Beyond Chain-of-Thought: Rewrite as a Universal Interface for Generative Multimodal Embeddings
Pith reviewed 2026-05-08 12:43 UTC · model grok-4.3
The pith
Rewrite replaces chain-of-thought to create stronger generative multimodal embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
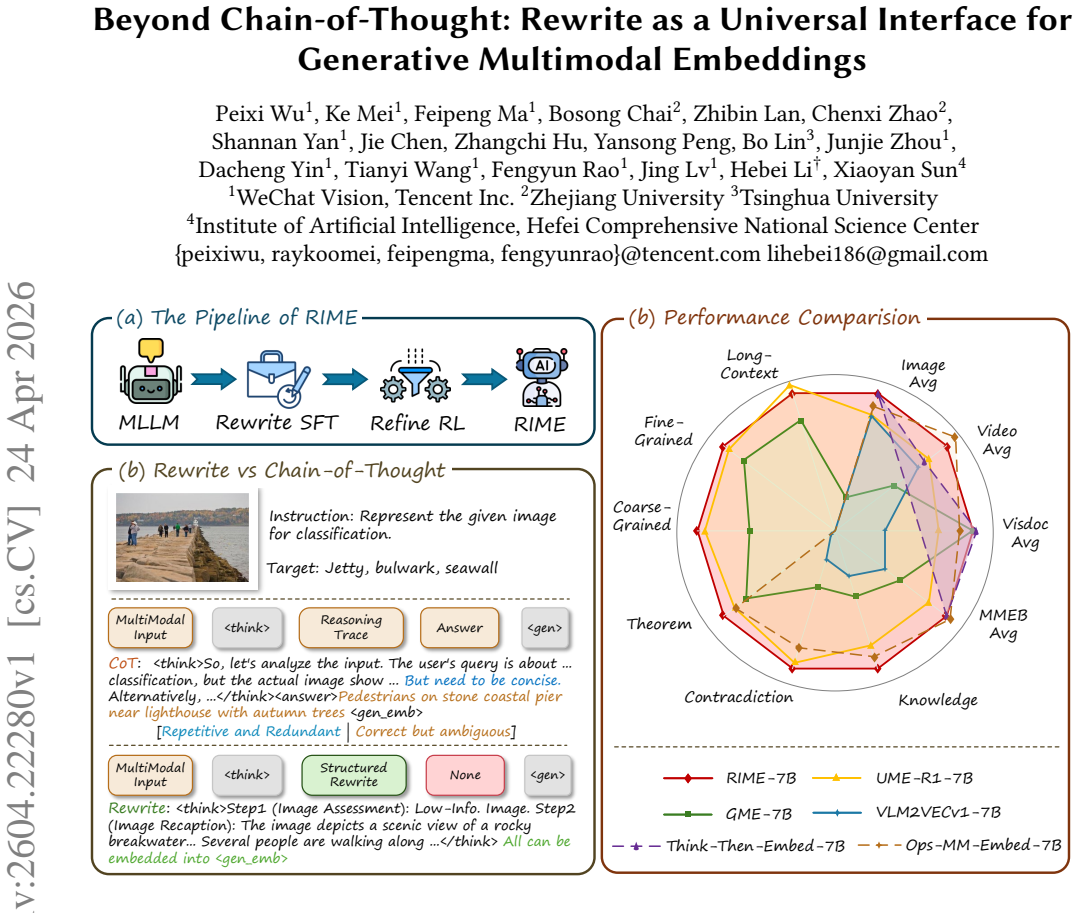
RIME is a unified framework that jointly optimizes generation and embedding through a retrieval-friendly rewrite, bridged by Cross-Mode Alignment for mutual retrieval between generative and discriminative spaces and guided by Refine-RL that anchors optimization to discriminative embeddings, resulting in substantial outperformance over prior generative models on MMEB-V2, MRMR, and UVRB while shortening the length of thinking.
What carries the argument
The retrieval-friendly rewrite step that acts as the central interface to jointly optimize generative and embedding objectives while preserving semantic content for downstream tasks.
If this is right
- Generative embeddings become usable in broader retrieval scenarios without introducing semantic ambiguity from long reasoning.
- Models gain the ability to trade off efficiency against accuracy through alignment of the two embedding spaces.
- Reinforcement learning for generation gains stability by treating discriminative embeddings as fixed semantic anchors.
- Shorter reasoning traces lower computational cost while sustaining or increasing task accuracy on embedding benchmarks.
Where Pith is reading between the lines
- The rewrite interface might extend beyond embeddings to other generative multimodal tasks such as captioning or question answering.
- Further tests on zero-shot or cross-modal retrieval could show whether the gains hold when query distributions shift from the training benchmarks.
- Integrating the rewrite with additional length penalties might yield even more compact outputs without further performance loss.
Load-bearing premise
The rewrite step preserves necessary semantic information for downstream retrieval while remaining retrieval-friendly.
What would settle it
Compare retrieval accuracy on held-out multimodal queries using RIME rewrite outputs versus direct chain-of-thought outputs; a drop below prior generative baselines would falsify the performance claim.
