Recognition: unknown
SyncFix: Fixing 3D Reconstructions via Multi-View Synchronization
Pith reviewed 2026-05-10 15:15 UTC · model grok-4.3
The pith
SyncFix refines 3D scene reconstructions by synchronizing multiple views through joint latent bridge matching in a diffusion process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SyncFix formulates refinement of reconstructed scenes as a joint latent bridge matching problem that synchronizes distorted and clean representations across multiple views to fix semantic and geometric inconsistencies. It learns a joint conditional over multiple views to enforce consistency throughout the denoising trajectory. Training is performed solely on image pairs, yet the approach generalizes naturally to an arbitrary number of views at inference, and reconstruction quality continues to improve with additional views although gains diminish at higher counts. Qualitative and quantitative results show that SyncFix produces higher-fidelity outputs than current baselines, even without any,
What carries the argument
Joint latent bridge matching that synchronizes distorted and clean representations across views during diffusion denoising.
If this is right
- Reconstruction quality rises as more views are supplied, with diminishing returns after a moderate count.
- The method outperforms existing baselines even when no clean reference images are supplied.
- Higher fidelity is obtained when a small number of clean references can be included.
- The pair-trained model applies without retraining to scenes containing any number of input views.
Where Pith is reading between the lines
- Pairwise training may suffice for multi-view consistency tasks in other diffusion pipelines such as video or novel-view synthesis.
- The synchronization mechanism could be tested on reconstruction pipelines that use different base models or different noise schedules.
- If view count continues to help, the approach might reduce the need for dense capture setups in practical 3D scanning.
Load-bearing premise
Training only on image pairs will generalize to any number of views at inference and the joint matching process will remove inconsistencies without creating new artifacts or losing detail.
What would settle it
Running SyncFix on a multi-view dataset with progressively added views and observing that perceptual or geometric error metrics stop improving or begin to worsen beyond a small number of views.
Figures
















read the original abstract
We present SyncFix, a framework that enforces cross-view consistency during the diffusion-based refinement of reconstructed scenes. SyncFix formulates refinement as a joint latent bridge matching problem, synchronizing distorted and clean representations across multiple views to fix the semantic and geometric inconsistencies. This means SyncFix learns a joint conditional over multiple views to enforce consistency throughout the denoising trajectory. Our training is done only on image pairs, but it generalizes naturally to an arbitrary number of views during inference. Moreover, reconstruction quality improves with additional views, with diminishing returns at higher view counts. Qualitative and quantitative results demonstrate that SyncFix consistently generates high-quality reconstructions and surpasses current state-of-the-art baselines, even in the absence of clean reference images. SyncFix achieves even higher fidelity when sparse references are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SyncFix, a framework for enforcing cross-view consistency in diffusion-based refinement of 3D scene reconstructions. It formulates the refinement as a joint latent bridge matching problem that synchronizes distorted and clean representations across views to correct semantic and geometric inconsistencies. The method is trained exclusively on image pairs but is claimed to generalize naturally to an arbitrary number of views at inference, with reconstruction quality improving as more views are added (with diminishing returns). It asserts consistent outperformance over state-of-the-art baselines even without clean reference images and further gains when sparse references are available.
Significance. If the pair-to-multi-view generalization holds without introducing artifacts and the claimed improvements are empirically validated, SyncFix could meaningfully advance diffusion-based 3D reconstruction by offering a scalable consistency mechanism that does not require multi-view training data or clean references. The observation of quality gains with additional views would be a useful practical property for real-world capture scenarios.
major comments (2)
- [Abstract] Abstract: the headline claim that 'training is done only on image pairs, but it generalizes naturally to an arbitrary number of views during inference' via 'joint latent bridge matching' is load-bearing for all performance assertions, yet no formulation is given for how the joint conditional is constructed when n>2 (single multi-view latent vs. repeated pairwise bridges), whether the denoising trajectory stays consistent, or how new artifacts are avoided.
