Recognition: unknown
Reinforcement Learning for Robust Calibration of Multi-Qudit Quantum Gates
Pith reviewed 2026-05-10 02:07 UTC · model grok-4.3
The pith
Reinforcement learning learns small corrections to optimal control pulses to produce robust controlled-phase gates on qutrits despite parameter uncertainties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimal control is first used to design high-fidelity control pulses for a nominal system model. Reinforcement learning is then employed as a calibration stage that learns small residual corrections to these pulses in the presence of static model mismatch, thereby preserving good gate performance under realistic parameter uncertainties. By learning structured, low-dimensional residual corrections conditioned on device-specific parameter variations, reinforcement learning enhances the transfer robustness of nominally optimal but parameter-sensitive control solutions across ensembles of devices.
What carries the argument
Contextual deep reinforcement learning that learns low-dimensional residual corrections to the nominal optimal control pulses, conditioned on static parameter variations.
If this is right
- The reinforcement learning step complements rather than replaces the optimal control design.
- Gate performance stays high under realistic static model mismatches and parameter uncertainties.
- Transfer robustness improves across different device instances through the structured corrections.
- Overall sensitivity to parameter fluctuations is reduced in a systematic way.
- Reinforcement learning functions as a practical calibration tool for high-dimensional quantum gates.
Where Pith is reading between the lines
- The same two-stage approach could extend to other multi-qudit gates and operations beyond controlled-phase.
- Corrections pre-learned on simulations might let hardware teams deploy gates faster with only light on-device fine-tuning.
- The low-dimensional correction idea points to a broader pattern for making any sensitive quantum control solution more adaptable.
- Testing the method on systems with time-varying noise would reveal whether the current static-mismatch focus needs expansion.
Load-bearing premise
Small residual corrections learned by contextual reinforcement learning from simulated parameter variations will transfer to real hardware without extensive additional training or invalidating the original pulses.
What would settle it
Apply the RL-corrected pulses to physical two-qutrit hardware with measured static parameter drifts and check whether gate fidelity stays close to the simulated robust values; a large drop would show the corrections do not transfer.
Figures














read the original abstract
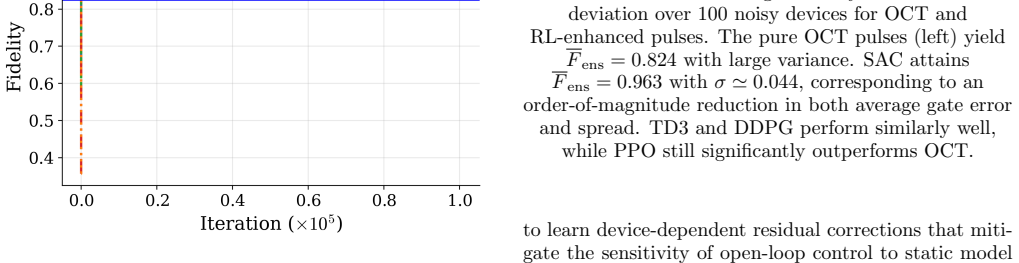
Higher-dimensional quantum systems, such as qudits, offer architectural and algorithmic advantages over qubits, but their increased spectral crowding and limited controllability render high-fidelity quantum gates particularly challenging. We propose a hybrid optimization framework that integrates optimal control theory methods with contextual deep reinforcement learning to achieve robust controlled-phase gates on two qutrits. Optimal control is first used to design high-fidelity control pulses for a nominal system model. Reinforcement learning is then employed as a calibration stage that learns small residual corrections to these pulses in the presence of static model mismatch, thereby preserving good gate performance under realistic parameter uncertainties. By learning structured, low-dimensional residual corrections conditioned on device-specific parameter variations, reinforcement learning enhances the transfer robustness of nominally optimal but parameter-sensitive control solutions across ensembles of devices. Crucially, the reinforcement learning step in our framework does not compete with the optimal control step but provides the adaptability required for realistic hardware, systematically reducing the sensitivity to parameter fluctuations. Our results establish reinforcement learning as a practical and scalable ingredient for robust calibration of quantum gates in high-dimensional systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid optimization framework that first applies optimal control theory to generate high-fidelity nominal pulses for controlled-phase gates on two qutrits, then uses contextual deep reinforcement learning to learn small residual corrections that compensate for static parameter mismatches. The RL stage is conditioned on device-specific variations and is intended to improve robustness across ensembles without replacing or competing with the optimal-control solution.
