Safety-critical Control Under Partial Observability: Reach-Avoid POMDP meets Belief Space Control
Pith reviewed 2026-05-15 13:46 UTC · model grok-4.3
The pith
A layered belief-space architecture decouples safety, goal reaching, and information gathering to solve reach-avoid POMDPs via real-time quadratic programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
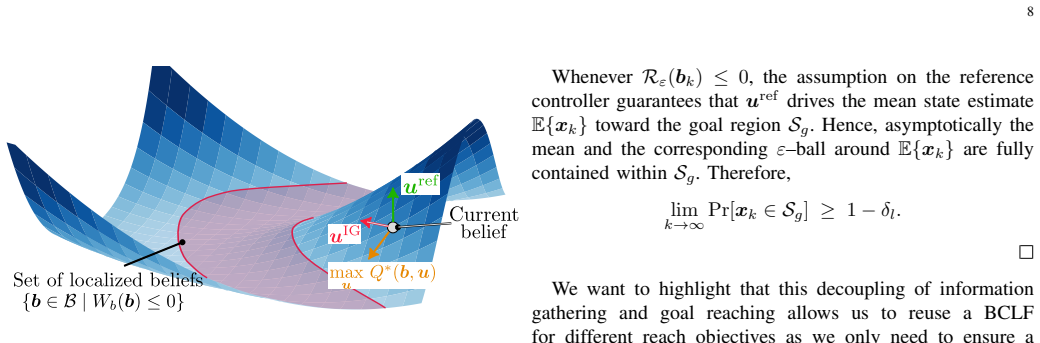
The paper claims that reach-avoid POMDPs can be solved by a certificate-based controller in belief space: Belief Control Lyapunov Functions formalize and learn information gathering as Lyapunov stability in belief space, Belief Control Barrier Functions supply probabilistic safety certificates via conformal prediction, and the three objectives are unified through lightweight quadratic programs that are solvable in real time for non-Gaussian beliefs whose dimension exceeds 10^4.
What carries the argument
Belief Control Lyapunov Functions (BCLFs) and Belief Control Barrier Functions (BCBFs) that operate in belief space, with BCLFs learned via reinforcement learning to handle information gathering and BCBFs using conformal prediction to enforce safety.
If this is right
- Control synthesis reduces to lightweight quadratic programs that run online without exhaustive belief-tree search.
- Probabilistic safety guarantees hold over finite horizons even for non-Gaussian belief representations larger than 10,000 dimensions.
- Information gathering is treated as a Lyapunov convergence problem that can be learned separately from safety and goal layers.
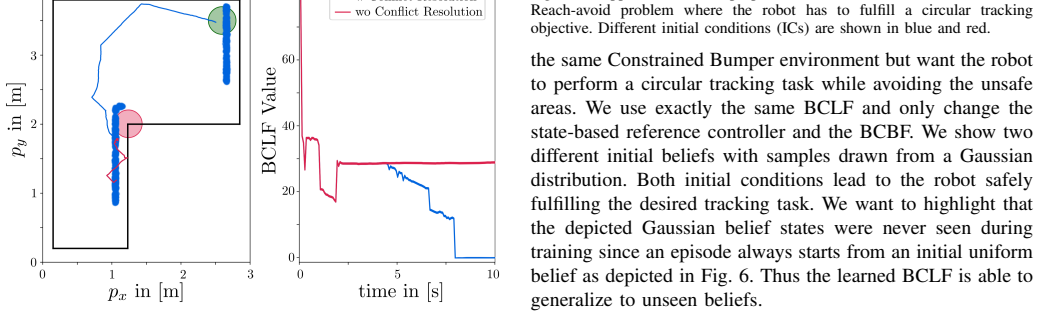
- Experiments show improved safety and task success rates compared with state-of-the-art constrained POMDP solvers.
Where Pith is reading between the lines
- The decoupling into independent certificates may let each layer be verified or improved in isolation before recomposition.
- The same quadratic-program structure could be reused for other partially observable tasks by replacing the specific BCLF or BCBF definitions.
- Because the method already handles non-Gaussian beliefs, it may extend to sensor fusion pipelines that produce multimodal uncertainty without additional approximation steps.
