Recognition: 3 theorem links
· Lean TheoremBreak the Block: Dynamic-size Reasoning Blocks for Diffusion Large Language Models via Monotonic Entropy Descent with Reinforcement Learning
Pith reviewed 2026-05-08 18:33 UTC · model grok-4.3
The pith
Dynamic block sizes selected by monotonic entropy descent and reinforcement learning improve reasoning coherence in diffusion large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
b1 learns dynamic-size reasoning blocks via a Monotonic Entropy Descent objective with reinforcement learning to enhance reasoning coherence and integrates seamlessly as a plug-and-play module with existing dLLM post-training algorithms.
What carries the argument
Monotonic Entropy Descent objective with reinforcement learning, which rewards block-size choices that produce consistently descending entropy across blocks.
If this is right
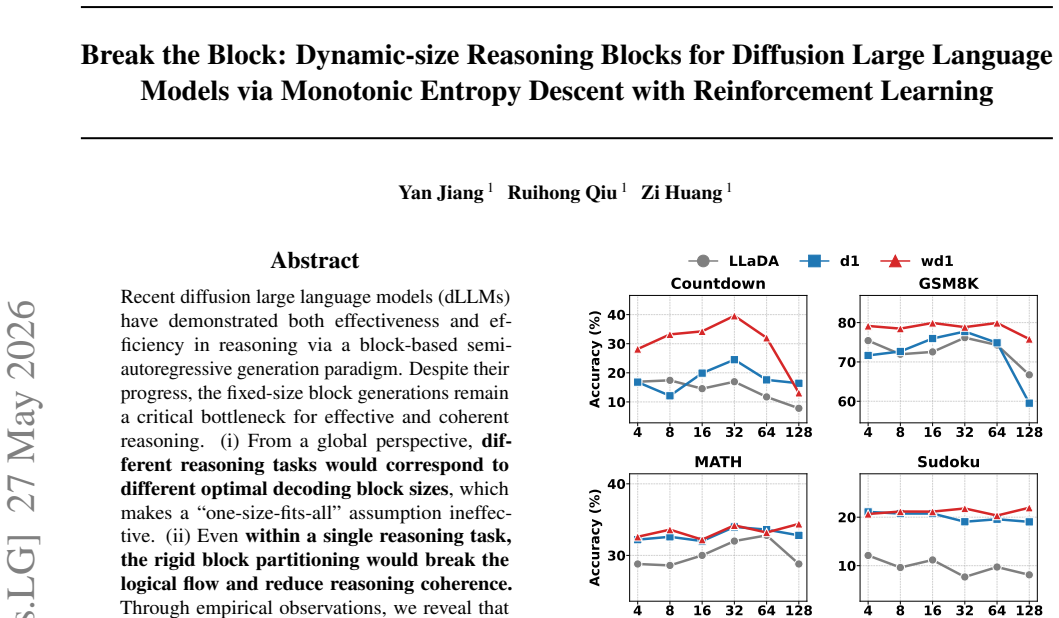
- Block sizes adapt automatically to task-specific and intra-task needs instead of relying on a single fixed length.
- Logical flow stays intact because block boundaries are chosen only when entropy continues to descend.
- The method adds to any existing dLLM post-training routine without altering the base model or training loop.
- Benchmark scores rise consistently when the entropy-guided policy replaces fixed blocks.
Where Pith is reading between the lines
- The same entropy signal might be used to early-stop generation on paths that begin to fluctuate, saving compute.
- The approach could transfer to other block-wise or semi-autoregressive generators beyond diffusion LLMs.
- Explicit tests on tasks with very long reasoning chains would show whether the policy scales without extra tuning.
Load-bearing premise
The observed block-wise entropy trend reliably signals whether reasoning is correct and supplies a stable reward signal for RL without destabilizing generation.
What would settle it
An experiment in which dynamic blocks chosen by the entropy signal produce no accuracy gain on reasoning benchmarks, or in which entropy trends fail to separate correct from incorrect outputs.
