AI Assistance Reduces Persistence and Hurts Independent Performance
Pith reviewed 2026-05-10 18:54 UTC · model grok-4.3
The pith
AI assistance improves short-term task performance but reduces persistence and impairs performance when working without help.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
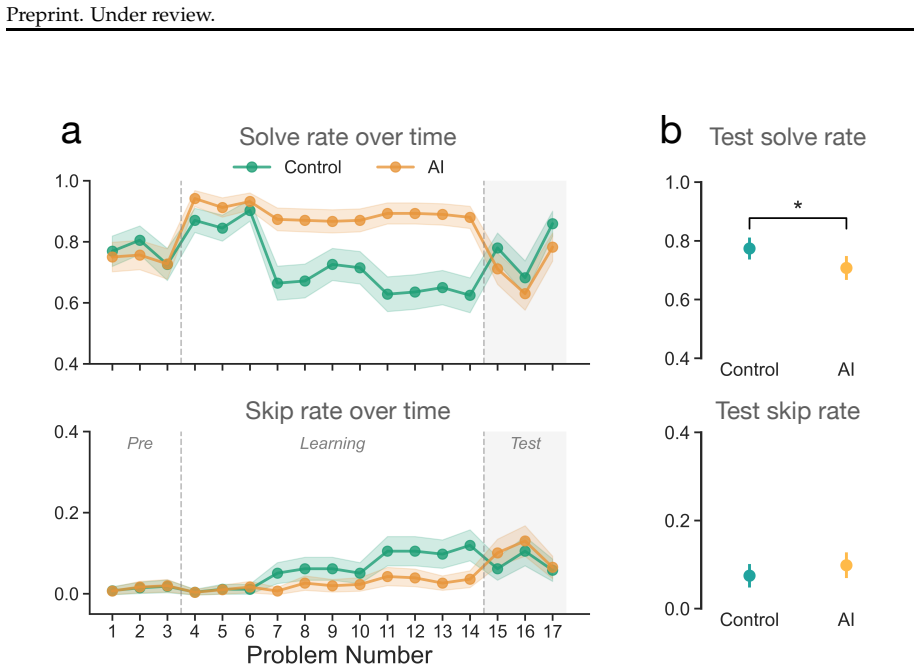
In randomized controlled trials, participants who received AI assistance performed better while the AI was available, yet they showed significantly reduced persistence and performed worse on subsequent unassisted versions of the tasks compared with participants who never had AI help. These negative effects on persistence and independent performance emerged after roughly 10 minutes of interaction. The authors attribute the drop in persistence to AI's short-sighted design that provides immediate complete answers and thereby denies users the experience of working through challenges on their own.
What carries the argument
AI conditioning users to expect immediate answers, which denies them practice at working through challenges independently.
If this is right
- AI systems that optimize only for immediate task completion undermine the persistence required for skill acquisition.
- Even brief exposure to current AI assistance produces measurable deficits in independent performance.
- Persistence, a foundational predictor of long-term learning, declines when AI removes the need to struggle through difficulties.
- Model development should incorporate mechanisms that scaffold long-term competence rather than supplying complete answers on demand.
Where Pith is reading between the lines
- AI tools used in education may need built-in delays or prompts that encourage initial independent effort to avoid eroding self-reliance.
- The findings raise questions about how repeated short AI sessions accumulate over days or weeks and whether the persistence deficit grows.
- Design choices that make AI sometimes refuse to answer or ask guiding questions could be tested as a direct countermeasure.
Load-bearing premise
The drop in persistence is caused by users learning to expect instant answers from AI rather than by differences in task difficulty, fatigue, or how the help was delivered.
What would settle it
A controlled experiment in which AI assistance is redesigned to withhold answers and prompt users to attempt problems first, then checking whether persistence and unassisted performance remain as high as in the no-AI group.
