Recognition: unknown
TurboEvolve: Towards Fast and Robust LLM-Driven Program Evolution
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
TurboEvolve makes LLM-driven program evolution more efficient and robust by using multi-island verbalized sampling plus seed-pool injection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TurboEvolve is a multi-island evolutionary framework that improves sample efficiency and robustness under fixed evaluation budgets. It introduces verbalized Sampling, prompting the LLM to emit K diverse candidates with explicit self-assigned sampling weights, an online scheduler that adapts K to expand exploration under stagnation and reduce overhead during steady progress, and seed-pool injection that clusters seeds and assigns them across islands with controlled perturbations and elitist preservation.
What carries the argument
Verbalized Sampling, in which the LLM itself proposes K candidates and their sampling weights, combined with an online scheduler and seed-pool injection across multiple islands.
If this is right
- Stronger performance is reached at lower evaluation budgets across multiple program-optimization benchmarks.
- Best-known solutions improve on several tasks.
- Sample efficiency and robustness increase under fixed budgets.
- Run-to-run variance decreases while solution quality rises.
Where Pith is reading between the lines
- The same verbalized-weight mechanism could be tested in other LLM-driven search loops where diversity must be controlled explicitly.
- Seed-pool injection offers a concrete way to reuse past LLM outputs across parallel search threads without losing novelty.
- The approach suggests that explicit adaptation rules inside the LLM prompt loop can compensate for the stochastic nature of model outputs.
Load-bearing premise
Prompting an LLM to produce diverse candidates with self-assigned weights will reliably generate useful variety, and the scheduler plus seed injection will improve the exploration-exploitation balance without adding new biases or overhead.
What would settle it
On the same program-optimization benchmarks and fixed evaluation budgets, TurboEvolve shows no consistent gain in best solution quality or no reduction in run-to-run variance compared with single-island LLM evolution baselines.
Figures



read the original abstract
LLM-driven program evolution can discover high-quality programs, but its cost and run-to-run variance hinder reliable progress. We propose TurboEvolve, a multi-island evolutionary framework that improves sample efficiency and robustness under fixed evaluation budgets. Inspired by the multiple-offspring strategy in evolutionary algorithms, TurboEvolve introduces verbalized Sampling, prompting the LLM to emit K diverse candidates with explicit self-assigned sampling weights, and an online scheduler that adapts K to expand exploration under stagnation and reduce overhead during steady progress. To exploit existing solution pools, we further propose "seed-pool injection," which clusters seeds and assigns them across islands with controlled perturbations and elitist preservation to balance diversity and refinement. Across multiple program-optimization benchmarks, TurboEvolve consistently achieves stronger performance at lower budgets and improves best-known solutions on several tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TurboEvolve, a multi-island evolutionary framework for LLM-driven program evolution. It introduces verbalized sampling (prompting the LLM to generate K diverse candidates with explicit self-assigned weights), an online scheduler that adapts K based on stagnation detection, and seed-pool injection via clustering with controlled perturbations and elitist preservation. The central empirical claim is that this yields stronger performance than baselines at lower evaluation budgets across program-optimization tasks while also improving best-known solutions on several benchmarks.
Significance. If the performance claims hold under rigorous controls, the work could meaningfully advance sample-efficient LLM-based program synthesis by addressing exploration-exploitation trade-offs in evolutionary loops. The multi-island design with explicit diversity mechanisms and stagnation-triggered adaptation offers a concrete, implementable recipe that could be adopted in other LLM evolution pipelines, particularly where compute budgets are constrained.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the headline claim of 'consistently stronger performance at lower budgets' is stated without any reported run counts, statistical tests (e.g., Wilcoxon or t-tests with p-values), exact baseline implementations, or variance measures. This prevents assessment of whether observed gains exceed noise or are reproducible.
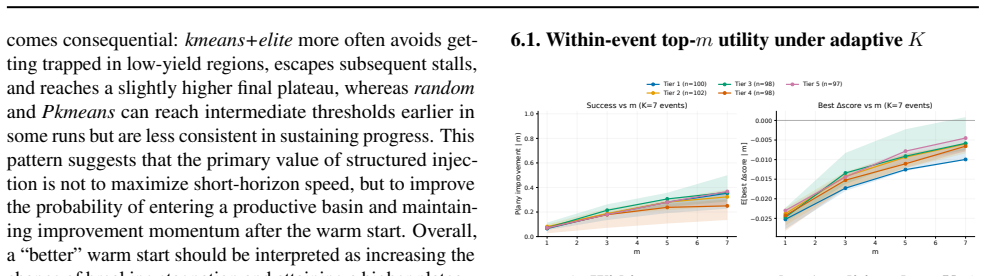
- [§3.2 and §3.3] §3.2 (Verbalized Sampling) and §3.3 (Online Scheduler): no ablation is presented that disables verbalized self-weighting (replacing it with uniform sampling) or freezes K while holding total LLM calls fixed. Without these controls, it is impossible to isolate whether the reported efficiency gains require the proposed mechanisms or arise from other implementation choices such as prompt formatting or island count.