Significance. If the RL corrections prove transferable, the approach could supply a practical calibration layer for parameter-sensitive qudit gates, addressing a recognized bottleneck in high-dimensional quantum control. The separation of nominal OC design from low-dimensional RL adaptation is a conceptually clean division of labor that may generalize beyond the two-qutrit case examined.
major comments (2)
- [Results and Discussion] The central claim that the learned corrections transfer to realistic hardware while preserving nominal pulses rests entirely on simulated parameter ensembles; no experimental data on superconducting or trapped-ion qudit devices are presented to test whether unmodeled noise, drift, or dynamics invalidate the corrections or require extensive retraining.
- [Methods] Quantitative details on the RL training (reward function, number of episodes, network architecture, and how contextual parameter vectors are encoded) are insufficient to assess whether the reported robustness gains are reproducible or merely artifacts of the chosen simulation model.
minor comments (2)
- Figure captions and axis labels should explicitly state the range of parameter variations used in the training and test ensembles.
- The abstract would benefit from one or two concrete performance numbers (e.g., average fidelity improvement or sensitivity reduction) to substantiate the robustness claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We address each major comment below, providing clarifications and indicating planned revisions where the manuscript can be strengthened without altering its core simulation-based scope.
read point-by-point responses
-
Referee: [Results and Discussion] The central claim that the learned corrections transfer to realistic hardware while preserving nominal pulses rests entirely on simulated parameter ensembles; no experimental data on superconducting or trapped-ion qudit devices are presented to test whether unmodeled noise, drift, or dynamics invalidate the corrections or require extensive retraining.
Authors: We acknowledge that the reported results rely exclusively on numerical simulations of static parameter ensembles, as the manuscript presents a theoretical framework for hybrid optimal-control and contextual RL calibration. This design choice enables controlled, systematic evaluation of robustness across mismatch distributions that would be difficult to access experimentally in a single study. We agree that hardware validation is ultimately required to assess unmodeled effects such as drift and dynamics. In the revised manuscript we will add a new subsection in the Discussion that outlines a concrete experimental roadmap for superconducting qutrit platforms, including protocols for initial pulse transfer, on-device RL fine-tuning, and monitoring for retraining triggers. This addition will clarify the intended transition from simulation to experiment without claiming current hardware results. revision: partial
-
Referee: [Methods] Quantitative details on the RL training (reward function, number of episodes, network architecture, and how contextual parameter vectors are encoded) are insufficient to assess whether the reported robustness gains are reproducible or merely artifacts of the chosen simulation model.
Authors: We accept this criticism and will expand the Methods section substantially in the revision. The updated text will specify: (i) the reward function as a weighted sum of negative gate infidelity (computed via process fidelity) and an L2 pulse-energy penalty with explicit coefficients; (ii) training performed for 10^5 episodes using proximal policy optimization with a batch size of 256 and early stopping based on validation infidelity; (iii) the contextual policy network architecture consisting of a 3-layer MLP (128-128-64 units, ReLU activations) with the contextual parameter vector (normalized detuning and coupling deviations) concatenated to the state observation; and (iv) the precise encoding scheme and hyperparameter values used. These additions will allow independent reproduction and direct assessment of whether the robustness improvements are model-dependent. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes a hybrid workflow: optimal control generates nominal pulses for a model, then contextual RL learns small residual corrections from independent ensembles of simulated parameter variations. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs (e.g., no self-definitional scaling or renaming of known results). The central claim rests on simulation outcomes for transfer robustness, which are externally falsifiable and not tautological. No load-bearing self-citations or uniqueness theorems imported from the authors' prior work appear in the provided text. This is the normal case of a methodological proposal whose results are not forced by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard assumptions of quantum mechanics and optimal control theory hold for the nominal system model.
- domain assumption Static model mismatch can be represented by a low-dimensional set of parameter variations that an RL agent can learn to correct.
Forward citations
Cited by 1 Pith paper
-
Computational and physical complexity of synthesizing random multi-qudit quantum states and unitary operators
Computational complexity of random multi-qudit states and unitaries scales exponentially with qudit number, while physical complexity scales more slowly.
