Recognition: unknown
T-REN: Learning Text-Aligned Region Tokens Improves Dense Vision-Language Alignment and Scalability
Pith reviewed 2026-05-10 04:51 UTC · model grok-4.3
The pith
T-REN pools image patches into compact text-aligned region tokens to improve dense vision-language alignment and slash token counts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
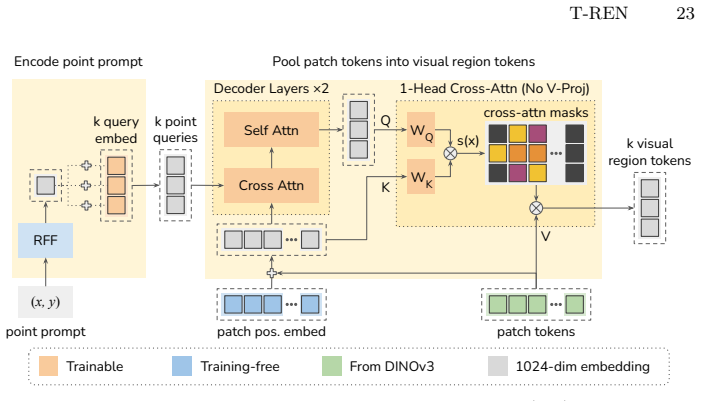
T-REN maps visual data to a compact set of text-aligned region-level representations by training a lightweight network on top of a frozen vision backbone to pool patch-level features within each semantic region and align them with region-level text annotations, delivering stronger dense cross-modal understanding along with large reductions in token count.
What carries the argument
Text-aligned Region Encoder Network (T-REN), a lightweight trainable module that pools patch representations into region tokens aligned to text annotations.
If this is right
- Open-vocabulary semantic segmentation on ADE20K improves by 5.9 mIoU.
- Object-level text-image retrieval recall on COCO increases by 18.4 percent.
- Video object localization recall on Ego4D rises by 15.6 percent.
- Video scene parsing mIoU on VSPW gains 17.6 points with token counts reduced by more than 187 times for videos.
Where Pith is reading between the lines
- The same pooling idea could extend to other dense prediction problems such as depth estimation without changing the backbone.
- Large token reductions open the door to processing much longer video sequences in applications where current patch-based models run out of memory or time.
- Because the backbone remains frozen, T-REN-style modules might plug into many existing pre-trained vision-language models with minimal extra cost.
Load-bearing premise
Region-level text annotations exist for training and the lightweight network can reliably pool patches into semantically meaningful text-aligned region tokens without adapting the frozen backbone.
What would settle it
Train T-REN on data that supplies only global image captions and no region-level text labels, then check whether the reported gains on ADE20K open-vocabulary segmentation and COCO retrieval disappear.
Figures










read the original abstract
Despite recent progress, vision-language encoders struggle with two core limitations: (1) weak alignment between language and dense vision features, which hurts tasks like open-vocabulary semantic segmentation; and (2) high token counts for fine-grained visual representations, which limits scalability to long videos. This work addresses both limitations. We propose T-REN (Text-aligned Region Encoder Network), an efficient encoder that maps visual data to a compact set of text-aligned region-level representations (or region tokens). T-REN achieves this through a lightweight network added on top of a frozen vision backbone, trained to pool patch-level representations within each semantic region into region tokens and align them with region-level text annotations. With only 3.7% additional parameters compared to the vision-language backbone, this design yields substantially stronger dense cross-modal understanding while reducing the token count by orders of magnitude. Specifically, T-REN delivers +5.9 mIoU on ADE20K open-vocabulary segmentation, +18.4% recall on COCO object-level text-image retrieval, +15.6% recall on Ego4D video object localization, and +17.6% mIoU on VSPW video scene parsing, all while reducing token counts by more than 24x for images and 187x for videos compared to the patch-based vision-language backbone. The code and model are available at https://github.com/savya08/T-REN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes T-REN, a lightweight network placed atop a frozen vision-language backbone that pools patch-level features into a compact set of text-aligned region tokens by training against region-level text annotations. It reports large gains on open-vocabulary segmentation (+5.9 mIoU on ADE20K), object-level retrieval (+18.4% recall on COCO), video object localization (+15.6% recall on Ego4D), and video scene parsing (+17.6 mIoU on VSPW), together with token-count reductions exceeding 24x for images and 187x for videos, all at a cost of only 3.7% extra parameters. Public code and models are released.
