Recognition: 2 theorem links
A Systematic Benchmark of Machine Transliteration Models for the Tajik-Farsi Language Pair: A Comparative Study from Rule-Based to Transformer Architectures
Pith reviewed 2026-05-08 19:19 UTC · model grok-4.3
The pith
Byte-level ByT5 reaches chrF++ scores of 87.4 and 80.1 for Tajik-Farsi transliteration while subword models fail below 18.5.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
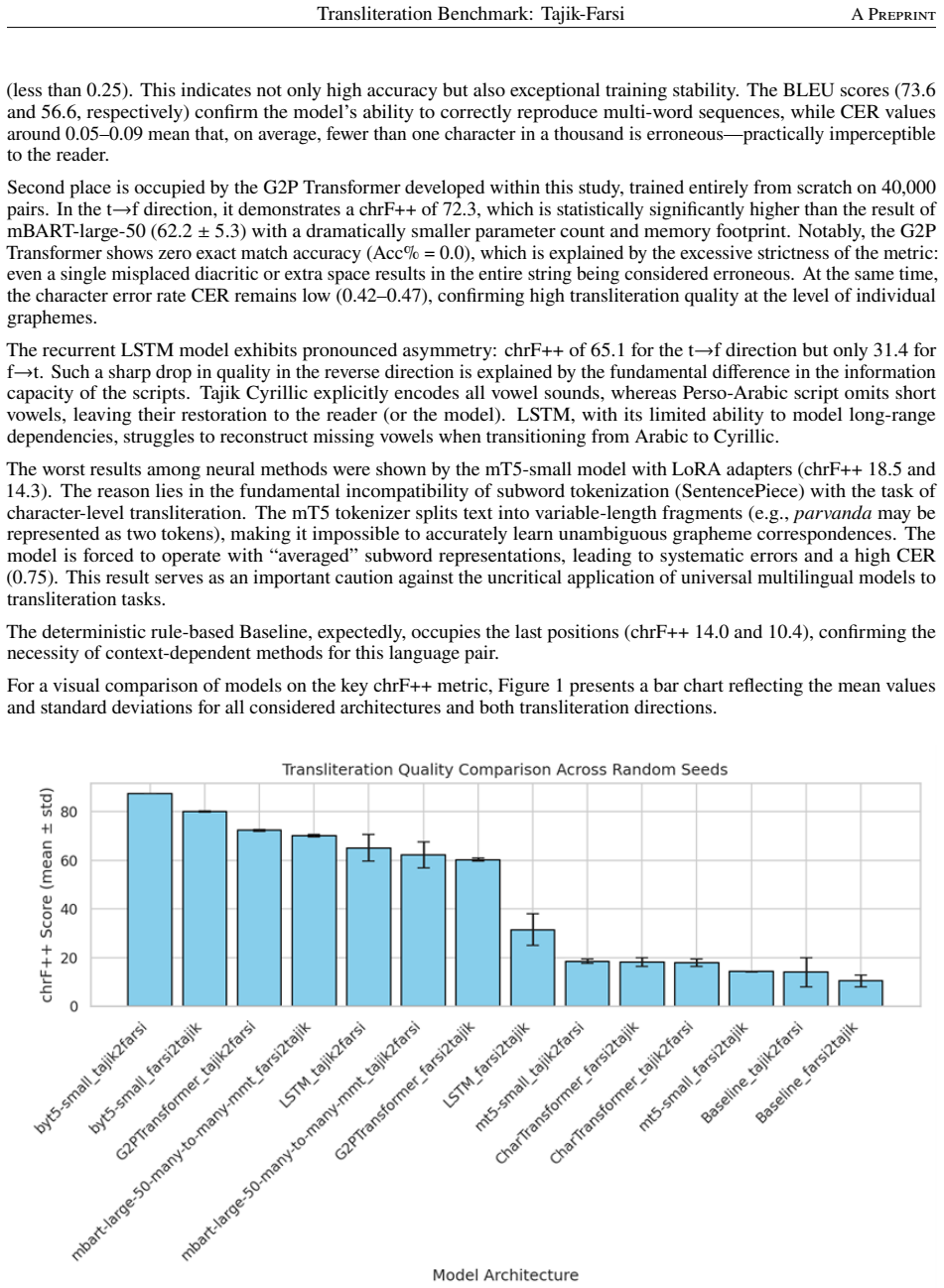
On the 40,000-pair test set the byte-level ByT5 model attains chrF++ of 87.4 for Tajik-to-Farsi and 80.1 for the reverse, the character-level G2P Transformer reaches 72.3, mBART scores 62.2, and mT5 with subword tokenization stays below 18.5. These numbers establish that architectures working at byte or character granularity outperform both rule-based baselines and pre-trained multilingual Seq2Seq models that depend on subword tokenization for this particular script-conversion task.
