Adapting a Text-to-Audio Model for Room Impulse Response Generation
Pith reviewed 2026-05-15 13:35 UTC · model grok-4.3
The pith
Adapting a pre-trained text-to-audio model generates plausible room impulse responses from text descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training on text-RIR pairs derived from vision-language labeling of image datasets and applying in-context learning for prompt handling, a pre-trained text-to-audio model can be adapted to generate room impulse responses whose acoustic properties match the input text descriptions, marking the first demonstration that large-scale generative audio priors can be leveraged for this purpose.
What carries the argument
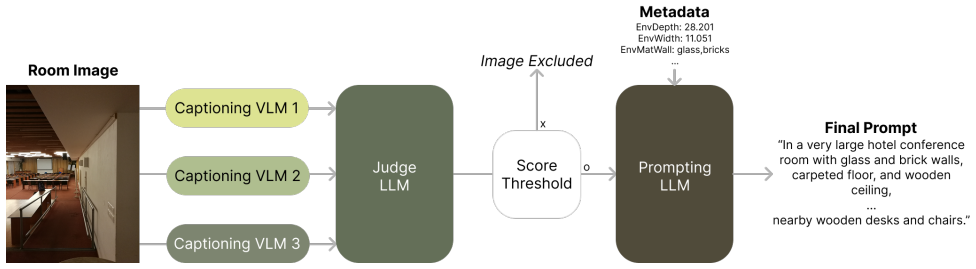
The adapted text-to-audio model conditioned on acoustic text descriptions obtained from a vision-language model labeling pipeline on image-RIR pairs, using an in-context learning strategy to support free-form prompts.
If this is right
- RIRs can be produced on demand for speech data augmentation without new physical measurements.
- Users can specify custom room acoustics through natural language prompts during inference.
- Large pre-trained audio models become viable starting points for other data-scarce acoustic generation tasks.
- Subjective plausibility of outputs supports immediate use in multimedia production pipelines.
Where Pith is reading between the lines
- Refining the vision-language labeling step for more precise acoustic attributes could raise the fidelity of generated RIRs.
- The same adaptation pattern may apply to generating other impulse responses or spatial audio effects from descriptive text.
- Hybrid systems that combine the adapted model with physics-based simulation could add controllability while retaining generative flexibility.
Load-bearing premise
The text descriptions extracted by vision-language models from room images accurately reflect the acoustic properties required to train a model that produces realistic room impulse responses.
What would settle it
A blind listening test in which human listeners cannot distinguish the generated RIRs from real recorded ones when used to render the same source signals, or objective acoustic metrics such as reverberation time and early reflection patterns that systematically deviate from real RIR distributions.
Figures
read the original abstract
Room Impulse Responses (RIRs) enable realistic acoustic simulation, with applications ranging from multimedia production to speech data augmentation. However, acquiring high-quality real-world RIRs is labor-intensive, and data scarcity remains a challenge for data-driven RIR generation approaches. In this paper, we propose a novel approach to RIR generation by adapting a pre-trained text-to-audio model, demonstrating for the first time that large-scale generative audio priors can be effectively leveraged for the task. To address the lack of text-RIR paired data, we utilize a labeling pipeline leveraging vision-language models to extract acoustic descriptions from existing image-RIR datasets. We introduce an in-context learning strategy to accommodate free-form user prompts during inference. Evaluations including subjective listening test demonstrate that our model generates plausible RIRs. Audio examples are available on our demo website.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to demonstrate the first effective adaptation of a large-scale pre-trained text-to-audio generative model for room impulse response (RIR) synthesis. To overcome the lack of paired text-RIR data, it introduces a vision-language model (VLM) labeling pipeline that extracts free-form acoustic descriptions from existing image-RIR datasets, fine-tunes the audio prior on these pairs, and employs in-context learning to support arbitrary user prompts at inference. Subjective listening tests are reported to show that the generated RIRs are plausible.
Significance. If the central adaptation claim holds after verification, the work would be significant as the first demonstration that large-scale generative audio priors can be repurposed for RIR generation, offering a scalable route to address data scarcity in acoustic simulation and speech augmentation. The in-context learning component could further enable flexible text-conditioned RIR synthesis beyond fixed datasets.
major comments (2)
- [Section 3] Section 3 (labeling pipeline): the claim that VLM-generated text descriptions accurately encode the acoustic properties (room volume, absorption, geometry) needed for effective adaptation is load-bearing, yet no quantitative validation is provided correlating the extracted labels with measurable RIR statistics such as RT60, DRR, or EDT, nor with human acoustic judgments of the source images. Without this check, fine-tuning may learn spurious visual-to-RIR mappings rather than leveraging the audio prior.
