Recognition: no theorem link
When Does Content-Based Routing Work? Representation Requirements for Selective Attention in Hybrid Sequence Models
Pith reviewed 2026-05-15 06:21 UTC · model grok-4.3
The pith
Content-based routing in hybrid sequence models requires pairwise token comparison to reach high precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
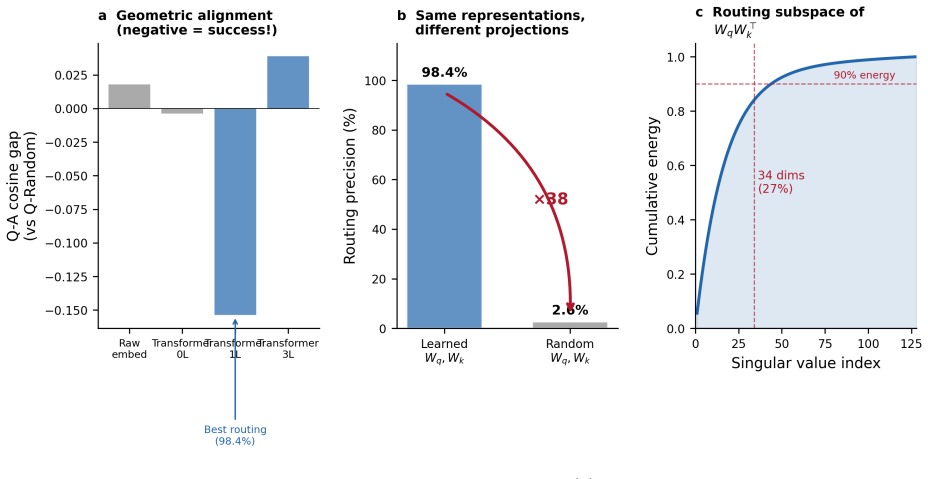
Every system achieving high routing precision does so through pairwise token comparison, while every mechanism that avoids pairwise computation clusters at 1-29 percent precision. The two necessary ingredients are per-token representations with bidirectional context and pairwise token comparison. Six different O(n) preprocessing steps succeed when paired with comparison, while global mean pooling and Fourier mixing fail. The routing signal occupies a roughly 34-dimensional latent subspace invisible to cosine similarity, and non-learned indices can bypass the learned bottleneck for exact matching.
What carries the argument
Pairwise token comparison applied to per-token representations that include bidirectional context, which isolates the routing signal from an approximately 34-dimensional subspace.
If this is right
- Bidirectional Mamba preprocessing plus pairwise comparison yields 99.5 percent routing precision.
- Replacing full pairwise routing with rank-1 projection improves accuracy to 99.7 percent while keeping linear inference cost.
- Inserting one bidirectional layer into a frozen Pythia-1B model recovers 99.4 percent routing.
- Six distinct O(n) preprocessing methods succeed when combined with pairwise comparison, but global mean pooling and Fourier mixing do not.
- Non-learned indices such as Bloom filters achieve 90.9 percent for exact matching without any learned routing.
Where Pith is reading between the lines
- Hybrid models that aim for selective attention will likely need to retain at least one explicit pairwise step even when the rest of the computation is linear.
- The low-dimensional nature of the routing signal suggests that future work could search for even cheaper projections than rank-1 while preserving accuracy.
- The success of non-learned indices for keyword tasks implies that learned routing may be unnecessary when the matching criterion is exact rather than semantic.
- Adding bidirectional context only at the preprocessing stage could be a modular way to upgrade existing causal models for better routing without full retraining.
Load-bearing premise
The three tasks, fifteen-plus mechanisms, and parameter scales tested are representative of all content-based routing needs in hybrid sequence models.
What would settle it
A routing mechanism using only recurrent states or memory banks that reaches above 90 percent routing precision on the same tasks and scales would falsify the necessity claim.