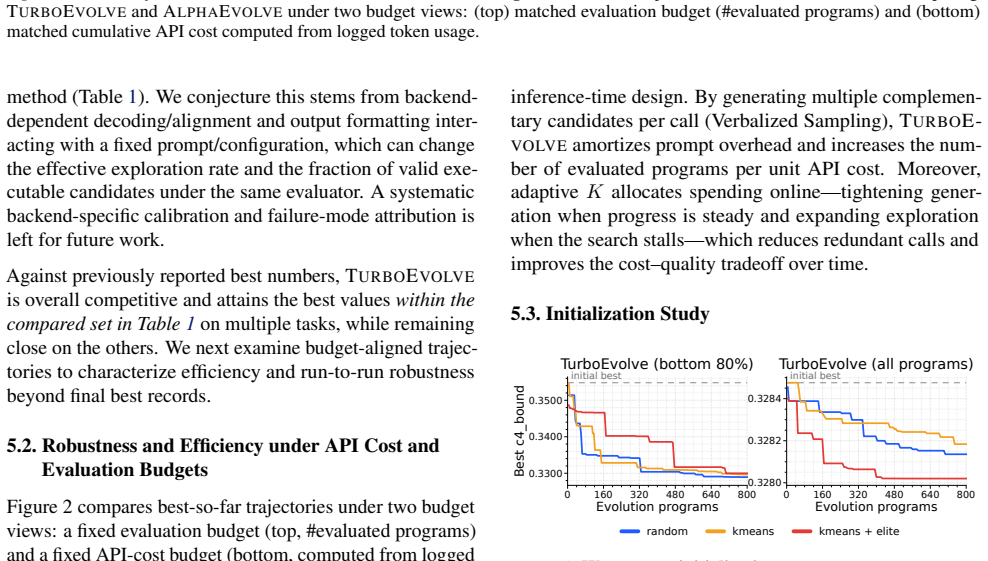
- [§3.4] §3.4 (Seed-Pool Injection): the clustering-plus-perturbation procedure is described but no quantitative analysis (e.g., diversity metrics before/after injection or overhead in prompt tokens) is supplied. This leaves open the possibility that the injection step introduces selection bias or hidden cost that offsets the claimed robustness gains.
minor comments (2)
- [§3.3] Notation for the scheduler's stagnation threshold and the clustering distance metric is introduced without a clear table of symbols or pseudocode, making the exact adaptation rule difficult to re-implement.
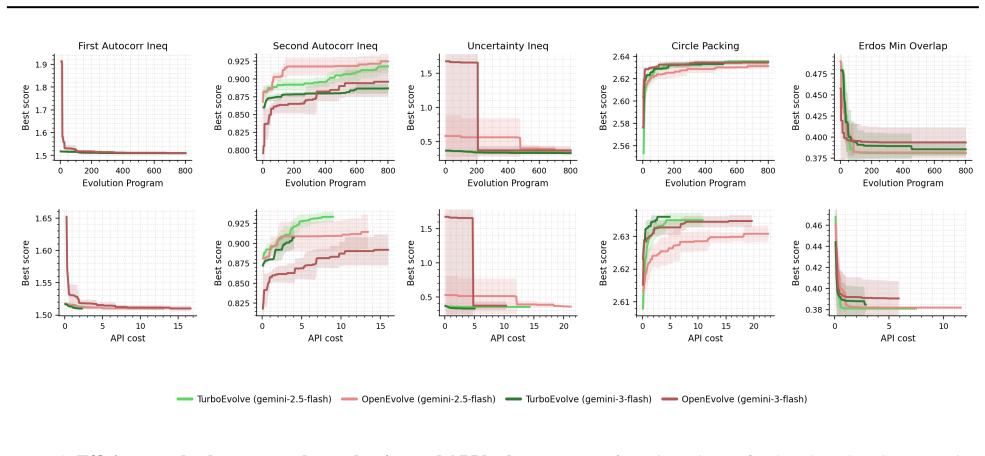
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the evaluation budget (number of LLM calls) and the precise metric (e.g., best fitness or success rate) to allow direct comparison with the textual claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The points raised regarding experimental rigor, ablations, and quantitative analysis are valid and will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline claim of 'consistently stronger performance at lower budgets' is stated without any reported run counts, statistical tests (e.g., Wilcoxon or t-tests with p-values), exact baseline implementations, or variance measures. This prevents assessment of whether observed gains exceed noise or are reproducible.