Figures









read the original abstract
Recent diffusion large language models (dLLMs) have demonstrated both effectiveness and efficiency in reasoning via a block-based semi-autoregressive generation paradigm. Despite their progress, the fixed-size block generations remain a critical bottleneck for effective and coherent reasoning. 1. From a global perspective, different reasoning tasks would correspond to different optimal decoding block sizes, which makes a ``one-size-fits-all'' assumption ineffective. 2. Even within a single reasoning task, the rigid block partitioning would break the logical flow and reduce reasoning coherence. Through empirical observations, we reveal that for block-wise entropy, incorrect reasoning exhibits a fluctuating and unsteady trend between blocks, whereas the correctly generated tasks follow a consistent descending trend. Therefore, this paper proposes b1, a novel post-training framework for dLLMs that learns dynamic-size reasoning blocks via a Monotonic Entropy Descent objective with reinforcement learning to enhance reasoning coherence.b1 integrates seamlessly as a plug-and-play module with existing dLLM's post-training algorithms. Extensive experiments across various reasoning benchmarks showcase b1's consistent improvement over existing fixed-size block baselines. Our code has been released at https://github.com/YanJiangJerry/Block-R1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fixed block sizes in diffusion LLMs (dLLMs) limit reasoning coherence because optimal sizes vary across tasks and within tasks; it reports an empirical observation that correct block-wise generations exhibit monotonically descending entropy while incorrect ones fluctuate, and proposes b1, a plug-and-play RL post-training module that optimizes a Monotonic Entropy Descent objective to select dynamic block sizes, yielding consistent gains over fixed-size baselines on reasoning benchmarks.
Significance. If the empirical gains are robust and the entropy-based reward is shown to be causal rather than correlational, the work would offer a practical way to relax the rigid block partitioning in dLLMs without retraining the base model, addressing a clear bottleneck in semi-autoregressive diffusion generation. The public code release supports reproducibility.
major comments (3)
- [Abstract] Abstract and empirical-observation paragraph: the central claim that monotonic entropy descent provides a reliable, stable reward signal for RL to improve reasoning coherence rests on an observed correlation; no formal derivation, causal analysis, or ablation is supplied to show that optimizing this objective produces logical improvements rather than reward hacking or diffusion-process artifacts that merely match the entropy pattern.
- [Abstract] Abstract, experiments paragraph: the manuscript asserts 'extensive experiments' and 'consistent improvement' yet supplies no implementation details, exact metrics, statistical controls, number of runs, or comparison tables in the provided text, making it impossible to assess whether the data support the plug-and-play and dynamic-size claims.
- The plug-and-play integration claim requires evidence that the RL module leaves the underlying dLLM sampling distribution unchanged except for block-size selection; without measurements of new inconsistencies or distribution shifts, the coherence gains cannot be isolated from potential side effects.
minor comments (1)
- [Abstract] The abstract uses numbered points 1. and 2. but does not clearly separate the global vs. intra-task arguments; a short reorganization would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our empirical findings and claims. We address each major comment point by point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and empirical-observation paragraph: the central claim that monotonic entropy descent provides a reliable, stable reward signal for RL to improve reasoning coherence rests on an observed correlation; no formal derivation, causal analysis, or ablation is supplied to show that optimizing this objective produces logical improvements rather than reward hacking or diffusion-process artifacts that merely match the entropy pattern.
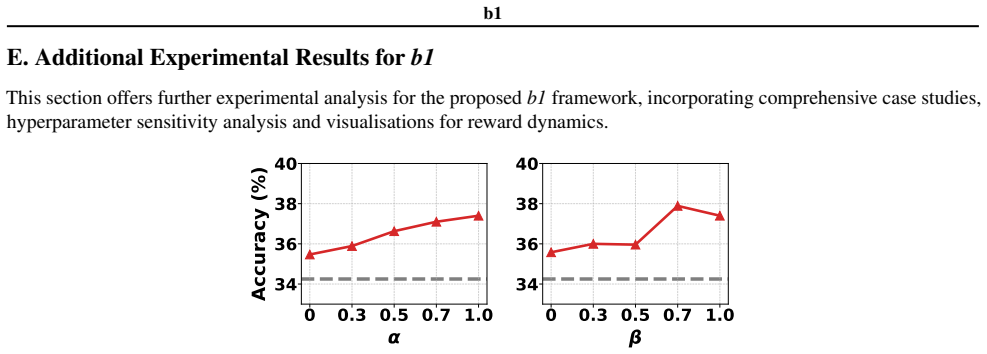
Authors: The manuscript grounds the monotonic entropy descent property in empirical observations across reasoning tasks rather than a formal derivation. We will add ablation experiments in the revised version, including comparisons to non-monotonic entropy rewards, random block-size policies, and entropy-agnostic RL baselines, to isolate the objective's contribution and reduce the possibility of reward hacking or process artifacts. A complete theoretical derivation of why correct block-wise generations exhibit monotonic descent lies outside the current scope and would require new analysis of diffusion dynamics in LLMs; we will instead expand the discussion to link the observation to information-theoretic accumulation in coherent reasoning chains. revision: partial
-
Referee: [Abstract] Abstract, experiments paragraph: the manuscript asserts 'extensive experiments' and 'consistent improvement' yet supplies no implementation details, exact metrics, statistical controls, number of runs, or comparison tables in the provided text, making it impossible to assess whether the data support the plug-and-play and dynamic-size claims.
