Recognition: no theorem link
Coupling Macro Dynamics and Micro States for Long-Horizon Social Simulation
Pith reviewed 2026-05-10 18:55 UTC · model grok-4.3
The pith
Coupling per-agent Markov decision processes for latent opinions with mean-field collective dynamics enables stable long-horizon social simulations that capture gradual shifts and reversals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
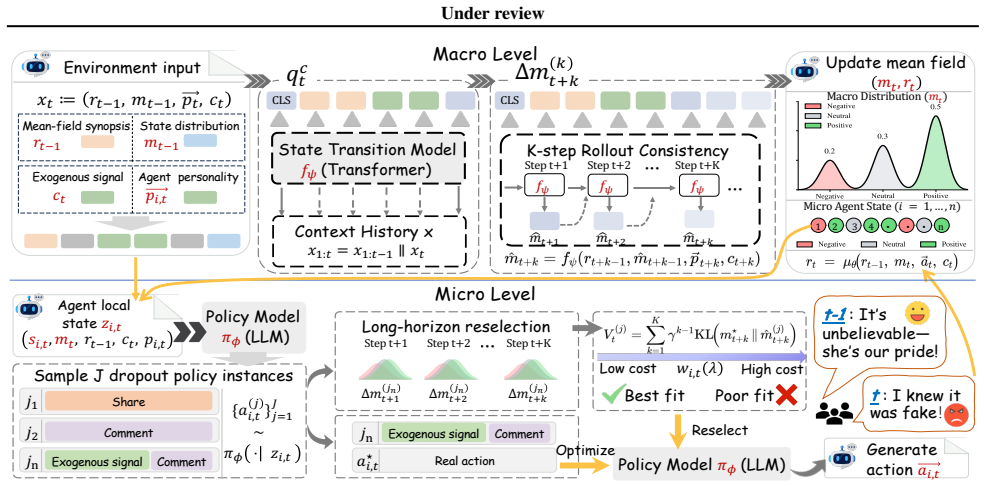
MF-MDP explicitly models per-agent latent opinion states with a state transition mechanism, combining individual Markov Decision Processes at the micro level with a mean-field collective framework at the macro level. This allows individual behaviors to change internal states gradually rather than trigger instant reactions, enabling the simulator to distinguish agents that are close to switching from those that are far from switching, capture opinion reversals, and maintain accuracy over long horizons.
What carries the argument
The MF-MDP framework, which couples micro-level individual Markov Decision Processes for per-agent latent opinion states with macro-level mean-field collective dynamics to govern aggregate behavior.
If this is right
- The simulator remains stable for up to 40,000 interactions instead of drifting after roughly 300.
- Long-horizon KL divergence drops by 75.3 percent, from 1.2490 to 0.3089.
- Reversal-specific KL divergence drops by 66.9 percent, from 1.6425 to 0.5434.
- Drift that appears in aggregate-only mean-field LLM baselines is substantially reduced.
Where Pith is reading between the lines
- The same micro-macro coupling could be tested on domains such as market sentiment or epidemic opinion spread to check whether the reversal-capture benefit generalizes beyond the reported social events.
- Replacing the MDP transition model with learned neural policies might further improve fidelity while preserving the mean-field aggregation layer.
- Scaling the population size while keeping the mean-field layer fixed would reveal the practical limits of the approximation for very large agent counts.
Load-bearing premise
Individual latent opinion states can be accurately represented as Markov decision processes and the mean-field approximation preserves enough fidelity to capture reversal patterns in the collective.
What would settle it
Run MF-MDP and the baseline MF-LLM on the same real-world event dataset for 5,000+ interactions and compare the frequency of observed opinion reversals against ground-truth data; a large mismatch in reversal rates would falsify the claim that micro-state modeling improves long-horizon fidelity.