Figures









read the original abstract
Multimodal Large Language Models (MLLMs) have emerged as a promising foundation for universal multimodal embeddings. Recent studies have shown that reasoning-driven generative multimodal embeddings can outperform discriminative embeddings on several embedding tasks. However, Chain-of-Thought (CoT) reasoning tends to generate redundant thinking steps and introduce semantic ambiguity in the summarized answers in broader retrieval scenarios. To address this limitation, we propose Rewrite-driven Multimodal Embedding (RIME), a unified framework that jointly optimizes generation and embedding through a retrieval-friendly rewrite. Meanwhile, we present the Cross-Mode Alignment (CMA) to bridge the generative and discriminative embedding spaces, enabling flexible mutual retrieval to trade off efficiency and accuracy. Based on this, we also introduce Refine Reinforcement Learning (Refine-RL) that treats discriminative embeddings as stable semantic anchors to guide the rewrite optimization. Extensive experiments on MMEB-V2, MRMR and UVRB demonstrate that RIME substantially outperforms prior generative embedding models while significantly reducing the length of thinking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rewrite-driven Multimodal Embedding (RIME), a unified framework replacing Chain-of-Thought reasoning with a retrieval-friendly rewrite step for generative multimodal embeddings. It introduces Cross-Mode Alignment (CMA) to bridge generative and discriminative embedding spaces for flexible mutual retrieval and Refine Reinforcement Learning (Refine-RL) that anchors rewrite optimization to stable discriminative embeddings. Experiments on MMEB-V2, MRMR, and UVRB are reported to show substantial outperformance over prior generative embedding models while reducing thinking length.
Significance. If the empirical results and ablations hold, RIME could offer a more efficient interface for generative multimodal embeddings by mitigating CoT redundancy and ambiguity, with CMA enabling trade-offs between efficiency and accuracy. The joint optimization via Refine-RL provides a concrete mechanism for aligning generative outputs to retrieval-friendly semantics.
major comments (2)
- [Abstract] Abstract: the claim of substantial outperformance on MMEB-V2, MRMR, and UVRB supplies no quantitative results, baselines, error bars, or ablation details, preventing evaluation of the central empirical claim from the provided text.
- [Abstract / §4] Abstract / §4 (Experiments): the assertion that the rewrite step preserves task-relevant semantics while remaining retrieval-friendly is not isolated from CMA alignment or Refine-RL anchoring; no controlled ablation, information-theoretic argument, or formal derivation separates the rewrite's contribution, which is load-bearing for attributing observed gains to the proposed interface rather than auxiliary objectives.
minor comments (1)
- [Abstract] Abstract: 'significantly reducing the length of thinking' lacks specific metrics (e.g., token counts or step reductions versus CoT baselines) that would clarify the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our paper. We have carefully considered each comment and provide point-by-point responses below, along with planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of substantial outperformance on MMEB-V2, MRMR, and UVRB supplies no quantitative results, baselines, error bars, or ablation details, preventing evaluation of the central empirical claim from the provided text.
Authors: We agree with the referee that the abstract lacks specific quantitative details, which would help readers quickly assess the claims. In the revised manuscript, we will update the abstract to include key performance numbers (e.g., average improvements on MMEB-V2, MRMR, and UVRB), mention the main baselines, and note that results include error bars from multiple runs. This addresses the evaluation concern directly. revision: yes
-
Referee: [Abstract / §4] Abstract / §4 (Experiments): the assertion that the rewrite step preserves task-relevant semantics while remaining retrieval-friendly is not isolated from CMA alignment or Refine-RL anchoring; no controlled ablation, information-theoretic argument, or formal derivation separates the rewrite's contribution, which is load-bearing for attributing observed gains to the proposed interface rather than auxiliary objectives.
Authors: We appreciate this point regarding the isolation of the rewrite step's contribution. The current experiments in §4 include ablations for the overall framework, but to more precisely separate the rewrite's role from CMA and Refine-RL, we will add a dedicated controlled experiment in the revision. This will involve comparing the full RIME against a variant where the rewrite is replaced by standard generation while retaining the other components. We will also include a short discussion on the semantic preservation properties of the rewrite based on embedding similarity metrics. This will better attribute the gains to the proposed rewrite interface. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmarks, not self-referential derivations
full rationale
The paper introduces RIME as a framework combining a retrieval-friendly rewrite interface, Cross-Mode Alignment (CMA), and Refine-RL, but supplies no equations, first-principles derivations, or parameter-fitting steps that reduce to their own inputs. Central performance claims are supported solely by empirical results on MMEB-V2, MRMR, and UVRB; the rewrite's semantic-preservation property is asserted as a design choice rather than derived from prior fitted quantities or self-citations. No load-bearing self-citation chains, ansatz smuggling, or uniqueness theorems appear in the provided text. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LaME: Learning to Think in Latent Space for Multimodal Embedding via Information Bottleneck
LaME performs latent multimodal embedding reasoning with K learnable reason tokens in a weakly supervised information bottleneck, matching some explicit CoT models while running 60x faster.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.