness in a high-stakes scientific domain. It usefully separates high-level pipeline success from step-level reliability and addresses real deployment constraints around data privacy. Public release of the dataset and suite is a clear strength that could support reproducible follow-on work.
major comments (2)
- [Evaluation section] Evaluation section (LLM grader description): No inter-annotator agreement, human-expert calibration, or ground-truth checks on edge cases (partial outputs, format-correct but biologically invalid results) are reported for the LLM-based grader. This directly undermines the central claims about completion rates and robustness, as grader errors could inflate success metrics for tasks like RNA-seq and variant calling.
- [Task curation and robustness tests] Task curation and robustness tests: Exact criteria for selecting and curating the end-to-end tasks, precise perturbation methods (e.g., how corrupted inputs or decoy files are generated and applied), and the full grader prompt are not provided. Without these, it is impossible to assess reproducibility or potential biases in the reported failure modes.
minor comments (1)
- [Abstract] The abstract would benefit from stating the total number of tasks, models, and agent harnesses evaluated to convey scale more precisely.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on BioAgent Bench. We appreciate the recognition of the benchmark's value for evaluating agent robustness in bioinformatics and address each major comment below. We will revise the manuscript to provide the requested details and validations.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (LLM grader description): No inter-annotator agreement, human-expert calibration, or ground-truth checks on edge cases (partial outputs, format-correct but biologically invalid results) are reported for the LLM-based grader. This directly undermines the central claims about completion rates and robustness, as grader errors could inflate success metrics for tasks like RNA-seq and variant calling.
Authors: We agree that explicit validation of the LLM grader is necessary to substantiate our reported completion rates and robustness findings. In the revised manuscript, we will expand the Evaluation section to include: inter-annotator agreement metrics (e.g., Cohen's kappa scores from a sample of 100 graded outputs reviewed by two domain experts), details on human-expert calibration procedures, and targeted ground-truth checks on edge cases including partial outputs and format-correct but biologically invalid results. These additions will quantify grader reliability and directly address potential inflation of success metrics. revision: yes
-
Referee: [Task curation and robustness tests] Task curation and robustness tests: Exact criteria for selecting and curating the end-to-end tasks, precise perturbation methods (e.g., how corrupted inputs or decoy files are generated and applied), and the full grader prompt are not provided. Without these, it is impossible to assess reproducibility or potential biases in the reported failure modes.
Authors: We acknowledge that greater transparency is required for reproducibility. The revised manuscript will include an expanded Methods section and new appendix with: (1) the exact criteria for task selection and curation (e.g., prevalence in PubMed, availability of reference datasets, and pipeline complexity thresholds), (2) precise perturbation methods including generation of corrupted inputs (via controlled noise injection) and decoy files (via random file insertion with specified probabilities), and (3) the complete grader prompt. These details will enable assessment of biases and support independent reproduction. revision: yes
Circularity Check
Empirical benchmark introduction with no derivations or self-referential reductions
full rationale
The paper presents BioAgent Bench as a new dataset and evaluation suite for AI agents on bioinformatics tasks such as RNA-seq and variant calling. It reports empirical results from running frontier models under various harnesses and an LLM grader, with findings on completion rates and robustness to perturbations. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes appear anywhere in the manuscript. All claims rest on newly curated tasks, released data, and direct evaluations rather than any chain that reduces to its own definitions or prior self-citations. The LLM grader is used for scoring but is not presented as a derived result; its limitations are external to circularity analysis.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Sound Agentic Science Requires Adversarial Experiments
Agentic science needs a falsification-first standard in which LLM agents actively search for ways a claim can fail rather than generating supporting narratives.
Reference graph
Works this paper leans on
-
[1]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
URL https://openreview.net/forum? id=VTF8yNQM66. Lakshman, A.CompGenomicsBioc2022: Compara- tive Genomics Analyses with SynExtend and DECI- PHER, 2024. URL https://www.ahl27.com/ CompGenomicsBioc2022/. R package version 3.4.0. Laurent, J. M., Janizek, J. D., Ruzo, M., Hinks, M. M., Hammerling, M. J., Narayanan, S., Ponnapati, M., White, A. D., and Rodriqu...
work page internal anchor Pith review arXiv 2024
-
[2]
URL https: //doi.org/10.1038/s42003-022-04088-z
doi: 10.1038/s42003-022-04088-z. URL https: //doi.org/10.1038/s42003-022-04088-z. Miller, H. E., Greenig, M., Tenmann, B., and Wang, B. Bioml-bench: Evaluation of ai agents for end-to-end biomedical ml.bioRxiv, 2025. doi: 10.1101/2025.09. 01.673319. Mitchener, L., Laurent, J. M., Andonian, A., Tenmann, B., Narayanan, S., Wellawatte, G. P., White, A., Sani...
-
[3]
URL https: //doi.org/10.1038/s41592-021-01254-9
doi: 10.1038/s41592-021-01254-9. URL https: //doi.org/10.1038/s41592-021-01254-9. Zhou, J., Huang, C., and Gao, X. Patient privacy in AI- driven omics methods.Trends in Genetics, 40(5):383– 386, 2024. doi: 10.1016/j.tig.2024.03.004. Ziri´on-Mart´ınez, C., Garfias-Gallegos, D., Arellano- Fernandez, T., Espinosa-Jaime, A., Bustos-D ´ıaz, E., Lovaco-Flores, ...
-
[4]
You are given the paths of the input and the reference data which the agent was given to work with
-
[5]
You are given the whole directory structure of the agent’s work and it is your job to estimate how close to completing the pipeline the agent came
-
[6]
You are given the final results which the agent was instructed to produce, if they exist
-
[7]
You are givne the truth data which is the expected output of the prompted pipeline
-
[8]
Inputs (provided at evaluation time) •1
You are given the prompt which the agent was given to complete. Inputs (provided at evaluation time) •1. Input data:{input data} •2. Reference data:{reference data} •3. Processing tree:{processing tree} •4. Results:{results} •5. Truth:{truth} •6. Prompt:{task prompt} Evaluation rules: •Priortize evaluation of the pipeline completion over the correctness o...
-
[9]
steps completed: int --- The number of steps that the agent completed
-
[10]
steps to completion: int --- The number of steps that the agent was expected to complete
-
[11]
final result reached: bool --- Whether the agent reached the final result
-
[12]
notes: str --- Summarize where the agent stopped if stopped and what steps are left to be done
-
[13]
!"(Phred 0). • evolution: ancestor *.fastq.gz (only files containing
results match: bool --- Set to true/false (or 1/0) per the rule above. You are supposed to return the metrics as a JSON object with fields that satisifes the schema: EvaluationResults A.5. Harness evaluation Table 4 shows completions rates per model and task for different harnesses. 14 BioAgent Bench: Evaluation Harness for AI Agents in Bioinformatics Tab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.