Significance. If the reported gains hold under scrutiny, the work provides a practical route to stronger dense vision-language alignment and improved scalability for high-resolution or long-video inputs. The public release of code and models is a clear strength that supports independent verification and extension.
major comments (3)
- [Abstract] Abstract: the claimed improvements (+5.9 mIoU, +18.4% recall, etc.) are stated without the corresponding baseline numbers from the underlying frozen backbone or from prior methods, preventing direct assessment of the magnitude of the contribution.
- [Method] Method section: the training procedure relies on region-level text annotations, but no details are given on how these annotations are sourced, generated, or filtered, nor are ablations shown when such supervision is removed or replaced by weaker signals. This information is load-bearing for the reproducibility of the token-reduction and cross-task gains.
- [Experiments] Experiments section: the manuscript provides no ablation isolating the text-alignment loss from simple region pooling, no analysis of how the frozen backbone's initial patch-text misalignment is corrected, and insufficient implementation details (exact backbone, hyper-parameters, baseline reproductions) to verify the numbers on ADE20K, COCO, Ego4D, and VSPW.
minor comments (1)
- [Abstract] Abstract: the precise pre- and post-reduction token counts should be stated explicitly alongside the reduction factors (24x / 187x) for clarity and comparability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to improve clarity, reproducibility, and completeness. We address each major comment below and will revise the manuscript to incorporate the suggested additions and details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claimed improvements (+5.9 mIoU, +18.4% recall, etc.) are stated without the corresponding baseline numbers from the underlying frozen backbone or from prior methods, preventing direct assessment of the magnitude of the contribution.
Authors: We agree that including baseline numbers in the abstract would aid immediate assessment. In the revised version, we will add the frozen backbone baselines (e.g., the mIoU and recall without T-REN) alongside the reported deltas and note key prior-method comparisons. Full tables with all baselines and prior methods remain in the Experiments section. revision: yes
-
Referee: [Method] Method section: the training procedure relies on region-level text annotations, but no details are given on how these annotations are sourced, generated, or filtered, nor are ablations shown when such supervision is removed or replaced by weaker signals. This information is load-bearing for the reproducibility of the token-reduction and cross-task gains.
Authors: We acknowledge that the current manuscript lacks explicit details on annotation sourcing, generation, and filtering. The revised Method section will include a dedicated paragraph describing the public datasets used (e.g., region captions from COCO and ADE20K), any generation or filtering steps, and new ablations that replace the text-alignment supervision with weaker signals or remove it entirely to quantify its role in the token-reduction and performance gains. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript provides no ablation isolating the text-alignment loss from simple region pooling, no analysis of how the frozen backbone's initial patch-text misalignment is corrected, and insufficient implementation details (exact backbone, hyper-parameters, baseline reproductions) to verify the numbers on ADE20K, COCO, Ego4D, and VSPW.
Authors: We agree these elements strengthen the paper. The revised Experiments section will add: (1) an ablation comparing T-REN with versus without the text-alignment loss (i.e., simple pooling only); (2) quantitative and qualitative analysis of misalignment correction between the frozen backbone's patch features and text; and (3) complete implementation details specifying the exact backbone (CLIP ViT-L/14), all hyperparameters, training schedules, and exact reproduction protocols for the reported baselines on ADE20K, COCO, Ego4D, and VSPW. These additions will appear in the main text and supplementary material. revision: yes
Circularity Check
No circularity; empirical gains rest on standard benchmark comparisons, not self-referential definitions or fits.
full rationale
The paper introduces T-REN as a lightweight pooling network trained on region-level text annotations atop a frozen backbone. All reported improvements (+5.9 mIoU, +18.4% recall, etc.) are presented as direct empirical measurements against prior models on public datasets (ADE20K, COCO, Ego4D, VSPW). No equations or derivations are given that reduce a claimed result to its own training inputs by construction. No self-citations are invoked as uniqueness theorems or to justify core design choices. Token reduction is a direct consequence of the region-token output format, not a renamed prediction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Patch-level features from a frozen vision backbone contain sufficient information to form semantic regions
invented entities (1)
-
Text-aligned region tokens
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LookWhen? Fast Video Recognition by Learning When, Where, and What to Compute
LookWhen factorizes video recognition into learning when, where, and what to compute via uniqueness-based token selection and dual-teacher distillation, achieving better accuracy-FLOPs trade-offs than baselines on mul...
