Recognition: unknown
KnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
KnowRL trains LLMs on compact interaction-aware knowledge point subsets to reduce reward sparsity in reinforcement learning for reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
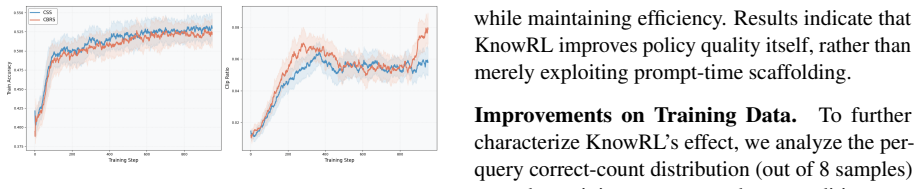
KnowRL decomposes guidance into atomic knowledge points (KPs) and uses Constrained Subset Search (CSS) to construct compact, interaction-aware subsets for training. It explicitly optimizes under the pruning interaction paradox, where removing one KP can help but removing several can hurt. KnowRL-Nemotron-1.5B trained this way reaches 70.08 average accuracy across eight reasoning benchmarks without KP hints at inference, a gain of 9.63 points over the base model, and 74.16 with selected KPs, establishing a new state of the art at the 1.5B scale.
What carries the argument
Constrained Subset Search (CSS), which identifies minimal-sufficient, interaction-aware subsets of atomic knowledge points (KPs) to supply guidance during RL training while accounting for pruning dependencies.
Load-bearing premise
Constrained Subset Search can reliably pick KP subsets that remain minimal and sufficient on unseen problems without selection bias or overfitting to the training distribution.
What would settle it
A held-out reasoning benchmark where KnowRL models show no accuracy gain over the base model or standard RL when using the curated KP subsets would show the minimal-sufficient selection does not improve reasoning.
Figures








read the original abstract
RLVR improves reasoning in large language models, but its effectiveness is often limited by severe reward sparsity on hard problems. Recent hint-based RL methods mitigate sparsity by injecting partial solutions or abstract templates, yet they typically scale guidance by adding more tokens, which introduce redundancy, inconsistency, and extra training overhead. We propose \textbf{KnowRL} (Knowledge-Guided Reinforcement Learning), an RL training framework that treats hint design as a minimal-sufficient guidance problem. During RL training, KnowRL decomposes guidance into atomic knowledge points (KPs) and uses Constrained Subset Search (CSS) to construct compact, interaction-aware subsets for training. We further identify a pruning interaction paradox -- removing one KP may help while removing multiple such KPs can hurt -- and explicitly optimize for robust subset curation under this dependency structure. We train KnowRL-Nemotron-1.5B from OpenMath-Nemotron-1.5B. Across eight reasoning benchmarks at the 1.5B scale, KnowRL-Nemotron-1.5B consistently outperforms strong RL and hinting baselines. Without KP hints at inference, KnowRL-Nemotron-1.5B reaches 70.08 average accuracy, already surpassing Nemotron-1.5B by +9.63 points; with selected KPs, performance improves to 74.16, establishing a new state of the art at this scale. The model, curated training data, and code are publicly available at https://github.com/Hasuer/KnowRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KnowRL, a knowledge-guided RL framework for LLM reasoning that decomposes hints into atomic knowledge points (KPs) and applies Constrained Subset Search (CSS) to curate compact, interaction-aware subsets during training. It identifies and optimizes for a pruning interaction paradox in KP dependencies. The authors train KnowRL-Nemotron-1.5B from OpenMath-Nemotron-1.5B and report consistent outperformance over RL and hinting baselines across eight reasoning benchmarks, with average accuracy reaching 70.08 without KP hints at inference (+9.63 over the base model) and 74.16 when using selected KPs, claiming a new SOTA at the 1.5B scale. The model, curated data, and code are released publicly.
Significance. If the empirical claims hold under rigorous validation, the work would offer a meaningful advance in addressing reward sparsity in RL for reasoning by replacing verbose hints with minimal-sufficient KP guidance, potentially lowering training overhead while improving performance. The explicit treatment of the pruning interaction paradox and the open release of artifacts (model, data, code) are notable strengths that support reproducibility and further investigation.
major comments (2)
- Abstract: The performance claims (70.08 average accuracy without hints, +9.63 improvement, and 74.16 with KPs establishing new SOTA) are presented without any description of the eight benchmarks, baseline implementations, number of runs, variance, or statistical tests. This prevents evaluation of whether the reported gains are robust or attributable to the claimed mechanism.