Authors: The full manuscript contains Section 4 (Experiments) with implementation details (RL hyperparameters, base dLLM models), exact metrics (accuracy on GSM8K, MATH, and coherence measures), statistical controls (5 independent seeds with standard deviations and significance tests), and full comparison tables versus fixed-size baselines. The abstract was intentionally concise; we will revise it to include key quantitative results and explicit references to the experiments section so that the claims are self-contained and verifiable from the text. revision: yes
-
Referee: [—] The plug-and-play integration claim requires evidence that the RL module leaves the underlying dLLM sampling distribution unchanged except for block-size selection; without measurements of new inconsistencies or distribution shifts, the coherence gains cannot be isolated from potential side effects.
Authors: We will add quantitative evidence in the revision by reporting KL divergence between the base dLLM token distribution and the b1-augmented distribution over sampled sequences, along with any observed generation inconsistencies. Because b1 acts solely as a post-training block-size selector during diffusion sampling and does not alter the underlying denoising network, we expect limited distribution shift; the new measurements will allow readers to isolate the coherence gains from side effects. revision: yes
Circularity Check
No significant circularity; derivation grounded in external empirical observation
full rationale
The paper's core chain begins with an empirical observation (block-wise entropy descends monotonically for correct reasoning but fluctuates for incorrect), which is presented as data-driven rather than derived from the model. It then constructs a Monotonic Entropy Descent objective to serve as the RL reward for learning dynamic block sizes. This objective is not self-definitional (the reward is not defined in terms of the policy outputs it optimizes), nor is any 'prediction' of coherence gains equivalent to the input by construction. Experiments on external benchmarks provide the claimed validation, and no load-bearing self-citations, uniqueness theorems, or ansatzes from prior author work are invoked in the provided text to force the result. The approach remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Block-wise entropy exhibits a consistent descending trend for correct reasoning and a fluctuating trend for incorrect reasoning
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (Jcost)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
b1 introduces Monotonic Entropy Descent (MED) via a block entropy reward, facilitating block generations with consistent descending entropy.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Block-R1: Rethinking the Role of Block Size in Multi-domain Reinforcement Learning for Diffusion Large Language Models
Block-R1 formulates domain block size conflicts in multi-domain RL for dLLMs, releases a 41K-sample dataset with per-sample best block sizes and a conflict score, and provides a benchmark plus simple cross-domain trai...
-
Block-R1: Rethinking the Role of Block Size in Multi-domain Reinforcement Learning for Diffusion Large Language Models
Introduces Block-R1 benchmark, Block-R1-41K dataset, and a conflict score to handle domain-specific optimal block sizes in RL post-training of diffusion LLMs.
