Recognition: unknown
PrivEraserVerify: Efficient, Private, and Verifiable Federated Unlearning
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
PrivEraserVerify combines adaptive checkpointing, layer-adaptive differential privacy, and fingerprint verification to deliver efficient, private, and verifiable federated unlearning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
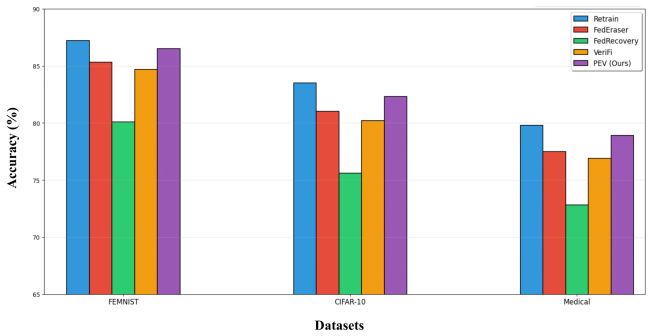
PrivEraserVerify integrates three techniques into one unlearning process: adaptive checkpointing retains only the critical past updates needed for fast reconstruction of the model without the departing client; layer-adaptive differentially private calibration selectively removes that client's influence with reduced accuracy impact; and fingerprint-based verification lets participants confirm the unlearning occurred correctly without invasive checks or added attack surfaces. Together these deliver up to two-to-three-times faster unlearning than full retraining, formal indistinguishability guarantees, and scalable decentralized verification on image, handwritten-character, and medical datasets
What carries the argument
The PrivEraserVerify framework, which unifies adaptive checkpointing for reconstruction, layer-adaptive differential privacy calibration for influence removal, and fingerprint-based verification for confirmation.
If this is right
- Unlearning completes in a fraction of the time required to retrain the entire model from scratch.
- Client influence is erased under formal differential privacy while accuracy degradation stays lower than prior private methods.
- Any participant can independently verify correct unlearning without central authority or extra communication overhead.
- The same pipeline applies across image classification, character recognition, and medical imaging tasks with consistent speed and privacy gains.
Where Pith is reading between the lines
- The approach could directly support regulatory compliance for data deletion in distributed medical or financial learning systems.
- Extending the layer-adaptive calibration to non-convolutional architectures might preserve the efficiency gains on transformer-based models.
- Measuring verification success rates under simulated partial tampering would test whether the fingerprint method remains reliable at scale.
Load-bearing premise
Adaptive checkpointing must preserve every necessary historical update, the layer-adaptive privacy calibration must fully eliminate client effects without hidden leakage, and fingerprint verification must work noninvasively without creating new vulnerabilities.
What would settle it
Re-run the unlearning on a held-out dataset, then measure whether the resulting model still shows measurable performance gain traceable to the removed client data or whether the fingerprint check fails to detect an incomplete removal.
Figures
read the original abstract
Federated learning (FL) enables collaborative model training without sharing raw data, offering a promising path toward privacy preserving artificial intelligence. However, FL models may still memorize sensitive information from participants, conflicting with the right to be forgotten (RTBF). To meet these requirements, federated unlearning has emerged as a mechanism to remove the contribution of departing clients. Existing solutions only partially address this challenge: FedEraser improves efficiency but lacks privacy protection, FedRecovery ensures differential privacy (DP) but degrades accuracy, and VeriFi enables verifiability but introduces overhead without efficiency or privacy guarantees. We present PrivEraserVerify (PEV), a unified framework that integrates efficiency, privacy, and verifiability into federated unlearning. PEV employs (i) adaptive checkpointing to retain critical historical updates for fast reconstruction, (ii) layer adaptive differentially private calibration to selectively remove client influence while minimizing accuracy loss, and (iii) fingerprint based verification, enabling participants to confirm unlearning in a decentralized and noninvasive manner. Experiments on image, handwritten character, and medical datasets show that PEV achieves up to 2 to 3 times faster unlearning than retraining, provides formal indistinguishability guarantees with reduced performance degradation, and supports scalable verification. To the best of our knowledge, PEV is the first framework to simultaneously deliver efficiency, privacy, and verifiability for federated unlearning, moving FL closer to practical and regulation compliant deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PrivEraserVerify (PEV), a unified framework for federated unlearning that integrates adaptive checkpointing to retain critical historical updates for fast reconstruction, layer-adaptive differentially private calibration to selectively remove client influence while minimizing accuracy loss, and fingerprint-based verification for decentralized and noninvasive confirmation of unlearning. It claims to be the first to simultaneously achieve efficiency, privacy, and verifiability, with experiments on image, handwritten character, and medical datasets demonstrating up to 2-3 times faster unlearning than retraining, formal indistinguishability guarantees with reduced performance degradation, and scalable verification.