Load-bearing premise
Belief Control Lyapunov Functions learned via reinforcement learning will reliably drive information gathering without destabilizing the safety or goal-reaching layers under the non-Gaussian beliefs encountered in practice.
What would settle it
A run on the space-robotics platform or simulation in which the quadratic program produces a control input that violates the finite-horizon safety certificate or fails to reduce belief uncertainty enough to reach the goal, despite using the learned BCLF and BCBF.
Figures











read the original abstract
Partially Observable Markov Decision Processes (POMDPs) provide a principled framework for robot decision-making under uncertainty. Solving reach-avoid POMDPs, however, requires coordinating three distinct behaviors: goal reaching, safety, and active information gathering to reduce uncertainty. Existing online POMDP solvers attempt to address all three within a single belief tree search, but this unified approach struggles with the conflicting time scales inherent to these objectives. We propose a layered, certificate-based control architecture that operates directly in belief space, decoupling goal reaching, information gathering, and safety into modular components. We introduce Belief Control Lyapunov Functions (BCLFs) that formalize information gathering as a Lyapunov convergence problem in belief space, and show how they can be learned via reinforcement learning. For safety, we develop Belief Control Barrier Functions (BCBFs) that leverage conformal prediction to provide probabilistic safety guarantees over finite horizons. The resulting control synthesis reduces to lightweight quadratic programs solvable in real time, even for non-Gaussian belief representations with dimension $>10^4$. Experiments in simulation and on a space-robotics platform demonstrate real-time performance and improved safety and task success compared to state-of-the-art constrained POMDP solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a layered certificate-based architecture for reach-avoid POMDPs that decouples goal reaching, information gathering, and safety in belief space. It introduces Belief Control Lyapunov Functions (BCLFs) learned via reinforcement learning to encode information gathering as a Lyapunov convergence problem in belief space, and Belief Control Barrier Functions (BCBFs) that use conformal prediction to deliver finite-horizon probabilistic safety guarantees. The resulting synthesis is reduced to a set of lightweight quadratic programs claimed to be solvable in real time even for non-Gaussian beliefs whose dimension exceeds 10^4, with supporting experiments on simulation and a space-robotics platform.
Significance. If the learned BCLFs provably maintain Lyapunov decrease under the closed-loop belief trajectories generated by the online QP and if the conformal calibration remains valid under the induced non-stationary dynamics, the work would constitute a meaningful practical advance: it supplies a modular, real-time alternative to unified belief-tree POMDP solvers that struggle with conflicting time scales, while extending certificate-based safety methods to high-dimensional non-Gaussian beliefs.
major comments (2)
- [BCLF definition and RL training] The central claim that control synthesis reduces to lightweight real-time QPs for non-Gaussian beliefs of dimension >10^4 rests on the assumption that RL-trained BCLFs will produce a stable Lyapunov decrease for information gathering that can be safely combined with BCBF constraints. No explicit argument, generalization bound, or closed-loop stability analysis is supplied showing that the learned BCLFs remain valid under the belief updates that arise when the QP is solved online; this assumption is load-bearing for both the real-time performance and the safety guarantees.
- [BCBF construction and conformal calibration] The finite-horizon probabilistic safety bounds obtained via conformal prediction for the BCBFs implicitly require that the calibration distribution remains representative under the non-stationary belief dynamics produced by the closed-loop controller. The manuscript provides no analysis or empirical check of how the conformal guarantee degrades when the belief trajectory is shaped by the QP that itself depends on the BCLF and BCBF terms; violation of this stationarity assumption would directly undermine the claimed safety certificates.
minor comments (2)
- [Abstract] The abstract asserts 'improved safety and task success' without quoting the quantitative metrics or baselines used; adding the specific success-rate and safety-violation numbers would improve clarity.
- [Experiments] The list of free parameters (RL hyperparameters for BCLF training) is acknowledged but no sensitivity analysis or ablation is reported; a brief table showing performance variation with these hyperparameters would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional justification would strengthen our claims. We address each major comment below and commit to revisions that incorporate further discussion and empirical validation without altering the core contributions.
read point-by-point responses
-
Referee: [BCLF definition and RL training] The central claim that control synthesis reduces to lightweight real-time QPs for non-Gaussian beliefs of dimension >10^4 rests on the assumption that RL-trained BCLFs will produce a stable Lyapunov decrease for information gathering that can be safely combined with BCBF constraints. No explicit argument, generalization bound, or closed-loop stability analysis is supplied showing that the learned BCLFs remain valid under the belief updates that arise when the QP is solved online; this assumption is load-bearing for both the real-time performance and the safety guarantees.