Figures





read the original abstract
Social network simulation aims to model collective opinion dynamics in large populations, but existing LLM-based simulators mainly focus on aggregate dynamics while largely ignoring individual internal states. This limits their ability to capture opinion reversals driven by gradual individual shifts and makes them unreliable in long-horizon simulations. We propose MF-MDP, a social simulation framework that tightly couples macro-level collective dynamics with micro-level individual states. MF-MDP explicitly models per-agent latent opinion states with a state transition mechanism, combining individual Markov Decision Processes at the micro level with a mean-field collective framework at the macro level. This allows individual behaviors to change internal states gradually rather than trigger instant reactions, enabling the simulator to distinguish agents that are close to switching from those that are far from switching, capture opinion reversals, and maintain accuracy over long horizons. Across real-world events, MF-MDP supports stable simulation of long-horizon social processes with up to 40,000 interactions, compared with about 300 in the baseline MF-LLM, while reducing long-horizon KL divergence by 75.3% (1.2490 to 0.3089) and reversal KL by 66.9% (1.6425 to 0.5434), significantly mitigating the drift observed in MF-LLM. Code is available at github.com/AI4SS/MF-MDP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MF-MDP, a social simulation framework that couples macro-level mean-field collective dynamics with micro-level per-agent Markov Decision Processes for modeling latent opinion states. This enables gradual internal state changes, opinion reversals, and stable long-horizon simulations (up to 40,000 interactions) on real-world events, outperforming the MF-LLM baseline by reducing long-horizon KL divergence by 75.3% (1.2490 to 0.3089) and reversal KL by 66.9% (1.6425 to 0.5434).
Significance. If the results hold, the work offers a concrete advance in LLM-based social simulation by addressing drift through explicit micro-state modeling, potentially enabling more reliable long-term opinion dynamics forecasts in large populations. The open code release supports reproducibility and extension.
major comments (2)
- [§3] §3 (Model Description), mean-field coupling equation: the central claim that per-agent MDP transitions driven by the population average suffice to distinguish agents near vs. far from reversal is load-bearing, yet the manuscript provides no ablation or sensitivity analysis against local network structure (e.g., clustering or degree heterogeneity) that could drive reversals in the evaluated events; if reversals depend on heterogeneous neighbor influences rather than the global mean, the reported KL reductions may not generalize.
- [§4.2] §4.2 (Experimental Results), Table 2 and associated text: the 40,000-interaction stability and 66.9% reversal-KL improvement are presented without reported variance across runs, exact event topologies, or confirmation that MF-LLM and MF-MDP used identical mean-field implementations and hyperparameter budgets; this weakens the attribution of gains specifically to the micro-MDP component.
minor comments (2)
- [Abstract] The abstract states 'Code is available at github.com/AI4SS/MF-MDP' but lacks a commit hash or DOI; adding this would improve reproducibility.
- [§3] Notation for the latent state transition probabilities in the MDP could be introduced with a compact equation early in §3 to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify key aspects of our MF-MDP framework. We address each major comment below and outline the revisions we will make to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [§3] §3 (Model Description), mean-field coupling equation: the central claim that per-agent MDP transitions driven by the population average suffice to distinguish agents near vs. far from reversal is load-bearing, yet the manuscript provides no ablation or sensitivity analysis against local network structure (e.g., clustering or degree heterogeneity) that could drive reversals in the evaluated events; if reversals depend on heterogeneous neighbor influences rather than the global mean, the reported KL reductions may not generalize.
Authors: We acknowledge that the mean-field coupling relies on the global population average and that local network structures could influence reversals in some settings. Our framework prioritizes scalability for long-horizon simulations of large populations, where explicit local neighbor modeling would be computationally infeasible. The real-world events evaluated show dominant collective trends consistent with mean-field dynamics, as indicated by the observed stability and KL improvements. To address the concern, we will add a dedicated paragraph in §3 discussing the mean-field approximation, its assumptions, and potential limitations with respect to local heterogeneity. We will also include a sensitivity analysis using synthetic networks with controlled clustering and degree distributions in the appendix to demonstrate the robustness of the micro-MDP benefits under varying local influences. revision: partial
-
Referee: [§4.2] §4.2 (Experimental Results), Table 2 and associated text: the 40,000-interaction stability and 66.9% reversal-KL improvement are presented without reported variance across runs, exact event topologies, or confirmation that MF-LLM and MF-MDP used identical mean-field implementations and hyperparameter budgets; this weakens the attribution of gains specifically to the micro-MDP component.