Reference graph
Works this paper leans on
-
[1]
ArXiv (2025)
Alama, O., Jariwala, D., Bhattacharya, A., Kim, S., Wang, W., Scherer, S.A.: Radseg: Unleashing parameter and compute efficient zero-shot open-vocabulary segmentation using agglomerative models. ArXiv (2025)
2025
-
[2]
ArXiv (2022)
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. ArXiv (2022)
2022
-
[3]
ArXiv (2025)
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Rasheed, H.A., Wang, J., Monteiro, M., Xu, H., Dong, S., Ravi, N., Li, S.W., Dollár, P., Feichtenhofer, C.: Perception encoder: The best visual embeddings are not at the output of the network. ArXiv (2025)
2025
-
[4]
CVPR (2016)
Caesar, H., Uijlings, J.R.R., Ferrari, V.: Coco-stuff: Thing and stuff classes in context. CVPR (2016)
2016
-
[5]
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers (2020)
2020
-
[6]
ICCV (2021)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. ICCV (2021)
2021
-
[7]
2016 IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR) (2016)
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. 2016 IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR) (2016)
2016
-
[8]
In: CVPR (2022)
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., Martin, M., Nagarajan, T., Radosavovic, I., Ramakrishnan, S.K., Ryan, F., Sharma, J., Wray, M., Xu, M., Xu, E.Z., Zhao, C., Bansal, S., Batra, D., Cartillier, V., Crane, S., Do, T., Doulaty, M., Erapalli, A., Feichtenhofer, C., Fragome...
2022
-
[9]
ArXiv (2021)
Jaegle, A., Gimeno, F., Brock, A., Zisserman, A., Vinyals, O., Carreira, J.: Per- ceiver: General perception with iterative attention. ArXiv (2021)
2021
-
[10]
CVPR (2024)
Jose, C., Moutakanni, T., Kang, D., Baldassarre, F., Darcet, T., Xu, H., Li, S.W., Szafraniec, M., Ramamonjisoa, M., Oquab, M., Sim’eoni, O., Vo, H.V., Labatut, P., Bojanowski, P.: Dinov2 meets text: A unified framework for image- and pixel-level vision-language alignment. CVPR (2024)
2024
-
[11]
In: NIPS (2025)
Khosla, S., V, S.T., Lee, B., Schwing, A., Hoiem, D.: Ren: Fast and efficient region encodings from patch-based image encoders. In: NIPS (2025)
2025
-
[12]
ICCV (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.B.: Segment anything. ICCV (2023)
2023
-
[13]
IJCV (2020) 16 S
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Ka- mali, S., Popov, S., Malloci, M., Kolesnikov, A., Duerig, T., Ferrari, V.: The open images dataset v4: Unified image classification, object detection, and visual rela- tionship detection at scale. IJCV (2020) 16 S. Khosla et al
2020
-
[14]
ArXiv (2024)
Lan, M., Chen, C., Ke, Y., Wang, X., Feng, L., Zhang, W.: Clearclip: Decomposing clip representations for dense vision-language inference. ArXiv (2024)
2024
-
[15]
In: European Conference on Computer Vision (2024)
Lan, M., Chen, C., Ke, Y., Wang, X., Feng, L., Zhang, W.: Proxyclip: Proxy at- tention improves clip for open-vocabulary segmentation. In: European Conference on Computer Vision (2024)
2024
-
[16]
ArXiv (2026)
Li, G., Liu, P.: Fastv-rag: Towards fast and fine-grained video qa with retrieval- augmented generation. ArXiv (2026)
2026
-
[17]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.C.H.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[18]
ArXiv (2023)
Liang, F., Wu, B., Dai, X., Li, K., Zhao, Y., Zhang, H., Zhang, P., Vajda, P., Marculescu, D.: Open-vocabulary semantic segmentation with mask-adapted clip. ArXiv (2023)
2023
-
[19]
ArXiv (2022)
Liang, Y., Ge, C., Tong, Z., Song, Y., Wang, J., Xie, P.: Not all patches are what you need: Expediting vision transformers via token reorganizations. ArXiv (2022)
2022
-
[20]
ICCV (2017)
Neuhold, G., Ollmann, T., Bulò, S.R., Kontschieder, P.: The mapillary vistas dataset for semantic understanding of street scenes. ICCV (2017)
2017
-
[21]
TMLR (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.Q., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y.B., Li, S.W., Misra, I., Rabbat, M.G., Sharma, V., Synnaeve, G., Xu, H., Jégou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual ...