Authors: We agree that a formal closed-loop stability analysis and generalization bound would provide stronger theoretical support. Our BCLFs are trained offline via RL to promote convergence in belief space, and the QP is formulated to enforce the decrease condition at each timestep based on the current belief estimate. In the revision we will add a dedicated subsection outlining the assumptions required for Lyapunov decrease preservation under the QP-induced belief updates, along with new empirical results plotting BCLF values over closed-loop trajectories from our simulation and hardware experiments. This modular separation enables practical real-time performance while the experiments demonstrate reliable behavior, even absent a complete theoretical guarantee. revision: partial
-
Referee: [BCBF construction and conformal calibration] The finite-horizon probabilistic safety bounds obtained via conformal prediction for the BCBFs implicitly require that the calibration distribution remains representative under the non-stationary belief dynamics produced by the closed-loop controller. The manuscript provides no analysis or empirical check of how the conformal guarantee degrades when the belief trajectory is shaped by the QP that itself depends on the BCLF and BCBF terms; violation of this stationarity assumption would directly undermine the claimed safety certificates.
Authors: We acknowledge the validity of this concern regarding potential non-stationarity. In the revised manuscript we will add an empirical calibration study in the experiments section: calibration data will be collected from trajectories generated by the full closed-loop QP controller (incorporating both BCLF and BCBF terms), and we will report the observed safety violation rates versus the conformal-predicted probabilities. This check will confirm that the finite-horizon guarantees hold under the induced dynamics for the evaluated scenarios. revision: yes
Circularity Check
Derivation chain is self-contained; no reductions to fitted inputs or self-citations by construction
full rationale
The paper introduces BCLFs formalized as Lyapunov functions in belief space and learned via RL, alongside BCBFs using conformal prediction for probabilistic guarantees. The reduction of control synthesis to real-time QPs follows directly from enforcing the certificate conditions in the modular QP formulation. No step equates a prediction to its own fitted parameters by construction, nor does any central claim rest on a self-citation chain that itself lacks independent verification. The architecture is presented as a new synthesis method combining existing certificate ideas with RL and conformal methods, remaining self-contained against external benchmarks without renaming known results or smuggling ansatzes via citation.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL hyperparameters for BCLF training
axioms (1)
- domain assumption Belief updates follow standard POMDP transition and observation models
invented entities (2)
-
Belief Control Lyapunov Functions (BCLFs)
no independent evidence
-
Belief Control Barrier Functions (BCBFs)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Risk-Constrained Belief-Space Optimization for Safe Control under Latent Uncertainty
A belief-space MPPI controller with CVaR safety constraints achieves 82% success and zero contact violations in uncertain robotic insertion simulations, outperforming risk-neutral and chance-constrained baselines.