- [Abstract] Abstract: the assertions of 'consistent outperformance of SOTA baselines' and 'reconstruction quality improves with additional views' are presented without any quantitative metrics, datasets, baselines, error analysis, or implementation details, rendering the central empirical claims unverifiable.
minor comments (2)
- The term 'joint latent bridge matching' is introduced without definition, prior reference, or relation to existing bridge-matching or latent diffusion literature.
- The abstract states that 'qualitative and quantitative results demonstrate...' but supplies no information on the evaluation protocol, datasets, or metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment point by point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'training is done only on image pairs, but it generalizes naturally to an arbitrary number of views during inference' via 'joint latent bridge matching' is load-bearing for all performance assertions, yet no formulation is given for how the joint conditional is constructed when n>2 (single multi-view latent vs. repeated pairwise bridges), whether the denoising trajectory stays consistent, or how new artifacts are avoided.
Authors: We agree that the abstract does not provide the requested formulation details for the n>2 case. In the revised version we will expand the abstract to briefly describe the construction of the joint conditional via a single synchronized multi-view latent representation (rather than repeated pairwise bridges), the maintenance of a consistent denoising trajectory through joint conditioning, and the avoidance of new artifacts via cross-view synchronization at each step. We will also ensure the method section supplies the corresponding mathematical details. revision: yes
-
Referee: [Abstract] Abstract: the assertions of 'consistent outperformance of SOTA baselines' and 'reconstruction quality improves with additional views' are presented without any quantitative metrics, datasets, baselines, error analysis, or implementation details, rendering the central empirical claims unverifiable.
Authors: We concur that the abstract would be more informative with specific supporting details. In the revision we will add concise quantitative highlights (e.g., key performance gains and the observed trend with increasing view count), along with references to the datasets, baselines, and evaluation metrics used in the experiments section. revision: yes
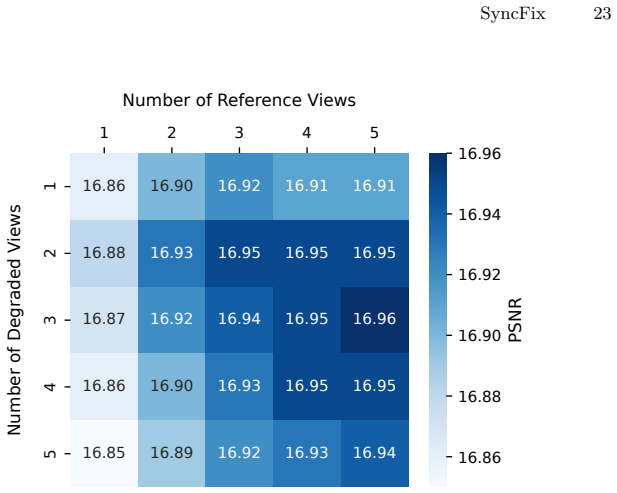
Circularity Check
No significant circularity; claims rest on empirical results rather than self-referential derivation
full rationale
The provided abstract and text assert that pair-trained joint latent bridge matching generalizes to arbitrary views at inference and improves with more views, but no equations, fitted parameters, or self-citations are quoted that reduce any prediction or uniqueness claim to the inputs by construction. The central results (surpassing baselines, higher fidelity with references) are presented as externally validated outcomes, keeping the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
joint latent bridge matching
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Generalizable Sparse-View 3D Reconstruction from Unconstrained Images
GenWildSplat is a feed-forward model that reconstructs 3D Gaussians from sparse unposed unconstrained images by predicting depth and poses with learned priors, an appearance adapter, and semantic segmentation for transients.