- [Evaluation] Evaluation section (and abstract): only subjective listening tests are reported, with no quantitative metrics (e.g., objective RIR error measures), no baseline comparisons against existing RIR generation methods, and no details on the adaptation/fine-tuning procedure (loss, hyperparameters, data splits). This limits assessment of whether the generative prior is actually being leveraged effectively.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit statements of the pre-trained text-to-audio model architecture and dataset sizes used for adaptation.
- Audio examples on the demo website are referenced but no quantitative analysis of failure cases (e.g., implausible reverberation times) is included in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate additional validation and evaluation details.
read point-by-point responses
-
Referee: [Section 3] Section 3 (labeling pipeline): the claim that VLM-generated text descriptions accurately encode the acoustic properties (room volume, absorption, geometry) needed for effective adaptation is load-bearing, yet no quantitative validation is provided correlating the extracted labels with measurable RIR statistics such as RT60, DRR, or EDT, nor with human acoustic judgments of the source images. Without this check, fine-tuning may learn spurious visual-to-RIR mappings rather than leveraging the audio prior.
Authors: We agree that the absence of quantitative validation for the VLM labels is a limitation. In the revision, we will add a new analysis in Section 3 correlating the extracted acoustic descriptions with ground-truth RIR statistics (RT60, DRR, EDT) computed from the source dataset. We will also report results from a human listening study on a subset of image-description pairs to assess whether the VLM outputs align with perceived acoustic properties. This will help demonstrate that the labels support effective use of the audio prior rather than spurious mappings. revision: yes
-
Referee: [Evaluation] Evaluation section (and abstract): only subjective listening tests are reported, with no quantitative metrics (e.g., objective RIR error measures), no baseline comparisons against existing RIR generation methods, and no details on the adaptation/fine-tuning procedure (loss, hyperparameters, data splits). This limits assessment of whether the generative prior is actually being leveraged effectively.
Authors: We acknowledge that the current evaluation relies solely on subjective tests and lacks objective metrics, baselines, and methodological details. In the revised manuscript, we will expand the evaluation section to include objective measures such as acoustic parameter estimation errors (RT60, DRR) and spectrogram-based distances between generated and reference RIRs. We will add comparisons against established RIR generation baselines. We will also include a dedicated subsection detailing the fine-tuning procedure, including the loss function, hyperparameters, training schedule, and data splits. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper adapts an external pre-trained text-to-audio model for RIR generation via a VLM labeling pipeline on existing image-RIR datasets plus in-context learning at inference. No equations or steps reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; the central demonstration relies on external priors and new data pairing rather than tautological renaming or internal fitting. The derivation remains independent of its own outputs and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can extract acoustic descriptions from images in existing room impulse response datasets that are suitable for training text-conditioned generation
Reference graph
Works this paper leans on
-
[1]
Adapting a Text-to-Audio Model for Room Impulse Response Generation
Introduction Room Impulse Responses (RIRs) characterize the acoustic transfer function of an enclosed space, capturing how sound propagates and interacts with the environment through reflec- tion, absorption, and scattering. Convolving anechoic audio sig- nal with an RIR simulates how a signal would sound within that specific space. Consequently, RIRs are...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Finetuning a Text-to-Audio Model for blind RIR Generation 2.1. Problem Definition This work targets blind RIR generation, which generates a plau- sible RIR for an unseen room given limited information of the room (in our case, natural language description). This problem setup is distinct from RIR estimation tasks that infer RIRs for unseen source-receiver...
-
[3]
Experiments 3.1. Experimental Setup We conducted our experiments using the BUT ReverbDB [17] , which provide real-world RIRs paired with room images. We split the dataset in room-disjoint manner into 1,736 train- ing samples from seven rooms and 589 test samples from two rooms of contrasting sizes: L207 (465 samples, 98 m3) and CR2 (124 samples, 1,033 m3)...
-
[4]
Conclusion We present a novel text conditioned RIR generation approach by fine-tuning a pre-trained TTA generative model. We demon- strate for the first time that large-scale generative audio priors can be effectively leveraged for RIR generation task. By over- coming data scarcity via finetuning and VLM driven labeling pipeline, our model generates high-...