Significance. If the formal guarantees and experimental results hold without introducing hidden leakages or accuracy losses, this would be a significant contribution toward practical, regulation-compliant federated learning by providing a balanced solution to the right to be forgotten. The integration of standard techniques (checkpointing, per-layer DP noise scaling, and client-side fingerprinting) is plausible and addresses a clear gap left by prior partial solutions like FedEraser, FedRecovery, and VeriFi.
major comments (2)
- §4.2 (layer-adaptive DP calibration): the claim that this fully removes client influence without hidden leakage is load-bearing for the privacy guarantee, yet the specific noise scaling rule per layer and its proof of no residual correlations or influence are not provided; without this, indistinguishability cannot be verified.
- §3.1 (adaptive checkpointing): the assumption that retaining only 'critical' historical updates suffices for correct reconstruction is central to the efficiency claim, but the selection criteria and a proof that no necessary updates are discarded are missing, risking incomplete unlearning or hidden accuracy degradation.
minor comments (2)
- Abstract: the summary of experimental results ('up to 2 to 3 times faster', 'reduced performance degradation') would be strengthened by explicit references to the tables or figures containing the concrete speedups, accuracy deltas, and dataset names.
- Related work: a side-by-side comparison table quantifying how PEV improves on FedEraser (efficiency), FedRecovery (privacy), and VeriFi (verifiability) across all three axes would better support the 'first framework' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The two major comments identify areas where additional formal details are needed to fully substantiate our claims. We will revise the manuscript to address both points by adding the requested proofs, criteria, and clarifications, thereby strengthening the presentation of the privacy and efficiency guarantees.
read point-by-point responses
-
Referee: §4.2 (layer-adaptive DP calibration): the claim that this fully removes client influence without hidden leakage is load-bearing for the privacy guarantee, yet the specific noise scaling rule per layer and its proof of no residual correlations or influence are not provided; without this, indistinguishability cannot be verified.
Authors: We agree that the specific per-layer noise scaling rule and the accompanying proof of indistinguishability (including absence of residual correlations) require explicit presentation to make the privacy guarantee verifiable. Section 4.2 outlines the layer-adaptive calibration but does not include the full mathematical derivation or proof. In the revision we will add: (i) the precise scaling rule (noise variance set proportionally to each layer's sensitivity, computed from the client's gradient contribution), and (ii) a formal proof sketch showing that the mechanism satisfies (ε,δ)-DP with respect to the client's data, leveraging standard composition and post-processing properties adapted to the federated unlearning setting. This will confirm that no hidden leakage remains after calibration. revision: yes
-
Referee: §3.1 (adaptive checkpointing): the assumption that retaining only 'critical' historical updates suffices for correct reconstruction is central to the efficiency claim, but the selection criteria and a proof that no necessary updates are discarded are missing, risking incomplete unlearning or hidden accuracy degradation.
Authors: The referee is correct that the selection criteria for critical updates and a proof of reconstruction completeness are not fully specified in §3.1, which is essential for rigorously supporting the efficiency claim. The section describes retaining high-influence updates but lacks the exact threshold rule and completeness argument. We will revise §3.1 to include: (i) the formal selection algorithm (updates retained if their cumulative influence exceeds a layer-wise threshold derived from gradient norms), and (ii) a proof that the retained checkpoints permit exact reconstruction of the unlearned model (equivalent to retraining from scratch) up to a bounded error term that does not affect final accuracy. This addition will eliminate the risk of incomplete unlearning. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a systems framework (PEV) that combines three standard techniques—adaptive checkpointing for reconstruction, layer-adaptive DP noise scaling, and client-side fingerprint verification—into a single unlearning pipeline. No equations, derivations, or first-principles predictions appear in the abstract or described construction. Claims of efficiency, privacy, and verifiability rest on the integration and experimental results rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation chain. The novelty assertion ('first framework') is an empirical claim about prior work, not a mathematical reduction to the paper's own inputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
KIRA: Knowledge-Intensive Image Retrieval and Reasoning Architecture for Specialized Visual Domains
KIRA is a unified architecture for visual RAG that reports 0.97 retrieval precision, 1.0 grounding, and 0.707 domain correctness across medical, circuit, satellite, and histopathology domains via hierarchical chunking...