Authors: We agree that statistical details and reproducibility information are necessary. The experiments were performed with 5 independent runs per method using different random seeds. In the revision we will add a dedicated paragraph in §4 reporting run counts, mean and standard deviation for all metrics, exact baseline code references, and Wilcoxon signed-rank tests with p-values comparing TurboEvolve to baselines. These additions will be placed in both the main text and supplementary material. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (Verbalized Sampling) and §3.3 (Online Scheduler): no ablation is presented that disables verbalized self-weighting (replacing it with uniform sampling) or freezes K while holding total LLM calls fixed. Without these controls, it is impossible to isolate whether the reported efficiency gains require the proposed mechanisms or arise from other implementation choices such as prompt formatting or island count.
Authors: We acknowledge the importance of isolating component contributions. While the integrated system is the focus of the current manuscript, we will add two controlled ablations in the revised §4: (1) replacing self-assigned weights with uniform sampling from the LLM outputs, and (2) fixing K to a constant while keeping the total LLM call budget identical. These experiments will clarify whether the adaptive weighting and scheduling are responsible for the observed gains. revision: yes
-
Referee: [§3.4] §3.4 (Seed-Pool Injection): the clustering-plus-perturbation procedure is described but no quantitative analysis (e.g., diversity metrics before/after injection or overhead in prompt tokens) is supplied. This leaves open the possibility that the injection step introduces selection bias or hidden cost that offsets the claimed robustness gains.
Authors: We will incorporate quantitative evaluation of the seed-pool injection mechanism. In the revised §3.4 and §4 we will report diversity metrics (average pairwise edit distance and embedding cosine similarity) before and after injection, as well as the additional token overhead incurred by the clustering and perturbation prompts. This will allow readers to assess any potential bias or cost trade-offs directly. revision: yes
Circularity Check
No significant circularity in empirical method proposal
full rationale
The paper proposes TurboEvolve as an empirical multi-island evolutionary framework with verbalized sampling, an adaptive scheduler, and seed-pool injection, then reports benchmark performance gains. No mathematical derivation, equations, fitted parameters renamed as predictions, or self-referential claims exist; the central assertions rest on experimental comparisons rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. The work is therefore self-contained as a method proposal with external falsifiability via benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
GEAR: Genetic AutoResearch for Agentic Code Evolution
GEAR applies genetic algorithms to maintain and evolve multiple research states in autonomous code agents, outperforming single-path baselines by continuing to discover improvements over extended runs.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
arXiv preprint arXiv:2510.14150 , year =
Assump c \ a o, H., Ferreira, D., Campos, L., and Murai, F. Codeevolve: An open source evolutionary coding agent for algorithm discovery and optimization. arXiv preprint arXiv:2510.14150, 2025
-
[3]
Cant \'u -Paz, E. et al. A survey of parallel genetic algorithms. Calculateurs paralleles, reseaux et systems repartis, 10 0 (2): 0 141--171, 1998
1998
-
[4]
Promptbreeder: Self-referential self-improvement via prompt evolution,
Fernando, C., Banarse, D., Michalewski, H., Osindero, S., and Rockt \"a schel, T. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023
-
[5]
E., Richardson, J., et al
Goldberg, D. E., Richardson, J., et al. Genetic algorithms with sharing for multimodal function optimization. In Genetic algorithms and their applications: Proceedings of the Second International Conference on Genetic Algorithms, volume 4149, pp.\ 414--425. Lawrence Erlbaum, Hillsdale, NJ, 1987
1987
-
[6]
Unixcoder: Unified cross-modal pre-training for code representation,