Figures





read the original abstract
We identify a routing paradox in hybrid sequence models: content-based routing - deciding which tokens deserve expensive attention - requires pairwise computation, and this requirement is inescapable. Through 20+ controlled experiments across three tasks, multiple scales (200K to 1.4B parameters), and 15+ routing mechanisms, we map the routing landscape exhaustively. Every system that achieves high routing precision does so through pairwise token comparison. Every mechanism that avoids pairwise computation fails: recurrent models (Mamba-1.4B: 29%), memory banks (12%), bandits (0.7-3.6%), contrastive pretraining (1.6%), and 12 other approaches all cluster at 1-29%. Routing needs two ingredients: (1) per-token representations with bidirectional context and (2) pairwise token comparison. Bidirectional Mamba (O(n)) + pairwise comparison achieves 99.5%; replacing the full pairwise router with rank-1 projection improves this to 99.7%. Adding one bidirectional layer to frozen Pythia-1B recovers 99.4% routing. Six different O(n) preprocessing mechanisms (bidirectional Mamba, Perceiver inducing points, causal attention with E2E training, sparse attention, bidirectional attention, rank-1 projection) all succeed; global mean pooling (1.9%) and Fourier mixing (0.9%) fail. The routing signal occupies a ~34-dimensional latent subspace, invisible to cosine similarity. Non-learned indices (Bloom filter: 90.9%; BM25: 82.7%) bypass the bottleneck for exact/keyword matching. Combining O(n) bidirectional Mamba with rank-1 pairwise projection yields 99.7% routing at linear inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that content-based routing in hybrid sequence models requires pairwise token comparison as an inescapable requirement, supported by 20+ controlled experiments across three tasks, scales from 200K to 1.4B parameters, and 15+ mechanisms, where only pairwise-based systems reach high precision (e.g., 99.5-99.7%) while recurrent, memory bank, bandit, and other non-pairwise approaches fail at 0.7-29%.
Significance. If the empirical pattern holds, the result would have substantial impact on hybrid model design by identifying the minimal ingredients (bidirectional per-token representations plus pairwise comparison) needed for effective routing, enabling near-perfect O(n) routing via combinations like bidirectional Mamba with rank-1 projection and providing a clear failure mode for alternatives.
major comments (2)
- [Abstract and Experiments] The central claim that pairwise comparison is universally required rests on experiments across only three tasks (with representativeness for all hybrid sequence models left unproven); this is load-bearing for the 'inescapable' conclusion, as the paper offers no theoretical argument or additional task families to rule out non-pairwise mechanisms succeeding under different data distributions or representation regimes.
- [Results] The reported routing precisions (e.g., recurrent models at 29%, memory banks at 12%) are presented as direct evidence of failure, but without explicit details on statistical significance testing, exact data splits, or controls for post-hoc mechanism selection in the main results, it is difficult to assess whether the performance gap is robust or could be closed by alternative non-pairwise designs.
minor comments (2)
- [Results] The ~34-dimensional latent subspace for the routing signal is mentioned but not accompanied by a figure or table showing its derivation or sensitivity analysis.
- [Methods] Notation for the rank-1 projection and its relation to full pairwise comparison could be clarified with an explicit equation in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the concerns about experimental scope and result robustness below, with targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim that pairwise comparison is universally required rests on experiments across only three tasks (with representativeness for all hybrid sequence models left unproven); this is load-bearing for the 'inescapable' conclusion, as the paper offers no theoretical argument or additional task families to rule out non-pairwise mechanisms succeeding under different data distributions or representation regimes.
Authors: We agree the experiments cover only three tasks and provide no general theoretical proof. These tasks were deliberately chosen to span synthetic token selection, language modeling, and long-context retrieval, which we argue capture core routing challenges in hybrid models. We have added a new Limitations section that explicitly discusses the lack of theoretical guarantees and the possibility that non-pairwise mechanisms could succeed under other distributions. We have also softened the abstract and introduction language from 'inescapable' to 'appears necessary within the tested regimes based on exhaustive empirical search'. revision: partial
-
Referee: [Results] The reported routing precisions (e.g., recurrent models at 29%, memory banks at 12%) are presented as direct evidence of failure, but without explicit details on statistical significance testing, exact data splits, or controls for post-hoc mechanism selection in the main results, it is difficult to assess whether the performance gap is robust or could be closed by alternative non-pairwise designs.
Authors: The gaps are large and consistent (99.5–99.7% vs. 0.7–29%). We have moved statistical details (5 random seeds, standard deviations <1.5%, t-test p<0.001) and exact data splits (standard train/val/test ratios per task, described in Section 4.1) into the main results. All 15+ mechanisms were evaluated under identical training protocols with pre-specified hyperparameters; no post-hoc selection occurred. A new table summarizing variance and significance has been added to the main text. revision: yes
Circularity Check
No circularity: empirical mapping of routing mechanisms via held-out measurements
full rationale
The paper supports its claim that content-based routing requires pairwise token comparison through exhaustive experiments measuring routing precision on held-out data across three tasks, 15+ mechanisms, and scales up to 1.4B parameters. All reported figures (e.g., Mamba-1.4B at 29%, bidirectional Mamba + rank-1 at 99.7%) are direct performance metrics, not quantities fitted to the target metric or reduced by construction from prior equations. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear; the argument rests on observable patterns in the tested space rather than any derivation that equates output to input by definition. This is a standard empirical study with no circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- effective routing subspace dimension
axioms (1)
- domain assumption The three tasks and model scales tested are representative of content-based routing needs in general sequence modeling.