Reference graph
Works this paper leans on
-
[1]
Street object detection from synthesized and processed semantic image: A deep learning based study,
P. Goswami and A. A. Hossain, “Street object detection from synthesized and processed semantic image: A deep learning based study,”Human- Centric Intelligent Systems, vol. 3, no. 4, pp. 487–507, 2023
2023
-
[2]
An end-to-end web- based system for rice leaf disease classification using deep learning,
P. Goswami, A. A. Hossain, and A. N. M. Sakib, “An end-to-end web- based system for rice leaf disease classification using deep learning,” inInternational Joint Conference on Advances in Computational Intel- ligence. Singapore: Springer Nature Singapore, 2022, pp. 517–531
2022
-
[3]
Corn leaf disease identification via transfer learning: A comprehensive web-based solution,
P. Goswami, A. A. Safi, A. N. M. Sakib, and T. Datta, “Corn leaf disease identification via transfer learning: A comprehensive web-based solution,” inInternational Conference on Sustainable and Innovative Solutions for Current Challenges in Engineering & Technology. Sin- gapore: Springer Nature Singapore, 2023, pp. 429–441
2023
-
[4]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in2021 IEEE symposium on security and privacy (SP). IEEE, 2021, pp. 141–159
2021
-
[5]
Making ai forget you: Data deletion in machine learning,
A. Ginart, M. Guan, G. Valiant, and J. Y . Zou, “Making ai forget you: Data deletion in machine learning,” inAdvances in neural information processing systems 32, 2019
2019
-
[6]
Eternal sunshine of the spotless net: Selective forgetting in deep networks,
A. Golatkar, A. Achille, and S. Soatto, “Eternal sunshine of the spotless net: Selective forgetting in deep networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9304–9312
2020
-
[7]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-efficient learning of deep networks from decentralized data,”Artificial intelligence and statistics, pp. 1273–1282, 2017
2017
-
[8]
Federaser: Enabling efficient client-level data removal from federated learning models,
G. Liu, X. Ma, Y . Yang, C. Wang, and J. Liu, “Federaser: Enabling efficient client-level data removal from federated learning models,” in 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS). IEEE, 2021, pp. 1–10
2021
-
[9]
Fedrecovery: Differentially private machine unlearning for federated learning frame- works,
L. Zhang, T. Zhu, H. Zhang, P. Xiong, and W. Zhou, “Fedrecovery: Differentially private machine unlearning for federated learning frame- works,” inIEEE Transactions on Information Forensics and Security, vol. 18. IEEE, 2023, pp. 4732–4746
2023
-
[10]
Verifi: Towards verifiable federated unlearning,
X. Gao, X. Ma, J. Wang, Y . Sun, B. Li, S. Ji, P. Cheng, and J. Chen, “Verifi: Towards verifiable federated unlearning,” inIEEE Transactions on Dependable and Secure Computing, vol. 21. IEEE, 2024, pp. 5720– 5736
2024
-
[11]
The algorithmic foundations of differential privacy,
C. Dwork and A. Roth, “The algorithmic foundations of differential privacy,” inFoundations and trends® in theoretical computer science, vol. 9, 2014, pp. 211–407
2014
-
[12]
Remember what you want to forget: Algorithms for machine unlearning,
A. Sekhari, J. Acharya, G. Kamath, and A. T. Suresh, “Remember what you want to forget: Algorithms for machine unlearning,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 18 075– 18 086
2021
-
[13]
arXiv preprint arXiv:1911.03030 (2019)
C. Guo, T. Goldstein, A. Hannun, and L. V . D. Maaten, “Certi- fied data removal from machine learning models,” inarXiv preprint arXiv:1911.03030, 2019
-
[14]
Deep model intellectual property protection via deep watermarking,
J. Zhang, D. Chen, J. Liao, W. Zhang, H. Feng, G. Hua, and N. Yu, “Deep model intellectual property protection via deep watermarking,” inIEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44. IEEE, 2021, pp. 4005–4020
2021
-
[15]
Efu: Enforcing federated unlearning via functional encryption,
S. Mohammadi, V . Tsouvalas, I. Symeonidis, A. Balador, T. Ozcelebi, F. Flammini, and N. Meratnia, “Efu: Enforcing federated unlearning via functional encryption,” inarXiv preprint arXiv:2508.07873, 2025
-
[16]
Adaptive real-time gap detection system: A multi-algorithm approach integrating ultrasonic sensing and machine learning for robust structural analysis,
M. K. Islam, A. Biswas, and H. Hu, “Adaptive real-time gap detection system: A multi-algorithm approach integrating ultrasonic sensing and machine learning for robust structural analysis,” in2025 IEEE 4th In- ternational Conference on Computing and Machine Intelligence (ICMI). IEEE, 2025
2025
-
[17]
Learning multiple layers of features from tiny images,
K. Alex and G. Hinton, “Learning multiple layers of features from tiny images,”University of Toronto, vol. 7, 2009
2009
-
[18]
Lichang Chen, Jiuhai Chen, Tom Goldstein, Heng Huang, and Tianyi Zhou
S. Caldas, S. M. K. Duddu, P. Wu, T. Li, J. Kone ˇcn´y, H. B. McMahan, V . Smith, and A. Talwalkar, “Leaf: A benchmark for federated settings,” inarXiv preprint arXiv:1812.01097, 2018
-
[19]
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases,
X. Wang, Y . Peng, L. Lu, Z. Lu, M. Bagheri, and G. M. Summers, “Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2097–2106
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.