Guo, D., Lu, S., Duan, N., Wang, Y., Zhou, M., and Yin, J. Unixcoder: Unified cross-modal pre-training for code representation. arXiv preprint arXiv:2203.03850, 2022
-
[7]
Hevia Fajardo, M. A. and Sudholt, D. Self-adjusting population sizes for non-elitist evolutionary algorithms: why success rates matter. In Proceedings of the Genetic and Evolutionary Computation Conference, pp.\ 1151--1159, 2021
2021
-
[8]
Kazimipour, B., Li, X., and Qin, A. K. A review of population initialization techniques for evolutionary algorithms. In 2014 IEEE congress on evolutionary computation (CEC), pp.\ 2585--2592. IEEE, 2014
2014
-
[9]
Gigaevo: An open source optimization framework powered by llms and evolution algorithms
Khrulkov, V., Galichin, A., Bashkirov, D., Vinichenko, D., Travkin, O., Alferov, R., Kuznetsov, A., and Oseledets, I. Gigaevo: An open source optimization framework powered by llms and evolution algorithms. arXiv preprint arXiv:2511.17592, 2025
-
[10]
Large language models as evolution strategies
Lange, R., Tian, Y., and Tang, Y. Large language models as evolution strategies. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, pp.\ 579--582, 2024
2024
-
[11]
Lange, R. T., Imajuku, Y., and Cetin, E. Shinkaevolve: Towards open-ended and sample-efficient program evolution. arXiv preprint arXiv:2509.19349, 2025
-
[12]
M., Robles, V., and Muelas, S
LaTorre, A., Pe \ n a, J. M., Robles, V., and Muelas, S. Using multiple offspring sampling to guide genetic algorithms to solve permutation problems. In Proceedings of the 10th annual conference on Genetic and evolutionary computation, pp.\ 1119--1120, 2008
2008
-
[13]
Lehman, J., Gordon, J., Jain, S., Ndousse, K., Yeh, C., and Stanley, K. O. Evolution through large models. In Handbook of evolutionary machine learning, pp.\ 331--366. Springer, 2023
2023
-
[14]
A survey of evolutionary algorithms
Liu, L., Fei, T., Zhu, Z., Wu, K., and Zhang, Y. A survey of evolutionary algorithms. In 2023 4th International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), pp.\ 22--27. IEEE, 2023
2023
-
[15]
Illuminating search spaces by mapping elites
Mouret, J.-B. and Clune, J. Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909, 2015
work page Pith review arXiv 2015
-
[16]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Novikov, A., V \ u , N., Eisenberger, M., Dupont, E., Huang, P.-S., Wagner, A. Z., Shirobokov, S., Kozlovskii, B., Ruiz, F. J., Mehrabian, A., et al. Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
P., Dupont, E., Ruiz, F
Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M. P., Dupont, E., Ruiz, F. J., Ellenberg, J. S., Wang, P., Fawzi, O., et al. Mathematical discoveries from program search with large language models. Nature, 625 0 (7995): 0 468--475, 2024
2024
-
[18]
Openevolve: an open-source evolutionary coding agent, 2025
Sharma, A. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve
2025
-
[19]
Loongflow: Directed evolutionary search via a cognitive plan-execute-summarize paradigm
Wan, C., Dai, X., Wang, Z., Li, M., Wang, Y., Mao, Y., Lan, Y., and Xiao, Z. Loongflow: Directed evolutionary search via a cognitive plan-execute-summarize paradigm. arXiv preprint arXiv:2512.24077, 2025
-
[20]
Wang, Y., Su, S.-R., Zeng, Z., Xu, E., Ren, L., Yang, X., Huang, Z., He, X., Ma, L., Peng, B., et al. Thetaevolve: Test-time learning on open problems. arXiv preprint arXiv:2511.23473, 2025
-
[21]
Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
Yuksekgonul, M., Koceja, D., Li, X., Bianchi, F., McCaleb, J., Wang, X., Kautz, J., Choi, Y., Zou, J., Guestrin, C., and Sun, Y. Learning to discover at test time. arXiv preprint arXiv:2601.16175, January 2026. doi:10.48550/arXiv.2601.16175. URL https://arxiv.org/abs/2601.16175
-
[22]
Zhang, J., Yu, S., Chong, D., Sicilia, A., Tomz, M. R., Manning, C. D., and Shi, W. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity. arXiv preprint arXiv:2510.01171, 2025
-
[23]
Gp for object classification: Brood size in brood recombination crossover
Zhang, M., Gao, X., and Lou, W. Gp for object classification: Brood size in brood recombination crossover. In Australasian Joint Conference on Artificial Intelligence, pp.\ 274--284. Springer, 2006
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.