Reference graph
Works this paper leans on
-
[1]
Visual generation without guidance.Forty-second international conference on machine learning, 2025a
Chen, H., Zheng, K., Zhang, Q., Cui, G., Cui, Y ., Ye, H., Lin, T.-Y ., Liu, M.-Y ., Zhu, J., and Wang, H. Bridging Su- pervised Learning and Reinforcement Learning in Math Reasoning.arXiv preprint arXiv:2505.18116,
-
[2]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
-
[3]
He, H., Renz, K., Cao, Y ., and Geiger, A. Mdpo: Overcom- ing the training-inference divide of masked diffusion lan- guage models.arXiv preprint arXiv:2508.13148,
-
[5]
URL https://arxiv. org/abs/2504.04188. Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InICLR,
-
[6]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review arXiv
-
[7]
M., Karashima, Y ., Wang, Z., Fujiki, D., and Fan, H
Lu, G., Chen, H. M., Karashima, Y ., Wang, Z., Fujiki, D., and Fan, H. Adablock-dllm: Semantic-aware diffusion llm inference via adaptive block size.arXiv preprint arXiv:2509.26432,
-
[8]
Mroueh, Y . Reinforcement Learning with Verifiable Re- wards: GRPO’s Effective Loss, Dynamics, and Success Amplification.arXiv preprint arXiv:2503.06639,
-
[9]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large Language Diffusion Models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review arXiv
-
[10]
arXiv preprint arXiv:2510.08554 , year=
Rojas, K., Lin, J., Rasul, K., Schneider, A., Nevmyvaka, Y ., Tao, M., and Deng, W. Improving reasoning for diffusion language models via group diffusion policy optimization. arXiv preprint arXiv:2510.08554,
-
[11]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[13]
Deferred commitment decoding for diffusion language models.CoRR, abs/2601.02076, 2026
Shu, Y ., Tian, Y ., Xu, C., Wang, Y ., and Chen, H. De- ferred commitment decoding for diffusion language mod- els.arXiv preprint arXiv:2601.02076,
-
[14]
Tang, X., Dolga, R., Yoon, S., and Bogunovic, I. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838,
-
[15]
Multiplex thinking: Reasoning via token-wise branch- and-merge.arXiv preprint arXiv:2601.08808,
9 b1 Tang, Y ., Dong, L., Hao, Y ., Dong, Q., Wei, F., and Gu, J. Multiplex thinking: Reasoning via token-wise branch- and-merge.arXiv preprint arXiv:2601.08808,
-
[16]
d2 : Improved techniques for training reasoning diffusion language models
Wang, G., Schiff, Y ., Turok, G., and Kuleshov, V . d2: Improved techniques for training reasoning diffusion lan- guage models.arXiv preprint arXiv:2509.21474, 2025a. Wang, Y ., Yang, L., Li, B., Tian, Y ., Shen, K., and Wang, M. Revolutionizing reinforcement learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949, 2025b. Xi...
-
[17]
MMaDA: Multimodal Large Diffusion Language Models
Yang, L., Tian, Y ., Li, B., Zhang, X., Shen, K., Tong, Y ., and Wang, M. Mmada: Multimodal Large Diffusion Language Models.arXiv preprint arXiv:2505.15809,
work page internal anchor Pith review arXiv
-
[18]
Dream 7B.URL https://hkunlp.github.io/blog/2025/dream,
Ye, J., Xie, Z., Zheng, L., Gao, J., Wu, Z., Jiang, X., Li, Z., and Kong, L. Dream 7B.URL https://hkunlp.github.io/blog/2025/dream,
2025
-
[19]
Zekri, O. and Boullé, N. Fine-Tuning Discrete Diffusion Models with Policy Gradient Methods.arXiv preprint arXiv:2502.01384,
-
[20]
Zhao, S., Gupta, D., Zheng, Q., and Grover, A. d1: Scaling Reasoning in Diffusion Large Language Models via Re- inforcement Learning.arXiv preprint arXiv:2504.12216,
-
[21]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models.arXiv preprint arXiv:2505.19223, 2025a. Zhu, X., Xia, M., Wei, Z., Chen, W.-L., Chen, D., and Meng, Y . The Surprising Effectiveness of Negative Reinforcement in LLM...
work page internal anchor Pith review arXiv
-
[22]
Appendix Overview This appendix provides supplementary materials, theoretical proofs, and comprehensive experimental details to support the main findings ofb1
10 b1 A. Appendix Overview This appendix provides supplementary materials, theoretical proofs, and comprehensive experimental details to support the main findings ofb1. We organised as follows: •Appendix Breviews related literature, categorized into: ◦Diffusion Large Language Models in Appendix B.1; ◦Reinforcement Learning for Reasoning in Appendix B.2; ◦...