2023
-
[22]
CVPR (2025)
Pitawela, D., Carneiro, G., Chen, H.T.: Cloc: Contrastive learning for ordinal clas- sification with multi-margin n-pair loss. CVPR (2025)
2025
-
[23]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[24]
Rao, Y., Zhao, W., Liu, B., Lu, J., Zhou, J., Hsieh, C.J.: Dynamicvit: Efficient vision transformers with dynamic token sparsification (2021)
2021
-
[25]
ArXiv (2024)
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., Liu, Z., Xu, H., Kim, H.J., Soran, B., Krishnamoorthi, R., Elhoseiny, M., Chandra, V.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. ArXiv (2024)
2024
-
[26]
ArXiv (2024)
Shi, Y., Dong, M., Xu, C.: Harnessing vision foundation models for high- performance, training-free open vocabulary segmentation. ArXiv (2024)
2024
-
[27]
In: CVPR (2024)
Shlapentokh-Rothman, M., Blume, A., Xiao, Y., Wu, Y., V, S.T., Tao, H., Lee, J.Y., Torres, W., Wang, Y.X., Hoiem, D.: Region-based representations revisited. In: CVPR (2024)
2024
-
[28]
ArXiv (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3. ArXiv (2025)
2025
-
[29]
CVPR (2024)
Tao, K., Qin, C., You, H., Sui, Y., Wang, H.: Dycoke : Dynamic compression of tokens for fast video large language models. CVPR (2024)
2024
-
[30]
arXiv (2025)
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., Hénaff, O., Harm- sen, J., Steiner, A., Zhai, X.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv (2025)
2025
-
[31]
ArXiv (2023) T-REN 17
Wang, F., Mei, J., Yuille, A.L.: Sclip: Rethinking self-attention for dense vision- language inference. ArXiv (2023) T-REN 17
2023
-
[32]
CVPR (2020)
Wu, C., Lin, Z., Cohen, S.D., Bui, T., Maji, S.: Phrasecut: Language-based image segmentation in the wild. CVPR (2020)
2020
-
[33]
In: ICLR (2025)
Wu, T.H., Biamby, G., Quenum, J., Gupta, R., Gonzalez, J.E., Darrell, T., Chan, D.: Visual haystacks: A vision-centric needle-in-a-haystack benchmark. In: ICLR (2025)
2025
-
[34]
In: ECCV (2023)
Wysocza’nska, M., Siméoni, O., Ramamonjisoa, M., Bursuc, A., Trzci’nski, T., P’erez, P.: Clip-dinoiser: Teaching clip a few dino tricks. In: ECCV (2023)
2023
-
[35]
ArXiv (2025)
Xiao, Y., Fu, Q., Tao, H., Wu, Y., Zhu, Z., Hoiem, D.: Textregion: Text-aligned region tokens from frozen image-text models. ArXiv (2025)
2025
-
[36]
ArXiv (2025)
Xie, C., Wang, B., Kong, F., Li, J., Liang, D., Zhang, G., Leng, D., Yin, Y.: Fg-clip: Fine-grained visual and textual alignment. ArXiv (2025)
2025
-
[37]
ArXiv (2024)
Xing, L., Huang, Q., wen Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., Lin, D.: Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. ArXiv (2024)
2024
-
[38]
Yin, H., Vahdat, A., Alvarez, J., Mallya, A., Kautz, J., Molchanov, P.: A-vit: Adaptive tokens for efficient vision transformer (2022)
2022
-
[39]
ICCV (2023)
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. ICCV (2023)
2023
-
[40]
IJCV (2016)
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Semantic understanding of scenes through the ade20k dataset. IJCV (2016)
2016
-
[41]
In: ECCV (2021) 18 S
Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip. In: ECCV (2021) 18 S. Khosla et al. A Supplementary Material This supplementary material is organized as follows: Section A.1 analyzes T- REN’s sensitivity to key hyperparameters; Section A.2 compares the computa- tional requirements of T-REN with baselines; and Section A.3 provides imple-...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.