Reference graph
Works this paper leans on
-
[1]
Sample a device instance by drawing (δω 1, δω2, δg) from the noise distribution
-
[2]
Construct the effective HamiltonianH 0(λ) with λ= (ω 1, ω2, χ1, χ2, g)
-
[3]
Compute the OCT baseline fidelity for this device, FOCT(δω1, δω2, δg) =F avg U[ϵ OCT;λ], U CZ3 .(12)
-
[4]
Provide the agent with a normalized context vector o= δω1 σω , δω2 σω , δg σg ,(13) which lies in a bounded subset ofR 3
-
[5]
The agent outputs an actiona∈[−1,1] 2K, corre- sponding to scaled cosine coefficients for the two drives: ci =αa i, i= 1,2,(14) with a global coefficient scaleα= 0.03. 5
-
[6]
(8), form the total pulsesϵ tot, propagate the system, and compute FRL(δω1, δω2, δg) =F avg U[ϵ tot;λ], U CZ3 .(15)
Build residual pulses via Eq. (8), form the total pulsesϵ tot, propagate the system, and compute FRL(δω1, δω2, δg) =F avg U[ϵ tot;λ], U CZ3 .(15)
-
[7]
By construction,r >0 if and only if the RL-corrected pulses outperform the OCT baseline on that particular device instance
Return a scalar reward r=F RL −F OCT,(16) and terminate the episode. By construction,r >0 if and only if the RL-corrected pulses outperform the OCT baseline on that particular device instance. This reward shaping makes the learning problem explicitlyresidual: the agent is incentivized to discover corrections that enhance robustness rather than to reproduc...
-
[8]
S. S. Bullock, D. P. O’Leary, and G. K. Bren- nen, Asymptotically optimal quantum circuits ford- level systems, Phys. Rev. Lett.94, 230502 (2005), doi:10.1103/PhysRevLett.94.230502
-
[9]
B. P. Lanyon, M. Barbieri, M. P. Almeida,et al., Simplifying quantum logic using higher-dimensional Hilbert spaces, Nat. Phys.5, 134–140 (2009), doi:10.1038/nphys1150
-
[10]
Y. Chi, J. Huang, Z. Zhang,et al., A programmable qudit-based quantum processor, Nat. Commun.13, 1166 (2022), doi:10.1038/s41467-022-28767-x
-
[11]
R. Bianchetti, S. M. Girvin, M. H. Devoret, R. J. Schoelkopf, and A. Wallraff, Control and tomography of a three-level superconducting artifi- 15 cial atom, Phys. Rev. Lett.105, 223601 (2010), doi:10.1103/PhysRevLett.105.223601
-
[12]
M. S. Blok, V. V. Ramasesh, T. Schuster, K. O’Brien, J. M. Kreikebaum, D. Dahlen, A. Morvan, B. Yoshida, N. Y. Yao, and I. Siddiqi, Quantum information scram- bling on a superconducting qutrit processor, Phys. Rev. X11, 021010 (2021), doi:10.1103/PhysRevX.11.021010
-
[13]
T. Roy, Z. Li, E. Kapit, and D. I. Schuster, Two- qutrit quantum algorithms on a programmable supercon- ducting processor, Phys. Rev. Appl.19, 064024 (2023), doi:10.1103/PhysRevApplied.19.064024
-
[14]
N. Goss, A. Morvan, B. Marinelli,et al., High-fidelity qutrit entangling gates for superconducting circuits, Nat. Commun.13, 7481 (2022), doi:10.1038/s41467-022- 34851-z
-
[15]
M. Kononenko, M. A. Yurtalan, S. Ren, J. Shi, S. Ashhab, and A. Lupascu, Characterization of con- trol in a superconducting qutrit using randomized benchmarking, Phys. Rev. Res.3, L042007 (2021), doi:10.1103/PhysRevResearch.3.L042007
-
[16]
S. J. Glaser, U. Boscain, T. Calarco,et al., Training Schr¨ odinger’s cat: quantum optimal control, Eur. Phys. J. D69, 279 (2015), doi:10.1140/epjd/e2015-60464-1
-
[17]