What carries the argument
A 40,000-pair stratified subset drawn from a 328,253-pair corpus aggregated from Shahnameh, Masnavi, diplomatic texts, terminology lists and crowdsourced pairs, used to train and evaluate rule-based, LSTM, character Transformer, G2P, mBART, mT5-LoRA and ByT5 systems.
Load-bearing premise
The 40,000-pair sample drawn from the mixed literary, diplomatic and crowdsourced sources captures the full range of real-world Tajik-Farsi spelling and vocabulary patterns without systematic bias.
What would settle it
Running ByT5 on a fresh collection of several thousand Tajik-Farsi pairs taken from contemporary news or social media and obtaining chrF++ scores below 70 in either direction would show the reported superiority does not hold outside the original corpus.
Figures



read the original abstract
This paper presents the first comprehensive comparative analysis of modern machine learning architectures for transliteration between Tajik (Cyrillic script) and Persian (Arabic script). A key contribution is the creation and validation of a unique parallel corpus aggregated from multiple heterogeneous sources, including crowdsourced projects, lexicographic pairs, parallel texts of "Shahnameh", diplomatic articles, texts of "Masnavi-i Ma'navi", official terminology lists, and transliterated correspondences. The initial dataset comprised 328,253 sentence pairs; a representative subset of 40,000 pairs was formed using stratified random sampling. The experiment compared six classes of models: rule-based baseline, LSTM with attention, character-level Transformer, G2P Transformer (trained from scratch), pre-trained multilingual models (mBART, mT5 with LoRA), and byte-level ByT5. Results demonstrate the overwhelming superiority of ByT5 (chrF++ 87.4 for Tajik to Farsi, 80.1 for reverse). The G2P Transformer significantly outperformed mBART (72.3 vs. 62.2 chrF++) despite limited data. Models using subword tokenization (mT5) failed completely (chrF++ less than 18.5). The findings demonstrate that for accurate transliteration of the Tajik-Farsi pair, architectures operating at the byte or character level are unequivocally more effective than traditional multilingual Seq2Seq models relying on subword tokenization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper creates a 40,000-pair Tajik-Farsi parallel corpus via stratified sampling from a 328k aggregate drawn from crowdsourced, literary (Shahnameh, Masnavi), diplomatic, and official sources, then benchmarks rule-based, LSTM, character-level Transformer, G2P Transformer, mBART, mT5 (LoRA), and ByT5 models for transliteration. It reports ByT5 as overwhelmingly superior (chrF++ 87.4 Tajik-to-Farsi, 80.1 reverse) while subword models like mT5 collapse (<18.5), concluding that byte/character-level architectures are unequivocally preferable to subword Seq2Seq models for this pair.
Significance. If the empirical ranking proves robust, the work supplies a useful first benchmark and dataset for Tajik-Farsi transliteration, an under-studied script-conversion task. The contrast between byte-level success and subword failure offers a concrete data point for architecture choice in low-resource transliteration settings.
major comments (3)
- [Corpus Construction] Corpus section: the 40k stratified subset is presented without stratification keys, per-source counts, or domain-wise performance breakdowns. Because the sources differ systematically in spelling conventions and difficulty, the absence of these diagnostics leaves open the possibility that the large chrF++ gaps (ByT5 87.4 vs. mT5 <18.5) are inflated by under-sampling of hard cases from particular domains.