Figures




read the original abstract
People often optimize for long-term goals in collaboration: A mentor or companion doesn't just answer questions, but also scaffolds learning, tracks progress, and prioritizes the other person's growth over immediate results. In contrast, current AI systems are fundamentally short-sighted collaborators - optimized for providing instant and complete responses, without ever saying no (unless for safety reasons). What are the consequences of this dynamic? Here, through a series of randomized controlled trials on human-AI interactions (N = 1,222), we provide causal evidence for two key consequences of AI assistance: reduced persistence and impairment of unassisted performance. Across a variety of tasks, including mathematical reasoning and reading comprehension, we find that although AI assistance improves performance in the short-term, people perform significantly worse without AI and are more likely to give up. Notably, these effects emerge after only brief interactions with AI (approximately 10 minutes). These findings are particularly concerning because persistence is foundational to skill acquisition and is one of the strongest predictors of long-term learning. We posit that persistence is reduced because AI conditions people to expect immediate answers, thereby denying them the experience of working through challenges on their own. These results suggest the need for AI model development to prioritize scaffolding long-term competence alongside immediate task completion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a series of randomized controlled trials (N=1,222) across mathematical reasoning and reading comprehension tasks demonstrating that brief AI assistance (~10 minutes) improves immediate performance but subsequently reduces persistence and impairs unassisted performance relative to no-assistance controls. The authors interpret this as evidence that current AI systems, optimized for instant complete answers, condition users to expect immediate solutions and thereby undermine independent skill development.
Significance. If the directional effects hold under tighter controls, the findings would be significant for AI design and human-AI collaboration research: they provide causal evidence that short-term performance gains can trade off against foundational learning processes such as persistence, which the paper correctly notes is a strong predictor of long-term outcomes. The multi-task replication and large sample are strengths that increase generalizability within the studied domains.
major comments (3)
- [Methods] Methods section: the manuscript provides insufficient detail on randomization procedures, exact statistical controls (e.g., covariates, multiple-comparison corrections), exclusion criteria, and power analysis. These omissions prevent full evaluation of internal validity and the robustness of the reported consistent directional effects.
- [Discussion] Discussion and abstract: the posited mechanism—that reduced persistence results specifically from AI conditioning users to expect immediate answers—is not isolated by the design. No yoked conditions (human assistance, delayed responses, hint-only AI, or fatigue-matched controls) are described, leaving the causal claim vulnerable to confounds such as receiving any external help, differential task engagement, or the 10-minute interaction itself.
- [Results] Results: while directional effects are reported across tasks, the manuscript does not provide effect sizes, confidence intervals, or pre-registered analysis plans for the persistence and unassisted-performance measures. This weakens the ability to assess practical significance and the claim that effects emerge reliably after brief exposure.
minor comments (2)
- [Abstract] The abstract states effects emerge after 'approximately 10 minutes' but the methods should explicitly report mean interaction times, variance, and any checks that time-on-task did not differ systematically between conditions.
- [Figures] Figure captions and legends should clarify how persistence was operationalized (e.g., time spent, attempts made, or self-report) and whether any participants were excluded for incomplete data.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and have revised the paper accordingly to improve transparency, clarify limitations, and strengthen reporting of results.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides insufficient detail on randomization procedures, exact statistical controls (e.g., covariates, multiple-comparison corrections), exclusion criteria, and power analysis. These omissions prevent full evaluation of internal validity and the robustness of the reported consistent directional effects.
Authors: We agree that the methods section lacks sufficient detail for full evaluation of internal validity. In the revised manuscript, we will expand the Methods to include: a complete description of the randomization procedures (implemented through the online survey platform with assignment to AI-assistance or control conditions); specification of all statistical controls, covariates, and multiple-comparison corrections used; explicit exclusion criteria applied to the N=1,222 sample; and a power analysis for the primary persistence and unassisted performance outcomes. These additions will allow readers to assess robustness directly. revision: yes
-
Referee: [Discussion] Discussion and abstract: the posited mechanism—that reduced persistence results specifically from AI conditioning users to expect immediate answers—is not isolated by the design. No yoked conditions (human assistance, delayed responses, hint-only AI, or fatigue-matched controls) are described, leaving the causal claim vulnerable to confounds such as receiving any external help, differential task engagement, or the 10-minute interaction itself.
Authors: We acknowledge that the current design does not include yoked controls (such as human assistance, delayed AI responses, or hint-only conditions) that would isolate the specific mechanism of conditioning to expect immediate answers from other potential confounds like receiving any external help or differences in engagement. The paper presents this mechanism as a posited explanation consistent with the observed pattern of results across tasks. We will revise the Discussion and abstract to frame the mechanism more explicitly as hypothesized rather than definitively established, and we will add a section outlining the need for future studies with tighter controls to test it. The multi-task replication and emergence of effects after brief exposure still provide causal evidence for the performance-persistence trade-off. revision: partial
-
Referee: [Results] Results: while directional effects are reported across tasks, the manuscript does not provide effect sizes, confidence intervals, or pre-registered analysis plans for the persistence and unassisted-performance measures. This weakens the ability to assess practical significance and the claim that effects emerge reliably after brief exposure.