A. Morvan, V. V. Ramasesh, M. S. Blok, J. M. Kreike- baum, K. O’Brien, L. Chen, B. K. Mitchell, R. K. Naik, D. I. Santiago, and I. Siddiqi, Qutrit randomized benchmarking, Phys. Rev. Lett.126, 210504 (2021), doi:10.1103/PhysRevLett.126.210504
-
[18]
M. A. Yurtalan, J. Shi, M. Kononenko, A. Lupascu, and S. Ashhab, Implementation of a Walsh–Hadamard gate in a superconducting qutrit, Phys. Rev. Lett.125, 180504 (2020), doi:10.1103/PhysRevLett.125.180504
-
[19]
M. Ringbauer, M. Meth, L. Postler,et al., A universal qudit quantum processor with trapped ions, Nat. Phys. 18, 1053–1057 (2022), doi:10.1038/s41567-022-01658-0
-
[20]
B. Basyildiz, Z. Gong, and S. Ashhab, Speed limits of two-qutrit gates, arXiv:2510.07742 [quant-ph] (2025). https://arxiv.org/abs/2510.07742
-
[21]
J. Q. You, X. Hu, S. Ashhab, and F. Nori, Low- decoherence flux qubit, Phys. Rev. B75, 140515 (2007), doi:10.1103/PhysRevB.75.140515
-
[22]
M. Subramanian and A. Lupascu, Efficient two- qutrit gates in superconducting circuits using para- metric coupling, Phys. Rev. A108, 062616 (2023), doi:10.1103/PhysRevA.108.062616
-
[23]
R. W. Heeres, P. Reinhold, N. Ofek,et al., Implementing a universal gate set on a logical qubit encoded in an os- cillator, Nat. Commun.8, 94 (2017), doi:10.1038/s41467- 017-00045-1
-
[24]
P. M. Poggi, G. De Chiara, S. Campbell, and A. Kiely, Universally robust quantum con- trol, Phys. Rev. Lett.132, 193801 (2024), doi:10.1103/PhysRevLett.132.193801
-
[25]
A. Jaouadi, E. Barrez, Y. Justum, and M. Desouter- Lecomte, Quantum gates in hyperfine levels of ultra- cold alkali dimers by revisiting constrained-phase opti- mal control design, J. Chem. Phys.139, 014310 (2013), doi:10.1063/1.4812317
-
[26]
Implementing Quantum Gates and Algorithms in Ultracold Polar Molecules,
S. Vranckx, A. Jaouadi, P. Pellegrini, L. Bomble, N. Vaeck, and M. Desouter-Lecomte, “Implementing Quantum Gates and Algorithms in Ultracold Polar Molecules,” N. Lorente and C. Joachim (Springer, Berlin, Heidelberg, 2013). doi:10.1007/978-3-642-33137-4 21
-
[27]
N. Khaneja, T. Reiss, C. Kehlet, T. Schulte-Herbr¨ uggen, and S. J. Glaser, Optimal control of coupled spin dy- namics: design of NMR pulse sequences by gradient as- cent algorithms, J. Magn. Reson.172, 296–305 (2005), doi:10.1016/j.jmr.2004.11.004
-
[28]
C. P. Koch, U. Boscain, T. Calarco, M. J. Goerz, S. J. Glaser, S. Hegerfeldt, M. Horn, D. Jaksch, M. K. Olsen, and A. Roux, Quantum optimal control in quantum technologies: Strategic report on current sta- tus, visions and goals for research in Europe, EPJ Quan- tum Technol.9, 19 (2022), doi:10.1140/epjqt/s40507- 022-00138-x
-
[29]
D. J. Egger and F. K. Wilhelm, Optimized controlled-Z gates for two superconducting qubits coupled through a resonator, Supercond. Sci. Technol.27, 014001 (2014), doi:10.1088/0953-2048/27/1/014001
-
[30]
J. Kelly, R. Barends, B. Campbell, Y. Chen, Z. Chen, B. Chiaro, A. Dunsworth, A. G. Fowler, I.-C. Hoi, E. Jef- frey, A. Megrant, J. Mutus, C. Neill, P. J. J. O’Malley, C. Quintana, P. Roushan, D. Sank, A. Vainsencher, J. Wenner, T. C. White, A. N. Cleland, and J. M. Mar- tinis, Optimal quantum control using randomized benchmarking, Phys. Rev. Lett.112, 24...