Reference graph
Works this paper leans on
-
[1]
Partially observable markov decision processes and robotics,
H. Kurniawati, “Partially observable markov decision processes and robotics,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. 1, pp. 253–277, 2022
work page 2022
-
[2]
A. Zhitnikov and V . Indelman, “Simplified continuous high-dimensional belief space planning with adaptive probabilistic belief-dependent con- straints,”IEEE Transactions on Robotics, vol. 40, pp. 1684–1705, 2023
work page 2023
-
[3]
Anytime probabilistically constrained provably convergent online belief space planning,
A. zhitnikov and V . Indelman, “Anytime probabilistically constrained provably convergent online belief space planning,”IEEE Transactions on Robotics, 2025
work page 2025
-
[4]
R. J. Moss, A. Jamgochian, J. Fischer, A. Corso, and M. J. Kochenderfer, “Constrainedzero: chance-constrained pomdp planning using learned 18 probabilistic failure surrogates and adaptive safety constraints,” inPro- ceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 6752–6760
work page 2024
-
[5]
Mobile robot control and navigation: A global overview,
S. G. Tzafestas, “Mobile robot control and navigation: A global overview,”Journal of Intelligent & Robotic Systems, vol. 91, no. 1, pp. 35–58, 2018
work page 2018
-
[6]
Stabilization with relaxed controls,
Z. Artstein, “Stabilization with relaxed controls,”Nonlinear Analysis: Theory, Methods & Applications, vol. 7, no. 11, pp. 1163–1173, 1983
work page 1983
-
[7]
Autonomous ucav strike missions using behavior control lyapunov functions,
P. Ogren, A. Backlund, T. Harryson, L. Kristensson, and P. Stensson, “Autonomous ucav strike missions using behavior control lyapunov functions,” inAIAA guidance, navigation, and control conference and exhibit, 2006, p. 6197
work page 2006
-
[8]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 3861–3876, 2016
work page 2016
-
[9]
Belief control barrier functions for risk-aware control,
M. Vahs, C. Pek, and J. Tumova, “Belief control barrier functions for risk-aware control,”IEEE Robotics and Automation Letters, vol. 8, no. 12, pp. 8565–8572, 2023
work page 2023
-
[10]
Risk-aware control for robots with non- gaussian belief spaces,
M. Vahs and J. Tumova, “Risk-aware control for robots with non- gaussian belief spaces,” inInternational Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 661–11 667
work page 2024
-
[11]
Point-based value iteration for continuous pomdps,
J. M. Porta, N. Vlassis, M. T. Spaan, and P. Poupart, “Point-based value iteration for continuous pomdps,”Journal of Machine Learning Research, vol. 7, pp. 2329–2367, 2006
work page 2006
-
[12]
Perseus: Randomized point-based value iteration for pomdps,
M. T. Spaan and N. Vlassis, “Perseus: Randomized point-based value iteration for pomdps,”Journal of artificial intelligence research, vol. 24, pp. 195–220, 2005
work page 2005
-
[13]
Heuristic search value iteration for pomdps,
T. Smith and R. Simmons, “Heuristic search value iteration for pomdps,” inProceedings of the 20th conference on Uncertainty in artificial intelligence, 2004, pp. 520–527
work page 2004
-
[14]
Point-based pomdp algorithms: improved analysis and implementation,
T. smith and R. Simmons, “Point-based pomdp algorithms: improved analysis and implementation,” inProceedings of the Twenty-First Con- ference on Uncertainty in Artificial Intelligence, 2005, pp. 542–549
work page 2005
-
[15]
Sarsop: Efficient point-based pomdp planning by approximating optimally reachable belief spaces
H. Kurniawati, D. Hsu, W. S. Leeet al., “Sarsop: Efficient point-based pomdp planning by approximating optimally reachable belief spaces.” in Robotics: Science and systems, vol. 2008. Zurich, Switzerland, 2008
work page 2008
-
[16]
Despot-alpha: Online pomdp planning with large state and observation spaces
N. P. Garg, D. Hsu, and W. S. Lee, “Despot-alpha: Online pomdp planning with large state and observation spaces.” inRobotics: Science and Systems, vol. 3, no. 3, 2019, pp. 3–2
work page 2019
-
[17]
An on-line pomdp solver for contin- uous observation spaces,
M. Hoerger and H. Kurniawati, “An on-line pomdp solver for contin- uous observation spaces,” inInternational conference on robotics and automation (ICRA). IEEE, 2021, pp. 7643–7649