Reference graph
Works this paper leans on
-
[1]
World Simulation with Video Foundation Models for Physical AI
Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., et al.: World simulation with video foundation models for physical ai. arXiv preprint arXiv:2511.00062 (2025)
work page internal anchor Pith review arXiv 2025
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Asim, M., Wewer, C., Wimmer, T., Schiele, B., Lenssen, J.E.: Met3r: Measuring multi-view consistency in generated images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6034–6044 (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF international conference on computer vision
Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srini- vasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5855–5864 (2021)
2021
-
[4]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Chadebec, C., Tasar, O., Sreetharan, S., Aubin, B.: Lbm: Latent bridge matching for fast image-to-image translation. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 29086–29098 (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng,K.,Liu,A.,Zhu,J.Y.,Ramanan,D.:Depth-supervisednerf:Fewerviewsand faster training for free. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12882–12891 (2022)
2022
-
[6]
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023) 18 Deming Li et al
-
[7]
Advances in Neural Information Processing Systems (2024)
Gao*, R., Holynski*, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P.P., Barron, J.T., Poole*, B.: Cat3d: Create anything in 3d with multi-view dif- fusion models. Advances in Neural Information Processing Systems (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (2023)
Haque, A., Tancik, M., Efros, A., Holynski, A., Kanazawa, A.: Instruct-nerf2nerf: Editing 3d scenes with instructions. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (2023)
2023
-
[9]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[10]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 300–309 (2023)
2023
-
[12]
In: Proceedings of the IEEE/CVF international conference on com- puter vision
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: Proceedings of the IEEE/CVF international conference on com- puter vision. pp. 17627–17638 (2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22160–22169 (2024)
2024
-
[14]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[15]
Liu, F., Sun, W., Wang, H., Wang, Y., Sun, H., Ye, J., Zhang, J., Duan, Y.: Reconx: Reconstruct any scene from sparse views with video diffusion model. arXiv preprint arXiv:2408.16767 (2024)
-
[16]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https: //openreview.net/forum?id=P4s6FUpCbG
Liu, X., Zhou, C., Huang, S.: 3DGS-enhancer: Enhancing unbounded 3d gaus- sian splatting with view-consistent 2d diffusion priors. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https: //openreview.net/forum?id=P4s6FUpCbG
2024
-
[17]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and trans- fer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z
2023
-
[18]
In: The Twelfth International Conference on Learning Representations (2024),https: //openreview.net/forum?id=MN3yH2ovHb
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Sync- dreamer: Generating multiview-consistent images from a single-view image. In: The Twelfth International Conference on Learning Representations (2024),https: //openreview.net/forum?id=MN3yH2ovHb
2024
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Luo, Y., Zhou, S., Lan, Y., Pan, X., Loy, C.C.: 3denhancer: Consistent multi-view diffusion for 3d enhancement. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16430–16440 (2025)
2025
-
[20]
In: International Conferenceon LearningRepresentations(2022),https://openreview.net/forum? id=aBsCjcPu_tE
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: SDEdit: Guided image synthesis and editing with stochastic differential equations. In: International Conferenceon LearningRepresentations(2022),https://openreview.net/forum? id=aBsCjcPu_tE
2022
-
[21]
In: ECCV (2020) SyncFix 19
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020) SyncFix 19
2020
-
[22]
Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S.M., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs.In:Proc.IEEEConf.onComputerVisionandPatternRecognition(CVPR) (2022)
2022
-
[23]
com/nv-tlabs/Fixer(2025), gitHub repository
NVIDIA: Fixer: Official repository for the nvidia fixer model.https://github. com/nv-tlabs/Fixer(2025), gitHub repository. Accessed: 2026-03-12
2025
-
[24]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=FjNys5c7VyY
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=FjNys5c7VyY
2023
-
[26]
arXiv preprint arXiv:2601.16981 (2026)
Serrano-Lozano, D., Bhattad, A., Herranz, L., Lalonde, J.F., Vazquez-Corral, J.: Synclight: Controllable and consistent multi-view relighting. arXiv preprint arXiv:2601.16981 (2026)