-
[5]
Generative AI Use Disclosure The authors used LLMs to polish the manuscript
-
[6]
Image method for efficiently simulating small-room acoustics,
J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,”The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 04 1979. [Online]. Available: https://doi.org/10.1121/1.382599
-
[7]
Calculating the acoustical room response by the use of a ray tracing technique,
A. Krokstad, S. Strom, and S. Sørsdal, “Calculating the acoustical room response by the use of a ray tracing technique,” Journal of Sound and Vibration, vol. 8, no. 1, pp. 118– 125, 1968. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/0022460X68901983
-
[8]
Finite-difference time-domain simulation of low-frequency room acoustic problems,
D. Botteldooren, “Finite-difference time-domain simulation of low-frequency room acoustic problems,”The Journal of the Acoustical Society of America, vol. 98, no. 6, pp. 3302–3308, 12
-
[9]
Available: https://doi.org/10.1121/1.413817
[Online]. Available: https://doi.org/10.1121/1.413817
-
[10]
Im- age2reverb: Cross-modal reverb impulse response synthesis,
N. Singh, J. Mentch, J. Ng, M. Beveridge, and I. Drori, “Im- age2reverb: Cross-modal reverb impulse response synthesis,” in Proceedings of the IEEE/CVF International Conference on Com- puter Vision, 2021, pp. 286–295
work page 2021
-
[11]
Av-rir: Audio-visual room impulse response estimation,
A. Ratnarajah, S. Ghosh, S. Kumar, P. Chiniya, and D. Manocha, “Av-rir: Audio-visual room impulse response estimation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 164–27 175
work page 2024
-
[12]
Room impulse response generation conditioned on acoustic parameters,
S. Arellano, C. Yeh, G. Bhattacharya, and D. Arteaga, “Room impulse response generation conditioned on acoustic parameters,” 10 2025, pp. 1–5
work page 2025
-
[13]
Yet another generative model for room impulse response estimation,
S. Lee, H.-S. Choi, and K. Lee, “Yet another generative model for room impulse response estimation,” in2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WAS- PAA), 2023, pp. 1–5
work page 2023
-
[14]
Daras: Dynamic audio-room acous- tic synthesis for blind room impulse response estimation,
C. Wang, M. Jia, and W. Jin, “Daras: Dynamic audio-room acous- tic synthesis for blind room impulse response estimation,”IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[15]
Promptreverb: Multimodal room impulse response generation through latent rectified flow matching,
A. V osoughi, Y . Zang, Q. Yang, N. Paek, R. Leistikow, and C. Xu, “Promptreverb: Multimodal room impulse response generation through latent rectified flow matching,” 2025. [Online]. Available: https://arxiv.org/abs/2510.22439
-
[16]
Acoustic volume ren- dering for neural impulse response fields,
Z. Lan, C. Zheng, Z. Zheng, and M. Zhao, “Acoustic volume ren- dering for neural impulse response fields,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2024
work page 2024
-
[17]
Learning neural acoustic fields,
A. Luo, Y . Du, M. J. Tarr, J. B. Tenenbaum, A. Torralba, and C. Gan, “Learning neural acoustic fields,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
work page 2022
-
[18]
Temporal modeling of room impulse response generation via multi-scale autoregressive learning,
S. Lyu, Y . Yu, and C. Wu, “Temporal modeling of room impulse response generation via multi-scale autoregressive learning,” 08 2025, pp. 923–927
work page 2025
-
[19]
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable audio open,” inICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
work page 2025
-
[20]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”J. Mach. Learn. Res., vol. 21, no. 1, Jan. 2020
work page 2020
-
[21]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhari- wal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. A...
work page 2020
-
[22]
Can large language models predict audio ef- fects parameters from natural language?
S. Doh, J. Koo, M. A. Mart ´ınez-Ram´ırez, W.-H. Liao, J. Nam, and Y . Mitsufuji, “Can large language models predict audio ef- fects parameters from natural language?” in2025 IEEE Work- shop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2025, pp. 1–5
work page 2025
-
[23]
Building and evaluation of a real room impulse response dataset,
I. Sz ¨oke, M. Sk ´acel, L. Mo ˇsner, J. Paliesek, and J. ˇCernock`y, “Building and evaluation of a real room impulse response dataset,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 4, pp. 863–876, 2019
work page 2019
-
[24]
International Telecommunications Union, “ITU-R BS.1534: Method for the subjective assessment of intermediate quality lev- els of coding systems,” ITU-R, Tech. Rep., Jul. 2014, recommen- dation ITU-R BS.1534
work page 2014
-
[25]
Lib- rispeech: An asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An asr corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
work page 2015
-
[26]
webmushra—a comprehensive framework for web-based listening tests,
M. Schoeffler, S. Bartoschek, F.-R. St ¨oter, M. Roess, S. Westphal, B. Edler, and J. Herre, “webmushra—a comprehensive framework for web-based listening tests,”Journal of open research software, vol. 6, no. 1, 2018
work page 2018
-
[27]
Whisperx: Time-accurate speech transcription of long-form audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “Whisperx: Time-accurate speech transcription of long-form audio,”INTER- SPEECH 2023, 2023
work page 2023
-
[28]
A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual eval- uation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in2001 IEEE In- ternational Conference on Acoustics, Speech, and Signal Process- ing. Proceedings (Cat. No.01CH37221), vol. 2, 2001, pp. 749– 752 vol.2
work page 2001
-
[29]
An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Lan- guage Processing, vol. 19, no. 7, pp. 2125–2136, 2011
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.