work page 2021
-
[18]
Sparse tree search optimality guarantees in pomdps with continuous observation spaces,
M. H. Lim, C. J. Tomlin, and Z. N. Sunberg, “Sparse tree search optimality guarantees in pomdps with continuous observation spaces,” in Proceedings of the Twenty-Ninth International Conference on Interna- tional Joint Conferences on Artificial Intelligence, 2021, pp. 4135–4142
work page 2021
-
[19]
Bayesian optimized monte carlo planning,
J. Mern, A. Yildiz, Z. Sunberg, T. Mukerji, and M. J. Kochenderfer, “Bayesian optimized monte carlo planning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 13, 2021, pp. 11 880– 11 887
work page 2021
-
[20]
Online algorithms for pomdps with continuous state, action, and observation spaces,
Z. Sunberg and M. Kochenderfer, “Online algorithms for pomdps with continuous state, action, and observation spaces,” inProceedings of the International Conference on Automated Planning and Scheduling, vol. 28, 2018, pp. 259–263
work page 2018
-
[21]
Online pomdp planning with anytime deterministic guarantees,
M. Barenboim and V . Indelman, “Online pomdp planning with anytime deterministic guarantees,”Advances in Neural Information Processing Systems, vol. 36, pp. 79 886–79 902, 2023
work page 2023
-
[22]
Monte-carlo tree search for constrained pomdps,
J. Lee, G.-H. Kim, P. Poupart, and K.-E. Kim, “Monte-carlo tree search for constrained pomdps,”Advances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[23]
Online planning for constrained pomdps with continuous spaces through dual ascent,
A. Jamgochian, A. Corso, and M. J. Kochenderfer, “Online planning for constrained pomdps with continuous spaces through dual ascent,” inProceedings of the International Conference on Automated Planning and Scheduling, vol. 33, 2023, pp. 198–202
work page 2023
-
[24]
Address- ing myopic constrained pomdp planning with recursive dual ascent,
P. Stocco, S. Chundi, A. Jamgochian, and M. J. Kochenderfer, “Address- ing myopic constrained pomdp planning with recursive dual ascent,” in Proceedings of the International Conference on Automated Planning and Scheduling, vol. 34, 2024, pp. 565–569
work page 2024
-
[25]
Constrained hierarchical monte carlo belief-state planning,
A. Jamgochian, H. Buurmeijer, K. H. Wray, A. Corso, and M. J. Kochen- derfer, “Constrained hierarchical monte carlo belief-state planning,” in International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 2368–2374
work page 2024
-
[26]
Belief space planning assuming maximum likelihood observations,
R. Platt, R. Tedrake, L. P. Kaelbling, and T. Lozano-Perez, “Belief space planning assuming maximum likelihood observations,” inRobotics: Science and Systems, 2010
work page 2010
-
[27]
Motion planning under uncertainty using iterative local optimization in belief space,
J. Van Den Berg, S. Patil, and R. Alterovitz, “Motion planning under uncertainty using iterative local optimization in belief space,”The International Journal of Robotics Research, vol. 31, no. 11, pp. 1263– 1278, 2012
work page 2012
-
[28]
Closed-loop belief space planning for linear, gaussian systems,
M. P. Vitus and C. J. Tomlin, “Closed-loop belief space planning for linear, gaussian systems,” inInternational Conference on Robotics and Automation. IEEE, 2011, pp. 2152–2159
work page 2011
-
[29]
Risk-aware spatio-temporal logic planning in gaussian belief spaces,
M. Vahs, C. Pek, and J. Tumova, “Risk-aware spatio-temporal logic planning in gaussian belief spaces,” inInternational Conference on Robotics and Automation. IEEE, 2023, pp. 7879–7885
work page 2023
-
[30]
Non-gaussian belief space planning as a convex program,
R. Platt Jr and R. Tedrake, “Non-gaussian belief space planning as a convex program,” inProc. of the IEEE Conference on Robotics and Automation, 2012
work page 2012
-
[31]
Efficient planning in non-gaussian belief spaces and its application to robot grasping,
R. Platt, L. Kaelbling, T. Lozano-Perez, and R. Tedrake, “Efficient planning in non-gaussian belief spaces and its application to robot grasping,” inRobotics Research: The 15th International Symposium ISRR. Springer, 2016, pp. 253–269
work page 2016