- [Experimental Results] Results section: chrF++ scores are given as point estimates with no error bars, bootstrap intervals, or paired significance tests. Without these, the claim of 'overwhelming superiority' cannot be distinguished from sampling variance in a single 40k split.
- [Model Implementation] Model Implementation: the rule-based baseline and the from-scratch G2P Transformer lack hyper-parameter tables, training schedules, or exact adaptation steps for the Tajik-Farsi pair. These omissions prevent both reproduction and assessment of whether the reported 72.3 vs. 62.2 gap is fairly obtained.
minor comments (2)
- [Abstract] Abstract: the 72.3 vs. 62.2 comparison does not state the translation direction.
- [Conclusion] Conclusion: the phrasing 'unequivocally more effective' should be qualified to the specific corpus and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us identify areas for improvement in clarity and rigor. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Corpus Construction] Corpus section: the 40k stratified subset is presented without stratification keys, per-source counts, or domain-wise performance breakdowns. Because the sources differ systematically in spelling conventions and difficulty, the absence of these diagnostics leaves open the possibility that the large chrF++ gaps (ByT5 87.4 vs. mT5 <18.5) are inflated by under-sampling of hard cases from particular domains.
Authors: We appreciate the referee's point regarding transparency in corpus construction. The 40k subset was created via stratified random sampling explicitly stratified by source domain (crowdsourced, literary texts from Shahnameh and Masnavi, diplomatic, and official sources) to maintain proportional representation of spelling conventions and text difficulty. In the revised manuscript we will add a table reporting the exact per-source counts and stratification keys. We will also include domain-wise chrF++ breakdowns for the primary models (ByT5, G2P Transformer, mT5) on the held-out test data; preliminary internal checks indicate that ByT5 maintains its advantage across all domains, which we will document to address concerns about potential under-sampling of harder cases. revision: yes
-
Referee: [Experimental Results] Results section: chrF++ scores are given as point estimates with no error bars, bootstrap intervals, or paired significance tests. Without these, the claim of 'overwhelming superiority' cannot be distinguished from sampling variance in a single 40k split.
Authors: We acknowledge that the absence of uncertainty estimates limits the strength of the superiority claim. Although the magnitude of the observed gaps (e.g., 87.4 versus <18.5) makes sampling variance an unlikely explanation, we agree that formal statistical support is warranted. In the revision we will add bootstrap confidence intervals (1,000 resamples of the test set) for all reported chrF++ scores and include paired statistical tests (Wilcoxon signed-rank test with Bonferroni correction) between the top-performing models and the subword baselines to substantiate the ranking. revision: yes
-
Referee: [Model Implementation] Model Implementation: the rule-based baseline and the from-scratch G2P Transformer lack hyper-parameter tables, training schedules, or exact adaptation steps for the Tajik-Farsi pair. These omissions prevent both reproduction and assessment of whether the reported 72.3 vs. 62.2 gap is fairly obtained.
Authors: We agree that insufficient implementation detail hinders reproducibility and fair comparison. The revised manuscript will include a dedicated appendix with (i) a full hyper-parameter table for every model, (ii) the complete training schedule and optimization settings for the from-scratch G2P Transformer and LSTM, and (iii) an explicit description of the rule-based baseline's mapping rules, exception handling, and any Tajik-Farsi-specific adaptations. These additions will allow readers to verify that the 72.3 versus 62.2 gap was obtained under comparable conditions. revision: yes
Circularity Check
No circularity in empirical benchmark of transliteration models
full rationale
The paper reports an empirical comparison of six model classes on a held-out test partition drawn from a 40,000-pair stratified subset of an aggregated corpus. All central claims (ByT5 superiority at chrF++ 87.4/80.1, failure of subword models below 18.5, preference for byte/character-level architectures) rest on direct performance measurements rather than any equation, derivation, or fitted parameter that reduces to quantities defined by the authors' own inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises; the sampling procedure is presented as an experimental design choice whose validity is external to the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 40,000-pair stratified subset is representative of the full 328,253-pair collection and of real-world Tajik-Farsi usage.