-
[31]
S. Ashhab, P. C. de Groot, and F. Nori, Speed limits for quantum gates in multiqubit systems, Phys. Rev. A85, 052327 (2012), doi:10.1103/PhysRevA.85.052327
-
[32]
J. Ghosh, A. Galiautdinov, Z. Zhou, A. N. Ko- rotkov, J. M. Martinis, and M. R. Geller, High-fidelity controlled-σZ gate for resonator-based superconducting quantum computers, Phys. Rev. A87, 022309 (2013), doi:10.1103/PhysRevA.87.022309
-
[33]
F. Motzoi, J. M. Gambetta, P. Rebentrost, and F. K. Wilhelm, Simple pulses for elimination of leakage in weakly nonlinear qubits, Phys. Rev. Lett.103, 110501 (2009), doi:10.1103/PhysRevLett.103.110501
-
[34]
S. Ashhab, F. Yoshihara, T. Fuse, N. Yamamoto, A. Lu- pascu, and K. Semba, Speed limits for two-qubit gates with weakly anharmonic qubits, Phys. Rev. A105, 042614 (2022), doi:10.1103/PhysRevA.105.042614
-
[35]
D. J. Egger and F. K. Wilhelm, Adaptive hybrid optimal quantum control for imprecisely character- ized systems, Phys. Rev. Lett.112, 240503 (2014), doi:10.1103/PhysRevLett.112.240503
-
[36]
M. Bukov, A. G. R. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, Reinforcement learning in different phases of quantum control, Phys. Rev. X8, 031086 (2018), doi:10.1103/PhysRevX.8.031086
-
[37]
M. Y. Niu, S. Boixo, V. Smelyanskiy, and H. Neven, Universal quantum control through deep reinforce- ment learning, npj Quantum Inf.5, 33 (2019), doi:10.1038/s41534-019-0141-3
-
[38]
Y. Liu, Superconducting quantum computing optimiza- tion based on multi-objective deep reinforcement learn- ing, Sci. Rep.15, 3828 (2025), doi:10.1038/s41598-024- 73456-y
-
[39]
A. Jaouadi, E. Mangaud, and M. Desouter-Lecomte, Re- exploring control strategies in a non-Markovian open quantum system by reinforcement learning, Phys. Rev. A 109, 013104 (2024), doi:10.1103/PhysRevA.109.013104
-
[40]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor, inProceedings of the 35th International Conference on Machine Learning (ICML), Proc. Mach. Learn. Res.80, 1861–1870 (2018). 16
2018
-
[41]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger, Addressing function approximation error in actor-critic methods, in Proceedings of the 35th International Conference on Ma- chine Learning (ICML), Proc. Mach. Learn. Res.80, 1587–1596 (2018)
2018
-
[42]
T. P. Lillicrapet al., Continuous control with deep rein- forcement learning, arXiv:1509.02971
work page internal anchor Pith review arXiv
-
[43]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, Proximal policy optimization algorithms, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
S. Li, Y. Fan, X. Li,et al., Robust quantum control using reinforcement learning from demonstration, npj Quan- tum Inf.11, 124 (2025), doi:10.1038/s41534-025-01065-2
-
[45]
M. A. Nielsen, A simple formula for the average gate fidelity of a quantum dynamical operation, Phys. Lett. A 303, 249–252 (2002), doi:10.1016/S0375-9601(02)01272- 0
-
[46]
J. R. Johansson, P. D. Nation, and F. Nori, QuTiP 2: A Python framework for the dynamics of open quan- tum systems, Comput. Phys. Commun.184, 1234–1240 (2013), doi:10.1016/j.cpc.2012.11.019
-
[47]
Lindoy, Deep Lall, Sebastian E
A. Agarwal, L. P. Lindoy, D. Lall, S. E. de Graaf, T. Lind- str¨ om, and I. Rungger, “Fast-tracking and disentangling of qubit noise fluctuations using minimal-data averaging and hierarchical discrete fluctuation auto-segmentation,” arXiv:2505.23622 (2025). doi:10.48550/arXiv.2505.23622
-
[48]
Decoherence benchmarking of su- perconducting qubits,
J. J. Burnett, A. Bengtsson, M. Scigliuzzo, J. Bylan- der, and P. Delsing, “Decoherence benchmarking of su- perconducting qubits,” npj Quantum Inf.5, 54 (2019). doi:10.1038/s41534-019-0168-5
-
[49]
Y. Baum, M. Amico, S. Howell, M. Hush, M. Li- uzzi, P. Mundada, T. Merkh, A. R. R. Carvalho, and M. J. Biercuk,Experimental deep reinforcement learn- ing for error-robust gate-set design on a superconduct- ing quantum computer, PRX Quantum2, 040324 (2021). https://doi.org/10.1103/PRXQuantum.2.040324
-
[50]
V. V. Sivak, A. Eickbusch, H. Liu, B. Royer, I. Tsiout- sios, and M. H. Devoret,Model-free quantum control with reinforcement learning, Phys. Rev. X12, 011059 (2022). https://doi.org/10.1103/PhysRevX.12.011059
-
[51]
H. N. Nguyen, F. Motzoi, M. Metcalf, K. B. Wha- ley, M. Bukov, and M. Schmitt,Reinforcement learning pulses for transmon qubit entangling gates, Mach. Learn.: Sci. Technol.5, 025066 (2024). https://doi.org/10.1088/2632-2153/ad4f4d
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.