-
[32]
Information acquisition with sensing robots: Algorithms and error bounds,
N. Atanasov, J. Le Ny, K. Daniilidis, and G. J. Pappas, “Information acquisition with sensing robots: Algorithms and error bounds,” in International conference on robotics and automation (ICRA). IEEE, 2014, pp. 6447–6454
work page 2014
-
[33]
Non-monotone energy-aware information gathering for heterogeneous robot teams,
X. Cai, B. Schlotfeldt, K. Khosoussi, N. Atanasov, G. J. Pappas, and J. P. How, “Non-monotone energy-aware information gathering for heterogeneous robot teams,” inInternational Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 8859–8865
work page 2021
-
[34]
Learning continuous control policies for information-theoretic active perception,
P. Yang, Y . Liu, S. Koga, A. Asgharivaskasi, and N. Atanasov, “Learning continuous control policies for information-theoretic active perception,” inInternational Conference on Robotics and Automation (ICRA). IEEE, 2023
work page 2023
-
[35]
Safe pomdp online planning among dynamic agents via adaptive conformal prediction,
S. Sheng, P. Yu, D. Parker, M. Kwiatkowska, and L. Feng, “Safe pomdp online planning among dynamic agents via adaptive conformal prediction,”IEEE Robotics and Automation Letters, 2024
work page 2024
-
[36]
Control theory meets pomdps: A hybrid systems approach,
M. Ahmadi, N. Jansen, B. Wu, and U. Topcu, “Control theory meets pomdps: A hybrid systems approach,”IEEE Transactions on Automatic Control, vol. 66, no. 11, pp. 5191–5204, 2020
work page 2020
-
[37]
Belief space control of safety-critical systems under state-dependent measurement noise,
R. Walia, M. Black, A. Schoer, and K. Leahy, “Belief space control of safety-critical systems under state-dependent measurement noise,”arXiv preprint arXiv:2510.14100, 2025
-
[38]
Risk-aware robot control in dynamic environments using belief control barrier functions,
S. Han, M. Vahs, and J. Tumova, “Risk-aware robot control in dynamic environments using belief control barrier functions,”arXiv preprint arXiv:2504.04097, 2025
-
[39]
Mobile sensor network control using mutual information methods and particle filters,
G. M. Hoffmann and C. J. Tomlin, “Mobile sensor network control using mutual information methods and particle filters,”IEEE Transactions on Automatic Control, vol. 55, no. 1, pp. 32–47, 2009
work page 2009
-
[40]
Mutual informa- tion methods with particle filters for mobile sensor network control,
G. M. Hoffmann, S. L. Waslander, and C. J. Tomlin, “Mutual informa- tion methods with particle filters for mobile sensor network control,” in Proceedings of the 45th Conference on Decision and Control. IEEE, 2006, pp. 1019–1024
work page 2006
-
[41]
Learning safe, generalizable perception-based hybrid control with certificates,
C. Dawson, B. Lowenkamp, D. Goff, and C. Fan, “Learning safe, generalizable perception-based hybrid control with certificates,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1904–1911, 2022
work page 1904
-
[42]
C. Dawson, S. Gao, and C. Fan, “Safe control with learned certificates: A survey of neural lyapunov, barrier, and contraction methods for robotics and control,”IEEE Transactions on Robotics, vol. 39, no. 3, pp. 1749– 1767, 2023
work page 2023
-
[43]
Safe nonlinear control using robust neural lyapunov-barrier functions,
C. Dawson, Z. Qin, S. Gao, and C. Fan, “Safe nonlinear control using robust neural lyapunov-barrier functions,” inConference on Robot Learning. PMLR, 2022, pp. 1724–1735
work page 2022
-
[44]
Learning barrier functions with memory for robust safe navigation,
K. Long, C. Qian, J. Cort ´es, and N. Atanasov, “Learning barrier functions with memory for robust safe navigation,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4931–4938, 2021
work page 2021
-
[45]
Barriernet: Differentiable control barrier functions for learning of safe robot control,
W. Xiao, T.-H. Wang, R. Hasani, M. Chahine, A. Amini, X. Li, and D. Rus, “Barriernet: Differentiable control barrier functions for learning of safe robot control,”IEEE Transactions on Robotics, vol. 39, no. 3, pp. 2289–2307, 2023
work page 2023
-
[46]
Distributionally robust lyapunov function search under uncertainty,