work page internal anchor Pith review arXiv 2026
-
[27]
arXiv preprint arXiv:2602.15755 (2026)
Shenoi, A., Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Raco: Ranking and co- variance for practical learned keypoints. arXiv preprint arXiv:2602.15755 (2026)
-
[28]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=FUgrjq2pbB
Shi, Y., Wang, P., Ye, J., Mai, L., Li, K., Yang, X.: MVDream: Multi-view dif- fusion for 3d generation. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=FUgrjq2pbB
2024
-
[29]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
Wang, G., Chen, Z., Loy, C.C., Liu, Z.: Sparsenerf: Distilling depth ranking for few- shot novel view synthesis. In: IEEE/CVF International Conference on Computer Vision (ICCV) (2023)
2023
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, H., Du, X., Li, J., Yeh, R.A., Shakhnarovich, G.: Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12619– 12629 (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
2025
-
[33]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Warburg, F., Weber, E., Tancik, M., Holynski, A., Kanazawa, A.: Nerfbusters: Removing ghostly artifacts from casually captured nerfs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18120–18130 (2023)
2023
-
[35]
Warburg*, F., Weber*, E., Tancik, M., Hołyński, A., Kanazawa, A.: Nerfbusters: Removing ghostly artifacts from casually captured nerfs (2023)
2023
-
[36]
arXiv preprint arXiv:2506.12563 (2025)
Wickrema, C., Leary, S., Sarkar, S., Giglio, M., Bianchi, E., Mace, E., Twardowski, M.: Benchmarking image similarity metrics for novel view synthesis applications. arXiv preprint arXiv:2506.12563 (2025)
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, J.Z., Zhang, Y., Turki, H., Ren, X., Gao, J., Shou, M.Z., Fidler, S., Gojcic, Z., Ling, H.: Difix3d+: Improving 3d reconstructions with single-step diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26024–26035 (2025)
2025
-
[38]
with diffusion priors
Wu, R., Mildenhall, B., Henzler, P., Park, K., Gao, R., Watson, D., Srinivasan, P.P., Verbin, D., Barron, J.T., Poole, B., et al.: Reconfusion: 3d reconstruction 20 Deming Li et al. with diffusion priors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21551–21561 (2024)
2024
-
[39]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16453–16463 (2025)
2025
-
[40]
Yang, J., Pavone, M., Wang, Y.:
-
[41]
In: The Fourteenth International Conferenceon LearningRepresentations(2026),https://openreview.net/forum? id=ImRhA9xmay
Ye, B., Chen, B., Xu, H., Barath, D., Pollefeys, M.: Yonosplat: You only need one model for feedforward 3d gaussian splatting. In: The Fourteenth International Conferenceon LearningRepresentations(2026),https://openreview.net/forum? id=ImRhA9xmay
2026
-
[42]
IEEE transactions on pattern analysis and machine intelligence (2024)
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. IEEE transactions on pattern analysis and machine intelligence (2024)
2024
-
[43]
Zhou, H., Shao, Z., Miao, S., Wang, P., Bai, D., Liu, B., Liao, Y.: Freefix: Boost- ing 3d gaussian splatting via fine-tuning-free diffusion models. arXiv preprint arXiv:2601.20857 (2026) SyncFix 21 A Technical Appendices and Supplementary Material A.1 sectionNumber of Views Analysis SyncFix is trained on view pairs, but our permutation-invariant latent c...
-
[44]
10 reveals a clear trend that the CVSC score improves with more de- graded views, regardless of the number of reference views
Fig. 10 reveals a clear trend that the CVSC score improves with more de- graded views, regardless of the number of reference views. The biggest gain occurs when moving from single-view to two-view inference. This finding supports our claim that jointly refining more views yields better cross-view consistency
-
[45]
11 shows that FID tends to increase as either the number of degraded views or the number of reference views grows
Fig. 11 shows that FID tends to increase as either the number of degraded views or the number of reference views grows. We attribute this behavior 22 Deming Li et al. to the attention being distributed across a larger set of inputs during joint conditioning, which can introduce a moderate averaging/smoothing effect
-
[46]
12 indicates that increasing the number of input views, particularly the reference images, leads to a higher PSNR and plateaus with more views
Fig. 12 indicates that increasing the number of input views, particularly the reference images, leads to a higher PSNR and plateaus with more views. We observe that the local details are better recovered in the regions that are visible in the reference views. We report the results with 5 degraded views and 5 reference views in our main text. 1 2 3 4 5 Num...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.