- Methods/Results (CSS and generalization): The central assumption that Constrained Subset Search produces minimal-sufficient, interaction-aware KP subsets that generalize beyond the training distribution (OpenMath-Nemotron) is not supported by any described ablation, held-out validation, or analysis showing performance degradation upon KP removal on unseen problems. Without such evidence, the gains could stem from data curation or RL regularization rather than the guidance mechanism.
minor comments (1)
- The abstract would be clearer if it explicitly named the eight reasoning benchmarks and the strong RL/hinting baselines used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the concerns about the abstract's lack of detail and the evidence supporting generalization of the CSS mechanism. We will revise the manuscript to strengthen these aspects while preserving the core contributions.
read point-by-point responses
-
Referee: Abstract: The performance claims (70.08 average accuracy without hints, +9.63 improvement, and 74.16 with KPs establishing new SOTA) are presented without any description of the eight benchmarks, baseline implementations, number of runs, variance, or statistical tests. This prevents evaluation of whether the reported gains are robust or attributable to the claimed mechanism.
Authors: We agree that the abstract is overly concise and omits key details needed to assess robustness. The full manuscript describes the eight benchmarks (MATH, GSM8K, AIME, AMC, OlympiadBench, and others), specifies the RL and hinting baselines with implementation details, and reports results averaged over multiple random seeds with standard deviations in the experimental section. We will revise the abstract to briefly reference the benchmarks and note that improvements are consistent across runs with reported variance. We will also ensure the results section explicitly discusses statistical significance of the gains. revision: yes
-
Referee: Methods/Results (CSS and generalization): The central assumption that Constrained Subset Search produces minimal-sufficient, interaction-aware KP subsets that generalize beyond the training distribution (OpenMath-Nemotron) is not supported by any described ablation, held-out validation, or analysis showing performance degradation upon KP removal on unseen problems. Without such evidence, the gains could stem from data curation or RL regularization rather than the guidance mechanism.
Authors: The paper demonstrates outperformance on eight diverse benchmarks, including several outside the OpenMath-Nemotron distribution, and analyzes the pruning interaction paradox with CSS. However, we acknowledge that explicit ablations isolating CSS subset generalization (e.g., KP removal on held-out unseen problems or dedicated validation of minimal-sufficiency) are not described. We will add such experiments in the revised version, including performance comparisons with and without selected KPs on a held-out problem set, to better distinguish the contribution of the minimal-sufficient guidance from data curation or regularization effects. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core contribution is an empirical RL training procedure (KnowRL) that applies Constrained Subset Search to curate knowledge-point subsets and optimizes against an identified pruning interaction paradox. All load-bearing claims reduce to measured benchmark accuracies after training KnowRL-Nemotron-1.5B on OpenMath-Nemotron data and evaluating with/without hints. No equations, definitions, or self-citations are shown that render the reported +9.63 point gain or 74.16 SOTA figure equivalent to fitted inputs or prior author results by construction. The method is presented as a practical engineering framework whose validity rests on external benchmark outcomes rather than internal self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard RL assumptions for language model policy optimization hold, including that reward signals can be shaped by external guidance without destabilizing training.
invented entities (2)
-
Atomic knowledge points (KPs)
no independent evidence
-
Constrained Subset Search (CSS)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Co-Evolving Policy Distillation
CoPD integrates multiple expert capabilities by running parallel RLVR training with bidirectional online policy distillation among experts, outperforming mixed RLVR and sequential OPD while surpassing domain-specific ...
Reference graph
Works this paper leans on
-
[1]
Jiazheng Li, Hong Lu, Kaiyue Wen, Zaiwen Yang, Jiax- uan Gao, Hongzhou Lin, Yi Wu, and Jingzhao Zhang
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math prob- lems and solutions.Hugging Face repository, 13:9. Jiazheng Li, Hong Lu, Kaiyue Wen, Zaiwen Yang, Jiax- uan Gao, Hongzhou Lin, Yi Wu, and Jingzhao Zhang
-
[2]
Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian
Questa: Expanding reasoning capacity in llms via question augmentation.CoRR, abs/2507.13266. Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian. 2026. Self-hinting language models enhance reinforcement learning.Preprint, arXiv:2602.03143. Mingyang Liu, Gabriele Farina, and Asuman E. Ozdaglar. 2025a. UFT: unifying supervised and rein- force...
-
[3]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Feng Zhang, Zezhong Tan, Xinhong Ma, Ziqiang Dong, Xi Leng, Jianfei Zhao, Xin Sun, and Yang Yang. 2025a. Adhint: Adaptive hints with difficulty priors for reinforcement learning.CoRR, abs/2512.13095. Kaiyi Zhang, Ang Lv, Jinpeng Li, Yongbo Wang, Feng Wang, Haoyuan Hu, an...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Your task is to extract the essential math- ematical knowledge required to solve the problem from the correct solution
A correct solution to the problem. Your task is to extract the essential math- ematical knowledge required to solve the problem from the correct solution. Requirements: - List only the core knowledge points that are indispensable for solving the problem. - Each knowledge point should be concise, general, and mathematically fundamental (not problem-specifi...
-
[6]
A mathematics problem
-
[7]
in this case
A candidate knowledge description. Your task is to determine whether the knowl- edge description is STRONGLY COU- PLED to the problem. Strong Coupling means the knowledge de- scription: - Contains specific numerical values, con- stants, or quantities appearing in the prob- lem or its solution (beyond common con- stants likeπ). - Mentions specific object n...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.