K. Long, Y . Yi, J. Cort ´es, and N. Atanasov, “Distributionally robust lyapunov function search under uncertainty,” inLearning for Dynamics and Control Conference. PMLR, 2023, pp. 864–877
work page 2023
-
[47]
Distributionally robust policy and lyapunov-certificate learning,
K. Long, J. Cortes, and N. Atanasov, “Distributionally robust policy and lyapunov-certificate learning,”IEEE Open Journal of Control Systems, 2024
work page 2024
-
[48]
J. Zhang, Q. Zhu, and W. Lin, “Neural stochastic control,”Advances in neural information processing systems, vol. 35, pp. 9098–9110, 2022
work page 2022
-
[49]
Neural continuous-time supermartingale certificates,
G. Neustroev, M. Giacobbe, and A. Lukina, “Neural continuous-time supermartingale certificates,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 26, 2025, pp. 27 538–27 546. 19
work page 2025
-
[50]
Learning a formally verified control barrier function in stochastic environment,
M. Tayal, H. Zhang, P. Jagtap, A. Clark, and S. Kolathaya, “Learning a formally verified control barrier function in stochastic environment,” in63rd Conference on Decision and Control (CDC). IEEE, 2024, pp. 4098–4104
work page 2024
-
[51]
Stochastic neural control barrier functions,
H. Zhang, M. Tayal, J. Cox, P. Jagtap, S. Kolathaya, and A. Clark, “Stochastic neural control barrier functions,”arXiv preprint arXiv:2506.21697, 2025
-
[52]
O. So, Z. Serlin, M. Mann, J. Gonzales, K. Rutledge, N. Roy, and C. Fan, “How to train your neural control barrier function: Learning safety filters for complex input-constrained systems,” inInternational Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 532–11 539
work page 2024
-
[53]
Safe value functions: Learned critics as hard safety constraints,
D. C. Tan, R. McCarthy, F. Acero, A. M. Delfaki, Z. Li, and D. Kanoulas, “Safe value functions: Learned critics as hard safety constraints,” in 20th International Conference on Automation Science and Engineering (CASE). IEEE, 2024, pp. 2441–2448
work page 2024
-
[54]
Safe model- based reinforcement learning with stability guarantees,
F. Berkenkamp, M. Turchetta, A. Schoellig, and A. Krause, “Safe model- based reinforcement learning with stability guarantees,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[55]
Generalizing safety beyond collision-avoidance via latent-space reachability analysis,
K. Nakamura, L. Peters, and A. Bajcsy, “Generalizing safety beyond collision-avoidance via latent-space reachability analysis,”arXiv preprint arXiv:2502.00935, 2025
-
[56]
S. Agrawal, J. Seo, K. Nakamura, R. Tian, and A. Bajcsy, “Anysafe: Adapting latent safety filters at runtime via safety constraint parameter- ization in the latent space,”arXiv preprint arXiv:2509.19555, 2025
-
[57]
K. Nakamura, A. L. Bishop, S. Man, A. M. Johnson, Z. Manchester, and A. Bajcsy, “How to train your latent control barrier function: Smooth safety filtering under hard-to-model constraints,” 2025. [Online]. Available: https://arxiv.org/abs/2511.18606
-
[58]
Rein- forcement learning for safe robot control using control lyapunov barrier functions,
D. Du, S. Han, N. Qi, H. B. Ammar, J. Wang, and W. Pan, “Rein- forcement learning for safe robot control using control lyapunov barrier functions,” inInternational Conference on Robotics and Automation, ICRA 2023. IEEE, 2023, pp. 9442–9448
work page 2023
-
[59]
Control barrier functions for stochastic systems,
A. Clark, “Control barrier functions for stochastic systems,”Automatica, vol. 130, p. 109688, 2021
work page 2021
-
[60]
Almost-sure safety guarantees of stochastic zero-control barrier functions do not hold,
O. So, A. Clark, and C. Fan, “Almost-sure safety guarantees of stochastic zero-control barrier functions do not hold,”arXiv preprint arXiv:2312.02430, 2023
-
[61]
Lyapunov theorems for stability and semistability of discrete-time stochastic systems,
W. M. Haddad and J. Lee, “Lyapunov theorems for stability and semistability of discrete-time stochastic systems,”Automatica, vol. 142, p. 110393, 2022
work page 2022
-
[62]
J. Lee, W. M. Haddad, and M. Lanchares, “Finite time stability and optimal finite time stabilization for discrete-time stochastic dynamical systems,”IEEE Transactions on Automatic Control, vol. 68, no. 7, pp. 3978–3991, 2022