Authors: We will revise the Results section to report effect sizes (e.g., Cohen's d) and 95% confidence intervals for the persistence and unassisted performance measures. We will also make the full analysis code and outputs available in a public repository. The studies were not pre-registered, which we will note as a limitation; however, the analysis plan followed the pre-specified experimental design. These changes will better convey practical significance and support evaluation of the reliability of effects after brief exposure. revision: yes
Circularity Check
No significant circularity: empirical RCT reporting
full rationale
The paper reports results from a series of randomized controlled trials (N=1,222) measuring short-term performance gains alongside subsequent drops in persistence and unassisted performance after brief AI exposure. No mathematical derivations, equations, fitted parameters presented as predictions, or first-principles chains appear in the provided text. The central claims rest on direct experimental comparisons rather than any reduction of outputs to inputs by construction. The posited mechanism (conditioning to expect immediate answers) is offered as an interpretation of the data, not a derived result that loops back to the experimental inputs. This is self-contained empirical work with no load-bearing steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The mathematical reasoning and reading comprehension tasks used in the study are valid proxies for real-world persistence and independent performance.
- ad hoc to paper Effects observed after approximately 10 minutes of AI interaction reflect a stable change in user behavior rather than transient factors.
Forward citations
Cited by 1 Pith paper
-
The efficiency-gain illusion: People underestimate the rate of AI use and overestimate its benefits on simple tasks
Three pre-registered studies with 2691 participants show people underestimate their AI usage rate and overestimate efficiency gains on simple tasks, with prior use entrenching further adoption.
Reference graph
Works this paper leans on
-
[3]
Calculate: 2 3 × 4 5
-
[4]
Calculate: 3 4 ÷ 2 3
-
[10]
Calculate: 3 4 − 1 2 × 1 3 + 1 6
-
[12]
Calculate: 1 2 × 3 5 + 2 3 × 3 4 Final Problems (Test Phase, 3 problems):Neither the AI chat assistant nor any reference materials were available during this phase for either condition
-
[15]
Calculate: 3 4 ÷ 1 2 A.3 AI-Assisted Condition: Chat Assistant Greeting Participants in the AI-assisted condition had access to a chat interface (described to participants as ChatGPT) throughout the main phase. The assistant opened each problem with the following greeting: “Hi! I’m here to help you solve the problem. I can already see the problem you need...
-
[16]
Calculate: 3 5 + 1 4
-
[17]
Calculate: 2 3 × 1 2
-
[18]
Calculate: 1 2 ÷ 1 4 Main Problems (11 problems):The problems were arranged in three difficulty blocks. Within each block the order was randomised across participants; block order was fixed (easy → medium → hard). The AI chat assistant was available to participants in the AI-assisted condition; the reference hints panel was available to participants in th...
-
[19]
Calculate: 1 2 ÷ 1 3
-
[20]
Calculate: 1 3 ÷ 2 4
-
[21]
Calculate: 5 6 − 1 3
-
[23]
Calculate: 5 6 − 1 3 ÷ 2 5
-
[24]
Calculate: 3 4 + 2 5 × 4 7
-
[25]
Calculate: 7 8 − 1 2 × 5 6
-
[26]
Calculate: 1 2 + 1 3 × 3 4 ÷ 2 5
-
[27]
Calculate: 2 3 + 1 4 × 6 7 ÷ 3 5
-
[28]
Calculate: 1 2 × 3 5 + 2 3 × 3 4
-
[29]
Calculate: 5 6 − 1 4 × 3 5 + 1 10 Final Problems (Test Phase):Three problems were presented at the end of the study. Neither the AI chat assistant nor the reference hints panel was available during this phase for either condition. These problems were presented in fixed order
-
[30]
Calculate: 2 3 + 1 4 × 3 5
-
[31]
Calculate: 3 4 − 1 2 × 2 3 + 1 4
-
[32]
Calculate: 3 4 ÷ 1 2 19 Preprint. Under review. B.3 Reference Materials Available to Participants Control condition: Reference hints panel.Participants in the control condition had access to a fixed sidebar panel titled“How to Solve Fractions”throughout the main experimental phase. The panel contained three solutions to the pretest problems. These solutio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.