Authors: We agree that these experimental details are essential for attributing gains to the micro-MDP component and for reproducibility. In the revised manuscript, we will update Table 2 to report means and standard deviations computed over multiple independent runs (at least five per event). We will expand the description in §4.1 to specify the exact network topologies, data sources, and preprocessing steps for each real-world event. Additionally, we will insert a clarifying statement in §4.2 confirming that MF-MDP and MF-LLM employ identical mean-field macro implementations and matched hyperparameter budgets, with the only difference being the per-agent MDP state transitions in MF-MDP. revision: yes
Circularity Check
No circularity: empirical validation of coupled MF-MDP simulator
full rationale
The paper introduces MF-MDP as a modeling framework that couples per-agent MDPs with a mean-field macro term, then reports empirical metrics (long-horizon stability up to 40k interactions, KL reductions of 75.3% and 66.9%) against the MF-LLM baseline. No derivation chain is presented that reduces a claimed prediction or first-principles result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted on a subset and then relabeled as predictions, and no ansatz is smuggled via prior work. The central claims rest on observable simulation outcomes rather than algebraic identity or self-referential fitting.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent state transition probabilities
axioms (2)
- domain assumption Individual behaviors follow Markov Decision Process assumptions
- domain assumption Mean-field approximation accurately represents collective dynamics
invented entities (1)
-
per-agent latent opinion states
no independent evidence
Forward citations
Cited by 4 Pith papers
-
OmniTrend: Content-Context Modeling for Scalable Social Popularity Prediction
OmniTrend predicts popularity by combining separate content attractiveness and contextual exposure predictors using cross-modal and exogenous signals.
-
HotComment: A Benchmark for Evaluating Popularity of Online Comments
HotComment is a new multimodal benchmark that quantifies online comment popularity via content quality assessment, interaction-based prediction, and agent-simulated user engagement, accompanied by the StyleCmt stylist...
-
Seeing Further and Wider: Joint Spatio-Temporal Enlargement for Micro-Video Popularity Prediction
A new joint spatio-temporal enlargement model for micro-video popularity prediction using frame scoring for long sequences and a topology-aware memory bank for unbounded historical associations.
-
CurEvo: Curriculum-Guided Self-Evolution for Video Understanding
CurEvo integrates curriculum guidance into self-evolution to structure autonomous improvement of video understanding models, yielding gains on VideoQA benchmarks.
Reference graph
Works this paper leans on
-
[1]
PMLR, 2018. Yang, Z., Zhang, Z., Zheng, Z., Jiang, Y ., Gan, Z., Wang, Z., Ling, Z., Chen, J., Ma, M., Dong, B., Gupta, P., Hu, S., Yin, Z., Li, G., Jia, X., Wang, L., Ghanem, B., Lu, H., Lu, C., Ouyang, W., Qiao, Y ., Torr, P., and Shao, J. Oasis: Open agent social interaction simulations with one million agents, 2025b. URL https://arxiv.org/ abs/2411.11...
-
[2]
Semantic-Aware Logical Reasoning via a Semiotic Framework
URL https://aclanthology.org/2025. findings-acl.468/. Zhang, Y ., Zhang, X., Sheng, J., Li, W., Yu, J., Yang, W., and Song, Z. From ambiguity to verdict: A semiotic-grounded multi-perspective agent for llm logical reasoning.arXiv preprint arXiv:2509.24765, 2025d. Zhou, H., Cai, J., Ye, Y ., Feng, Y ., Gao, C., Yu, J., Song, Z., and Yang, W. Video anomaly ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
KL(pt ∥ˆpt), averaged over timesteps, penalizing mismatched probability mass and being sensitive to mode dropping
KL Divergence. KL(pt ∥ˆpt), averaged over timesteps, penalizing mismatched probability mass and being sensitive to mode dropping
-
[4]
W(p t,ˆpt), averaged over timesteps, measuring the cost of transporting probability mass and being more robust to small support shifts
Wasserstein Distance. W(p t,ˆpt), averaged over timesteps, measuring the cost of transporting probability mass and being more robust to small support shifts
-
[5]
Dynamic Time Warping (DTW).DTW between the two time series {pt} and {ˆpt} (or scalar projections per label), evaluating temporal alignment by allowing elastic matching across timesteps and penalizing phase shifts. 16 Under review GTMF-MDP(Ours)MF-LLMSocial Retrieval Direct LLM (a) Culture-Behavior Share(a) Culture-Behavior Comment(a) Culture-Belief Believ...
-
[6]
Negative Log-Likelihood (NLL).The average −logπ ϕ(a⋆ i,t |z i,t) over all ground-truth actions, measuring how well the learned policy assigns probability to real behaviors
-
[7]
real labels and averaged across classes (treating each class equally), highlighting performance on minority labels
Macro-F1.F1 computed from predicted vs. real labels and averaged across classes (treating each class equally), highlighting performance on minority labels
-
[8]
Micro-F1.F1 computed by aggregating true/false positives across all actions before forming F1, emphasizing overall accuracy dominated by frequent labels. D. Additional Experimental Results and Analysis D.1. Full Results Semantic fidelity under evolving states.Fig. 4 evaluates semantic fidelity over eight semantic-related dimensions (excludingNLL Loss); fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.