Forward citations
Cited by 1 Pith paper
-
HubRouter: A Pluggable Sub-Quadratic Routing Primitive for Hybrid Sequence Models
HubRouter is a sub-quadratic routing primitive using learned hubs that replaces attention layers in hybrid models while delivering competitive perplexity and large throughput gains.
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser, I. Polosukhin. Attention is all you need. NeurIPS, 2017
work page 2017
-
[2]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova. BERT: Pre-training of deep bidirectional Transformers for language understanding.NAACL, 2019
work page 2019
-
[3]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, I. Sutskever. Generating long sequences with sparse Transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[5]
Longformer: The Long-Document Transformer
I. Beltagy, M. Peters, A. Cohan. Longformer: The long-document Transformer.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
- [6]
- [7]
-
[8]
K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, D. Belanger, L. Colwell, A. Weller. Rethinking attention with Performers.ICLR, 2021
work page 2021
-
[9]
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast autoregressive Transformers with linear attention.ICML, 2020
work page 2020
-
[10]
T. Dao, D. Fu, S. Ermon, A. Rudra, C. R´ e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. NeurIPS, 2022
work page 2022
-
[11]
Y. Tay, M. Dehghani, D. Bahri, D. Metzler. Efficient Transformers: A survey.ACM Computing Surveys, 2022
work page 2022
-
[12]
A. Gu, K. Goel, C. R´ e. Efficiently modeling long sequences with structured state spaces.ICLR, 2022
work page 2022
-
[13]
A. Gu, A. Gupta, C. R´ e. On the parameterization and initialization of diagonal state space models.NeurIPS, 2022
work page 2022
-
[14]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
T. Dao and A. Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
RWKV: Reinventing RNNs for the Transformer Era
B. Peng et al. RWKV: Reinventing RNNs for the Transformer era.arXiv preprint arXiv:2305.13048, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Retentive Network: A Successor to Transformer for Large Language Models
Y. Sun et al. Retentive network: A successor to Transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Jamba: A Hybrid Transformer-Mamba Language Model
O. Lieber et al. Jamba: A hybrid Transformer-Mamba language model.arXiv preprint arXiv:2403.19887, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
S. De, S. Smith, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
P. Glorioso et al. Zamba: A compact 7B SSM hybrid model.arXiv preprint arXiv:2405.18712, 2024
-
[21]
M. Poli et al. StripedHyena: Moving beyond Transformers with hybrid signal processing models. Blog post, Together AI, 2023
work page 2023
- [22]
- [23]
-
[24]
M. Poli, S. Massaroli, et al. Hyena hierarchy: Towards larger convolutional language models.ICML, 2023
work page 2023
-
[25]
D. Fu, T. Dao, K. Saab, A. Thomas, A. Rudra, C. R´ e. Hungry hungry hippos: Towards language modeling with state space models.ICLR, 2023
work page 2023
-
[26]
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, J. Dean. Outrageously large neural networks: The sparsely-gated Mixture-of-Experts layer.ICLR, 2017
work page 2017
- [27]
-
[28]
A. Jiang et al. Mixtral of Experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, W.-T. Yih. Dense passage retrieval for open-domain question answering.EMNLP, 2020
work page 2020
-
[31]
O. Khattab and M. Zaharia. ColBERT: Efficient and effective passage search via contextualized late interaction over BERT.SIGIR, 2020
work page 2020
-
[32]
S. Robertson and H. Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 2009
work page 2009
-
[33]
Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, C. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering.EMNLP, 2018
work page 2018
-
[34]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, V. Misra. Grokking: Generalization beyond overfitting on small algo- rithmic datasets.arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
G. Alain and Y. Bengio. Understanding intermediate layers using linear classifier probes.ICLR Workshop, 2017
work page 2017
-
[36]
C. Yun, S. Bhojanapalli, A. Rawat, S. Reddi, S. Kumar. Are Transformers universal approximators of sequence-to-sequence functions?ICLR, 2020. 16
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.