Forward citations
Cited by 2 Pith papers
-
Natural Language Processing: A Comprehensive Practical Guide from Tokenisation to RLHF
A structured practicum guides readers through the complete modern NLP pipeline with reproducible sessions and new linguistic resources for Tajik and Tatar.
-
Natural Language Processing: A Comprehensive Practical Guide from Tokenisation to RLHF
The work provides a reproducible, session-based guide to the NLP pipeline with original adaptations and resources for morphologically rich low-resource languages.
Reference graph
Works this paper leans on
-
[1]
Arabov, M. K. , title =. 2026 , publisher =
2026
-
[2]
Findings of the Association for Computational Linguistics: EACL 2026 , year =
Merchant, Rayyan and Tang, Kevin , title =. Findings of the Association for Computational Linguistics: EACL 2026 , year =
2026
-
[3]
Proceedings of the Second Workshop on Computation and Written Language (CAWL) @ LREC-COLING 2024 , year =
Merchant, Rayyan and Tang, Kevin , title =. Proceedings of the Second Workshop on Computation and Written Language (CAWL) @ LREC-COLING 2024 , year =
2024
-
[4]
The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family , year =
Arabov, Mullosharaf Kurbonovich , title =. The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family , year =
-
[5]
Proceedings of the 2nd Workshop on NLP for Languages Using Arabic Script , year =
Kurbonovich, Arabov Mullosharaf , title =. Proceedings of the 2nd Workshop on NLP for Languages Using Arabic Script , year =
-
[6]
Arabov, M. K. and Makhmadaliev, Kh. S. and Khabibullozoda, K. Kh. , title =. Science and Innovation. Series of Geological and Technical Sciences , number =. 2025 , note =
2025
-
[7]
The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family , year =
Basirat, Ali and Namazifard, Danial and Hemmati, Navid Baradaran , title =. The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family , year =
-
[8]
The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family , year =
Jafari, Sadegh and Azin, Tara and Roodi, Farhad and Tafti, Zahra Dehghani and Ghadrdan, Mehrdad and Esfahani, Elham Vatankhahan and Naebzadeh, Aylin and Shahhosseini, Mohammadhadi and Khan, Ghafoor and Forghani, Kazem and Namazi, Danial and Hashemi, Seyed Mohammad Hossein and Farsi, Farhan and Osoolian, Mohammad and Mohammadi, Maede and Zare, Mohammad Erf...
-
[9]
Proceedings of the 1st Workshop on NLP for Languages Using Arabic Script , year =
Jafari, Sadegh and Farsi, Farhan and Ebrahimi, Navid and Sajadi, Mohamad Bagher and Eetemadi, Sauleh , title =. Proceedings of the 1st Workshop on NLP for Languages Using Arabic Script , year =
-
[10]
3rd International Conference on Learning Representations (ICLR 2015) , year =
Bahdanau, Dzmitry and Cho, Kyunghyun and Bengio, Yoshua , title =. 3rd International Conference on Learning Representations (ICLR 2015) , year =
2015
-
[11]
Hu, E. J. and Shen, Y. and Wallis, P. and Allen-Zhu, Z. and Li, Y. and Wang, S. and Wang, L. and Chen, W. , title =. 10th International Conference on Learning Representations (ICLR 2022) , year =
2022
-
[12]
Proceedings of the Second Conference on Machine Translation (WMT 2017) , year =
Popovi. Proceedings of the Second Conference on Machine Translation (WMT 2017) , year =
2017
-
[13]
Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12) , year =
Davis, Chris Irwin , title =. Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12) , year =
-
[14]
Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC'08) , year =
Megerdoomian, Karine and Parvaz, Dan , title =. Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC'08) , year =
-
[15]
Grashchenko, L. A. , title =. 2003 , url =
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.