work page 2022
-
[63]
A tutorial on conformal prediction
G. Shafer and V . V ovk, “A tutorial on conformal prediction.”Journal of Machine Learning Research, vol. 9, no. 3, 2008
work page 2008
-
[64]
L. Lindemann, Y . Zhao, X. Yu, G. J. Pappas, and J. V . Deshmukh, “Formal verification and control with conformal prediction: Practical safety guarantees for autonomous systems,”IEEE Control Systems, vol. 45, no. 6, pp. 72–122, 2025
work page 2025
-
[65]
A. H. Jazwinski,Stochastic processes and filtering theory. Courier Corporation, 2007
work page 2007
-
[66]
S ¨arkk¨a,Recursive Bayesian inference on stochastic differential equa- tions
S. S ¨arkk¨a,Recursive Bayesian inference on stochastic differential equa- tions. Helsinki University of Technology, 2006
work page 2006
-
[67]
Continuous-discrete filtering using ekf, ukf, and pf,
M. Mallick, M. Morelande, and L. Mihaylova, “Continuous-discrete filtering using ekf, ukf, and pf,” in15th International Conference on Information Fusion. IEEE, 2012, pp. 1087–1094
work page 2012
-
[68]
A survey of convergence results on particle filtering methods for practitioners,
D. Crisan and A. Doucet, “A survey of convergence results on particle filtering methods for practitioners,”IEEE Transactions on Signal Pro- cessing, vol. 50, no. 3, pp. 736–746, 2002
work page 2002
- [69]
-
[70]
Independent resampling sequential monte carlo algorithms,
R. Lamberti, Y . Petetin, F. Desbouvries, and F. Septier, “Independent resampling sequential monte carlo algorithms,”IEEE Transactions on Signal Processing, vol. 65, no. 20, pp. 5318–5333, 2017
work page 2017
-
[71]
Semi- independent resampling for particle filtering,
R. lamberti, Y . Petetin, F. Desbouvries, and F. Septier, “Semi- independent resampling for particle filtering,”IEEE Signal Processing Letters, vol. 25, no. 1, pp. 130–134, 2017
work page 2017
-
[72]
Tactile exploration with particle-based belief entropy,
L. Bruderm ¨uller, J. Jankowski, S. Calinon, M. Toussaint, and N. Hawes, “Tactile exploration with particle-based belief entropy,” in 2nd Workshop on Dexterous Manipulation: Design, Perception and Control (RSS), 2024. [Online]. Available: https://openreview.net/forum? id=7sKUwZvTD6
work page 2024
-
[73]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
work page 2017
-
[74]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
work page 2015
-
[75]
Composing control barrier functions for complex safety specifications,
T. G. Molnar and A. D. Ames, “Composing control barrier functions for complex safety specifications,”IEEE Control Systems Letters, vol. 7, pp. 3615–3620, 2023
work page 2023
-
[76]
Astrobee: A new platform for free-flying robotics on the international space station,
T. Smith, J. Barlow, M. Bualat, T. Fong, C. Provencher, H. Sanchez, and E. Smith, “Astrobee: A new platform for free-flying robotics on the international space station,” inInternational Symposium on Artificial Intelligence, Robotics, and Automation in Space (i-SAIRAS), no. ARC- E-DAA-TN31584, 2016
work page 2016
-
[77]
Stein particle filter for nonlinear, non-gaussian state estimation,
F. A. Maken, F. Ramos, and L. Ott, “Stein particle filter for nonlinear, non-gaussian state estimation,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5421–5428, 2022
work page 2022
-
[78]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
work page 2018
-
[79]
Verification of neural reachable tubes via scenario optimization and conformal prediction,
A. Lin and S. Bansal, “Verification of neural reachable tubes via scenario optimization and conformal prediction,” in6th Annual Learning for Dynamics & Control Conference. PMLR, 2024, pp. 719–731
work page 2024
-
[80]
Safe perception-based control under stochastic sensor uncertainty using con- formal prediction,
S. Yang, G. J. Pappas, R. Mangharam, and L. Lindemann, “Safe perception-based control under stochastic sensor uncertainty using con- formal prediction,” in62nd Conference on Decision and Control (CDC). IEEE, 2023, pp. 6072–6078. X. APPENDIX A. Proof of Theorem 5 Proof.First, we show that the CLF candidate is greater than zero everywhere outside the goal s...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.