2025
-
[23]
However, using a fixed block size is not ideal because reasoning tasks vary in difficulty
usually break the output into fixed-size blocks and generate these blocks in parallel (Arriola et al., 2025). However, using a fixed block size is not ideal because reasoning tasks vary in difficulty. Some steps need more tokens, while others need fewer (Xiong et al., 2025). A fixed size prevents the model from adjusting its resources based on the actual ...
2025
-
[24]
However, a key limitation remains across all 11 b1 these approaches
use score-based objectives instead of relying on probability estimates. However, a key limitation remains across all 11 b1 these approaches. Current methods, includingwd1(Tang et al., 2025), GDPO (Rojas et al., 2025), and TraceRL (Wang et al., 2025b), are strictly limited to generating blocks of a fixed size. They do not allow the model to adjust the bloc...
2025
-
[25]
was developed under few-shot scenarios to search for the next newline character and truncate blocks at that position. Despite providing variable block sizes, AdaBlock-dLLM operates as a hard-coded method reliant on pre-defined confidence thresholds and is restricted to splitting at newline characters, which do not always represent the true boundaries of r...
2026
-
[26]
Notably, all reward functions, including the reward introduced inb1, share the same reward weight
and wd1(Tang et al., 2025),with the specific configurations detailed below. Notably, all reward functions, including the reward introduced inb1, share the same reward weight
2025
-
[27]
Implementation of GRPO is based on the TRL library (von Werra et al.,
andwd1(Tang et al., 2025). Implementation of GRPO is based on the TRL library (von Werra et al.,
2025
-
[28]
For the GRPO optimisation, Low-Rank Adaptation (LoRA) is integrated with a specific configuration of rankr= 128and a scaling factorα= 64followingd1(Zhao et al.,
on LLaDA-8b-Instruct,ensuring that our model selection remains identical to prior methods (Zhao et al., 2025; Tang et al., 2025).Note that other non-block dLLM backbones, such as Dream (Ye et al., 2025), are excluded as they do not originally designed with block-based generation paradigm. For the GRPO optimisation, Low-Rank Adaptation (LoRA) is integrated...
2025
-
[29]
The training of GRPO across the GSM8K, MATH, Countdown, and Sudoku benchmarks is performed on a cluster of four AMD Mi300x GPUs
andwd1(Tang et al., 2025). The training of GRPO across the GSM8K, MATH, Countdown, and Sudoku benchmarks is performed on a cluster of four AMD Mi300x GPUs. The experimental setup involves a sequence length of 256 tokens, a per-GPU batch size of 12, and a gradient accumulation frequency of
2025
-
[30]
Notably,b1reaches its peak performance significantly earlier than the baselines, specifically at step 1,000 for Sudoku, 2,100 for Countdown, 1,400 for MATH500, and 2,000 for GSM8K
Each method undergoes training for a total of 10,000 global steps and is evaluated every 100 steps. Notably,b1reaches its peak performance significantly earlier than the baselines, specifically at step 1,000 for Sudoku, 2,100 for Countdown, 1,400 for MATH500, and 2,000 for GSM8K. In comparison, the state-of-the-art baseline wd1requires 1,500, 3,000, 1,500...
2017
-
[31]
The learning rate is fixed at 3×10 −6 with gradient clipping enforced at a threshold of 0.2
andwd1(Tang et al., 2025). The learning rate is fixed at 3×10 −6 with gradient clipping enforced at a threshold of 0.2. To enhance computational throughput, Flash Attention 2 (Dao,
2025
-
[32]
Theorem 1: Equivalence between Block Entropy Reward and Spearman’s Rank Correlation Coefficient The maximisation of the local reward Rent (Eq. (8)) between adjacent block pairs is mathematically equivalent to maximising the global negative Spearman’s Rank Correlation Coefficient (rSCC): arg maxRent = arg maxrSCC.(11) As the proposed rSCC measures the mono...
1952
-
[33]
In contrast,b1demonstrates markedly superior stability and faster convergence. By learning dynamic-size reasoning blocks that align with the semantic flow,b1mitigates the optimisation difficulties associated with fixed rigid block generations, thereby establishing a more stable RL training paradigm for dLLMs. E.4. Discussion of Difference between Existing...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.